
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
این نوت بوک آموزش دنباله به مدل دنباله (seq2seq) برای اسپانیایی به ترجمه انگلیسی بر اساس موثر روشهای مبتنی بر توجه عصبی ترجمه ماشینی . این یک مثال پیشرفته است که برخی از دانش های زیر را فرض می کند:
- مدل های دنباله به دنباله
- اصول TensorFlow در زیر لایه keras:
- کار با تانسورها به طور مستقیم
- نوشتن سفارشی
keras.Modelوkeras.layers
در حالی که این معماری تا حدودی منسوخ شده آن است که هنوز یک پروژه بسیار مفید برای کار را از طریق به دست آوردن یک درک عمیق تر از مکانیسم توجه (قبل از رفتن به ترانسفورماتور ).
پس از آموزش مدل در این نوت بوک، شما قادر خواهید بود به ورودی یک جمله اسپانیایی خواهد بود، مانند، و بازگشت به ترجمه انگلیسی "¿todavia estan EN کاسا؟": "شما هنوز هم در خانه"
مدل حاصل صادرات به عنوان یک tf.saved_model ، بنابراین می توان آن را در دیگر محیط های TensorFlow استفاده می شود.
کیفیت ترجمه برای نمونه اسباب بازی مناسب است، اما طرح توجه ایجاد شده شاید جالب تر باشد. این نشان میدهد که در هنگام ترجمه به کدام بخش از جمله ورودی توجه مدل میشود:
برپایی
pip install tensorflow_text
import numpy as np
import typing
from typing import Any, Tuple
import tensorflow as tf
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
این آموزش چند لایه را از ابتدا می سازد، اگر می خواهید بین پیاده سازی سفارشی و داخلی جابجا شوید از این متغیر استفاده کنید.
use_builtins = True
این آموزش از بسیاری از API های سطح پایین استفاده می کند که در آنها به راحتی می توان اشکال را اشتباه گرفت. این کلاس برای بررسی اشکال در طول آموزش استفاده می شود.
بررسی کننده شکل
class ShapeChecker():
def __init__(self):
# Keep a cache of every axis-name seen
self.shapes = {}
def __call__(self, tensor, names, broadcast=False):
if not tf.executing_eagerly():
return
if isinstance(names, str):
names = (names,)
shape = tf.shape(tensor)
rank = tf.rank(tensor)
if rank != len(names):
raise ValueError(f'Rank mismatch:\n'
f' found {rank}: {shape.numpy()}\n'
f' expected {len(names)}: {names}\n')
for i, name in enumerate(names):
if isinstance(name, int):
old_dim = name
else:
old_dim = self.shapes.get(name, None)
new_dim = shape[i]
if (broadcast and new_dim == 1):
continue
if old_dim is None:
# If the axis name is new, add its length to the cache.
self.shapes[name] = new_dim
continue
if new_dim != old_dim:
raise ValueError(f"Shape mismatch for dimension: '{name}'\n"
f" found: {new_dim}\n"
f" expected: {old_dim}\n")
داده
ما یک مجموعه داده زبان ارائه شده توسط خواهید استفاده کنید http://www.manythings.org/anki/ این مجموعه داده شامل جفت ترجمه زبان در قالب:
May I borrow this book? ¿Puedo tomar prestado este libro?
آنها زبان های مختلفی دارند، اما ما از مجموعه داده انگلیسی-اسپانیایی استفاده خواهیم کرد.
مجموعه داده را دانلود و آماده کنید
برای راحتی، ما یک کپی از این مجموعه داده را در Google Cloud میزبانی کردهایم، اما میتوانید نسخه خود را نیز دانلود کنید. پس از دانلود مجموعه داده، در اینجا مراحلی را برای آماده سازی داده ها انجام خواهیم داد:
- اضافه کردن شروع و پایان رمز به هر یک جمله.
- جملات را با حذف کاراکترهای خاص پاک کنید.
- یک فهرست واژه و فهرست واژه معکوس ایجاد کنید (لغت نامه ها از word → id و id → word نگاشت می شوند).
- هر جمله را به حداکثر طول اضافه کنید.
# Download the file
import pathlib
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = pathlib.Path(path_to_zip).parent/'spa-eng/spa.txt'
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip 2646016/2638744 [==============================] - 0s 0us/step 2654208/2638744 [==============================] - 0s 0us/step
def load_data(path):
text = path.read_text(encoding='utf-8')
lines = text.splitlines()
pairs = [line.split('\t') for line in lines]
inp = [inp for targ, inp in pairs]
targ = [targ for targ, inp in pairs]
return targ, inp
targ, inp = load_data(path_to_file)
print(inp[-1])
Si quieres sonar como un hablante nativo, debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un músico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado.
print(targ[-1])
If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
یک مجموعه داده tf.data ایجاد کنید
از این آرایه از رشته ها شما می توانید یک ایجاد tf.data.Dataset از رشتهها که shuffles و دسته آنها موثر:
BUFFER_SIZE = len(inp)
BATCH_SIZE = 64
dataset = tf.data.Dataset.from_tensor_slices((inp, targ)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
for example_input_batch, example_target_batch in dataset.take(1):
print(example_input_batch[:5])
print()
print(example_target_batch[:5])
break
tf.Tensor( [b'No s\xc3\xa9 lo que quiero.' b'\xc2\xbfDeber\xc3\xada repetirlo?' b'Tard\xc3\xa9 m\xc3\xa1s de 2 horas en traducir unas p\xc3\xa1ginas en ingl\xc3\xa9s.' b'A Tom comenz\xc3\xb3 a temerle a Mary.' b'Mi pasatiempo es la lectura.'], shape=(5,), dtype=string) tf.Tensor( [b"I don't know what I want." b'Should I repeat it?' b'It took me more than two hours to translate a few pages of English.' b'Tom became afraid of Mary.' b'My hobby is reading.'], shape=(5,), dtype=string)
پیش پردازش متن
یکی از اهداف این آموزش است برای ساخت یک مدل است که می تواند به عنوان یک صادر tf.saved_model . برای اینکه که مدل صادر مفید آن باید به tf.string ورودی، و بازگشت tf.string خروجی: تمام پردازش متن داخل مدل اتفاق می افتد.
استاندارد سازی
این مدل با متن چند زبانه با واژگان محدود سروکار دارد. بنابراین استانداردسازی متن ورودی بسیار مهم خواهد بود.
اولین مرحله عادی سازی یونیکد برای تقسیم کاراکترهای تاکیدی و جایگزینی کاراکترهای سازگار با معادل های ASCII آنها است.
tensorflow_text بسته شامل یک عملیات یونیکد عادی:
example_text = tf.constant('¿Todavía está en casa?')
print(example_text.numpy())
print(tf_text.normalize_utf8(example_text, 'NFKD').numpy())
b'\xc2\xbfTodav\xc3\xada est\xc3\xa1 en casa?' b'\xc2\xbfTodavi\xcc\x81a esta\xcc\x81 en casa?'
عادی سازی یونیکد اولین گام در تابع استانداردسازی متن خواهد بود:
def tf_lower_and_split_punct(text):
# Split accecented characters.
text = tf_text.normalize_utf8(text, 'NFKD')
text = tf.strings.lower(text)
# Keep space, a to z, and select punctuation.
text = tf.strings.regex_replace(text, '[^ a-z.?!,¿]', '')
# Add spaces around punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿]', r' \0 ')
# Strip whitespace.
text = tf.strings.strip(text)
text = tf.strings.join(['[START]', text, '[END]'], separator=' ')
return text
print(example_text.numpy().decode())
print(tf_lower_and_split_punct(example_text).numpy().decode())
¿Todavía está en casa? [START] ¿ todavia esta en casa ? [END]
بردار سازی متن
این تابع استاندارد خواهد شد تا در یک پیچیده tf.keras.layers.TextVectorization لایه که استخراج لغات و تبدیل متن ورودی به توالی از نشانه رسیدگی خواهد شد.
max_vocab_size = 5000
input_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
TextVectorization لایه و لایه های بسیاری پیش پردازش دیگر یک adapt روش. این روش بار خوانده شده یک عصر از داده های آموزشی، و آثار زیادی مانند Model.fix . این adapt روش مقدار دهی اولیه لایه بر اساس داده. در اینجا واژگان را مشخص می کند:
input_text_processor.adapt(inp)
# Here are the first 10 words from the vocabulary:
input_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'que', 'de', 'el', 'a', 'no']
که اسپانیایی است TextVectorization لایه، در حال حاضر ساخت و .adapt() به زبان انگلیسی یکی:
output_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
output_text_processor.adapt(targ)
output_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'the', 'i', 'to', 'you', 'tom']
اکنون این لایه ها می توانند دسته ای از رشته ها را به دسته ای از شناسه های رمز تبدیل کنند:
example_tokens = input_text_processor(example_input_batch)
example_tokens[:3, :10]
<tf.Tensor: shape=(3, 10), dtype=int64, numpy=
array([[ 2, 9, 17, 22, 5, 48, 4, 3, 0, 0],
[ 2, 13, 177, 1, 12, 3, 0, 0, 0, 0],
[ 2, 120, 35, 6, 290, 14, 2134, 506, 2637, 14]])>
get_vocabulary روش می توان برای تبدیل شناسه رمز به متن:
input_vocab = np.array(input_text_processor.get_vocabulary())
tokens = input_vocab[example_tokens[0].numpy()]
' '.join(tokens)
'[START] no se lo que quiero . [END] '
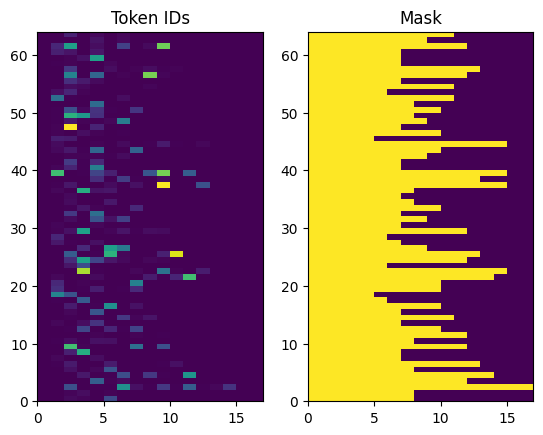
شناسه های توکن برگشتی دارای لایه صفر هستند. این به راحتی می تواند به یک ماسک تبدیل شود:
plt.subplot(1, 2, 1)
plt.pcolormesh(example_tokens)
plt.title('Token IDs')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')
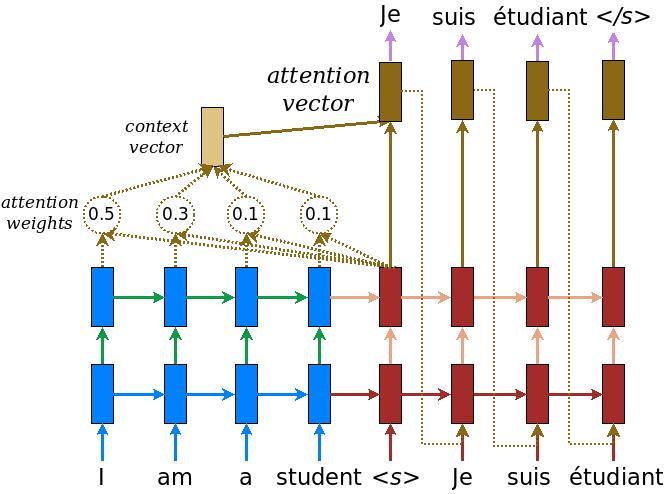
مدل رمزگذار/رمزگشا
نمودار زیر نمای کلی از مدل را نشان می دهد. در هر مرحله زمانی خروجی رمزگشا با یک مجموع وزنی روی ورودی رمزگذاری شده ترکیب می شود تا کلمه بعدی را پیش بینی کند. نمودار و فرمول از هستند مقاله Luong به است .
قبل از ورود به آن، چند ثابت برای مدل تعریف کنید:
embedding_dim = 256
units = 1024
رمزگذار
با ساختن رمزگذار، قسمت آبی نمودار بالا، شروع کنید.
رمزگذار:
- طول می کشد یک لیست از شناسه رمز (از
input_text_processor). - به نظر می رسد تا یک بردار تعبیه برای هر نشانه (با استفاده از یک
layers.Embedding). - پردازش درونه گیریها را در یک دنباله جدید (با استفاده از یک
layers.GRU). - برمی گرداند:
- دنباله پردازش شده این به سر توجه منتقل می شود.
- وضعیت داخلی. این برای مقداردهی اولیه رمزگشا استفاده خواهد شد
class Encoder(tf.keras.layers.Layer):
def __init__(self, input_vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.enc_units = enc_units
self.input_vocab_size = input_vocab_size
# The embedding layer converts tokens to vectors
self.embedding = tf.keras.layers.Embedding(self.input_vocab_size,
embedding_dim)
# The GRU RNN layer processes those vectors sequentially.
self.gru = tf.keras.layers.GRU(self.enc_units,
# Return the sequence and state
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, tokens, state=None):
shape_checker = ShapeChecker()
shape_checker(tokens, ('batch', 's'))
# 2. The embedding layer looks up the embedding for each token.
vectors = self.embedding(tokens)
shape_checker(vectors, ('batch', 's', 'embed_dim'))
# 3. The GRU processes the embedding sequence.
# output shape: (batch, s, enc_units)
# state shape: (batch, enc_units)
output, state = self.gru(vectors, initial_state=state)
shape_checker(output, ('batch', 's', 'enc_units'))
shape_checker(state, ('batch', 'enc_units'))
# 4. Returns the new sequence and its state.
return output, state
در اینجا نحوه تطبیق آن با هم تا کنون آمده است:
# Convert the input text to tokens.
example_tokens = input_text_processor(example_input_batch)
# Encode the input sequence.
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
example_enc_output, example_enc_state = encoder(example_tokens)
print(f'Input batch, shape (batch): {example_input_batch.shape}')
print(f'Input batch tokens, shape (batch, s): {example_tokens.shape}')
print(f'Encoder output, shape (batch, s, units): {example_enc_output.shape}')
print(f'Encoder state, shape (batch, units): {example_enc_state.shape}')
Input batch, shape (batch): (64,) Input batch tokens, shape (batch, s): (64, 14) Encoder output, shape (batch, s, units): (64, 14, 1024) Encoder state, shape (batch, units): (64, 1024)
رمزگذار حالت داخلی خود را برمیگرداند تا بتوان از حالت آن برای مقداردهی اولیه رمزگشا استفاده کرد.
همچنین معمول است که یک RNN وضعیت خود را برگرداند تا بتواند یک توالی را در چندین تماس پردازش کند. شما بیشتر از آن ساخت رمزگشا را خواهید دید.
سر توجه
رمزگشا از توجه برای تمرکز انتخابی بر روی بخش هایی از دنباله ورودی استفاده می کند. توجه دنباله ای از بردارها را به عنوان ورودی برای هر مثال می گیرد و برای هر مثال یک بردار "توجه" برمی گرداند. این لایه توجه شبیه به یک است layers.GlobalAveragePoling1D اما لایه توجه انجام میانگین وزنی.
بیایید ببینیم که چگونه این کار می کند:


جایی که:
- \(s\) شاخص رمزگذار است.
- \(t\) شاخص رسیور است.
- \(\alpha_{ts}\) وزن توجه باشد.
- \(h_s\) است که دنباله ای از خروجی رمزگذار به (توجه "کلید" و "ارزش" در اصطلاحات ترانسفورماتور) حضور داشتند.
- \(h_t\) دولت رسیور توجه به دنباله (توجه "پرس و جو" در اصطلاحات ترانسفورماتور) است.
- \(c_t\) در نتیجه بردار زمینه است.
- \(a_t\) خروجی نهایی ترکیب "زمینه" و "پرس و جو" است.
معادلات:
- محاسبه وزن توجه، \(\alpha_{ts}\)، به عنوان یک softmax در سراسر دنباله خروجی رمزگذار است.
- بردار زمینه را به عنوان مجموع وزنی خروجی های رمزگذار محاسبه می کند.
تاریخ و زمان آخرین است \(score\) تابع. وظیفه آن محاسبه یک امتیاز لاجیت اسکالر برای هر جفت کلید-پرس و جو است. دو رویکرد رایج وجود دارد:
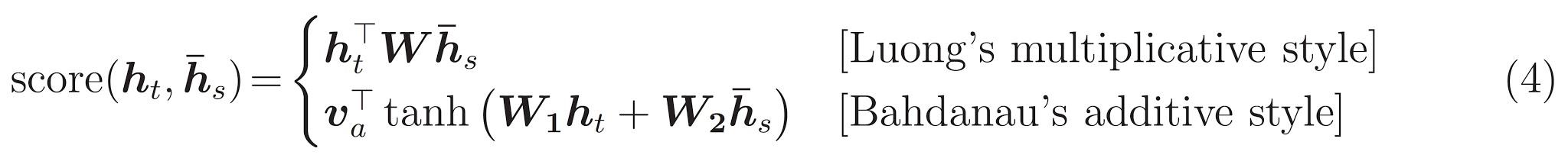
این آموزش با استفاده از توجه افزودنی Bahdanau است . TensorFlow شامل پیاده سازی هر دو به عنوان layers.Attention و layers.AdditiveAttention . کلاس زیر دسته ماتریس وزن در یک جفت از layers.Dense لایه ها، و اجرای داخلی را فراخوانی میکند.
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
# For Eqn. (4), the Bahdanau attention
self.W1 = tf.keras.layers.Dense(units, use_bias=False)
self.W2 = tf.keras.layers.Dense(units, use_bias=False)
self.attention = tf.keras.layers.AdditiveAttention()
def call(self, query, value, mask):
shape_checker = ShapeChecker()
shape_checker(query, ('batch', 't', 'query_units'))
shape_checker(value, ('batch', 's', 'value_units'))
shape_checker(mask, ('batch', 's'))
# From Eqn. (4), `W1@ht`.
w1_query = self.W1(query)
shape_checker(w1_query, ('batch', 't', 'attn_units'))
# From Eqn. (4), `W2@hs`.
w2_key = self.W2(value)
shape_checker(w2_key, ('batch', 's', 'attn_units'))
query_mask = tf.ones(tf.shape(query)[:-1], dtype=bool)
value_mask = mask
context_vector, attention_weights = self.attention(
inputs = [w1_query, value, w2_key],
mask=[query_mask, value_mask],
return_attention_scores = True,
)
shape_checker(context_vector, ('batch', 't', 'value_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
return context_vector, attention_weights
لایه توجه را تست کنید
درست BahdanauAttention لایه:
attention_layer = BahdanauAttention(units)
این لایه 3 ورودی می گیرد:
-
query: این خواهد بود که توسط رسیور تولید، بعد. -
value: این خواهد بود که خروجی از رمز گذار. -
mask: برای رد این بالشتک،example_tokens != 0
(example_tokens != 0).shape
TensorShape([64, 14])
اجرای برداری لایه توجه به شما امکان می دهد دسته ای از توالی بردارهای پرس و جو و دسته ای از توالی بردارهای مقدار را ارسال کنید. نتیجه این است:
- دسته ای از دنباله های نتیجه بردار اندازه پرس و جوها را نشان می دهد.
- توجه دسته ای نقشه ها، با اندازه
(query_length, value_length).
# Later, the decoder will generate this attention query
example_attention_query = tf.random.normal(shape=[len(example_tokens), 2, 10])
# Attend to the encoded tokens
context_vector, attention_weights = attention_layer(
query=example_attention_query,
value=example_enc_output,
mask=(example_tokens != 0))
print(f'Attention result shape: (batch_size, query_seq_length, units): {context_vector.shape}')
print(f'Attention weights shape: (batch_size, query_seq_length, value_seq_length): {attention_weights.shape}')
Attention result shape: (batch_size, query_seq_length, units): (64, 2, 1024) Attention weights shape: (batch_size, query_seq_length, value_seq_length): (64, 2, 14)
وزن توجه باید به طور خلاصه 1.0 برای هر دنباله.
در اینجا وزن توجه در سراسر توالی در می t=0 :
plt.subplot(1, 2, 1)
plt.pcolormesh(attention_weights[:, 0, :])
plt.title('Attention weights')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')

از آنجا که از مقدار دهی اولیه کوچک تصادفی وزن توجه همه نزدیک به 1/(sequence_length) . اگر شما در در وزن برای یک دنباله تک زوم، شما می توانید ببینید که برخی از تغییرات کوچک است که مدل می توانند یاد بگیرند به گسترش است، و بهره برداری از وجود دارد.
attention_weights.shape
TensorShape([64, 2, 14])
attention_slice = attention_weights[0, 0].numpy()
attention_slice = attention_slice[attention_slice != 0]
plt.suptitle('Attention weights for one sequence')
plt.figure(figsize=(12, 6))
a1 = plt.subplot(1, 2, 1)
plt.bar(range(len(attention_slice)), attention_slice)
# freeze the xlim
plt.xlim(plt.xlim())
plt.xlabel('Attention weights')
a2 = plt.subplot(1, 2, 2)
plt.bar(range(len(attention_slice)), attention_slice)
plt.xlabel('Attention weights, zoomed')
# zoom in
top = max(a1.get_ylim())
zoom = 0.85*top
a2.set_ylim([0.90*top, top])
a1.plot(a1.get_xlim(), [zoom, zoom], color='k')
[<matplotlib.lines.Line2D at 0x7fb42c5b1090>] <Figure size 432x288 with 0 Axes>

رمزگشا
وظیفه رمزگشا تولید پیشبینی برای توکن خروجی بعدی است.
- رمزگشا خروجی کامل رمزگذار را دریافت می کند.
- از یک RNN برای پیگیری آنچه تاکنون تولید کرده است استفاده می کند.
- از خروجی RNN خود به عنوان پرس و جو برای توجه به خروجی رمزگذار استفاده می کند و بردار زمینه را تولید می کند.
- خروجی RNN و بردار زمینه را با استفاده از معادله 3 (زیر) برای تولید "بردار توجه" ترکیب می کند.
- پیش بینی های لاجیت را برای توکن بعدی بر اساس "بردار توجه" ایجاد می کند.

در اینجا است Decoder کلاس و اولیه آن است. Initializer تمام لایه های لازم را ایجاد می کند.
class Decoder(tf.keras.layers.Layer):
def __init__(self, output_vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.dec_units = dec_units
self.output_vocab_size = output_vocab_size
self.embedding_dim = embedding_dim
# For Step 1. The embedding layer convets token IDs to vectors
self.embedding = tf.keras.layers.Embedding(self.output_vocab_size,
embedding_dim)
# For Step 2. The RNN keeps track of what's been generated so far.
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
# For step 3. The RNN output will be the query for the attention layer.
self.attention = BahdanauAttention(self.dec_units)
# For step 4. Eqn. (3): converting `ct` to `at`
self.Wc = tf.keras.layers.Dense(dec_units, activation=tf.math.tanh,
use_bias=False)
# For step 5. This fully connected layer produces the logits for each
# output token.
self.fc = tf.keras.layers.Dense(self.output_vocab_size)
call روش برای این لایه را می گیرد و تانسورها چندگانه محاسبه میکند. آنها را در کلاس های کانتینری ساده سازماندهی کنید:
class DecoderInput(typing.NamedTuple):
new_tokens: Any
enc_output: Any
mask: Any
class DecoderOutput(typing.NamedTuple):
logits: Any
attention_weights: Any
در اینجا اجرای است call روش:
def call(self,
inputs: DecoderInput,
state=None) -> Tuple[DecoderOutput, tf.Tensor]:
shape_checker = ShapeChecker()
shape_checker(inputs.new_tokens, ('batch', 't'))
shape_checker(inputs.enc_output, ('batch', 's', 'enc_units'))
shape_checker(inputs.mask, ('batch', 's'))
if state is not None:
shape_checker(state, ('batch', 'dec_units'))
# Step 1. Lookup the embeddings
vectors = self.embedding(inputs.new_tokens)
shape_checker(vectors, ('batch', 't', 'embedding_dim'))
# Step 2. Process one step with the RNN
rnn_output, state = self.gru(vectors, initial_state=state)
shape_checker(rnn_output, ('batch', 't', 'dec_units'))
shape_checker(state, ('batch', 'dec_units'))
# Step 3. Use the RNN output as the query for the attention over the
# encoder output.
context_vector, attention_weights = self.attention(
query=rnn_output, value=inputs.enc_output, mask=inputs.mask)
shape_checker(context_vector, ('batch', 't', 'dec_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
# Step 4. Eqn. (3): Join the context_vector and rnn_output
# [ct; ht] shape: (batch t, value_units + query_units)
context_and_rnn_output = tf.concat([context_vector, rnn_output], axis=-1)
# Step 4. Eqn. (3): `at = tanh(Wc@[ct; ht])`
attention_vector = self.Wc(context_and_rnn_output)
shape_checker(attention_vector, ('batch', 't', 'dec_units'))
# Step 5. Generate logit predictions:
logits = self.fc(attention_vector)
shape_checker(logits, ('batch', 't', 'output_vocab_size'))
return DecoderOutput(logits, attention_weights), state
Decoder.call = call
رمزگذار پردازش دنباله ورودی کامل خود را با یک تماس به RNN آن است. این پیاده سازی از رسیور می تواند که برای آموزش کارآمد انجام دهد. اما این آموزش به چند دلیل رمزگشا را در یک حلقه اجرا می کند:
- انعطاف پذیری: نوشتن حلقه به شما امکان کنترل مستقیم روی روند آموزشی را می دهد.
- وضوح: این ممکن است برای انجام کلاهبرداری پوشش و استفاده از
layers.RNNیاtfa.seq2seqرابط های برنامه کاربردی برای بسته بندی این همه را به یک مکالمه. اما نوشتن آن به عنوان یک حلقه ممکن است واضح تر باشد.- آموزش رایگان حلقه در نشان نسل متن tutiorial.
حالا سعی کنید از این رمزگشا استفاده کنید.
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
رسیور 4 ورودی می گیرد.
-
new_tokens- نشانه آخرین تولید می شود. مقداردهی اولیه رسیور با"[START]"رمز. -
enc_output- تولید شده توسطEncoder. -
mask- یک تانسور بولی نشان می دهد که در آنtokens != 0 -
state- قبلیstateخروجی از رسیور (وضعیت داخلی RNN رسیور است). رمز عبورNoneبه آن صفر مقداردهی اولیه. مقاله اصلی آن را از حالت RNN نهایی رمزگذار مقداردهی اولیه می کند.
# Convert the target sequence, and collect the "[START]" tokens
example_output_tokens = output_text_processor(example_target_batch)
start_index = output_text_processor.get_vocabulary().index('[START]')
first_token = tf.constant([[start_index]] * example_output_tokens.shape[0])
# Run the decoder
dec_result, dec_state = decoder(
inputs = DecoderInput(new_tokens=first_token,
enc_output=example_enc_output,
mask=(example_tokens != 0)),
state = example_enc_state
)
print(f'logits shape: (batch_size, t, output_vocab_size) {dec_result.logits.shape}')
print(f'state shape: (batch_size, dec_units) {dec_state.shape}')
logits shape: (batch_size, t, output_vocab_size) (64, 1, 5000) state shape: (batch_size, dec_units) (64, 1024)
نمونه ای از یک توکن با توجه به لاجیت ها:
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
رمزگشایی رمز به عنوان اولین کلمه خروجی:
vocab = np.array(output_text_processor.get_vocabulary())
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['already'],
['plants'],
['pretended'],
['convince'],
['square']], dtype='<U16')
اکنون از رمزگشا برای تولید مجموعه دوم لاجیت استفاده کنید.
- رمز عبور همان
enc_outputوmask، این تغییر نکرده است. - رمز عبور، نمونهبرداری رمز و
new_tokens. - رمز عبور
decoder_stateرسیور زمان گذشته بازگشت، به طوری که RNN با یک حافظه که در آن ترک کردن زمان گذشته همچنان ادامه دارد.
dec_result, dec_state = decoder(
DecoderInput(sampled_token,
example_enc_output,
mask=(example_tokens != 0)),
state=dec_state)
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['nap'],
['mean'],
['worker'],
['passage'],
['baked']], dtype='<U16')
آموزش
اکنون که تمام اجزای مدل را در اختیار دارید، زمان شروع آموزش مدل است. شما نیاز خواهید داشت:
- یک تابع ضرر و بهینه ساز برای انجام بهینه سازی.
- یک تابع مرحله آموزشی که نحوه به روز رسانی مدل را برای هر دسته ورودی/هدف تعریف می کند.
- یک حلقه آموزشی برای هدایت آموزش و ذخیره پست های بازرسی.
تابع ضرر را تعریف کنید
class MaskedLoss(tf.keras.losses.Loss):
def __init__(self):
self.name = 'masked_loss'
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def __call__(self, y_true, y_pred):
shape_checker = ShapeChecker()
shape_checker(y_true, ('batch', 't'))
shape_checker(y_pred, ('batch', 't', 'logits'))
# Calculate the loss for each item in the batch.
loss = self.loss(y_true, y_pred)
shape_checker(loss, ('batch', 't'))
# Mask off the losses on padding.
mask = tf.cast(y_true != 0, tf.float32)
shape_checker(mask, ('batch', 't'))
loss *= mask
# Return the total.
return tf.reduce_sum(loss)
مرحله آموزش را اجرا کنید
شروع با یک کلاس مدل، روند آموزش به عنوان اجرا train_step روش در این مدل است. مشاهده سفارشی متناسب برای جزئیات بیشتر.
در اینجا train_step روش یک پوشه در سراسر است _train_step پیاده سازی که بعد خواهد آمد. این لفاف بسته بندی شامل یک سوئیچ برای روشن و خاموش کردن tf.function تلفیقی، به اشکال زدایی آسان تر است.
class TrainTranslator(tf.keras.Model):
def __init__(self, embedding_dim, units,
input_text_processor,
output_text_processor,
use_tf_function=True):
super().__init__()
# Build the encoder and decoder
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.use_tf_function = use_tf_function
self.shape_checker = ShapeChecker()
def train_step(self, inputs):
self.shape_checker = ShapeChecker()
if self.use_tf_function:
return self._tf_train_step(inputs)
else:
return self._train_step(inputs)
به طور کلی اجرای برای Model.train_step روش به شرح زیر:
- دریافت یک دسته ای از
input_text, target_textازtf.data.Dataset. - آن ورودیهای متن خام را به توکنها و ماسکها تبدیل کنید.
- اجرای رمزگذار در
input_tokensبرای دریافتencoder_outputوencoder_state. - حالت رمزگشا و از دست دادن را راه اندازی کنید.
- حلقه بیش از
target_tokens:- رمزگشا را یک مرحله در یک زمان اجرا کنید.
- ضرر را برای هر مرحله محاسبه کنید.
- میانگین ضرر را جمع آوری کنید.
- محاسبه گرادیان از دست دادن و استفاده از بهینه ساز برای اعمال به روز رسانی به مدل
trainable_variables.
_preprocess روش، اضافه زیر، ادوات مراحل # 1 و # 2:
def _preprocess(self, input_text, target_text):
self.shape_checker(input_text, ('batch',))
self.shape_checker(target_text, ('batch',))
# Convert the text to token IDs
input_tokens = self.input_text_processor(input_text)
target_tokens = self.output_text_processor(target_text)
self.shape_checker(input_tokens, ('batch', 's'))
self.shape_checker(target_tokens, ('batch', 't'))
# Convert IDs to masks.
input_mask = input_tokens != 0
self.shape_checker(input_mask, ('batch', 's'))
target_mask = target_tokens != 0
self.shape_checker(target_mask, ('batch', 't'))
return input_tokens, input_mask, target_tokens, target_mask
TrainTranslator._preprocess = _preprocess
_train_step روش، اضافه زیر، دسته مراحل باقی مانده جز در واقع در حال اجرا رسیور:
def _train_step(self, inputs):
input_text, target_text = inputs
(input_tokens, input_mask,
target_tokens, target_mask) = self._preprocess(input_text, target_text)
max_target_length = tf.shape(target_tokens)[1]
with tf.GradientTape() as tape:
# Encode the input
enc_output, enc_state = self.encoder(input_tokens)
self.shape_checker(enc_output, ('batch', 's', 'enc_units'))
self.shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder's state to the encoder's final state.
# This only works if the encoder and decoder have the same number of
# units.
dec_state = enc_state
loss = tf.constant(0.0)
for t in tf.range(max_target_length-1):
# Pass in two tokens from the target sequence:
# 1. The current input to the decoder.
# 2. The target for the decoder's next prediction.
new_tokens = target_tokens[:, t:t+2]
step_loss, dec_state = self._loop_step(new_tokens, input_mask,
enc_output, dec_state)
loss = loss + step_loss
# Average the loss over all non padding tokens.
average_loss = loss / tf.reduce_sum(tf.cast(target_mask, tf.float32))
# Apply an optimization step
variables = self.trainable_variables
gradients = tape.gradient(average_loss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# Return a dict mapping metric names to current value
return {'batch_loss': average_loss}
TrainTranslator._train_step = _train_step
_loop_step روش، اضافه زیر، اجرا رسیور و محاسبه از دست دادن تدریجی و دولت رسیور جدید ( dec_state ).
def _loop_step(self, new_tokens, input_mask, enc_output, dec_state):
input_token, target_token = new_tokens[:, 0:1], new_tokens[:, 1:2]
# Run the decoder one step.
decoder_input = DecoderInput(new_tokens=input_token,
enc_output=enc_output,
mask=input_mask)
dec_result, dec_state = self.decoder(decoder_input, state=dec_state)
self.shape_checker(dec_result.logits, ('batch', 't1', 'logits'))
self.shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
self.shape_checker(dec_state, ('batch', 'dec_units'))
# `self.loss` returns the total for non-padded tokens
y = target_token
y_pred = dec_result.logits
step_loss = self.loss(y, y_pred)
return step_loss, dec_state
TrainTranslator._loop_step = _loop_step
مرحله آموزش را تست کنید
ساخت یک TrainTranslator ، و پیکربندی آن برای آموزش استفاده از Model.compile روش:
translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
use_tf_function=False)
# Configure the loss and optimizer
translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
تست کردن train_step . برای یک مدل متنی مانند این، ضرر باید از نزدیک شروع شود:
np.log(output_text_processor.vocabulary_size())
8.517193191416236
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.5849695>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.55271>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.4929113>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.3296022>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=6.80437>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.000246>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.8740363>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.794589>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.3175836>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.108163>}
CPU times: user 5.49 s, sys: 0 ns, total: 5.49 s
Wall time: 5.45 s
در حالی که آن را آسان تر برای اشکال زدایی بدون tf.function آن را به افزایش عملکرد. بنابراین در حال حاضر که _train_step روش کار، سعی کنید tf.function -wrapped _tf_train_step ، به حداکثر رساندن عملکرد در حالی که آموزش:
@tf.function(input_signature=[[tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])]])
def _tf_train_step(self, inputs):
return self._train_step(inputs)
TrainTranslator._tf_train_step = _tf_train_step
translator.use_tf_function = True
تماس اول کند خواهد بود، زیرا عملکرد را ردیابی می کند.
translator.train_step([example_input_batch, example_target_batch])
2021-12-04 12:09:48.074769: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.180156: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:09:48.285846: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:09:48.307794: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.425447: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node while/body/_1/while/TensorListPushBack_56 was passed float from while/body/_1/while/decoder_1/gru_3/PartitionedCall:6 incompatible with expected variant.
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.045638>}
اما پس از آن آن را معمولا 2-3x سریعتر از مشتاق train_step روش:
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.1098256>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.169871>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.139249>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.0410743>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.9664454>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.895707>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.8154407>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.7583396>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.6986444>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.640298>}
CPU times: user 4.4 s, sys: 960 ms, total: 5.36 s
Wall time: 1.67 s
یک آزمایش خوب برای یک مدل جدید این است که ببینیم می تواند برای یک دسته ورودی بیش از حد مناسب باشد. آن را امتحان کنید، ضرر باید به سرعت به صفر برسد:
losses = []
for n in range(100):
print('.', end='')
logs = translator.train_step([example_input_batch, example_target_batch])
losses.append(logs['batch_loss'].numpy())
print()
plt.plot(losses)
.................................................................................................... [<matplotlib.lines.Line2D at 0x7fb427edf210>]

اکنون که مطمئن هستید مرحله آموزش کار می کند، یک کپی جدید از مدل بسازید تا از ابتدا آموزش دهید:
train_translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor)
# Configure the loss and optimizer
train_translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
مدل را آموزش دهید
در حالی که این اشتباه است هیچ چیز با نوشتن خود حلقه آموزش سفارشی خود را، اجرا وجود دارد Model.train_step روش، همانطور که در بخش قبلی، اجازه می دهد تا شما را به اجرای Model.fit و جلوگیری از بازنویسی تمام که کد دیگ بخار ورق.
این آموزش تنها قطار برای چند دوره، بنابراین استفاده از callbacks.Callback به جمع آوری تاریخ تلفات دسته ای، برای توطئه:
class BatchLogs(tf.keras.callbacks.Callback):
def __init__(self, key):
self.key = key
self.logs = []
def on_train_batch_end(self, n, logs):
self.logs.append(logs[self.key])
batch_loss = BatchLogs('batch_loss')
train_translator.fit(dataset, epochs=3,
callbacks=[batch_loss])
Epoch 1/3
2021-12-04 12:10:11.617839: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:11.737105: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:10:11.855054: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:10:11.878896: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:12.004755: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node StatefulPartitionedCall/while/body/_59/while/TensorListPushBack_56 was passed float from StatefulPartitionedCall/while/body/_59/while/decoder_2/gru_5/PartitionedCall:6 incompatible with expected variant.
1859/1859 [==============================] - 349s 185ms/step - batch_loss: 2.0443
Epoch 2/3
1859/1859 [==============================] - 350s 188ms/step - batch_loss: 1.0382
Epoch 3/3
1859/1859 [==============================] - 343s 184ms/step - batch_loss: 0.8085
<keras.callbacks.History at 0x7fb42c3eda10>
plt.plot(batch_loss.logs)
plt.ylim([0, 3])
plt.xlabel('Batch #')
plt.ylabel('CE/token')
Text(0, 0.5, 'CE/token')
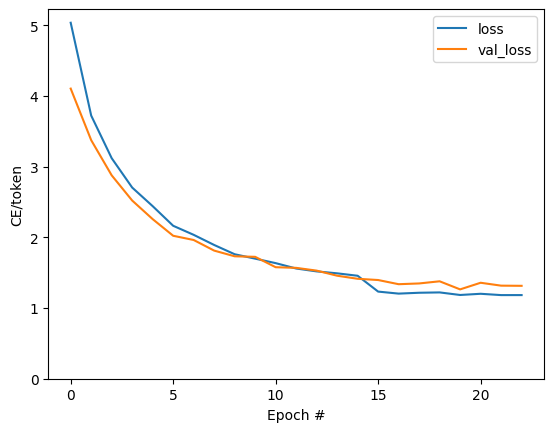
جهش های قابل مشاهده در طرح در مرزهای دوران هستند.
ترجمه کردن
حالا که مدل آموزش داده شده است، اجرای یک تابع به طور کامل اجرا text => text ترجمه.
برای این نیازهای مدل به وارونه text => token IDs نقشه برداری توسط ارائه output_text_processor . همچنین باید شناسه های توکن های خاص را بداند. همه اینها در سازنده کلاس جدید پیاده سازی شده است. پیاده سازی روش ترجمه واقعی به دنبال خواهد بود.
به طور کلی این شبیه به حلقه آموزشی است، با این تفاوت که ورودی به رمزگشا در هر مرحله زمانی نمونه ای از آخرین پیش بینی رمزگشا است.
class Translator(tf.Module):
def __init__(self, encoder, decoder, input_text_processor,
output_text_processor):
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.output_token_string_from_index = (
tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(),
mask_token='',
invert=True))
# The output should never generate padding, unknown, or start.
index_from_string = tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(), mask_token='')
token_mask_ids = index_from_string(['', '[UNK]', '[START]']).numpy()
token_mask = np.zeros([index_from_string.vocabulary_size()], dtype=np.bool)
token_mask[np.array(token_mask_ids)] = True
self.token_mask = token_mask
self.start_token = index_from_string(tf.constant('[START]'))
self.end_token = index_from_string(tf.constant('[END]'))
translator = Translator(
encoder=train_translator.encoder,
decoder=train_translator.decoder,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:21: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
شناسه های رمز را به متن تبدیل کنید
روش اول برای پیاده سازی است tokens_to_text که تبدیل از شناسه رمز به متن قابل خواندن توسط انسان.
def tokens_to_text(self, result_tokens):
shape_checker = ShapeChecker()
shape_checker(result_tokens, ('batch', 't'))
result_text_tokens = self.output_token_string_from_index(result_tokens)
shape_checker(result_text_tokens, ('batch', 't'))
result_text = tf.strings.reduce_join(result_text_tokens,
axis=1, separator=' ')
shape_checker(result_text, ('batch'))
result_text = tf.strings.strip(result_text)
shape_checker(result_text, ('batch',))
return result_text
Translator.tokens_to_text = tokens_to_text
تعدادی شناسه رمز تصادفی را وارد کنید و ببینید چه چیزی ایجاد می کند:
example_output_tokens = tf.random.uniform(
shape=[5, 2], minval=0, dtype=tf.int64,
maxval=output_text_processor.vocabulary_size())
translator.tokens_to_text(example_output_tokens).numpy()
array([b'vain mysteries', b'funny ham', b'drivers responding',
b'mysterious ignoring', b'fashion votes'], dtype=object)
نمونه ای از پیش بینی های رمزگشا
این تابع خروجی های لاجیت رمزگشا را می گیرد و شناسه های توکن را از آن توزیع نمونه برداری می کند:
def sample(self, logits, temperature):
shape_checker = ShapeChecker()
# 't' is usually 1 here.
shape_checker(logits, ('batch', 't', 'vocab'))
shape_checker(self.token_mask, ('vocab',))
token_mask = self.token_mask[tf.newaxis, tf.newaxis, :]
shape_checker(token_mask, ('batch', 't', 'vocab'), broadcast=True)
# Set the logits for all masked tokens to -inf, so they are never chosen.
logits = tf.where(self.token_mask, -np.inf, logits)
if temperature == 0.0:
new_tokens = tf.argmax(logits, axis=-1)
else:
logits = tf.squeeze(logits, axis=1)
new_tokens = tf.random.categorical(logits/temperature,
num_samples=1)
shape_checker(new_tokens, ('batch', 't'))
return new_tokens
Translator.sample = sample
این تابع را روی برخی از ورودی های تصادفی آزمایش کنید:
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
<tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[4506],
[3577],
[2961],
[4586],
[ 944]])>
حلقه ترجمه را پیاده سازی کنید
در اینجا یک پیاده سازی کامل از حلقه ترجمه متن به متن است.
این پیاده سازی جمع آوری نتایج را به لیست پایتون، قبل از استفاده از tf.concat میکند آنها را در تانسورها.
این پیاده سازی استاتیک unrolls نمودار به max_length تکرار. این با اجرای مشتاقانه در پایتون مشکلی ندارد.
def translate_unrolled(self,
input_text, *,
max_length=50,
return_attention=True,
temperature=1.0):
batch_size = tf.shape(input_text)[0]
input_tokens = self.input_text_processor(input_text)
enc_output, enc_state = self.encoder(input_tokens)
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
result_tokens = []
attention = []
done = tf.zeros([batch_size, 1], dtype=tf.bool)
for _ in range(max_length):
dec_input = DecoderInput(new_tokens=new_tokens,
enc_output=enc_output,
mask=(input_tokens!=0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
attention.append(dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens.append(new_tokens)
if tf.executing_eagerly() and tf.reduce_all(done):
break
# Convert the list of generates token ids to a list of strings.
result_tokens = tf.concat(result_tokens, axis=-1)
result_text = self.tokens_to_text(result_tokens)
if return_attention:
attention_stack = tf.concat(attention, axis=1)
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_unrolled
آن را روی یک ورودی ساده اجرا کنید:
%%time
input_text = tf.constant([
'hace mucho frio aqui.', # "It's really cold here."
'Esta es mi vida.', # "This is my life.""
])
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its a long cold here . this is my life . CPU times: user 165 ms, sys: 4.37 ms, total: 169 ms Wall time: 164 ms
اگر شما می خواهید به صادرات این مدل شما نیاز به قرار دادن این روش در یک tf.function . اگر بخواهید این کار را انجام دهید، این پیاده سازی اساسی چند مشکل دارد:
- نمودارهای به دست آمده بسیار بزرگ هستند و ساخت، ذخیره یا بارگذاری چند ثانیه طول می کشد.
- شما نمی توانید از یک حلقه آماری نعوظ شکستن، پس از آن همیشه اجرا خواهد شد
max_lengthتکرار، حتی اگر تمام خروجی انجام می شود. اما حتی در این صورت هم به طور جزئی سریعتر از اجرای مشتاقانه است.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
اجرای tf.function یک بار آن را کامپایل:
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 18.8 s, sys: 0 ns, total: 18.8 s Wall time: 18.7 s
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 88 ms
[اختیاری] از یک حلقه نمادین استفاده کنید
def translate_symbolic(self,
input_text,
*,
max_length=50,
return_attention=True,
temperature=1.0):
shape_checker = ShapeChecker()
shape_checker(input_text, ('batch',))
batch_size = tf.shape(input_text)[0]
# Encode the input
input_tokens = self.input_text_processor(input_text)
shape_checker(input_tokens, ('batch', 's'))
enc_output, enc_state = self.encoder(input_tokens)
shape_checker(enc_output, ('batch', 's', 'enc_units'))
shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
shape_checker(new_tokens, ('batch', 't1'))
# Initialize the accumulators
result_tokens = tf.TensorArray(tf.int64, size=1, dynamic_size=True)
attention = tf.TensorArray(tf.float32, size=1, dynamic_size=True)
done = tf.zeros([batch_size, 1], dtype=tf.bool)
shape_checker(done, ('batch', 't1'))
for t in tf.range(max_length):
dec_input = DecoderInput(
new_tokens=new_tokens, enc_output=enc_output, mask=(input_tokens != 0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
attention = attention.write(t, dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
shape_checker(dec_result.logits, ('batch', 't1', 'vocab'))
shape_checker(new_tokens, ('batch', 't1'))
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens = result_tokens.write(t, new_tokens)
if tf.reduce_all(done):
break
# Convert the list of generated token ids to a list of strings.
result_tokens = result_tokens.stack()
shape_checker(result_tokens, ('t', 'batch', 't0'))
result_tokens = tf.squeeze(result_tokens, -1)
result_tokens = tf.transpose(result_tokens, [1, 0])
shape_checker(result_tokens, ('batch', 't'))
result_text = self.tokens_to_text(result_tokens)
shape_checker(result_text, ('batch',))
if return_attention:
attention_stack = attention.stack()
shape_checker(attention_stack, ('t', 'batch', 't1', 's'))
attention_stack = tf.squeeze(attention_stack, 2)
shape_checker(attention_stack, ('t', 'batch', 's'))
attention_stack = tf.transpose(attention_stack, [1, 0, 2])
shape_checker(attention_stack, ('batch', 't', 's'))
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_symbolic
پیاده سازی اولیه از لیست های پایتون برای جمع آوری خروجی ها استفاده می کرد. این با استفاده از tf.range عنوان تکرارکننده حلقه، اجازه می دهد tf.autograph برای تبدیل حلقه. بزرگترین تغییر در این پیاده سازی، استفاده از tf.TensorArray جای پایتون list به تانسورها تجمع می یابد. tf.TensorArray مورد نیاز است برای جمع آوری یک تعداد متغیر از تانسورها در حالت نمودار.
با اجرای مشتاقانه، این پیاده سازی همتراز با نسخه اصلی است:
%%time
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 170 ms
اما زمانی که شما آن را در یک بسته بندی tf.function شما دو تفاوتها دقت کنید.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
اول: ایجاد نمودار بسیار سریعتر (~ تا 10x)، از آن را ایجاد کنید max_iterations نسخه از مدل.
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 1.79 s, sys: 0 ns, total: 1.79 s Wall time: 1.77 s
دوم: تابع کامپایل شده در ورودی های کوچک بسیار سریعتر است (در این مثال 5 برابر)، زیرا می تواند از حلقه خارج شود.
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 40.1 ms, sys: 0 ns, total: 40.1 ms Wall time: 17.1 ms
فرآیند را تجسم کنید
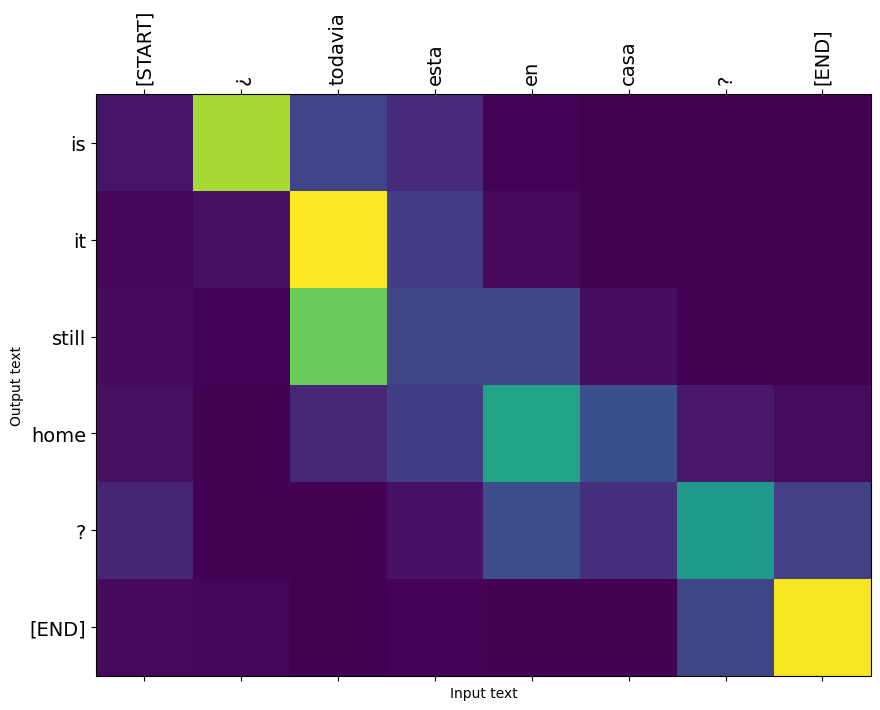
وزن توجه بازگردانده شده توسط translate روش نشان می دهد که در آن مدل بود "به دنبال" هنگامی که آن را تولید هر نشانه خروجی.
بنابراین مجموع توجه به ورودی باید همه موارد را برگرداند:
a = result['attention'][0]
print(np.sum(a, axis=-1))
[1.0000001 0.99999994 1. 0.99999994 1. 0.99999994]
در اینجا توزیع توجه برای اولین مرحله خروجی از مثال اول است. توجه داشته باشید که چگونه توجه اکنون بسیار بیشتر از مدل آموزش ندیده متمرکز شده است:
_ = plt.bar(range(len(a[0, :])), a[0, :])

از آنجایی که بین کلمات ورودی و خروجی مقداری تراز ناهمواری وجود دارد، انتظار دارید که توجه نزدیک به مورب متمرکز شود:
plt.imshow(np.array(a), vmin=0.0)
<matplotlib.image.AxesImage at 0x7faf2886ced0>

در اینجا چند کد برای ایجاد نمودار توجه بهتر وجود دارد:
طرح های توجه با برچسب
def plot_attention(attention, sentence, predicted_sentence):
sentence = tf_lower_and_split_punct(sentence).numpy().decode().split()
predicted_sentence = predicted_sentence.numpy().decode().split() + ['[END]']
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
attention = attention[:len(predicted_sentence), :len(sentence)]
ax.matshow(attention, cmap='viridis', vmin=0.0)
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xlabel('Input text')
ax.set_ylabel('Output text')
plt.suptitle('Attention weights')
i=0
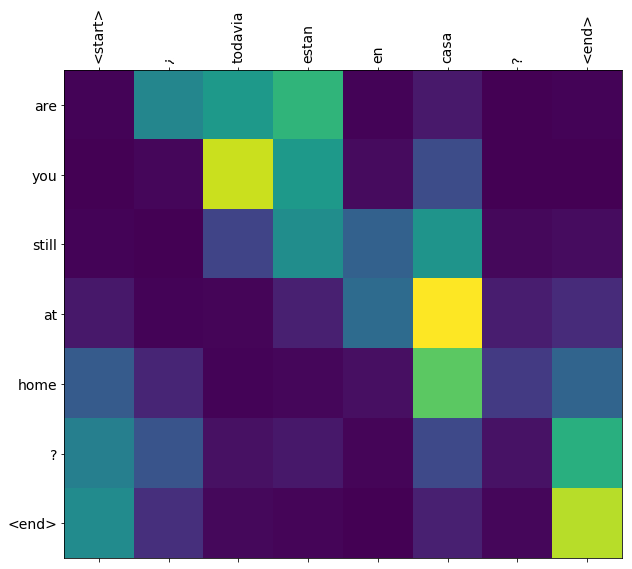
plot_attention(result['attention'][i], input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
چند جمله دیگر را ترجمه کنید و آنها را ترسیم کنید:
%%time
three_input_text = tf.constant([
# This is my life.
'Esta es mi vida.',
# Are they still home?
'¿Todavía están en casa?',
# Try to find out.'
'Tratar de descubrir.',
])
result = translator.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? all about killed . CPU times: user 78 ms, sys: 23 ms, total: 101 ms Wall time: 23.1 ms
result['text']
<tf.Tensor: shape=(3,), dtype=string, numpy=
array([b'this is my life .', b'are you still at home ?',
b'all about killed .'], dtype=object)>
i = 0
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 1
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 2
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

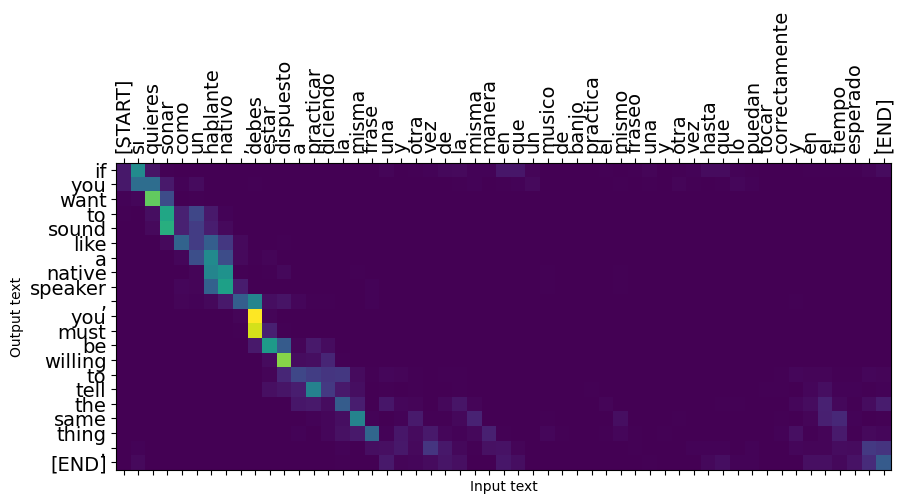
جملات کوتاه اغلب به خوبی کار می کنند، اما اگر ورودی بیش از حد طولانی باشد، مدل به معنای واقعی کلمه تمرکز خود را از دست می دهد و ارائه پیش بینی های معقول را متوقف می کند. دو دلیل اصلی برای این وجود دارد:
- این مدل بدون توجه به پیشبینیهای مدل، با تغذیه اجباری توسط معلم در هر مرحله آموزش داده شد. اگر گاهی اوقات پیشبینیهای خودش را تامین میکرد، این مدل میتوانست قویتر شود.
- مدل فقط از طریق حالت RNN به خروجی قبلی خود دسترسی دارد. اگر حالت RNN خراب شود، راهی برای بازیابی مدل وجود ندارد. ترانسفورماتور این حل با استفاده از خود توجه در رمز گذار و رمز.
long_input_text = tf.constant([inp[-1]])
import textwrap
print('Expected output:\n', '\n'.join(textwrap.wrap(targ[-1])))
Expected output: If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
result = translator.tf_translate(long_input_text)
i = 0
plot_attention(result['attention'][i], long_input_text[i], result['text'][i])
_ = plt.suptitle('This never works')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
صادرات
هنگامی که شما یک مدل شما با شما راضی ممکن است بخواهید به صادرات آن به عنوان یک tf.saved_model برای استفاده در خارج از این برنامه پایتون می باشد که آن را ایجاد کرده است.
از آنجا که مدل یک زیر کلاس از است tf.Module (از طریق keras.Model )، و تمام قابلیت های صادراتی در وارد tf.function مدل باید پاک با صادرات tf.saved_model.save :
حالا که تابع ترسیم شده می توان آن را با استفاده از صادر saved_model.save :
tf.saved_model.save(translator, 'translator',
signatures={'serving_default': translator.tf_translate})
2021-12-04 12:27:54.310890: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as encoder_2_layer_call_fn, encoder_2_layer_call_and_return_conditional_losses, decoder_2_layer_call_fn, decoder_2_layer_call_and_return_conditional_losses, embedding_4_layer_call_fn while saving (showing 5 of 60). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: translator/assets INFO:tensorflow:Assets written to: translator/assets
reloaded = tf.saved_model.load('translator')
result = reloaded.tf_translate(three_input_text)
%%time
result = reloaded.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? find out about to find out . CPU times: user 42.8 ms, sys: 7.69 ms, total: 50.5 ms Wall time: 20 ms
مراحل بعدی
- دانلود یک مجموعه داده های مختلف به آزمایش با ترجمه، برای مثال، انگلیسی به آلمانی و یا انگلیسی به فرانسوی.
- با آموزش روی یک مجموعه داده بزرگتر یا استفاده از دوره های بیشتر آزمایش کنید.
- سعی کنید ترانسفورماتور آموزش که پیاده سازی یک کار ترجمه مشابه اما با استفاده از یک لایه ترانسفورماتور به جای RNNs. این نسخه همچنین با استفاده از یک
text.BertTokenizerبرای پیاده سازی از Tokenization wordpiece. - یک نگاه در tensorflow_addons.seq2seq برای اجرای این نوع از توالی به مدل دنباله.
tfa.seq2seqبسته شامل قابلیت سطح بالا مثلseq2seq.BeamSearchDecoder.