
رویدادهای فاجعه بار شامل NaN ها گاهی اوقات می توانند در طول یک برنامه TensorFlow رخ دهند و فرآیندهای آموزشی مدل را فلج کنند. علت اصلی چنین وقایعی اغلب مبهم است، به خصوص برای مدل هایی با اندازه و پیچیدگی غیر ضروری. برای آسانتر کردن اشکالزدایی این نوع باگهای مدل، TensorBoard 2.3+ (به همراه TensorFlow 2.3+) یک داشبورد تخصصی به نام Debugger V2 ارائه میکند. در اینجا نحوه استفاده از این ابزار را با کار بر روی یک باگ واقعی شامل NaNs در یک شبکه عصبی نوشته شده در TensorFlow نشان میدهیم.
تکنیک های نشان داده شده در این آموزش برای انواع دیگر فعالیت های اشکال زدایی مانند بررسی اشکال تانسور زمان اجرا در برنامه های پیچیده قابل استفاده است. این آموزش به دلیل فراوانی نسبتا بالای وقوع NaN ها بر روی آنها تمرکز دارد.
مشاهده اشکال
کد منبع برنامه TF2 که ما آن را اشکال زدایی خواهیم کرد در GitHub موجود است. برنامه نمونه نیز در بسته تنسورفلو پیپ (نسخه 2.3+) بسته بندی شده است و می تواند توسط:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
این برنامه TF2 یک ادراک چند لایه (MLP) ایجاد می کند و آن را برای تشخیص تصاویر MNIST آموزش می دهد. این مثال به طور هدفمند از API سطح پایین TF2 برای تعریف ساختارهای لایه سفارشی، تابع از دست دادن و حلقه آموزشی استفاده می کند، زیرا احتمال وجود اشکالات NaN زمانی که از این API انعطاف پذیرتر اما مستعد خطا استفاده می کنیم بیشتر از زمانی است که از API ساده تر استفاده می کنیم. APIهای سطح بالا با قابلیت استفاده اما کمی کمتر انعطاف پذیر مانند tf.keras .
این برنامه پس از هر مرحله آموزشی یک دقت تست را چاپ می کند. میتوانیم در کنسول ببینیم که دقت تست پس از مرحله اول در سطح تقریباً شانسی (~0.1) گیر میکند. مطمئناً انتظار می رود که آموزش مدل اینگونه رفتار کند: ما انتظار داریم که دقت به تدریج به 1.0 (100٪) با افزایش مرحله نزدیک شود.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
یک حدس علمی این است که این مشکل ناشی از یک بی ثباتی عددی است، مانند NaN یا بی نهایت. با این حال، چگونه تأیید کنیم که واقعاً چنین است و چگونه عملیات TensorFlow (op) را مسئول ایجاد ناپایداری عددی مییابیم؟ برای پاسخ به این سوالات، اجازه دهید برنامه باگی را با Debugger V2 ابزارسازی کنیم.
ابزار دقیق کد TensorFlow با Debugger V2
tf.debugging.experimental.enable_dump_debug_info() نقطه ورودی API Debugger V2 است. یک برنامه TF2 را با یک خط کد تنظیم می کند. به عنوان مثال، افزودن خط زیر در نزدیکی ابتدای برنامه باعث می شود که اطلاعات اشکال زدایی در فهرست log (logdir) در /tmp/tfdbg2_logdir نوشته شود. اطلاعات اشکال زدایی جنبه های مختلف زمان اجرا TensorFlow را پوشش می دهد. در TF2، شامل تاریخچه کامل اجرای مشتاق، ساخت گراف انجام شده توسط @tf.function ، اجرای نمودارها، مقادیر تانسور تولید شده توسط رویدادهای اجرا، و همچنین مکان کد (ردپای پشته پایتون) آن رویدادها است. . غنای اطلاعات اشکال زدایی کاربران را قادر می سازد تا باگ های مبهم را محدود کنند.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
آرگومان tensor_debug_mode کنترل می کند که Debugger V2 چه اطلاعاتی را از هر تانسور مشتاق یا درون گراف استخراج می کند. "FULL_HEALTH" حالتی است که اطلاعات زیر را در مورد هر تانسور نوع شناور دریافت می کند (به عنوان مثال، float32 که معمولاً دیده می شود و نوع کمتر bfloat16 dtype):
- نوع DType
- رتبه
- تعداد کل عناصر
- تجزیه عناصر نوع شناور به دسته های زیر: محدود منفی (
-)، صفر (0)، محدود مثبت (+)، بی نهایت منفی (-∞)، بی نهایت مثبت (+∞)، وNaN.
حالت "FULL_HEALTH" برای رفع اشکالات مربوط به NaN و infinity مناسب است. برای مشاهده سایر تنظیمات tensor_debug_mode به زیر مراجعه کنید.
آرگومان circular_buffer_size تعداد رویدادهای تانسور ذخیره شده در logdir را کنترل می کند. به طور پیشفرض روی 1000 تنظیم میشود، که باعث میشود تنها 1000 تانسور آخر قبل از پایان برنامه TF2 ابزاردار روی دیسک ذخیره شود. این رفتار پیشفرض با قربانی کردن کامل بودن دادههای اشکالزدایی، سربار دیباگر را کاهش میدهد. اگر کامل بودن ترجیح داده شود، مانند این مورد، میتوانیم بافر دایرهای را با تنظیم آرگومان روی یک مقدار منفی غیرفعال کنیم (مثلاً در اینجا -1).
مثال debug_mnist_v2 enable_dump_debug_info() را با ارسال پرچمهای خط فرمان به آن فراخوانی میکند. برای اجرای دوباره برنامه مشکل ساز TF2 با فعال بودن ابزار اشکال زدایی، این کار را انجام دهید:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
راه اندازی Debugger V2 GUI در TensorBoard
اجرای برنامه با ابزار دقیق دیباگر یک logdir در /tmp/tfdbg2_logdir ایجاد می کند. میتوانیم TensorBoard را راهاندازی کنیم و آن را در logdir با استفاده از:
tensorboard --logdir /tmp/tfdbg2_logdir
در مرورگر وب، به صفحه TensorBoard در http://localhost:6006 بروید. افزونه «Debugger V2» به طور پیشفرض غیرفعال خواهد بود، بنابراین آن را از منوی «افزونههای غیرفعال» در بالا سمت راست انتخاب کنید. پس از انتخاب، باید به شکل زیر باشد:
استفاده از Debugger V2 GUI برای یافتن علت اصلی NaNs
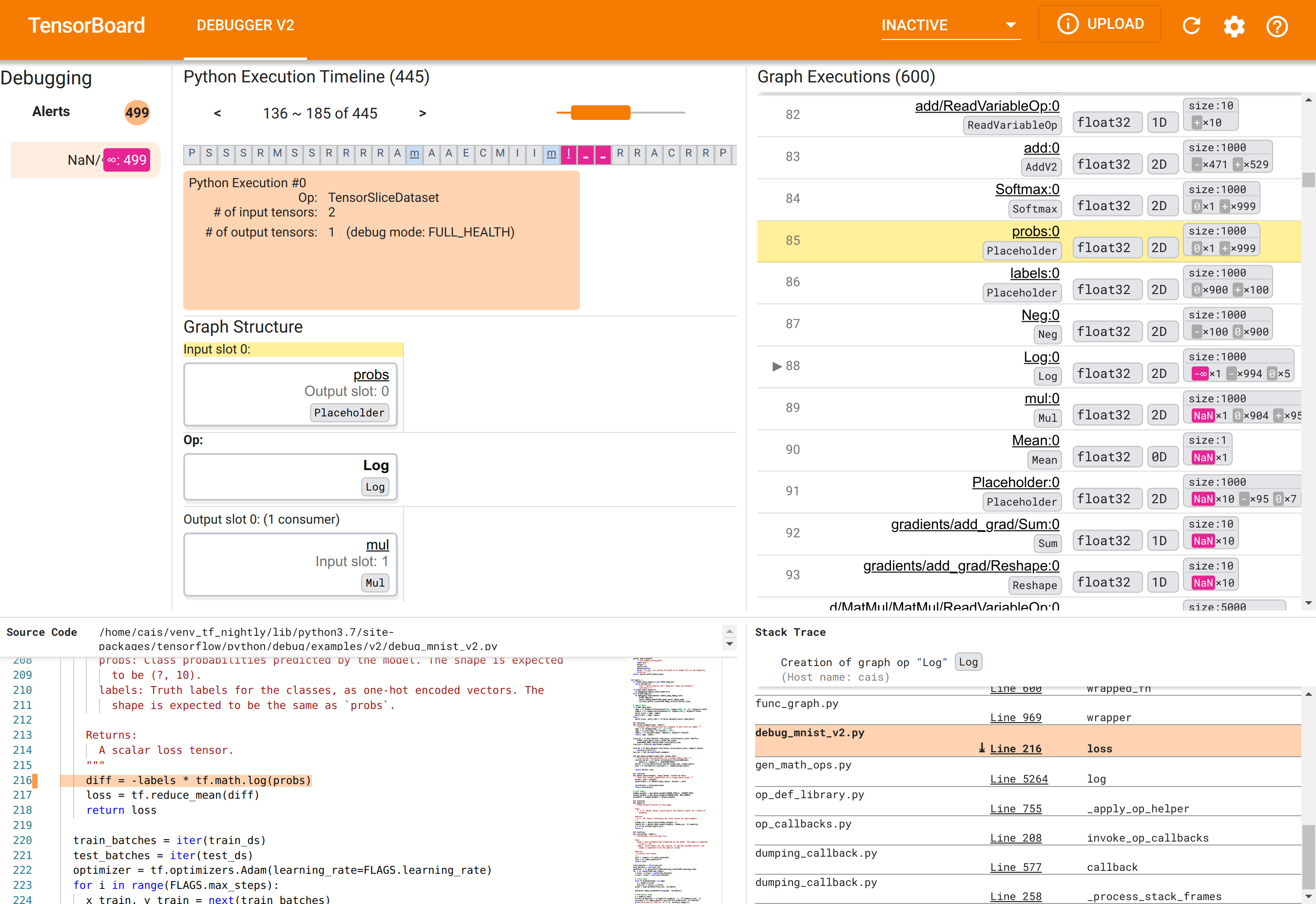
Debugger V2 GUI در TensorBoard به شش بخش سازماندهی شده است:
- هشدارها : این بخش بالا سمت چپ حاوی لیستی از رویدادهای "هشدار" است که توسط دیباگر در داده های اشکال زدایی از برنامه TensorFlow ابزاری شناسایی شده است. هر هشدار نشان دهنده یک ناهنجاری خاص است که توجه را ضروری می کند. در مورد ما، این بخش 499 رویداد NaN/∞ را با رنگ صورتی مایل به قرمز برجسته می کند. این ظن ما را تأیید میکند که مدل به دلیل وجود NaNs و/یا بینهایتها در مقادیر تانسور داخلیاش نمیتواند یاد بگیرد. به زودی به بررسی این هشدارها خواهیم پرداخت.
- جدول زمانی اجرای پایتون : این قسمت نیمه بالایی بخش بالا و میانی است. این تاریخچه کامل از اجرای مشتاقانه عملیات و نمودارها را ارائه می دهد. هر کادر از جدول زمانی با حرف اولیه عملیات یا نام گراف مشخص میشود (مثلاً «T» برای «TensorSliceDataset» عملیات، «m» برای «مدل»
tf.function). ما میتوانیم با استفاده از دکمههای پیمایش و نوار اسکرول بالای جدول زمانی در این خط زمانی حرکت کنیم. - اجرای نمودار : این بخش که در گوشه سمت راست بالای رابط کاربری گرافیکی قرار دارد، مرکزی برای رفع اشکال ما خواهد بود. این شامل تاریخچه ای از تمام تانسورهای نوع d شناور است که در داخل نمودارها محاسبه شده اند (یعنی توسط
@tf-functions کامپایل شده اند). - ساختار نمودار (نیمه پایین بخش میانی بالا)، کد منبع (بخش پایین-چپ)، و ردیابی پشته (بخش پایین-راست) در ابتدا خالی هستند. وقتی با رابط کاربری گرافیکی تعامل داشته باشیم، محتوای آنها پر می شود. این سه بخش همچنین نقش مهمی در کار اشکال زدایی ما خواهند داشت.
با توجه به سازماندهی رابط کاربری، بیایید مراحل زیر را انجام دهیم تا به علت پیدایش NaN ها پی ببریم. ابتدا روی هشدار NaN/∞ در قسمت Alerts کلیک کنید. این به طور خودکار لیست 600 تانسور گراف را در بخش Graph Execution پیمایش می کند و بر روی 88# تمرکز می کند که تانسوری به نام Log:0 است که توسط یک Log (لگاریتم طبیعی) تولید می شود. رنگ صورتی-قرمز برجسته یک عنصر -∞ را در بین 1000 عنصر تانسور 2 بعدی float32 برجسته می کند. این اولین تانسور در تاریخ اجرای برنامه TF2 است که حاوی هر گونه NaN یا بی نهایت است: تانسورهایی که قبل از آن محاسبه شده اند حاوی NaN یا ∞ نیستند. بسیاری از (در واقع، بیشتر) تانسورهایی که پس از آن محاسبه می شوند حاوی NaN هستند. میتوانیم با بالا و پایین کردن لیست Graph Execution این موضوع را تأیید کنیم. این مشاهدات یک اشاره قوی ارائه می دهد که عملیات Log منبع بی ثباتی عددی در این برنامه TF2 است.
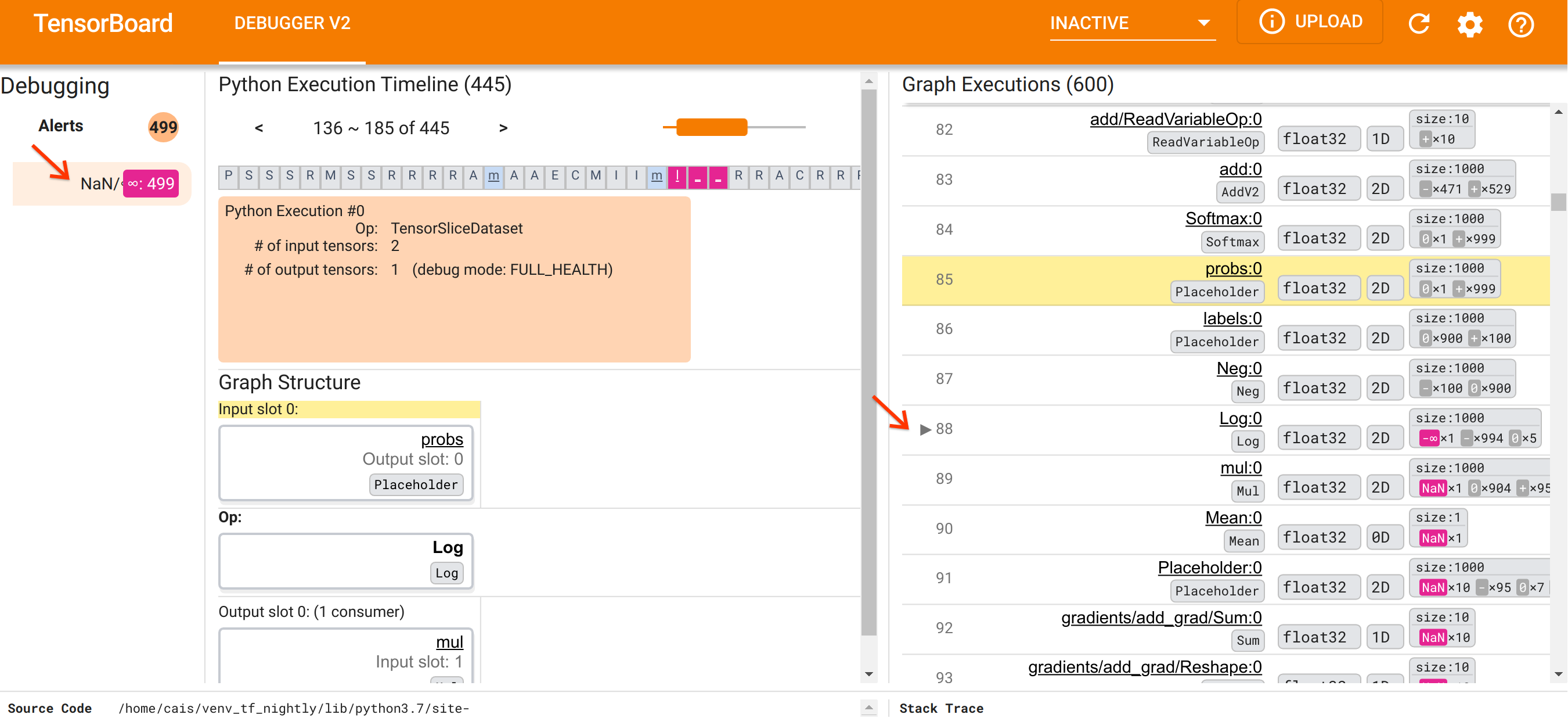
چرا این عملیات Log یک -∞ را بیرون می زند؟ پاسخ به این سوال مستلزم بررسی ورودی عملیات است. با کلیک بر روی نام تانسور ( Log:0 ) یک تصویر ساده اما آموزنده از مجاورت Log op در نمودار TensorFlow آن در بخش Graph Structure نمایش داده می شود. به جهت بالا به پایین جریان اطلاعات توجه کنید. خود عملیات به صورت پررنگ در وسط نشان داده شده است. بلافاصله در بالای آن، میتوانیم یک عملیات Placeholder را ببینیم که یک و تنها ورودی را به عملیات Log ارائه میکند. تانسور تولید شده توسط این مکانگردان probs در لیست اجرای نمودار کجاست؟ با استفاده از رنگ پس زمینه زرد به عنوان کمک بصری، می بینیم که تانسور probs:0 سه ردیف بالاتر از Log:0 است، یعنی در ردیف 85.
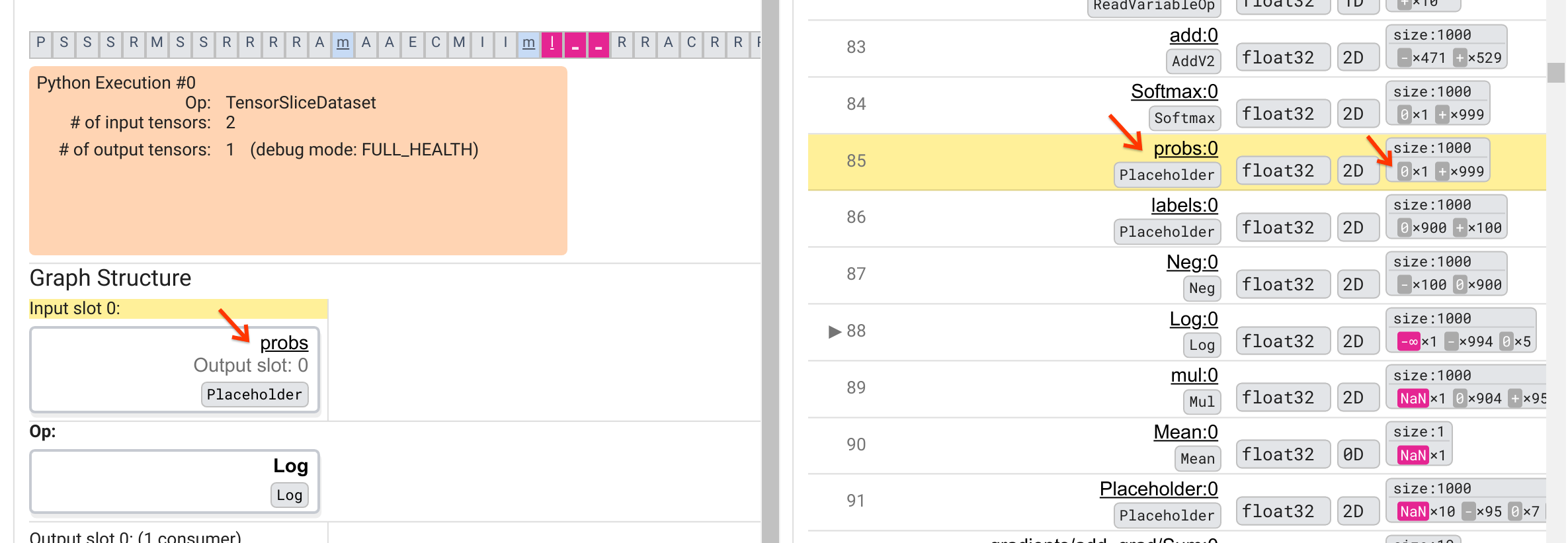
یک نگاه دقیق تر به تفکیک عددی تانسور probs:0 در ردیف 85 نشان می دهد که چرا مصرف کننده آن Log:0 یک -∞ تولید می کند: از بین 1000 عنصر probs:0 ، یک عنصر دارای مقدار 0 است. -∞ برابر است با نتیجه محاسبه لگاریتم طبیعی 0! اگر بتوانیم به نحوی اطمینان حاصل کنیم که عملیات Log فقط در معرض ورودیهای مثبت قرار میگیرد، میتوانیم از وقوع NaN/∞ جلوگیری کنیم. این را می توان با اعمال برش (به عنوان مثال، با استفاده از tf.clip_by_value() ) در تانسور probs Placeholder به دست آورد.
ما به حل این اشکال نزدیک تر می شویم، اما هنوز کاملاً انجام نشده است. برای اعمال اصلاح، باید بدانیم که در کد منبع پایتون، Log op و ورودی Placeholder آن از کجا سرچشمه گرفته است. Debugger V2 پشتیبانی درجه یک را برای ردیابی عملیات گراف و رویدادهای اجرا در منبع آنها فراهم می کند. وقتی روی تانسور Log:0 در Graph Executions کلیک کردیم، بخش Stack Trace با stack trace اصلی ایجاد Log op پر شد. ردیابی پشته تا حدودی بزرگ است زیرا شامل فریم های زیادی از کد داخلی TensorFlow است (به عنوان مثال، gen_math_ops.py و dumping_callback.py)، که ما می توانیم با خیال راحت برای اکثر وظایف اشکال زدایی از آنها چشم پوشی کنیم. فریم مورد علاقه، خط 216 از debug_mnist_v2.py است (یعنی فایل پایتون که ما در واقع سعی در رفع اشکال داریم). با کلیک بر روی "خط 216" نمایی از خط کد مربوطه در بخش کد منبع ظاهر می شود.
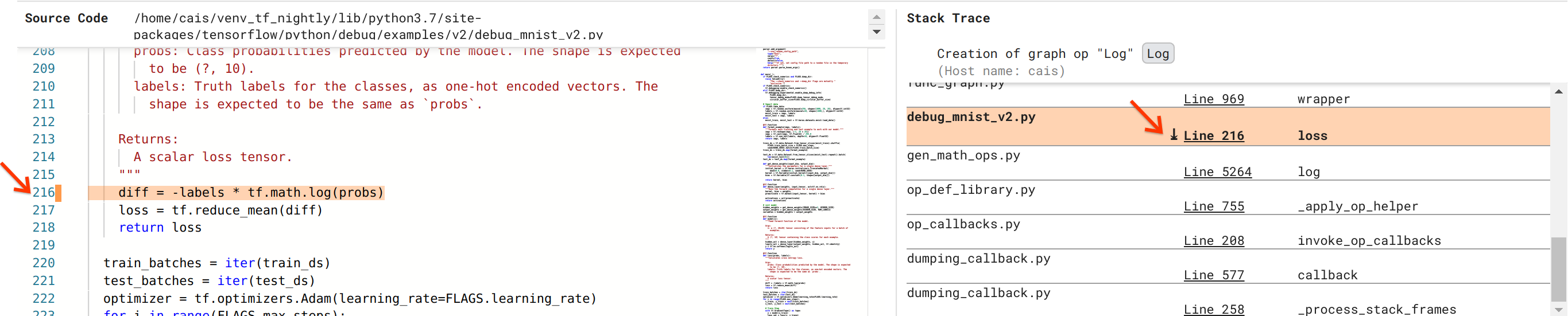
این در نهایت ما را به کد منبعی میرساند که عملیات Log مشکلساز را از ورودی probs آن ایجاد کرده است. این تابع از دست دادن متقابل آنتروپی طبقهبندی شده سفارشی ما است که با @tf.function تزئین شده و از این رو به یک نمودار TensorFlow تبدیل شده است. probs op Placeholder با اولین آرگومان ورودی تابع ضرر مطابقت دارد. عملیات Log با فراخوانی API tf.math.log() ایجاد می شود.
اصلاح ارزش برش برای این باگ چیزی شبیه به این خواهد بود:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
این بی ثباتی عددی در این برنامه TF2 را برطرف می کند و باعث می شود MLP با موفقیت آموزش ببیند. روش ممکن دیگر برای رفع ناپایداری عددی استفاده از tf.keras.losses.CategoricalCrossentropy است.
این امر سفر ما را از مشاهده یک اشکال مدل TF2 تا رسیدن به تغییر کدی که باگ را برطرف میکند، به کمک ابزار Debugger V2، پایان میدهد، که دید کاملی را به تاریخچه اجرای مشتاق و گراف برنامه TF2 ابزاردار، از جمله خلاصههای عددی، ارائه میکند. مقادیر تانسور و ارتباط بین عملیات، تانسور و کد منبع اصلی آنها.
سازگاری سخت افزاری Debugger V2
Debugger V2 از سخت افزار اصلی آموزشی از جمله CPU و GPU پشتیبانی می کند. آموزش Multi-GPU با tf.distributed.MirroredStrategy نیز پشتیبانی می شود. پشتیبانی از TPU هنوز در مرحله اولیه است و نیاز به تماس دارد
tf.config.set_soft_device_placement(True)
قبل از فراخوانی enable_dump_debug_info() . ممکن است محدودیت های دیگری در TPU ها نیز داشته باشد. اگر در استفاده از Debugger V2 با مشکل مواجه شدید، لطفاً اشکالات را در صفحه مشکلات GitHub ما گزارش دهید.
سازگاری API Debugger V2
Debugger V2 در سطح نسبتاً پایینی از پشته نرم افزار TensorFlow پیاده سازی شده است و از این رو با tf.keras ، tf.data و دیگر APIهای ساخته شده در بالای سطوح پایین تر TensorFlow سازگار است. Debugger V2 همچنین با TF1 سازگار است، اگرچه Eager Execution Timeline برای لاگ دیباگ های ایجاد شده توسط برنامه های TF1 خالی خواهد بود.
نکات استفاده از API
یک سوال متداول در مورد این API اشکال زدایی این است که در کد TensorFlow باید فراخوانی enable_dump_debug_info() وارد کرد. به طور معمول، API باید هرچه زودتر در برنامه TF2 شما فراخوانی شود، ترجیحاً بعد از خطوط واردات پایتون و قبل از شروع ساخت و اجرای نمودار. این امر پوشش کامل تمام عملیات ها و نمودارهایی را که مدل شما و آموزش آن را تقویت می کنند، تضمین می کند.
حالتهای tensor_debug_در حال حاضر پشتیبانی شده عبارتند از: NO_TENSOR ، CURT_HEALTH ، CONCISE_HEALTH ، FULL_HEALTH ، و SHAPE . آنها در مقدار اطلاعات استخراج شده از هر تانسور و سربار عملکرد برنامه اشکال زدایی متفاوت هستند. لطفاً به بخش args در مستندات enable_dump_debug_info() مراجعه کنید.
سربار عملکرد
API اشکال زدایی سربار عملکرد را به برنامه TensorFlow ابزاری معرفی می کند. سربار بر اساس tensor_debug_mode ، نوع سخت افزار، و ماهیت برنامه TensorFlow ابزاری متفاوت است. به عنوان یک نقطه مرجع، در یک پردازنده گرافیکی، حالت NO_TENSOR در طول آموزش یک مدل ترانسفورماتور با اندازه دسته ای 64، 15٪ سربار اضافه می کند. درصد سربار برای سایر حالت های tensor_debug بیشتر است: تقریباً 50٪ برای CURT_HEALTH ، CONCISE_HEALTH ، FULL_HEALTH و SHAPE حالت ها در CPU ها، سربار کمی کمتر است. در TPU ها، سربار در حال حاضر بیشتر است.
ارتباط با سایر APIهای رفع اشکال TensorFlow
توجه داشته باشید که TensorFlow ابزارها و API های دیگری را برای اشکال زدایی ارائه می دهد. می توانید چنین API هایی را در فضای نام tf.debugging.* در صفحه اسناد API مرور کنید. در میان این APIها، پرکاربردترین tf.print() است. چه زمانی باید از Debugger V2 استفاده کرد و چه زمانی باید tf.print() به جای آن استفاده کرد؟ tf.print() در مواردی مناسب است
- ما دقیقا می دانیم کدام تانسورها را چاپ کنیم،
- ما دقیقاً می دانیم که در کد منبع باید آن عبارات
tf.print()درج کنیم، - تعداد چنین تانسورهایی خیلی زیاد نیست.
برای موارد دیگر (به عنوان مثال، بررسی بسیاری از مقادیر تانسور، بررسی مقادیر تانسور تولید شده توسط کد داخلی TensorFlow، و جستجوی منشا بی ثباتی عددی همانطور که در بالا نشان دادیم)، Debugger V2 راه سریع تری برای اشکال زدایی ارائه می دهد. علاوه بر این، Debugger V2 یک رویکرد یکپارچه برای بازرسی تانسورهای مشتاق و گراف ارائه می دهد. علاوه بر این اطلاعاتی در مورد ساختار گراف و مکان های کد ارائه می دهد که فراتر از قابلیت tf.print() است.
API دیگری که می تواند برای اشکال زدایی مسائل مربوط به ∞ و NaN استفاده شود tf.debugging.enable_check_numerics() است. برخلاف enable_dump_debug_info() ، enable_check_numerics() اطلاعات اشکال زدایی را روی دیسک ذخیره نمی کند. در عوض، صرفاً ∞ و NaN را در طول زمان اجرا TensorFlow نظارت میکند و به محض اینکه هر عملیاتی چنین مقادیر عددی بدی را تولید میکند، در محل کد مبدا خطا میکند. در مقایسه با enable_dump_debug_info() سربار کارایی پایین تری دارد، اما ردیابی کاملی از تاریخچه اجرای برنامه ندارد و دارای یک رابط کاربری گرافیکی مانند Debugger V2 نیست.