
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
الگوریتم های یادگیری ماشین معمولاً از نظر محاسباتی گران هستند. بنابراین تعیین کمیت عملکرد برنامه یادگیری ماشین برای اطمینان از اینکه شما از بهینهترین نسخه مدل خود استفاده میکنید، حیاتی است. از TensorFlow Profiler برای نمایه اجرای کد TensorFlow خود استفاده کنید.
برپایی
from datetime import datetime
from packaging import version
import os
TensorFlow نیمرخ نیاز به آخرین نسخه از TensorFlow و TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
تأیید کنید که TensorFlow می تواند به GPU دسترسی داشته باشد.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
آموزش یک مدل طبقه بندی تصویر با تماس های TensorBoard
در این آموزش، شما قابلیت های TensorFlow نیمرخ کشف با گرفتن مشخصات عملکرد به دست آمده با آموزش یک مدل به تصاویر طبقه بندی در مجموعه داده MNIST .
از مجموعه داده های TensorFlow برای وارد کردن داده های آموزشی و تقسیم آن به مجموعه های آموزشی و آزمایشی استفاده کنید.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
داده های آموزشی و آزمایشی را با عادی سازی مقادیر پیکسل بین 0 و 1 از قبل پردازش کنید.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
مدل طبقه بندی تصویر را با استفاده از Keras ایجاد کنید.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
برای گرفتن نمایههای عملکرد و فراخوانی آن در حین آموزش مدل، یک پاسخ تماس TensorBoard ایجاد کنید.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
از TensorFlow Profiler برای پروفایل عملکرد آموزش مدل استفاده کنید
TensorFlow Profiler در TensorBoard تعبیه شده است. TensorBoard را با استفاده از جادوی Colab بارگیری کرده و راه اندازی کنید. مشاهده پروفایل عملکرد از طریق رفتن به زبانه نمایه.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
مشخصات عملکرد این مدل مشابه تصویر زیر است.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
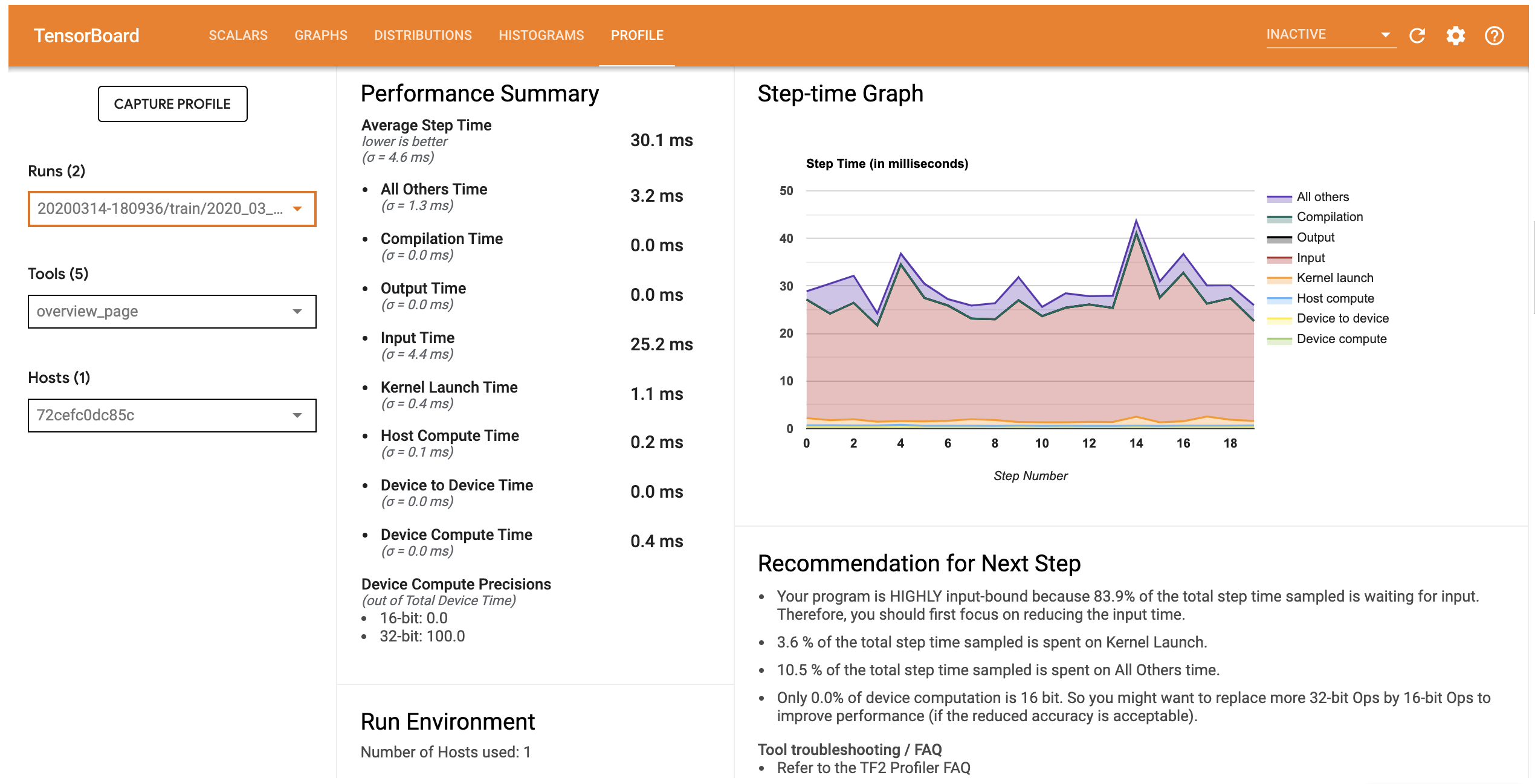
پروفایل تب صفحه نمای کلی که نشان می دهد شما یک خلاصه سطح بالایی از عملکرد مدل خود را باز می کند. با نگاهی به نمودار Step-time در سمت راست، می توانید ببینید که مدل دارای محدودیت ورودی بالایی است (یعنی زمان زیادی را در خط لوله ورودی داده صرف می کند). صفحه نمای کلی همچنین به شما توصیه هایی در مورد گام های بعدی احتمالی می دهد که می توانید برای بهینه سازی عملکرد مدل خود دنبال کنید.
برای درک که در آن تنگنا عملکرد در خط لوله ورودی رخ می دهد، ردیابی بیننده از ابزار کشویی در سمت چپ انتخاب کنید. Trace Viewer یک جدول زمانی از رویدادهای مختلفی که در CPU و GPU در طول دوره نمایهسازی رخ داده است را به شما نشان میدهد.
Trace Viewer چندین گروه رویداد را در محور عمودی نشان می دهد. هر گروه رویداد دارای چندین مسیر افقی است که با رویدادهای ردیابی پر شده است. آهنگ یک جدول زمانی رویداد برای رویدادهایی است که روی یک رشته یا یک جریان GPU اجرا میشوند. رویدادهای فردی بلوک های رنگی و مستطیلی در مسیرهای خط زمانی هستند. زمان از چپ به راست حرکت می کند. حرکت رخدادهای ردیابی با استفاده از میانبرهای صفحه کلید W (زوم)، S (زوم کردن)، ها (چپ)، و A D (راست اسکرول).
یک مستطیل منفرد نشان دهنده یک رویداد ردیابی است. آیکون اشاره گر ماوس را در نوار ابزار شناور انتخاب کنید (یا از میانبر صفحه کلید 1 ) و با کلیک رویداد اثری به آن تجزیه و تحلیل. با این کار اطلاعات مربوط به رویداد مانند زمان شروع و مدت آن نمایش داده می شود.
علاوه بر کلیک کردن، می توانید ماوس را برای انتخاب گروهی از رویدادهای ردیابی بکشید. با این کار لیستی از تمام رویدادهای آن منطقه به همراه خلاصه رویداد به شما ارائه می شود. با استفاده از M کلیدی برای اندازه گیری مدت زمان از حوادث انتخاب شده است.
رویدادهای ردیابی از:
- CPU: پردازنده حوادث تحت یک گروه رویداد به نام نمایش داده
/host:CPU. هر آهنگ نشان دهنده یک رشته در CPU است. رویدادهای CPU شامل رویدادهای خط لوله ورودی، رویدادهای زمانبندی عملیات GPU (op)، رویدادهای اجرای عملیات CPU و غیره است. - GPU: حوادث GPU تحت گروه رویداد پیشوند نمایش داده
/device:GPU:. هر گروه رویداد نشان دهنده یک جریان در GPU است.
اشکال زدایی گلوگاه های عملکرد
از Trace Viewer برای پیدا کردن گلوگاه های عملکرد در خط لوله ورودی خود استفاده کنید. تصویر زیر تصویری از مشخصات عملکرد است.
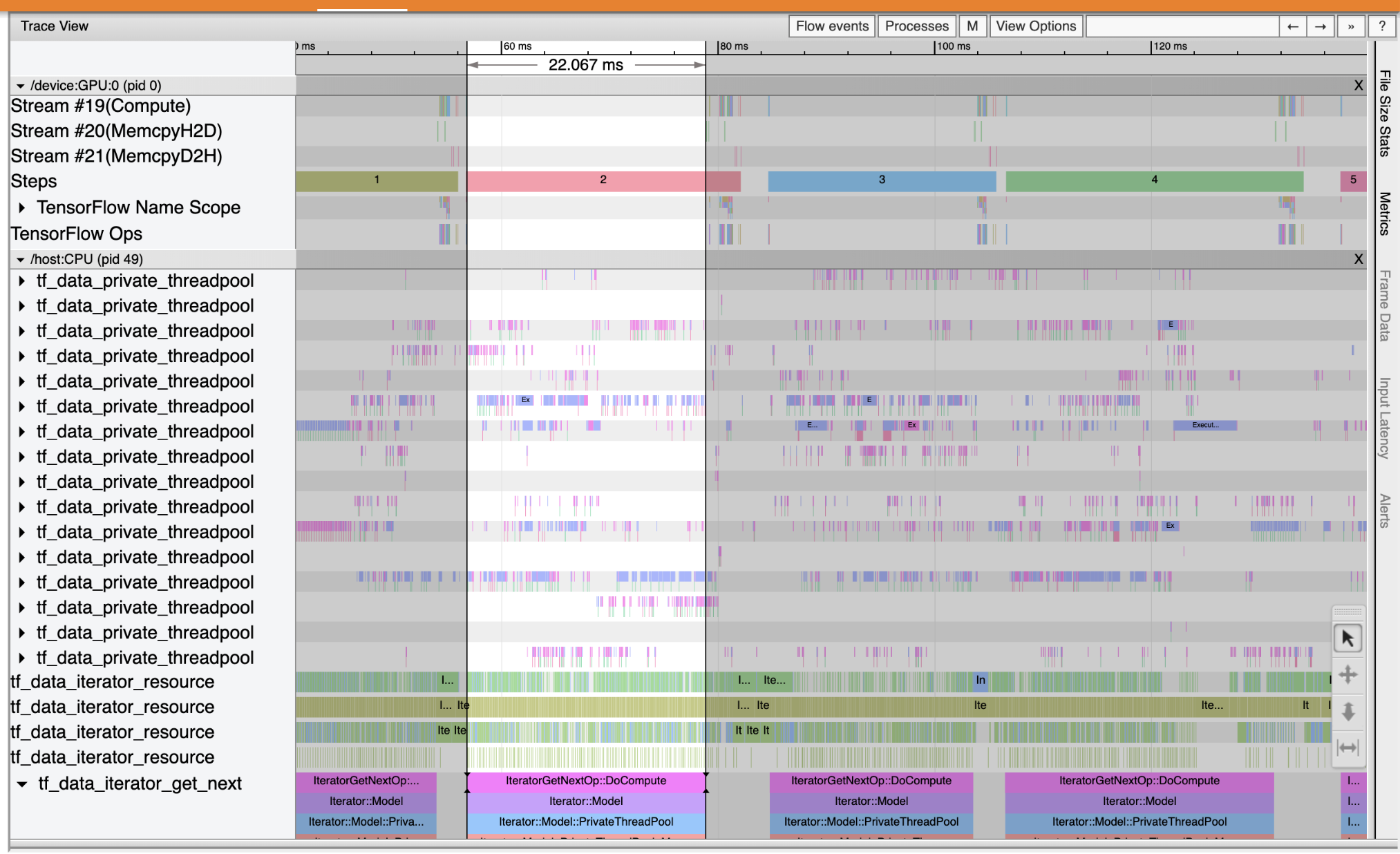
با نگاهی به آثار رویداد، شما می توانید ببینید که GPU غیر فعال است در حالی که tf_data_iterator_get_next عملیات در حال اجرا است بر روی CPU. این عملیات وظیفه پردازش داده های ورودی و ارسال آن به GPU را برای آموزش دارد. به عنوان یک قانون کلی، ایده خوبی است که دستگاه (GPU/TPU) را همیشه فعال نگه دارید.
استفاده از tf.data API برای بهینه سازی خط لوله ورودی. در این مورد، بیایید مجموعه داده آموزشی را کش کنیم و داده ها را از قبل واکشی کنیم تا مطمئن شویم که همیشه داده هایی برای پردازش GPU وجود دارد. مشاهده اینجا برای کسب اطلاعات بیشتر در مورد استفاده از tf.data برای بهینه سازی خطوط لوله ورودی خود را.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
دوباره مدل را آموزش دهید و با استفاده مجدد از تماس قبلی، نمایه عملکرد را ثبت کنید.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
دوباره راه اندازی TensorBoard و باز کردن تب مشخصات برای مشاهده مشخصات عملکرد برای خط لوله ورودی به روز شد.
مشخصات عملکرد مدل با خط لوله ورودی بهینه شده مشابه تصویر زیر است.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
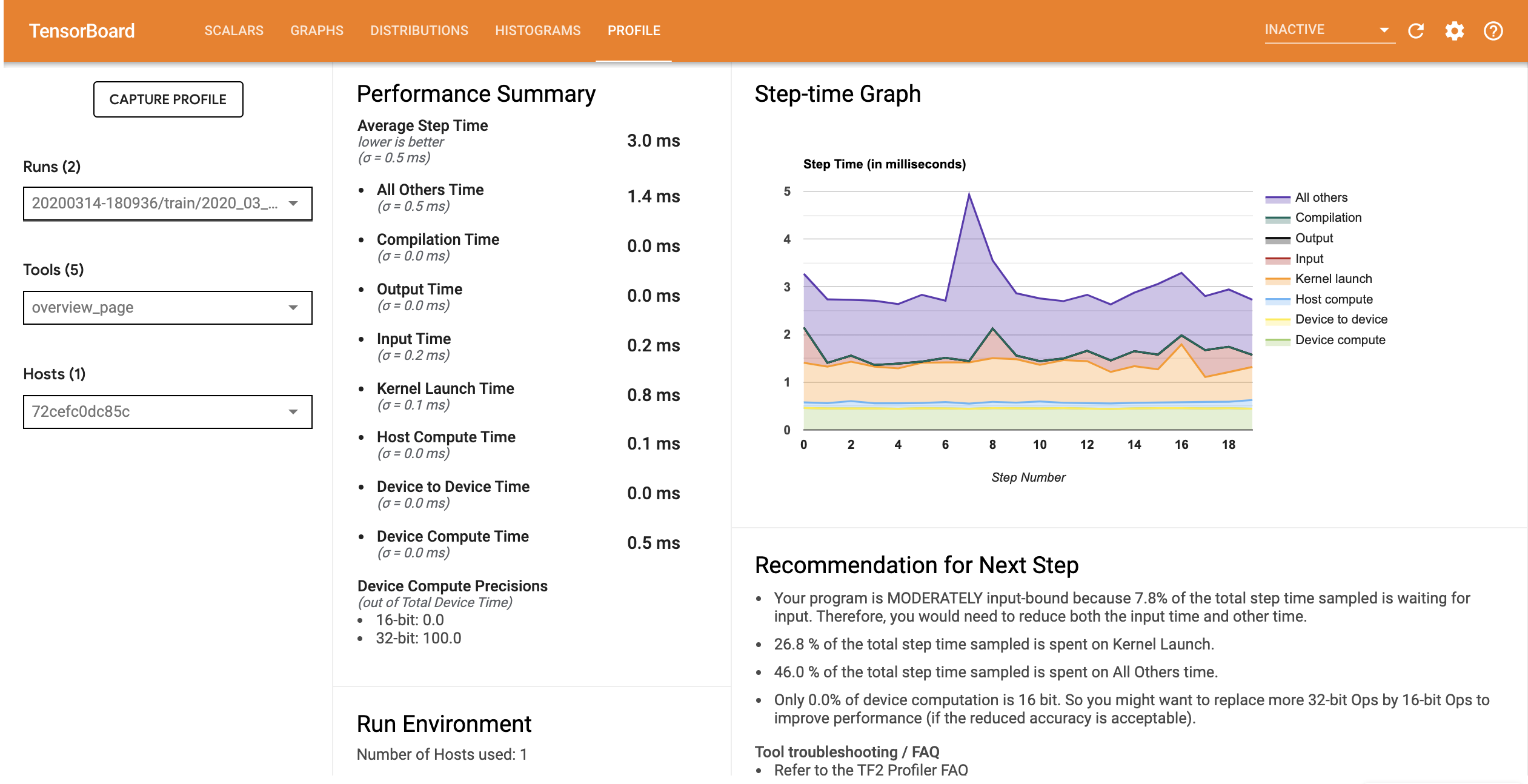
از صفحه نمای کلی، می توانید ببینید که میانگین زمان گام مانند زمان مرحله ورودی کاهش یافته است. نمودار Step-time همچنین نشان میدهد که مدل دیگر محدود به ورودی بالا نیست. برای بررسی رویدادهای ردیابی با خط لوله ورودی بهینه شده، Trace Viewer را باز کنید.
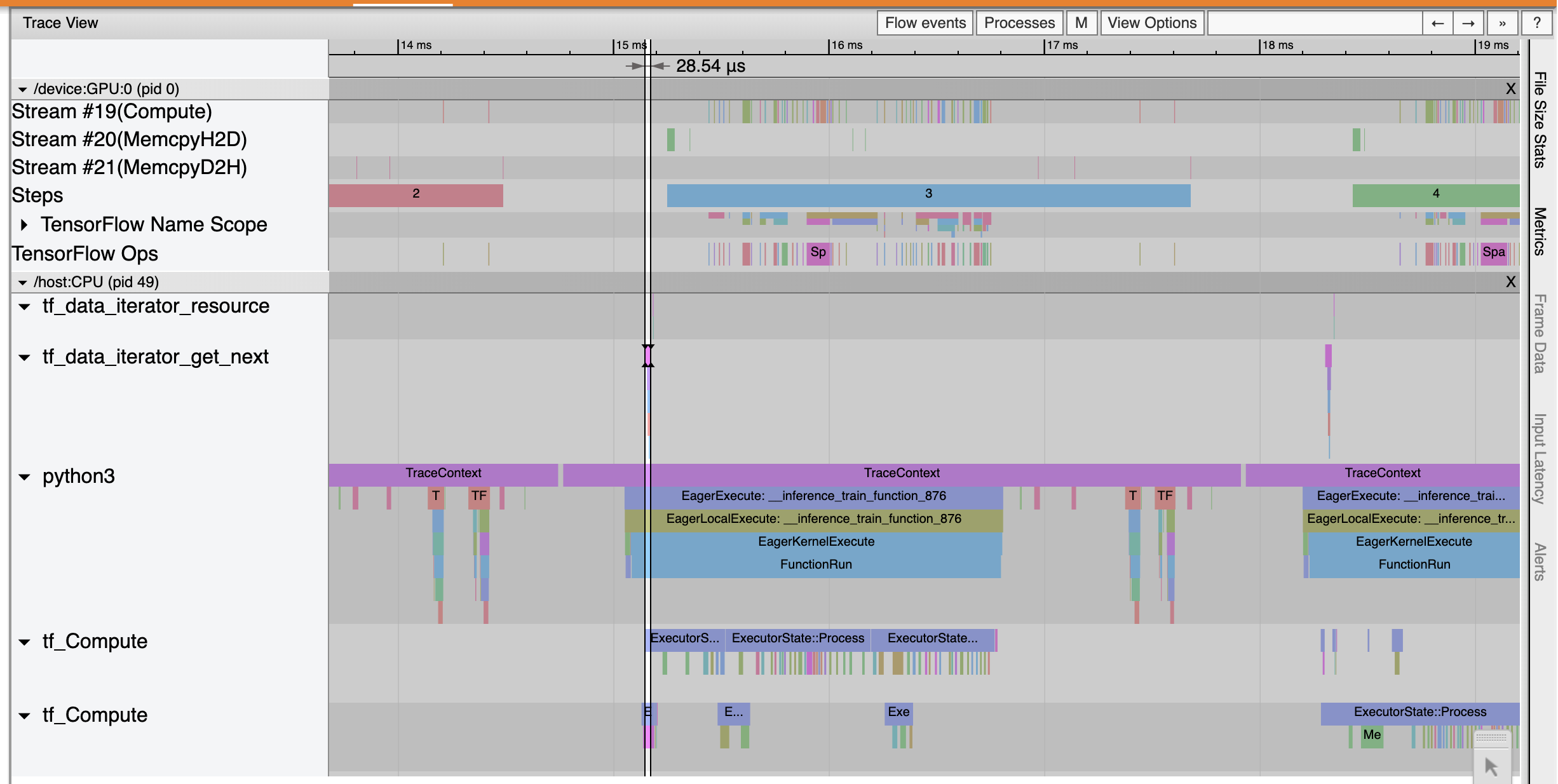
ردیابی بیننده نشان می دهد که tf_data_iterator_get_next عملیات اجرا بسیار سریعتر. بنابراین GPU یک جریان ثابت از داده ها را برای انجام آموزش دریافت می کند و از طریق آموزش مدل به استفاده بسیار بهتری می رسد.
خلاصه
از TensorFlow Profiler برای پروفایل و اشکال زدایی عملکرد آموزش مدل استفاده کنید. دفعات بازدید: راهنمای نیمرخ و تماشای پروفایل عملکرد در TF 2 بحث از نشست TensorFlow برنامه نویس 2020 برای کسب اطلاعات بیشتر در مورد TensorFlow پیشفیلتر.