| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
با استفاده از TensorBoard کدهای جاسازی پروژکتور، شما می گرافیکی می تواند نشان دهنده درونه گیریها ابعادی بالا. این می تواند در تجسم، بررسی و درک لایه های تعبیه شده شما مفید باشد.

در این آموزش، نحوه تجسم این نوع لایه آموزش دیده را خواهید آموخت.
برپایی
برای این آموزش، ما از TensorBoard برای تجسم یک لایه جاسازی ایجاد شده برای طبقه بندی داده های بررسی فیلم استفاده خواهیم کرد.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
داده های IMDB
ما از مجموعه داده ای متشکل از 25000 نقد فیلم IMDB استفاده خواهیم کرد که هر کدام دارای یک برچسب احساسات (مثبت/منفی) هستند. هر بررسی به عنوان دنباله ای از شاخص های کلمه (اعداد صحیح) از پیش پردازش شده و کدگذاری می شود. برای سادگی، کلمات با فرکانس کلی در مجموعه داده نمایه می شوند، برای مثال عدد صحیح "3" سومین کلمه پرتکرار ظاهر شده در همه بررسی ها را رمزگذاری می کند. این اجازه می دهد تا عملیات فیلترینگ سریع مانند: "فقط 10000 کلمه رایج را در نظر بگیرید، اما 20 کلمه رایج را حذف کنید".
به عنوان یک قرارداد، "0" برای هیچ کلمه خاصی نیست، اما در عوض برای رمزگذاری هر کلمه ناشناخته استفاده می شود. بعداً در آموزش، ردیف "0" را در تجسم حذف خواهیم کرد.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
لایه جاسازی Keras
لایه Keras کدهای جاسازی می توان برای قطار یک تعبیه برای هر کلمه در واژگان خود را. هر کلمه (یا زیر کلمه در این مورد) با یک بردار (یا تعبیه) 16 بعدی همراه خواهد بود که توسط مدل آموزش داده می شود.
مشاهده این آموزش برای کسب اطلاعات بیشتر در مورد درونه گیریها کلمه.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
ذخیره داده ها برای TensorBoard
TensorBoard تانسورها و ابرداده ها را از لاگ پروژه های tensorflow شما می خواند. مسیر را به دایرکتوری ورود به سیستم با مشخص log_dir زیر کلیک کنید. برای این آموزش، ما با استفاده از /logs/imdb-example/ .
برای بارگذاری دادهها در Tensorboard، باید یک نقطه بازرسی آموزشی را به همراه ابردادهای که اجازه تجسم یک لایه خاص در مدل را میدهد، در آن فهرست ذخیره کنیم.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
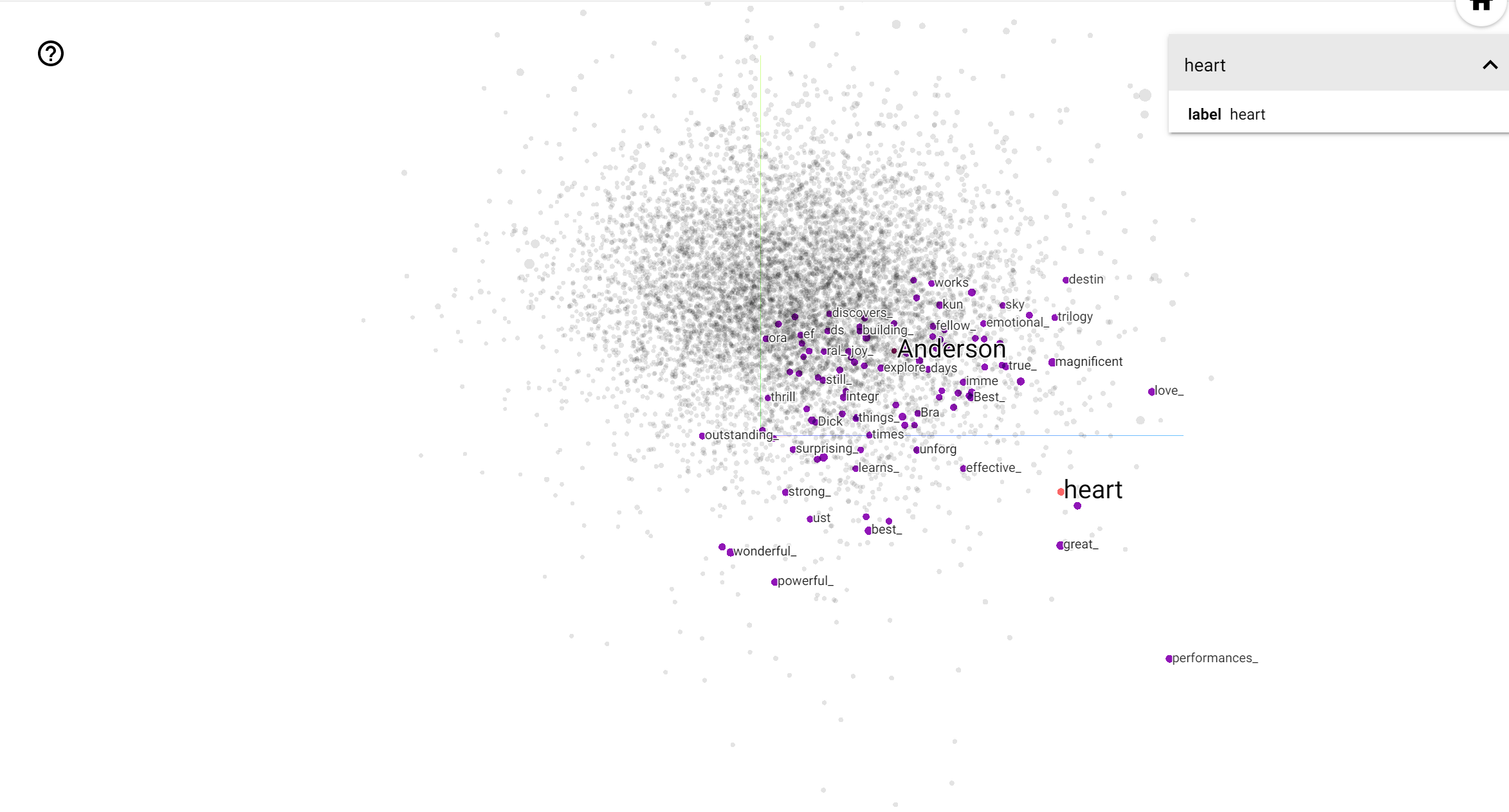
تحلیل و بررسی
TensorBoard Projector ابزاری عالی برای تفسیر و بصری کردن جاسازی است. داشبورد به کاربران اجازه می دهد عبارات خاصی را جستجو کنند و کلماتی را که در مجاورت یکدیگر در فضای تعبیه شده (کم بعدی) قرار دارند برجسته می کند. از این مثال ما می توانید ببینید که وس اندرسون و آلفرد هیچکاک هر دو واژه به جای خنثی هستند اما که آنها در زمینه های مختلف اشاره شده است.

در این فضا، هیچکاک به کلماتی مانند نزدیک تر است nightmare ، که به احتمال زیاد با توجه به این واقعیت که او به عنوان "استاد تعلیق" شناخته شده است، در حالی که اندرسون به کلمه نزدیک تر است heart ، است که سازگار با سبک و دلگرم کننده خستگی ناپذیر دقیق خود .