
TFDV(TensorFlow Data Validation)는 학습 및 제공 데이터를 분석하여 다음을 수행할 수 있습니다.
기술통계 계산 ,
스키마 를 추론하고,
데이터 이상 징후를 감지합니다.
핵심 API는 위에 구축되고 노트북 컨텍스트에서 호출할 수 있는 편리한 메서드를 통해 각 기능을 지원합니다.
기술 데이터 통계 계산
TFDV는 존재하는 기능과 값 분포의 모양 측면에서 데이터에 대한 빠른 개요를 제공하는 기술 통계를 계산할 수 있습니다. 패싯 개요 와 같은 도구는 쉽게 탐색할 수 있도록 이러한 통계를 간결하게 시각화할 수 있습니다.
예를 들어 path 가 TFRecord 형식( tensorflow.Example 유형의 레코드를 보유함)의 파일을 가리킨다고 가정해 보겠습니다. 다음 스니펫은 TFDV를 사용한 통계 계산을 보여줍니다.
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
반환된 값은 DatasetFeatureStatisticsList 프로토콜 버퍼입니다. 예제 노트북에는 Facets 개요를 사용한 통계 시각화가 포함되어 있습니다.
tfdv.visualize_statistics(stats)
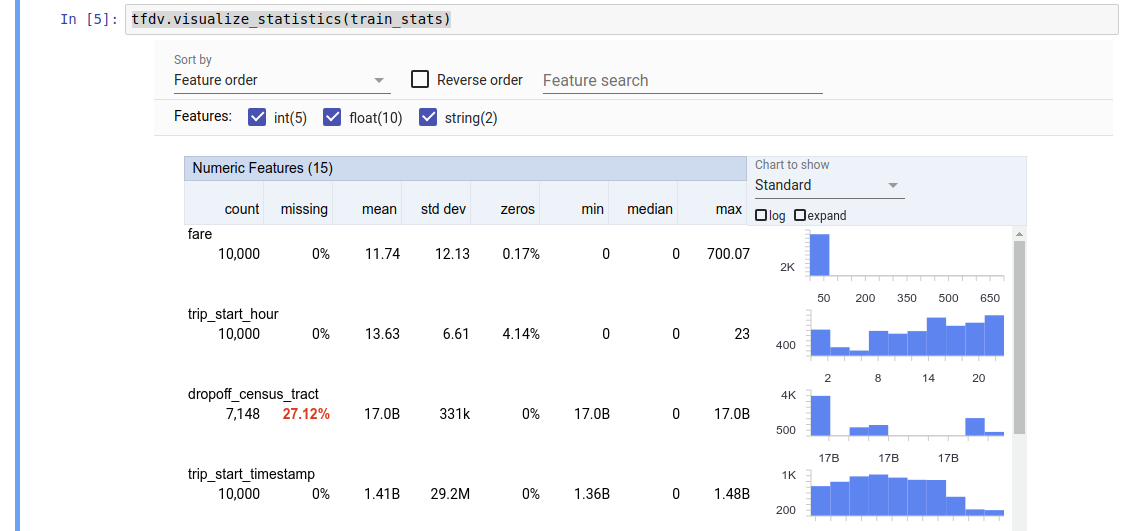
이전 예에서는 데이터가 TFRecord 파일에 저장되어 있다고 가정합니다. TFDV는 또한 다른 일반적인 형식에 대한 확장성을 갖춘 CSV 입력 형식을 지원합니다. 여기에서 사용 가능한 데이터 디코더를 찾을 수 있습니다. 또한 TFDV는 Pandas DataFrame으로 표시되는 메모리 내 데이터를 사용하는 사용자를 위해 tfdv.generate_statistics_from_dataframe 유틸리티 함수를 제공합니다.
기본 데이터 통계 세트를 계산하는 것 외에도 TFDV는 의미 영역(예: 이미지, 텍스트)에 대한 통계도 계산할 수 있습니다. 의미 도메인 통계 계산을 활성화하려면, enable_semantic_domain_stats True로 설정된 tfdv.StatsOptions 객체를 tfdv.generate_statistics_from_tfrecord 에 전달하세요.
Google Cloud에서 실행
내부적으로 TFDV는 Apache Beam 의 데이터 병렬 처리 프레임워크를 사용하여 대규모 데이터 세트에 대한 통계 계산을 확장합니다. TFDV와 더 깊이 통합하려는 애플리케이션(예: 데이터 생성 파이프라인 끝에 통계 생성 연결, 사용자 정의 형식으로 데이터에 대한 통계 생성 )의 경우 API는 통계 생성을 위해 Beam PTransform도 노출합니다.
Google Cloud에서 TFDV를 실행하려면 TFDV 휠 파일을 다운로드하여 Dataflow 작업자에게 제공해야 합니다. 다음과 같이 휠 파일을 현재 디렉터리에 다운로드합니다.
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
다음 스니펫은 Google Cloud에서 TFDV를 사용하는 예시를 보여줍니다.
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
이 경우 생성된 통계 proto는 GCS_STATS_OUTPUT_PATH 에 기록된 TFRecord 파일에 저장됩니다.
참고 GCP에서 tfdv.generate_statistics_... 함수(예: tfdv.generate_statistics_from_tfrecord )를 호출할 때 output_path 를 제공해야 합니다. 없음을 지정하면 오류가 발생할 수 있습니다.
데이터에 대한 스키마 추론
스키마는 데이터의 예상 속성을 설명합니다. 이러한 속성 중 일부는 다음과 같습니다.
- 어떤 기능이 있을 것으로 예상되는지
- 그들의 유형
- 각 예의 특성 값 수
- 모든 예에서 각 기능의 존재
- 예상되는 기능 영역.
간단히 말해서, 스키마는 "올바른" 데이터에 대한 기대치를 설명하므로 데이터의 오류를 감지하는 데 사용할 수 있습니다(아래 설명 참조). 또한 동일한 스키마를 사용하여 데이터 변환을 위한 TensorFlow Transform을 설정할 수 있습니다. 스키마는 상당히 정적일 것으로 예상됩니다. 예를 들어 여러 데이터 세트가 동일한 스키마를 따를 수 있는 반면 통계(위에 설명됨)는 데이터 세트마다 다를 수 있습니다.
스키마 작성은 특히 기능이 많은 데이터 세트의 경우 지루한 작업일 수 있으므로 TFDV는 기술 통계를 기반으로 스키마의 초기 버전을 생성하는 방법을 제공합니다.
schema = tfdv.infer_schema(stats)
일반적으로 TFDV는 특정 데이터 세트에 대한 스키마의 과적합을 방지하기 위해 보수적인 휴리스틱을 사용하여 통계에서 안정적인 데이터 속성을 추론합니다. 추론된 스키마를 검토하고 필요에 따라 구체화하여 TFDV의 휴리스틱이 놓쳤을 수 있는 데이터에 대한 도메인 지식을 캡처하는 것이 좋습니다.
기본적으로 tfdv.infer_schema value_count.min 해당 기능의 value_count.max 와 같은 경우 필요한 각 기능의 모양을 추론합니다. 모양 추론을 비활성화하려면 infer_feature_shape 인수를 False로 설정합니다.
스키마 자체는 스키마 프로토콜 버퍼 로 저장되므로 표준 프로토콜 버퍼 API를 사용하여 업데이트/편집할 수 있습니다. TFDV는 또한 이러한 업데이트를 더 쉽게 만들 수 있는 몇 가지 유틸리티 방법을 제공합니다. 예를 들어 스키마에 단일 값을 사용하는 필수 문자열 기능인 payment_type 을 설명하는 다음 스탠자가 포함되어 있다고 가정해 보겠습니다.
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
예의 50% 이상에서 기능이 채워져야 함을 표시하려면 다음을 수행하세요.
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
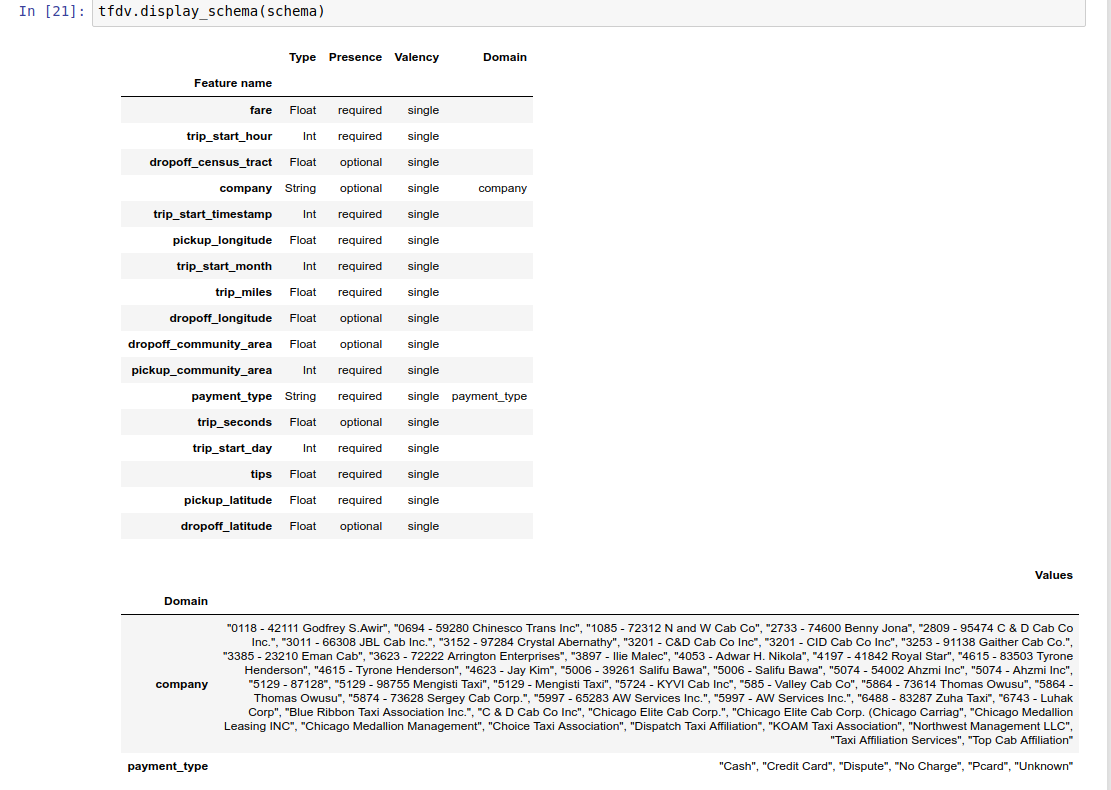
예제 노트북에는 스키마의 간단한 시각화가 테이블로 포함되어 있으며 각 기능과 해당 주요 특성이 스키마에 인코딩되어 나열되어 있습니다.
데이터 오류 확인
스키마가 주어지면 데이터 세트가 스키마에 설정된 기대치를 준수하는지 또는 데이터 이상이 존재하는지 확인할 수 있습니다. (a) 데이터 세트의 통계를 스키마와 일치시키거나 (b) 예시별로 오류를 확인하여 전체 데이터 세트에서 집계된 데이터의 오류를 확인할 수 있습니다.
데이터 세트의 통계를 스키마와 비교
집계된 오류를 확인하기 위해 TFDV는 데이터 세트의 통계를 스키마와 일치시키고 불일치를 표시합니다. 예를 들어:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
결과는 Anomalies 프로토콜 버퍼의 인스턴스이며 통계가 스키마와 일치하지 않는 오류를 설명합니다. 예를 들어 other_path 의 데이터에 스키마에 지정된 도메인 외부에 있는 payment_type 기능에 대한 값이 포함된 예가 포함되어 있다고 가정해 보겠습니다.
이로 인해 이상 현상이 발생합니다.
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
이는 통계에서 특성 값의 1% 미만으로 도메인 외부 값이 발견되었음을 나타냅니다.
이것이 예상된 경우 스키마는 다음과 같이 업데이트될 수 있습니다.
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
이상이 실제로 데이터 오류를 나타내는 경우 기본 데이터를 훈련에 사용하기 전에 수정해야 합니다.
이 모듈에서 감지할 수 있는 다양한 이상 유형이 여기에 나열되어 있습니다.
예제 노트북에는 오류가 감지된 기능과 각 오류에 대한 간단한 설명을 나열하는 테이블 형태의 간단한 시각화가 포함되어 있습니다.

예제별로 오류 확인
TFDV는 또한 데이터 세트 전체의 통계를 스키마와 비교하는 대신 예제별로 데이터의 유효성을 검사하는 옵션도 제공합니다. TFDV는 사례별로 데이터를 검증한 다음 발견된 비정상적인 사례에 대한 요약 통계를 생성하는 기능을 제공합니다. 예를 들어:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
validate_examples_in_tfrecord 반환하는 anomalous_example_stats 는 각 데이터 세트가 특정 변칙을 나타내는 예제 집합으로 구성된 DatasetFeatureStatisticsList 프로토콜 버퍼입니다. 이를 사용하여 특정 변칙을 나타내는 데이터 세트의 예 수와 해당 예의 특성을 확인할 수 있습니다.
스키마 환경
기본적으로 유효성 검사에서는 파이프라인의 모든 데이터 세트가 단일 스키마를 준수한다고 가정합니다. 어떤 경우에는 약간의 스키마 변형을 도입해야 합니다. 예를 들어 라벨로 사용되는 기능은 학습 중에는 필요하지만(검증해야 함) 제공 중에는 누락됩니다.
이러한 요구사항을 표현하기 위해 환경을 사용할 수 있습니다. 특히, 스키마의 기능은 default_environment, in_environment 및 not_in_environment를 사용하여 환경 세트와 연관될 수 있습니다.
예를 들어 팁 기능이 학습에서 라벨로 사용되고 있지만 제공 데이터에서는 누락된 경우입니다. 환경을 지정하지 않으면 이상으로 표시됩니다.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

이 문제를 해결하려면 모든 기능의 기본 환경을 'TRAINING'과 'SERVING'으로 설정하고 SERVING 환경에서 'tips' 기능을 제외해야 합니다.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
데이터 편향 및 드리프트 확인
데이터세트가 스키마에 설정된 기대치를 준수하는지 확인하는 것 외에도 TFDV는 다음을 감지하는 기능도 제공합니다.
- 학습 데이터와 제공 데이터 사이의 왜곡
- 훈련 데이터의 다른 날 사이의 드리프트
TFDV는 스키마에 지정된 드리프트/기울기 비교기를 기반으로 다양한 데이터 세트의 통계를 비교하여 이 검사를 수행합니다. 예를 들어 학습 데이터세트와 제공 데이터세트 내 '결제_유형' 기능 간에 차이가 있는지 확인하려면 다음 안내를 따르세요.
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
참고 L-무한대 표준은 범주형 기능에 대한 편향만 감지합니다. infinity_norm 임계값을 지정하는 대신, skew_comparator 에 jensen_shannon_divergence 임계값을 지정하면 숫자 및 범주형 특성 모두에 대한 편향을 감지합니다.
데이터 세트가 스키마에 설정된 기대치를 준수하는지 확인하는 것과 마찬가지로 결과는 Anomalies 프로토콜 버퍼의 인스턴스이기도 하며 학습 데이터 세트와 제공 데이터 세트 간의 왜곡을 설명합니다. 예를 들어 제공 데이터에 Cash 값이 있는 payement_type 기능이 있는 훨씬 더 많은 예가 포함되어 있다고 가정하면 편향 이상이 발생합니다.
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
이상이 실제로 학습 데이터와 제공 데이터 사이의 편향을 나타내는 경우 모델 성능에 직접적인 영향을 미칠 수 있으므로 추가 조사가 필요합니다.
예제 노트북에는 편향 기반 이상을 확인하는 간단한 예가 포함되어 있습니다.
훈련 데이터의 여러 날짜 간의 드리프트를 유사한 방식으로 감지할 수 있습니다.
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
참고 L-무한대 표준은 범주형 기능에 대한 편향만 감지합니다. infinity_norm 임계값을 지정하는 대신, skew_comparator 에 jensen_shannon_divergence 임계값을 지정하면 숫자 및 범주형 특성 모두에 대한 편향을 감지합니다.
사용자 정의 데이터 커넥터 작성
데이터 통계를 계산하기 위해 TFDV는 다양한 형식(예: tf.train.Example 의 TFRecord , CSV 등)의 입력 데이터를 처리할 수 있는 몇 가지 편리한 방법을 제공합니다. 데이터 형식이 이 목록에 없으면 입력 데이터를 읽기 위한 사용자 지정 데이터 커넥터를 작성하고 이를 TFDV 코어 API와 연결하여 데이터 통계를 계산해야 합니다.
데이터 통계 계산을 위한 TFDV 핵심 API 는 입력 예제 배치의 PCollection(입력 예제 배치는 Arrow RecordBatch로 표시됨)을 취하고 단일 DatasetFeatureStatisticsList 프로토콜 버퍼가 포함된 PCollection을 출력하는 Beam PTransform 입니다.
Arrow RecordBatch에서 입력 예제를 일괄 처리하는 사용자 정의 데이터 커넥터를 구현한 후에는 데이터 통계를 계산하기 위해 이를 tfdv.GenerateStatistics API와 연결해야 합니다. tf.train.Example 의 TFRecord 예로 들어 보겠습니다. tfx_bsl TFExampleRecord 데이터 커넥터를 제공하며, 아래는 이를 tfdv.GenerateStatistics API와 연결하는 방법의 예입니다.
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
데이터 조각에 대한 통계 계산
데이터 조각에 대한 통계를 계산하도록 TFDV를 구성할 수 있습니다. Arrow RecordBatch 받아 일련의 튜플 형식 (slice key, record batch) 을 출력하는 슬라이싱 기능을 제공하여 슬라이싱을 활성화할 수 있습니다. TFDV는 통계를 계산할 때 tfdv.StatsOptions 의 일부로 제공될 수 있는 특성 값 기반 슬라이싱 함수를 생성하는 쉬운 방법을 제공합니다.
조각화가 활성화되면 출력 DatasetFeatureStatisticsList proto에는 조각당 하나씩 여러 DatasetFeatureStatistics proto가 포함됩니다. 각 조각은 DatasetFeatureStatistics proto에서 데이터세트 이름 으로 설정된 고유한 이름으로 식별됩니다. 기본적으로 TFDV는 구성된 슬라이스 외에도 전체 데이터 세트에 대한 통계를 계산합니다.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])