
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
TensorFlow क्वांटम क्वांटम प्राइमेटिव्स को TensorFlow पारिस्थितिकी तंत्र में लाता है। अब क्वांटम शोधकर्ता TensorFlow से टूल का लाभ उठा सकते हैं। इस ट्यूटोरियल में आप अपने क्वांटम कंप्यूटिंग अनुसंधान में TensorBoard को शामिल करने पर करीब से नज़र डालेंगे। TensorFlow से DCGAN ट्यूटोरियल का उपयोग करके आप जल्दी से काम करने वाले प्रयोगों और विज़ुअलाइज़ेशन का निर्माण करेंगे जो Niu et al द्वारा किए गए हैं। . मोटे तौर पर आप बोलेंगे:
- एक GAN को ऐसे नमूने तैयार करने के लिए प्रशिक्षित करें जो देखने में ऐसा लगे जैसे वे क्वांटम सर्किट से आए हों।
- समय के साथ प्रशिक्षण प्रगति के साथ-साथ वितरण विकास की कल्पना करें।
- गणना ग्राफ़ की खोज करके प्रयोग को बेंचमार्क करें।
pip install tensorflow==2.7.0 tensorflow-quantum tensorboard_plugin_profile==2.4.0
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
#docs_infra: no_execute
%load_ext tensorboard
import datetime
import time
import cirq
import tensorflow as tf
import tensorflow_quantum as tfq
from tensorflow.keras import layers
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
2022-02-04 12:46:52.770534: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. डेटा जनरेशन
कुछ डेटा इकट्ठा करके शुरू करें। आप कुछ बिटस्ट्रिंग नमूनों को जल्दी से उत्पन्न करने के लिए TensorFlow क्वांटम का उपयोग कर सकते हैं जो आपके बाकी प्रयोगों के लिए प्राथमिक डेटा स्रोत होंगे। नीउ एट अल की तरह। आप यह पता लगाएंगे कि अत्यधिक कम गहराई के साथ यादृच्छिक सर्किट से नमूनाकरण का अनुकरण करना कितना आसान है। सबसे पहले, कुछ सहायकों को परिभाषित करें:
def generate_circuit(qubits):
"""Generate a random circuit on qubits."""
random_circuit = cirq.generate_boixo_2018_supremacy_circuits_v2(
qubits, cz_depth=2, seed=1234)
return random_circuit
def generate_data(circuit, n_samples):
"""Draw n_samples samples from circuit into a tf.Tensor."""
return tf.squeeze(tfq.layers.Sample()(circuit, repetitions=n_samples).to_tensor())
अब आप सर्किट के साथ-साथ कुछ नमूना डेटा का निरीक्षण कर सकते हैं:
qubits = cirq.GridQubit.rect(1, 5)
random_circuit_m = generate_circuit(qubits) + cirq.measure_each(*qubits)
SVGCircuit(random_circuit_m)
findfont: Font family ['Arial'] not found. Falling back to DejaVu Sans.

samples = cirq.sample(random_circuit_m, repetitions=10)
print('10 Random bitstrings from this circuit:')
print(samples)
10 Random bitstrings from this circuit: (0, 0)=1000001000 (0, 1)=0000001010 (0, 2)=1010000100 (0, 3)=0010000110 (0, 4)=0110110010
आप TensorFlow क्वांटम में भी ऐसा ही कर सकते हैं:
generate_data(random_circuit_m, 10)
<tf.Tensor: shape=(10, 5), dtype=int8, numpy=
array([[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 1, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 1, 1, 0, 0],
[1, 0, 0, 0, 0],
[1, 0, 0, 1, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 0, 0]], dtype=int8)>
अब आप इसके साथ अपना प्रशिक्षण डेटा जल्दी से तैयार कर सकते हैं:
N_SAMPLES = 60000
N_QUBITS = 10
QUBITS = cirq.GridQubit.rect(1, N_QUBITS)
REFERENCE_CIRCUIT = generate_circuit(QUBITS)
all_data = generate_data(REFERENCE_CIRCUIT, N_SAMPLES)
all_data
<tf.Tensor: shape=(60000, 10), dtype=int8, numpy=
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]], dtype=int8)>
जैसे-जैसे प्रशिक्षण चल रहा होगा, कल्पना करने के लिए कुछ सहायक कार्यों को परिभाषित करना उपयोगी होगा। उपयोग करने के लिए दो दिलचस्प मात्राएँ हैं:
- नमूनों के पूर्णांक मान, ताकि आप वितरण के हिस्टोग्राम बना सकें।
- नमूने के एक सेट का रैखिक XEB निष्ठा अनुमान, कुछ संकेत देने के लिए कि नमूने "वास्तव में क्वांटम यादृच्छिक" कैसे हैं।
@tf.function
def bits_to_ints(bits):
"""Convert tensor of bitstrings to tensor of ints."""
sigs = tf.constant([1 << i for i in range(N_QUBITS)], dtype=tf.int32)
rounded_bits = tf.clip_by_value(tf.math.round(
tf.cast(bits, dtype=tf.dtypes.float32)), clip_value_min=0, clip_value_max=1)
return tf.einsum('jk,k->j', tf.cast(rounded_bits, dtype=tf.dtypes.int32), sigs)
@tf.function
def xeb_fid(bits):
"""Compute linear XEB fidelity of bitstrings."""
final_probs = tf.squeeze(
tf.abs(tfq.layers.State()(REFERENCE_CIRCUIT).to_tensor()) ** 2)
nums = bits_to_ints(bits)
return (2 ** N_QUBITS) * tf.reduce_mean(tf.gather(final_probs, nums)) - 1.0
यहां आप XEB का उपयोग करके अपने वितरण और विवेक जांच चीजों की कल्पना कर सकते हैं:
plt.hist(bits_to_ints(all_data).numpy(), 50)
plt.show()
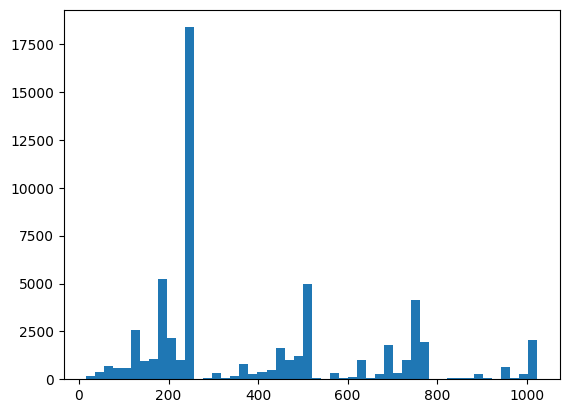
xeb_fid(all_data)
<tf.Tensor: shape=(), dtype=float32, numpy=-0.0015467405>
2. एक मॉडल बनाएं
यहां आप क्वांटम केस के लिए DCGAN ट्यूटोरियल से संबंधित घटकों का उपयोग कर सकते हैं। MNIST अंक बनाने के बजाय नए GAN का उपयोग N_QUBITS लंबाई के साथ बिटस्ट्रिंग नमूने बनाने के लिए किया जाएगा
LATENT_DIM = 100
def make_generator_model():
"""Construct generator model."""
model = tf.keras.Sequential()
model.add(layers.Dense(256, use_bias=False, input_shape=(LATENT_DIM,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(N_QUBITS, activation='relu'))
return model
def make_discriminator_model():
"""Constrcut discriminator model."""
model = tf.keras.Sequential()
model.add(layers.Dense(256, use_bias=False, input_shape=(N_QUBITS,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
return model
इसके बाद, अपने जनरेटर और डिस्क्रिमिनेटर मॉडल को इंस्टेंट करें, नुकसान को परिभाषित करें और अपने मुख्य प्रशिक्षण लूप के लिए उपयोग करने के लिए train_step फ़ंक्शन बनाएं:
discriminator = make_discriminator_model()
generator = make_generator_model()
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
"""Compute discriminator loss."""
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
"""Compute generator loss."""
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
BATCH_SIZE=256
@tf.function
def train_step(images):
"""Run train step on provided image batch."""
noise = tf.random.normal([BATCH_SIZE, LATENT_DIM])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(
gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(
disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(
zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(
zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss
अब जब आपके पास अपने मॉडल के लिए आवश्यक सभी बिल्डिंग ब्लॉक्स हैं, तो आप एक प्रशिक्षण फ़ंक्शन सेट कर सकते हैं जिसमें TensorBoard विज़ुअलाइज़ेशन शामिल है। पहले एक TensorBoard फ़ाइलराइटर सेटअप करें:
logdir = "tb_logs/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
file_writer = tf.summary.create_file_writer(logdir + "/metrics")
file_writer.set_as_default()
tf.summary मॉड्यूल का उपयोग करके, अब आप scalar , histogram (साथ ही अन्य) को TensorBoard में मुख्य train फ़ंक्शन के अंदर लॉगिंग शामिल कर सकते हैं:
def train(dataset, epochs, start_epoch=1):
"""Launch full training run for the given number of epochs."""
# Log original training distribution.
tf.summary.histogram('Training Distribution', data=bits_to_ints(dataset), step=0)
batched_data = tf.data.Dataset.from_tensor_slices(dataset).shuffle(N_SAMPLES).batch(512)
t = time.time()
for epoch in range(start_epoch, start_epoch + epochs):
for i, image_batch in enumerate(batched_data):
# Log batch-wise loss.
gl, dl = train_step(image_batch)
tf.summary.scalar(
'Generator loss', data=gl, step=epoch * len(batched_data) + i)
tf.summary.scalar(
'Discriminator loss', data=dl, step=epoch * len(batched_data) + i)
# Log full dataset XEB Fidelity and generated distribution.
generated_samples = generator(tf.random.normal([N_SAMPLES, 100]))
tf.summary.scalar(
'Generator XEB Fidelity Estimate', data=xeb_fid(generated_samples), step=epoch)
tf.summary.histogram(
'Generator distribution', data=bits_to_ints(generated_samples), step=epoch)
# Log new samples drawn from this particular random circuit.
random_new_distribution = generate_data(REFERENCE_CIRCUIT, N_SAMPLES)
tf.summary.histogram(
'New round of True samples', data=bits_to_ints(random_new_distribution), step=epoch)
if epoch % 10 == 0:
print('Epoch {}, took {}(s)'.format(epoch, time.time() - t))
t = time.time()
3. प्रशिक्षण और प्रदर्शन को विज़ुअलाइज़ करें
TensorBoard डैशबोर्ड को अब इसके साथ लॉन्च किया जा सकता है:
#docs_infra: no_execute
%tensorboard --logdir tb_logs/
train को कॉल करते समय TensoBoard डैशबोर्ड प्रशिक्षण लूप में दिए गए सभी सारांश आँकड़ों के साथ स्वतः अपडेट हो जाएगा।
train(all_data, epochs=50)
Epoch 10, took 9.325464487075806(s) Epoch 20, took 7.684147119522095(s) Epoch 30, took 7.508770704269409(s) Epoch 40, took 7.5157341957092285(s) Epoch 50, took 7.533370494842529(s)
जबकि प्रशिक्षण चल रहा है (और एक बार यह पूरा हो गया है) आप अदिश मात्रा की जांच कर सकते हैं:

हिस्टोग्राम टैब पर स्विच करने पर आप यह भी देख सकते हैं कि क्वांटम वितरण से नमूने को फिर से बनाने में जनरेटर नेटवर्क कितना अच्छा करता है:
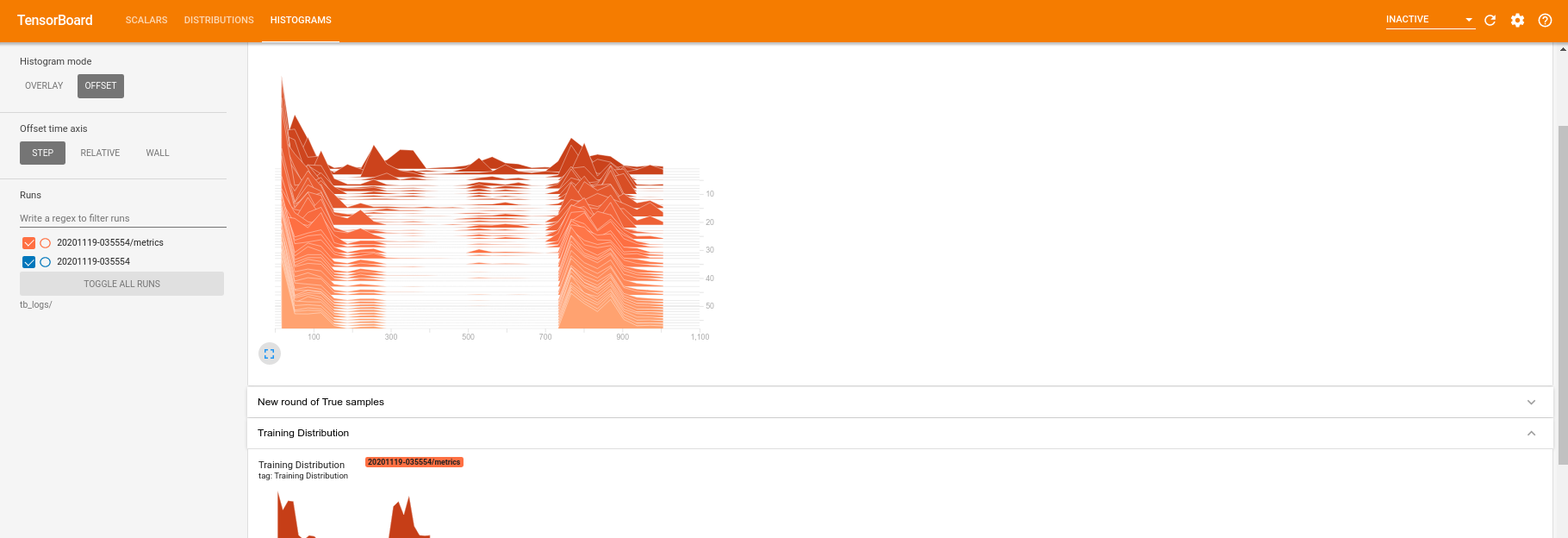
आपके प्रयोग से संबंधित सारांश आँकड़ों की वास्तविक समय निगरानी की अनुमति देने के अलावा, TensorBoard प्रदर्शन बाधाओं की पहचान करने के लिए अपने प्रयोगों को प्रोफाइल करने में भी आपकी मदद कर सकता है। प्रदर्शन निगरानी के साथ अपने मॉडल को फिर से चलाने के लिए आप यह कर सकते हैं:
tf.profiler.experimental.start(logdir)
train(all_data, epochs=10, start_epoch=50)
tf.profiler.experimental.stop()
Epoch 50, took 0.8879530429840088(s)
TensorBoard tf.profiler.experimental.start और tf.profiler.experimental.stop के बीच के सभी कोड को प्रोफाइल करेगा। यह प्रोफ़ाइल डेटा तब TensorBoard के profile पृष्ठ में देखा जा सकता है:
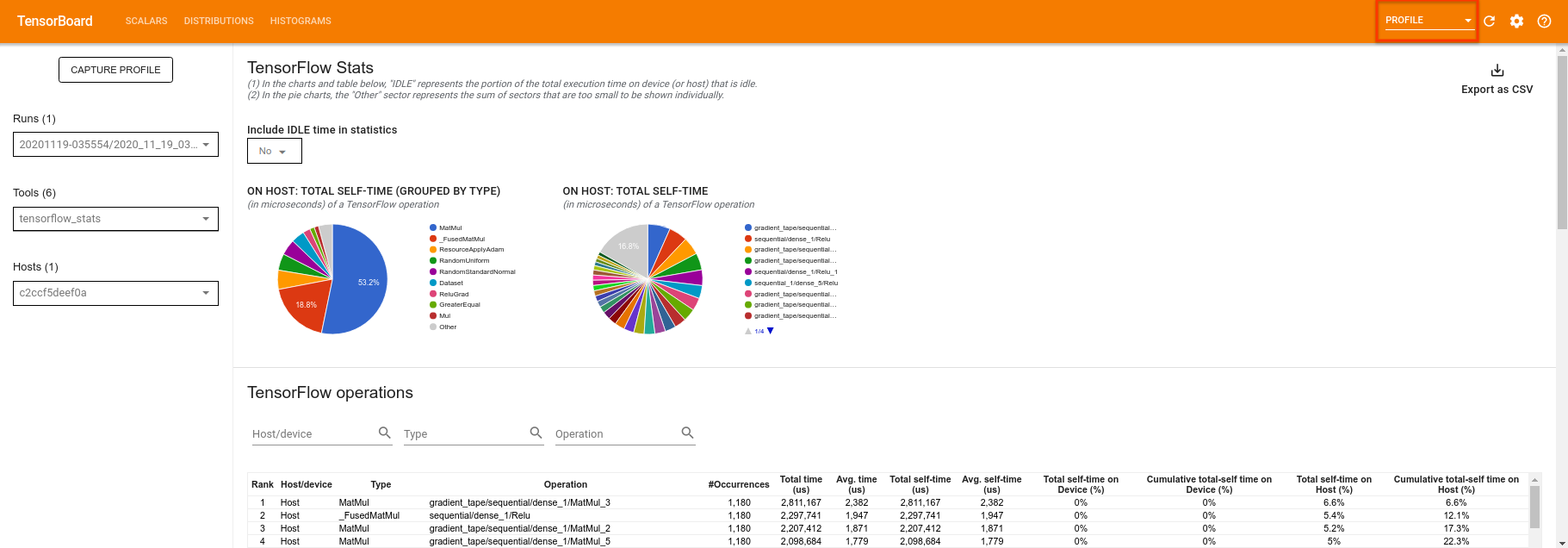
गहराई बढ़ाने या क्वांटम सर्किट के विभिन्न वर्गों के साथ प्रयोग करने का प्रयास करें। TensorBoard की अन्य सभी बेहतरीन विशेषताओं की जाँच करें जैसे कि हाइपरपैरामीटर ट्यूनिंग जिसे आप अपने TensorFlow क्वांटम प्रयोगों में शामिल कर सकते हैं।