
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
tf.data API شما را قادر می سازد خطوط لوله ورودی پیچیده ای را از قطعات ساده و قابل استفاده مجدد بسازید. برای مثال، خط لوله برای یک مدل تصویر ممکن است دادهها را از فایلها در یک سیستم فایل توزیع شده جمعآوری کند، اختلالات تصادفی را برای هر تصویر اعمال کند، و تصاویر انتخابی تصادفی را در یک دسته برای آموزش ادغام کند. خط لوله برای یک مدل متنی ممکن است شامل استخراج نمادها از دادههای متن خام، تبدیل آنها به شناسههای جاسازی شده با یک جدول جستجو، و دستهبندی توالیهایی با طولهای مختلف باشد. tf.data API مدیریت حجم زیادی از داده ها، خواندن از فرمت های مختلف داده و انجام تبدیل های پیچیده را ممکن می سازد.
tf.data API یک انتزاع tf.data.Dataset را معرفی می کند که نشان دهنده دنباله ای از عناصر است که در آن هر عنصر از یک یا چند جزء تشکیل شده است. به عنوان مثال، در خط لوله تصویر، یک عنصر ممکن است یک نمونه آموزشی واحد باشد، با یک جفت مولفه تانسور که تصویر و برچسب آن را نشان می دهد.
دو روش متمایز برای ایجاد مجموعه داده وجود دارد:
یک منبع داده یک
Datasetرا از داده های ذخیره شده در حافظه یا در یک یا چند فایل می سازد.تبدیل داده یک مجموعه داده را از یک یا چند شی
tf.data.Datasetمی سازد.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
مکانیک پایه
برای ایجاد خط لوله ورودی، باید با یک منبع داده شروع کنید. به عنوان مثال، برای ساخت Dataset از داده های موجود در حافظه، می توانید از tf.data.Dataset.from_tensors() یا tf.data.Dataset.from_tensor_slices() استفاده کنید. همچنین، اگر داده های ورودی شما در فایلی با فرمت TFRecord توصیه شده ذخیره شده است، می توانید از tf.data.TFRecordDataset() استفاده کنید.
هنگامی که یک آبجکت Dataset دارید، میتوانید آن را با استفاده از روش زنجیرهای بر روی شی tf.data.Dataset به یک Dataset جدید تبدیل کنید. برای مثال، میتوانید تبدیلهای هر عنصر مانند Dataset.map() و تبدیلهای چند عنصری مانند Dataset.batch() را اعمال کنید. برای فهرست کامل تغییرات، به مستندات tf.data.Dataset مراجعه کنید.
شی Dataset یک Python قابل تکرار است. این باعث می شود که عناصر آن با استفاده از یک حلقه for مصرف شود:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
یا با ایجاد صریح یک تکرار کننده پایتون با استفاده از iter و مصرف عناصر next با استفاده از زیر:
it = iter(dataset)
print(next(it).numpy())
8
از طرف دیگر، عناصر مجموعه داده را می توان با استفاده از تبدیل reduce مصرف کرد، که همه عناصر را کاهش می دهد تا یک نتیجه واحد ایجاد شود. مثال زیر نحوه استفاده از تبدیل reduce را برای محاسبه مجموع مجموعه داده ای از اعداد صحیح نشان می دهد.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
ساختار مجموعه داده
یک مجموعه داده دنباله ای از عناصر را تولید می کند که در آن هر عنصر همان ساختار (تودرتو) اجزاء است. اجزای منفرد ساختار می توانند از هر نوع قابل نمایش با tf.TypeSpec ، از جمله tf.Tensor ، tf.sparse.SparseTensor ، tf.RaggedTensor ، tf.TensorArray ، یا tf.data.Dataset .
ساختارهای پایتون که میتوانند برای بیان ساختار (تودرتو) عناصر استفاده شوند عبارتند از: tuple ، dict ، NamedTuple و OrderedDict . به طور خاص، list یک ساختار معتبر برای بیان ساختار عناصر مجموعه نیست. این به این دلیل است که کاربران اولیه tf.data به شدت احساس میکردند که ورودیهای list (مثلاً به tf.data.Dataset.from_tensors ) که بهطور خودکار بهعنوان تانسور بستهبندی میشوند و خروجیهای list (مثلاً مقادیر بازگشتی توابع تعریفشده توسط کاربر) مجبور به تبدیل شدن به یک tuple هستند. در نتیجه، اگر میخواهید یک ورودی list به عنوان یک ساختار در نظر گرفته شود، باید آن را به چند tf.stack تبدیل کنید و اگر میخواهید خروجی list یک جزء باشد، باید صریحاً آن را با استفاده از tuple بسته بندی کنید. .
ویژگی Dataset.element_spec به شما اجازه می دهد تا نوع هر جزء عنصر را بررسی کنید. این ویژگی یک ساختار تودرتو از اشیاء tf.TypeSpec را برمیگرداند که با ساختار عنصر مطابقت دارد، که ممکن است یک مؤلفه منفرد، چند مؤلفه یا چند مؤلفه تو در تو باشد. مثلا:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
تبدیل های Dataset داده از مجموعه داده های هر ساختاری پشتیبانی می کند. هنگام استفاده از تبدیل های Dataset.map() و Dataset.filter() که یک تابع را برای هر عنصر اعمال می کنند، ساختار عنصر آرگومان های تابع را تعیین می کند:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
خواندن داده های ورودی
مصرف آرایه های NumPy
برای مثالهای بیشتر به بارگیری آرایههای NumPy مراجعه کنید.
اگر همه دادههای ورودی شما در حافظه جا میشوند، سادهترین راه برای ایجاد Dataset از آنها این است که آنها را به اشیاء tf.Tensor تبدیل کنید و از Dataset.from_tensor_slices() استفاده کنید.
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
مصرف مولدهای پایتون
یکی دیگر از منابع داده رایج که می تواند به راحتی به عنوان tf.data.Dataset جذب شود، مولد پایتون است.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
سازنده Dataset.from_generator مولد پایتون را به یک tf.data.Dataset کاملاً کاربردی تبدیل می کند.
سازنده یک فراخوانی را به عنوان ورودی می گیرد، نه یک تکرار کننده. این به آن اجازه می دهد تا زمانی که ژنراتور به پایان رسید دوباره راه اندازی شود. یک args اختیاری می گیرد که به عنوان آرگومان های فراخوانی ارسال می شود.
آرگومان output_types مورد نیاز است زیرا tf.data یک tf.Graph را در داخل میسازد و لبههای گراف به tf.dtype نیاز دارند.
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
آرگومان output_shapes مورد نیاز نیست، اما به شدت توصیه می شود زیرا بسیاری از عملیات TensorFlow از تانسورهایی با رتبه ناشناخته پشتیبانی نمی کنند. اگر طول یک محور خاص ناشناخته یا متغیر است، آن را به عنوان None در output_shapes کنید.
همچنین مهم است که توجه داشته باشید که output_shapes و output_types از قوانین تودرتو مانند سایر روشهای مجموعه پیروی میکنند.
در اینجا یک مولد مثال است که هر دو جنبه را نشان می دهد، چندین آرایه را برمی گرداند، که در آن آرایه دوم یک برداری با طول ناشناخته است.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
خروجی اول int32 و دومی float32 است.
مورد اول یک عدد اسکالر، شکل () و دومی یک بردار با طول مجهول، شکل (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
اکنون می توان از آن مانند یک tf.data.Dataset معمولی استفاده کرد. توجه داشته باشید که هنگام دستهبندی یک مجموعه داده با شکل متغیر، باید از Dataset.padded_batch استفاده کنید.
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
برای مثال واقعی تر، سعی کنید preprocessing.image.ImageDataGenerator را به عنوان tf.data.Dataset قرار دهید.
ابتدا داده ها را دانلود کنید:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
image.ImageDataGenerator را ایجاد کنید
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
مصرف داده های TFRecord
برای مثال سرتاسر به بارگیری TFRecords مراجعه کنید.
tf.data API از انواع فرمت های فایل پشتیبانی می کند تا بتوانید مجموعه داده های بزرگی را که در حافظه جا نمی شوند پردازش کنید. به عنوان مثال، فرمت فایل TFRecord یک فرمت باینری رکورد محور ساده است که بسیاری از برنامه های TensorFlow برای آموزش داده ها از آن استفاده می کنند. کلاس tf.data.TFRecordDataset شما را قادر می سازد تا محتوای یک یا چند فایل TFRecord را به عنوان بخشی از خط لوله ورودی به جریان بیاندازید.
در اینجا یک مثال با استفاده از فایل آزمایشی از علائم نام خیابان فرانسوی (FSNS) آورده شده است.
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
آرگومان filenames به مقدار اولیه TFRecordDataset می تواند یک رشته، یک لیست از رشته ها یا یک tf.Tensor از رشته ها باشد. بنابراین اگر دو مجموعه فایل برای اهداف آموزشی و اعتبارسنجی دارید، می توانید یک متد کارخانه ای ایجاد کنید که مجموعه داده را تولید می کند و نام فایل ها را به عنوان آرگومان ورودی در نظر می گیرد:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
بسیاری از پروژه های TensorFlow از رکوردهای سریالی tf.train.Example در فایل های TFRecord خود استفاده می کنند. اینها قبل از بازرسی باید رمزگشایی شوند:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
مصرف داده های متنی
برای مثال به بارگیری متن مراجعه کنید.
بسیاری از مجموعه داده ها به صورت یک یا چند فایل متنی توزیع می شوند. tf.data.TextLineDataset یک راه آسان برای استخراج خطوط از یک یا چند فایل متنی فراهم می کند. با توجه به یک یا چند نام فایل، یک TextLineDataset یک عنصر با ارزش رشته ای در هر خط از آن فایل ها تولید می کند.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
در اینجا چند خط اول فایل اول آمده است:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
برای جایگزین کردن خطوط بین فایل ها از Dataset.interleave استفاده کنید. این کار به هم زدن فایل ها با هم آسان تر می شود. در اینجا سطرهای اول، دوم و سوم هر ترجمه آمده است:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
به طور پیش فرض، یک TextLineDataset هر خط از هر فایل را به دست می دهد، که ممکن است مطلوب نباشد، برای مثال، اگر فایل با یک خط سرصفحه شروع شود یا حاوی نظرات باشد. این خطوط را می توان با استفاده از تبدیل های Dataset.skip() یا Dataset.filter() حذف کرد. در اینجا، شما خط اول را رد می کنید، سپس فیلتر می کنید تا فقط بازماندگان را پیدا کنید.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
مصرف داده های CSV
برای مثالهای بیشتر، بارگیری فایلهای CSV و بارگیری قابهای داده پاندا را ببینید.
فرمت فایل CSV یک فرمت محبوب برای ذخیره داده های جدولی در متن ساده است.
مثلا:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
اگر دادههای شما در حافظه جای میگیرد، همان روش Dataset.from_tensor_slices روی دیکشنریها کار میکند و اجازه میدهد این دادهها به راحتی وارد شوند:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
یک رویکرد مقیاس پذیرتر بارگذاری از دیسک در صورت لزوم است.
ماژول tf.data روش هایی را برای استخراج رکوردها از یک یا چند فایل CSV ارائه می دهد که با RFC 4180 مطابقت دارند.
تابع experimental.make_csv_dataset رابط سطح بالایی برای خواندن مجموعهای از فایلهای csv است. این استنتاج نوع ستون و بسیاری از ویژگیهای دیگر، مانند دستهبندی و درهم ریختن، برای سادهتر کردن استفاده را پشتیبانی میکند.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
اگر فقط به زیر مجموعه ای از ستون ها نیاز دارید، می توانید از آرگومان select_columns استفاده کنید.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
همچنین یک کلاس experimental.CsvDataset سطح پایین تر وجود دارد که کنترل دانه بندی دقیق تری را ارائه می دهد. این استنتاج نوع ستون را پشتیبانی نمی کند. در عوض باید نوع هر ستون را مشخص کنید.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
اگر برخی از ستون ها خالی هستند، این رابط سطح پایین به شما امکان می دهد مقادیر پیش فرض را به جای انواع ستون ها ارائه دهید.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
بهطور پیشفرض، یک CsvDataset هر ستون از هر خط فایل را به دست میدهد، که ممکن است مطلوب نباشد، برای مثال اگر فایل با یک خط سرصفحه شروع میشود که باید نادیده گرفته شود، یا اگر برخی از ستونها در ورودی لازم نباشد. این خطوط و فیلدها را می توان به ترتیب با آرگومان های header و select_cols حذف کرد.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
مصرف مجموعه ای از فایل ها
مجموعه دادههای زیادی وجود دارد که به صورت مجموعهای از فایلها توزیع میشوند که هر فایل یک نمونه است.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
دایرکتوری ریشه شامل یک دایرکتوری برای هر کلاس است:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
فایل های موجود در هر دایرکتوری کلاس نمونه هایی هستند:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
داده ها را با استفاده از تابع tf.io.read_file و برچسب را از مسیر استخراج کنید و جفت های (image, label) را برگردانید:
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
دسته بندی عناصر مجموعه داده
دسته بندی ساده
سادهترین شکل دستهبندی n عنصر متوالی از یک مجموعه داده در یک عنصر واحد. تبدیل Dataset.batch() دقیقاً این کار را انجام میدهد، با همان محدودیتهایی که tf.stack() برای هر جزء از عناصر اعمال میشود: یعنی برای هر جزء i ، همه عناصر باید یک تانسور دقیقاً یکسان داشته باشند.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
در حالی که tf.data سعی میکند اطلاعات شکل را منتشر کند، تنظیمات پیشفرض Dataset.batch به یک اندازه دسته ناشناخته منجر میشود، زیرا ممکن است آخرین دسته پر نباشد. به None ها در شکل توجه کنید:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
از آرگومان drop_remainder برای نادیده گرفتن آخرین دسته استفاده کنید و انتشار شکل کامل را دریافت کنید:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
دسته بندی تانسورها با بالشتک
دستور العمل فوق برای تانسورهایی که همه اندازه یکسانی دارند کار می کند. با این حال، بسیاری از مدلها (مثلاً مدلهای دنبالهای) با دادههای ورودی کار میکنند که میتوانند اندازههای متفاوتی داشته باشند (مثلاً دنبالههایی با طولهای مختلف). برای رسیدگی به این مورد، تبدیل Dataset.padded_batch شما را قادر میسازد تا تانسورهایی با شکلهای مختلف را با مشخص کردن یک یا چند بعد که ممکن است در آنها قرار داده شوند، دستهبندی کنید.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
تبدیل Dataset.padded_batch به شما این امکان را می دهد که برای هر بعد از هر جزء، padding های متفاوتی را تنظیم کنید، و ممکن است طول متغیر (در مثال بالا با None مشخص شده است) یا طول ثابت باشد. همچنین میتوان مقدار padding را که پیشفرض 0 است، نادیده گرفت.
گردش کار آموزشی
پردازش چند دوره
tf.data API دو روش اصلی برای پردازش چندین دوره از یک داده ارائه می دهد.
ساده ترین راه برای تکرار روی یک مجموعه داده در چند دوره، استفاده از تبدیل Dataset.repeat() است. ابتدا یک مجموعه داده از داده های تایتانیک ایجاد کنید:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
اعمال تبدیل Dataset.repeat() بدون هیچ آرگومان ورودی را به طور نامحدود تکرار می کند.
تبدیل Dataset.repeat آرگومان های خود را بدون علامت دادن به پایان یک دوره و آغاز دوره بعدی به هم متصل می کند. به همین دلیل، یک Dataset.batch که بعد از Dataset.repeat اعمال میشود، دستههایی را به دست میدهد که در محدودههای دوره قرار دارند:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
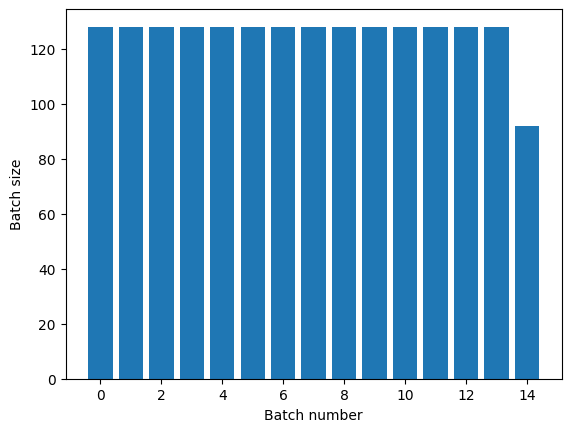
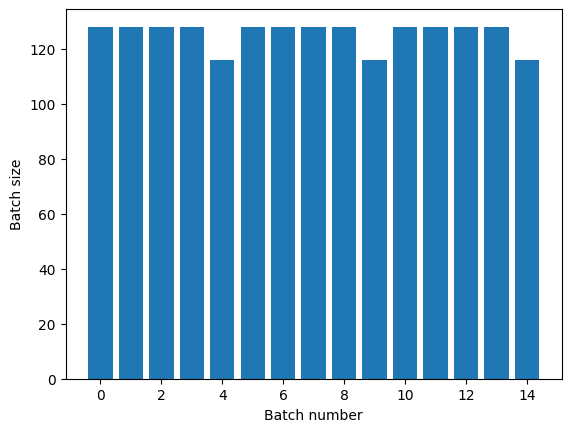
اگر به جداسازی دوره ای واضح نیاز دارید، Dataset.batch را قبل از تکرار قرار دهید:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
اگر میخواهید یک محاسبات سفارشی (مثلاً برای جمعآوری آمار) در پایان هر دوره انجام دهید، سادهترین کار این است که تکرار مجموعه دادهها را در هر دوره مجدداً راهاندازی کنید:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
به طور تصادفی داده های ورودی را به هم می زنند
تبدیل Dataset.shuffle() یک بافر با اندازه ثابت نگه می دارد و عنصر بعدی را به طور یکنواخت به صورت تصادفی از آن بافر انتخاب می کند.
یک شاخص به مجموعه داده اضافه کنید تا بتوانید اثر را ببینید:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
از آنجایی که buffer_size 100 و اندازه دسته 20 است، اولین دسته حاوی هیچ عنصری با شاخص بیش از 120 نیست.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
مانند Dataset.batch ، ترتیب مربوط به Dataset.repeat اهمیت دارد.
Dataset.shuffle تا زمانی که بافر shuffle خالی نشود، پایان یک دوره را نشان نمی دهد. بنابراین، مخلوطی که قبل از تکرار قرار میگیرد، هر عنصر یک دوره را قبل از انتقال به دوره بعدی نشان میدهد:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
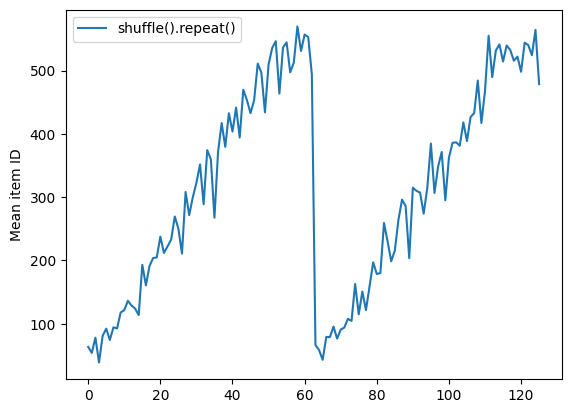
اما تکرار قبل از یک مخلوط کردن، مرزهای دوران را با هم مخلوط می کند:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
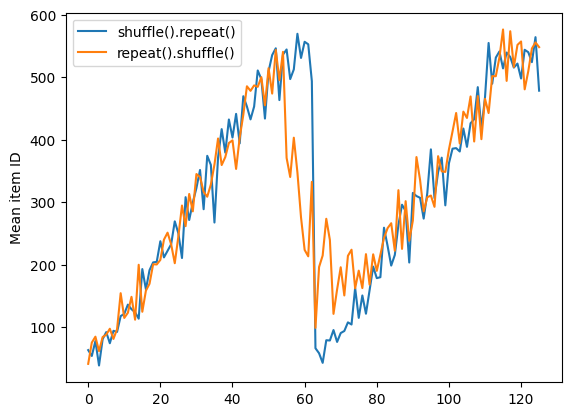
پیش پردازش داده ها
تبدیل Dataset.map(f) یک مجموعه داده جدید را با اعمال تابع f به هر عنصر از مجموعه داده ورودی تولید می کند. این تابع بر اساس تابع map() است که معمولاً برای لیست ها (و سایر ساختارها) در زبان های برنامه نویسی تابعی اعمال می شود. تابع f اشیاء tf.Tensor را می گیرد که یک عنصر را در ورودی نشان می دهند و اشیاء tf.Tensor را که یک عنصر را در مجموعه داده جدید نشان می دهند، برمی گرداند. اجرای آن از عملیات استاندارد TensorFlow برای تبدیل یک عنصر به عنصر دیگر استفاده می کند.
این بخش نمونه های رایج نحوه استفاده از Dataset.map() را پوشش می دهد.
رمزگشایی داده های تصویر و تغییر اندازه آن
هنگام آموزش یک شبکه عصبی بر روی دادههای تصویر دنیای واقعی، اغلب لازم است تصاویر با اندازههای مختلف به یک اندازه مشترک تبدیل شوند، به طوری که ممکن است به یک اندازه ثابت تبدیل شوند.
مجموعه داده نام فایل گل را بازسازی کنید:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
تابعی بنویسید که عناصر مجموعه داده را دستکاری کند.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
تست کنید که کار می کند.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

آن را روی مجموعه داده نقشه برداری کنید.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


استفاده از منطق پایتون دلخواه
به دلایل عملکرد، در صورت امکان از عملیات TensorFlow برای پیش پردازش داده های خود استفاده کنید. با این حال، گاهی اوقات فراخوانی کتابخانه های خارجی پایتون هنگام تجزیه داده های ورودی مفید است. می توانید از عملیات tf.py_function() Dataset.map() در تبدیل Dataset.map() استفاده کنید.
برای مثال، اگر میخواهید چرخش تصادفی اعمال کنید، ماژول tf.image فقط tf.image.rot90 دارد که برای تقویت تصویر چندان مفید نیست.
برای نشان دادن tf.py_function ، به جای آن از تابع scipy.ndimage.rotate استفاده کنید:
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

برای استفاده از این تابع با Dataset.map همان اخطارهایی که در Dataset.from_generator اعمال می شود، باید اشکال و انواع برگشتی را هنگام اعمال تابع توصیف کنید:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


تجزیه پیام های بافر پروتکل tf.Example
بسیاری از خطوط لوله ورودی پیام های بافر پروتکل tf.train.Example را از فرمت TFRecord استخراج می کنند. هر رکورد tf.train.Example حاوی یک یا چند "ویژگی" است و خط لوله ورودی معمولا این ویژگی ها را به تانسور تبدیل می کند.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
برای درک داده ها می توانید با tf.train.Example tf.train.Example خارج از tf.data.Dataset کار کنید:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
پنجره سری زمانی
برای پایان به پایان سری های زمانی مثال ببینید: پیش بینی سری های زمانی .
داده های سری زمانی اغلب با دست نخورده بودن محور زمانی سازماندهی می شوند.
از یک Dataset.range ساده برای نشان دادن استفاده کنید:
range_ds = tf.data.Dataset.range(100000)
به طور معمول، مدل های مبتنی بر این نوع داده ها یک برش زمانی پیوسته می خواهند.
ساده ترین روش جمع آوری داده ها است:
با استفاده از batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
یا برای انجام پیشبینیهای متراکم در یک قدمی آینده، ممکن است ویژگیها و برچسبها را یک مرحله نسبت به یکدیگر تغییر دهید:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
برای پیشبینی یک پنجره کامل به جای یک افست ثابت، میتوانید دستهها را به دو بخش تقسیم کنید:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
برای اجازه دادن مقداری همپوشانی بین ویژگیهای یک دسته و برچسبهای دسته دیگر، از Dataset.zip استفاده کنید:
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
با استفاده از window
در حالی که استفاده از Dataset.batch کار می کند، شرایطی وجود دارد که ممکن است به کنترل دقیق تری نیاز داشته باشید. متد Dataset.window به شما کنترل کامل می دهد، اما به دقت نیاز دارد: Dataset ای از Datasets داده ها را برمی گرداند. برای جزئیات بیشتر به ساختار مجموعه داده مراجعه کنید.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
متد Dataset.flat_map می تواند مجموعه داده ای از مجموعه داده ها را گرفته و آن را در یک مجموعه داده واحد مسطح کند:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
تقریباً در همه موارد، شما می خواهید ابتدا مجموعه داده را .batch کنید:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
اکنون، می توانید ببینید که آرگومان shift میزان حرکت هر پنجره را کنترل می کند.
با کنار هم گذاشتن این تابع می توانید این تابع را بنویسید:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
سپس استخراج برچسب ها مانند قبل آسان است:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
نمونه گیری مجدد
هنگام کار با مجموعه داده ای که از نظر کلاس بسیار نامتعادل است، ممکن است بخواهید مجموعه داده را مجدداً نمونه برداری کنید. tf.data دو روش برای این کار ارائه می دهد. مجموعه داده های کلاهبرداری کارت اعتباری نمونه خوبی از این نوع مشکلات است.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
اکنون، توزیع کلاس ها را بررسی کنید، بسیار کج است:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
یک رویکرد رایج برای آموزش با مجموعه داده نامتعادل، متعادل کردن آن است. tf.data شامل چند روش است که این گردش کار را فعال می کند:
نمونه گیری از مجموعه داده ها
یکی از روشهای نمونهگیری مجدد یک مجموعه داده، استفاده از sample_from_datasets است. این زمانی بیشتر کاربرد دارد که برای هر کلاس یک مجموعه داده جداگانه data.Dataset .
در اینجا، فقط از فیلتر برای تولید آنها از داده های کلاهبرداری کارت اعتباری استفاده کنید:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
برای استفاده از tf.data.Dataset.sample_from_datasets مجموعه داده ها و وزن هر کدام را ارسال کنید:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
اکنون مجموعه داده نمونه هایی از هر کلاس را با احتمال 50/50 تولید می کند:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
نمونه گیری مجدد رد
یکی از مشکلات روش Dataset.sample_from_datasets بالا این است که به یک tf.data.Dataset جداگانه برای هر کلاس نیاز دارد. شما می توانید از Dataset.filter برای ایجاد آن دو مجموعه داده استفاده کنید، اما این باعث می شود تمام داده ها دو بار بارگذاری شوند.
متد data.Dataset.rejection_resample را می توان روی یک مجموعه داده برای متعادل کردن مجدد آن اعمال کرد، در حالی که فقط یک بار بارگیری می شود. برای دستیابی به تعادل، عناصر از مجموعه داده حذف می شوند.
data.Dataset.rejection_resample یک آرگومان class_func می گیرد. این class_func برای هر عنصر مجموعه داده اعمال میشود و برای تعیین اینکه یک مثال برای اهداف متعادلسازی به کدام کلاس تعلق دارد، استفاده میشود.
هدف در اینجا متعادل کردن توزیع lable است و عناصر creditcard_ds از قبل (features, label) جفت هستند. بنابراین class_func فقط باید آن برچسب ها را برگرداند:
def class_func(features, label):
return label
روش unbatch با نمونههای جداگانه سروکار دارد، بنابراین در این مورد باید قبل از اعمال آن روش، مجموعه داده را جدا کنید.
این روش به توزیع هدف، و اختیاری یک تخمین توزیع اولیه به عنوان ورودی نیاز دارد.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
متد rejection_resample جفت هایی (class, example) را برمی گرداند که در آن class خروجی class_func است. در این مورد، example قبلاً یک جفت (feature, label) بود، بنابراین از map برای رها کردن کپی اضافی از برچسب ها استفاده کنید:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
اکنون مجموعه داده نمونه هایی از هر کلاس را با احتمال 50/50 تولید می کند:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
ایتراتور بازرسی
Tensorflow از گرفتن چک پوینتها پشتیبانی میکند تا زمانی که فرآیند آموزشی شما دوباره راهاندازی میشود، بتواند آخرین بازرسی را بازیابی کند تا بیشتر پیشرفت آن را بازیابی کند. علاوه بر چک کردن متغیرهای مدل، میتوانید پیشرفت تکرارکننده مجموعه داده را نیز بررسی کنید. این می تواند مفید باشد اگر مجموعه داده بزرگی دارید و نمی خواهید مجموعه داده را از ابتدا در هر راه اندازی مجدد شروع کنید. با این حال توجه داشته باشید که نقاط بازرسی تکرارکننده ممکن است بزرگ باشند، زیرا تبدیلهایی مانند shuffle و prefetch به عناصر بافر در تکرارکننده نیاز دارند.
برای گنجاندن تکرار کننده خود در یک چک پوینت، تکرار کننده را به سازنده tf.train.Checkpoint کنید.
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
استفاده از tf.data با tf.keras
tf.keras API بسیاری از جنبه های ایجاد و اجرای مدل های یادگیری ماشین را ساده می کند. API های .fit() و .evaluate() و .predict() از مجموعه داده ها به عنوان ورودی پشتیبانی می کنند. در اینجا مجموعه داده سریع و تنظیم مدل آمده است:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
ارسال مجموعه داده ای از جفت (feature, label) تمام چیزی است که برای Model.fit و Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
اگر یک مجموعه داده بی نهایت را ارسال کنید، برای مثال با فراخوانی Dataset.repeat() ، فقط باید آرگومان steps_per_epoch را نیز ارسال کنید:
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
برای ارزیابی می توانید تعدادی از مراحل ارزیابی را پشت سر بگذارید:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
برای مجموعه داده های طولانی، تعداد مراحل را برای ارزیابی تنظیم کنید:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
هنگام فراخوانی Model.predict به برچسب ها نیست.
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
اما اگر مجموعه داده ای حاوی آنها را ارسال کنید، برچسب ها نادیده گرفته می شوند:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)