
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
هنگامی که ساخت مدل های یادگیری ماشین، شما نیاز به انتخاب های مختلف hyperparameters ، مانند نرخ ترک تحصیل در یک لایه یا نرخ یادگیری است. این تصمیمات بر معیارهای مدل مانند دقت تأثیر می گذارد. بنابراین، یک گام مهم در گردش کار یادگیری ماشین، شناسایی بهترین فراپارامترها برای مشکل شما است که اغلب شامل آزمایش است. این فرآیند با نام «بهینه سازی فراپارامتر» یا «تنظیم فراپارامتر» شناخته می شود.
داشبورد Hparams در TensorBoard ابزارهای مختلفی را برای کمک به این فرآیند برای شناسایی بهترین آزمایش یا امیدوارکنندهترین مجموعههای فراپارامترها فراهم میکند.
این آموزش بر روی مراحل زیر تمرکز دارد:
- تنظیم آزمایش و خلاصه Hparams
- اجرای TensorFlow را برای ثبت هایپرپارامترها و متریک ها تطبیق دهید
- اجراها را شروع کنید و همه آنها را در یک فهرست اصلی ثبت کنید
- نتایج را در داشبورد Hparams TensorBoard تجسم کنید
با نصب TF 2.0 و بارگیری پسوند نوت بوک TensorBoard شروع کنید:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
TensorFlow و افزونه TensorBoard Hparams را وارد کنید:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
دانلود FashionMNIST مجموعه داده و آن را در مقیاس:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. تنظیم آزمایش و خلاصه آزمایش Hparams
با سه فراپارامتر در مدل آزمایش کنید:
- تعداد واحدها در اولین لایه متراکم
- نرخ رها شدن در لایه انصراف
- بهینه ساز
مقادیری را که باید امتحان کنید فهرست کنید و یک پیکربندی آزمایشی را در TensorBoard ثبت کنید. این مرحله اختیاری است: میتوانید اطلاعات دامنه را برای فعال کردن فیلتر کردن دقیقتر هایپرپارامترها در رابط کاربری ارائه دهید، و میتوانید مشخص کنید که کدام معیارها باید نمایش داده شوند.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
اگر شما انتخاب می کنید به جست و خیز این مرحله، شما می توانید یک لفظ رشته هر کجا که می در غیر این صورت استفاده استفاده HParam به عنوان مثال،: ارزش hparams['dropout'] به جای hparams[HP_DROPOUT] .
2. اجرای TensorFlow را برای ثبت هایپرپارامترها و متریک ها تطبیق دهید
مدل بسیار ساده خواهد بود: دو لایه متراکم با یک لایه حذفی بین آنها. کد آموزشی آشنا به نظر می رسد، اگرچه هایپرپارامترها دیگر کدگذاری شده نیستند. در عوض، hyperparameters در یک ارائه hparams فرهنگ لغت و مورد استفاده در سراسر تابع آموزش:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
برای هر اجرا، خلاصه hparams را با پارامترهای فوق و دقت نهایی ثبت کنید:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
هنگام آموزش مدلهای Keras، میتوانید به جای نوشتن مستقیم این موارد از callbacks استفاده کنید:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. اجراها را شروع کنید و همه آنها را در یک فهرست والد ثبت کنید
اکنون میتوانید چندین آزمایش را امتحان کنید و هر کدام را با مجموعهای از فراپارامترهای متفاوت آموزش دهید.
برای سادگی، از جستجوی شبکه ای استفاده کنید: تمام ترکیبات پارامترهای گسسته و فقط مرزهای پایین و بالای پارامتر با ارزش واقعی را امتحان کنید. برای سناریوهای پیچیده تر، ممکن است انتخاب هر یک از مقادیر فراپارامتر به صورت تصادفی مؤثرتر باشد (این جستجوی تصادفی نامیده می شود). روش های پیشرفته تری وجود دارد که می توان از آنها استفاده کرد.
چند آزمایش انجام دهید که چند دقیقه طول می کشد:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. نتایج را در پلاگین Hparams TensorBoard تجسم کنید
داشبورد Hparams اکنون می تواند باز شود. TensorBoard را راه اندازی کنید و روی "HParams" در بالا کلیک کنید.
%tensorboard --logdir logs/hparam_tuning
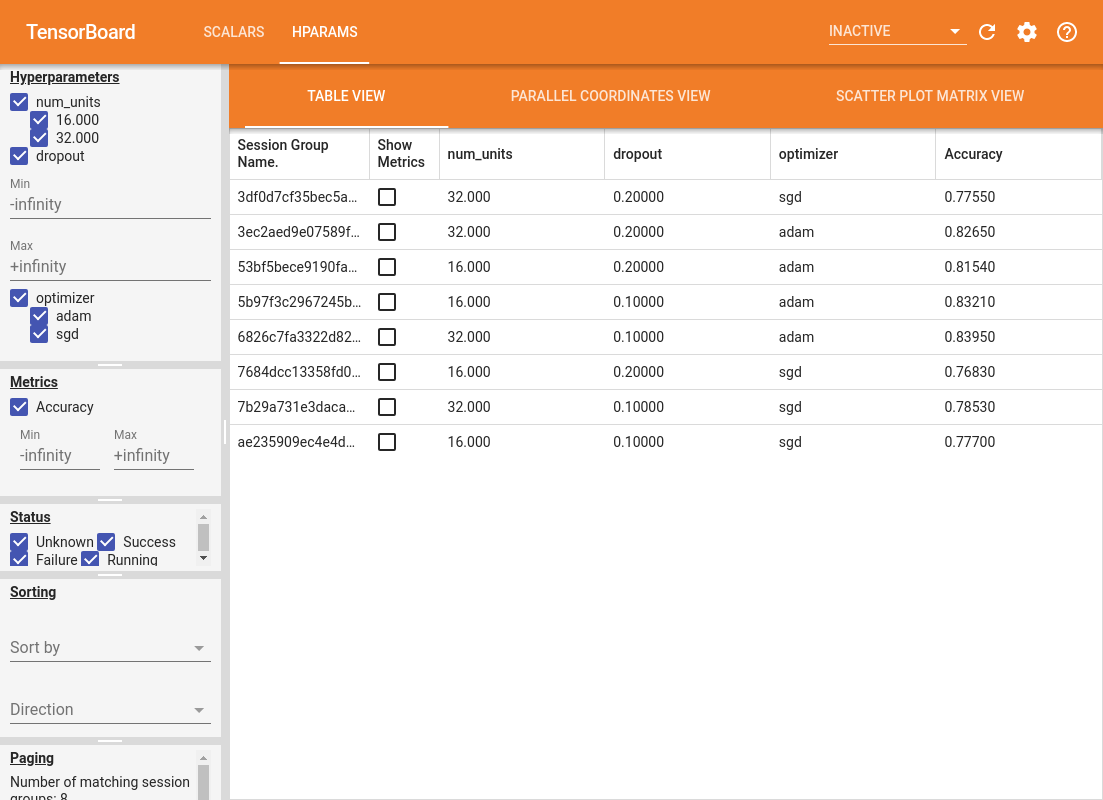
صفحه سمت چپ داشبورد قابلیت های فیلترینگی را ارائه می دهد که در تمام نماهای داشبورد Hparams فعال هستند:
- فیلتر کنید که کدام هایپرپارامترها/متریک ها در داشبورد نشان داده شده اند
- فیلتر کنید که کدام مقادیر هایپرپارامتر/متریک در داشبورد نشان داده شده است
- فیلتر در وضعیت اجرا (در حال اجرا، موفقیت، ...)
- مرتب سازی بر اساس هایپرپارامتر/متریک در نمای جدول
- تعداد گروههای جلسه برای نمایش (مفید برای عملکرد زمانی که آزمایشهای زیادی وجود دارد)
داشبورد Hparams دارای سه نمای مختلف با اطلاعات مفید مختلف است:
- جدول نمایش لیست اجرا می شود، hyperparameters خود، و معیارهای خود را.
- موازی مختصات نمایش هر یک از اجرا به عنوان یک خط رفتن را از طریق یک محور برای هر hyperparemeter و متریک نشان می دهد. روی هر محوری کلیک کنید و ماوس را بکشید تا منطقهای را علامتگذاری کنید که فقط اجراهایی را که از آن عبور میکنند برجسته میکند. این می تواند برای شناسایی گروه هایی از فراپارامترها مفید باشد. خود محورها را می توان با کشیدن آنها دوباره مرتب کرد.
- پراکندگی داستان نمایش نشان می دهد توطئه مقایسه هر یک hyperparameter / متریک با هر متریک. این می تواند به شناسایی همبستگی ها کمک کند. برای انتخاب یک منطقه در یک نمودار خاص، کلیک کنید و بکشید و آن جلسات را در سایر نمودارها برجسته کنید.
یک ردیف جدول، یک خط مختصات موازی، و یک بازار نمودار پراکندگی را می توان برای مشاهده نمودار معیارها به عنوان تابعی از مراحل آموزش برای آن جلسه کلیک کرد (اگرچه در این آموزش فقط یک مرحله برای هر اجرا استفاده می شود).
برای بررسی بیشتر قابلیتهای داشبورد Hparams، مجموعهای از گزارشهای از پیش تولید شده را با آزمایشهای بیشتر دانلود کنید:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
این گزارشها را در TensorBoard مشاهده کنید:
%tensorboard --logdir logs/hparam_demo
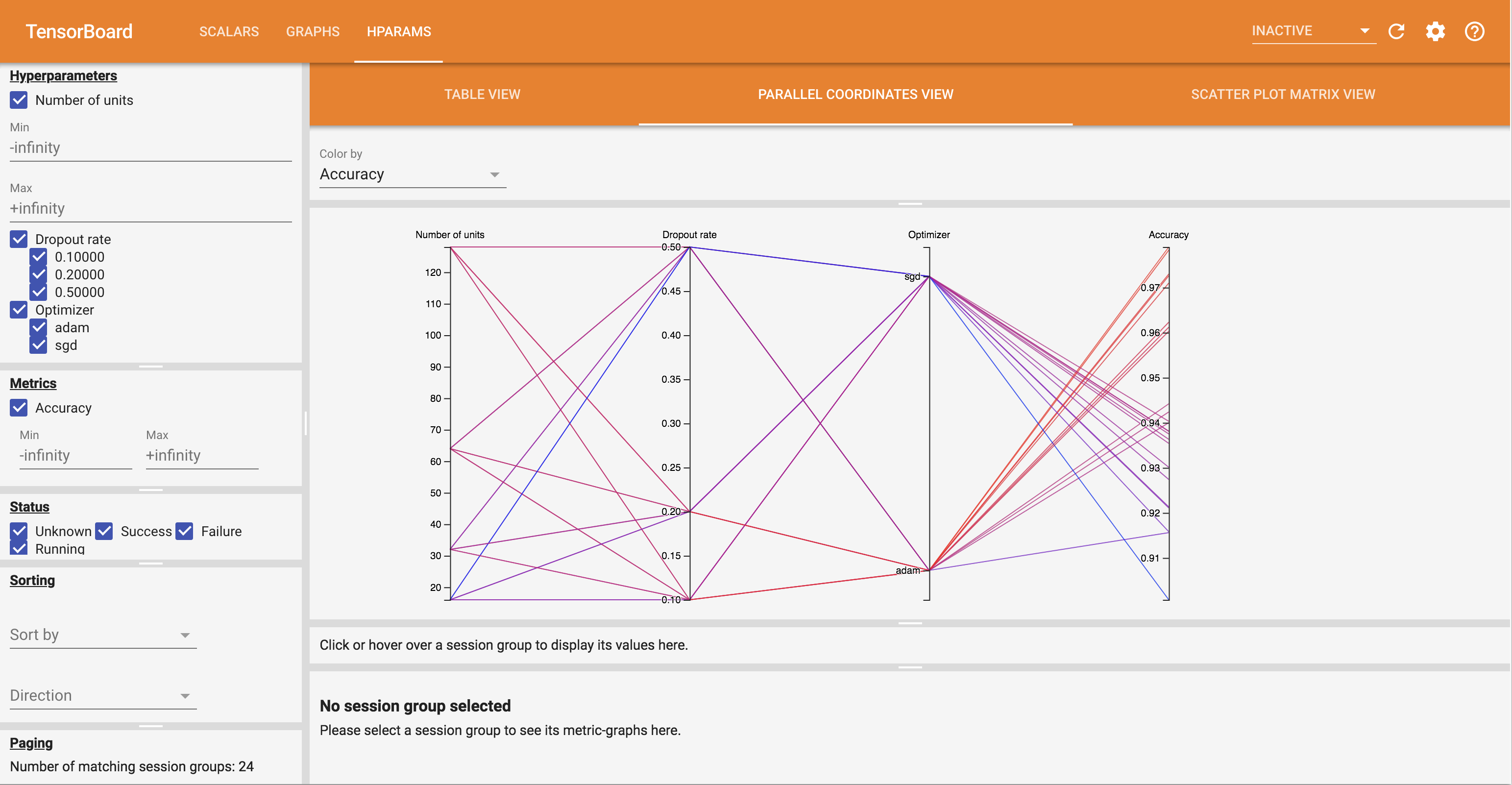
می توانید نماهای مختلف را در داشبورد Hparams امتحان کنید.
برای مثال با رفتن به نمای مختصات موازی و کلیک و کشیدن بر روی محور دقت می توانید اجراها را با بالاترین دقت انتخاب کنید. از آنجایی که این اجراها از «آدام» در محور بهینهساز عبور میکنند، میتوانید نتیجه بگیرید که «آدام» در این آزمایشها بهتر از «sgd» عمل کرده است.