
Metadata ML (MLMD) adalah perpustakaan untuk merekam dan mengambil metadata yang terkait dengan alur kerja pengembang ML dan ilmuwan data. MLMD merupakan bagian integral dari TensorFlow Extended (TFX) , namun dirancang agar dapat digunakan secara mandiri.
Setiap proses pipeline ML produksi menghasilkan metadata yang berisi informasi tentang berbagai komponen pipeline, eksekusinya (misalnya proses pelatihan), dan artefak yang dihasilkan (misalnya model yang dilatih). Jika terjadi perilaku atau kesalahan alur yang tidak terduga, metadata ini dapat dimanfaatkan untuk menganalisis silsilah komponen alur dan masalah debug. Anggaplah metadata ini setara dengan masuk dalam pengembangan perangkat lunak.
MLMD membantu Anda memahami dan menganalisis semua bagian yang saling berhubungan dari pipeline ML Anda alih-alih menganalisisnya secara terpisah dan dapat membantu Anda menjawab pertanyaan tentang pipeline ML Anda seperti:
- Pada kumpulan data manakah model tersebut dilatih?
- Hyperparameter apa yang digunakan untuk melatih model?
- Proses pipeline manakah yang membuat model?
- Pelatihan manakah yang menghasilkan model ini?
- Versi TensorFlow manakah yang membuat model ini?
- Kapan model yang gagal diluncurkan?
Penyimpanan metadata
MLMD mendaftarkan jenis metadata berikut dalam database yang disebut Penyimpanan Metadata .
- Metadata tentang artefak yang dihasilkan melalui komponen/langkah pipeline ML Anda
- Metadata tentang eksekusi komponen/langkah ini
- Metadata tentang saluran pipa dan informasi silsilah terkait
Penyimpanan Metadata menyediakan API untuk mencatat dan mengambil metadata ke dan dari backend penyimpanan. Backend penyimpanan dapat dicolokkan dan dapat diperluas. MLMD menyediakan implementasi referensi untuk SQLite (yang mendukung in-memory dan disk) dan MySQL out of the box.
Grafik ini menunjukkan ikhtisar tingkat tinggi dari berbagai komponen yang merupakan bagian dari MLMD.
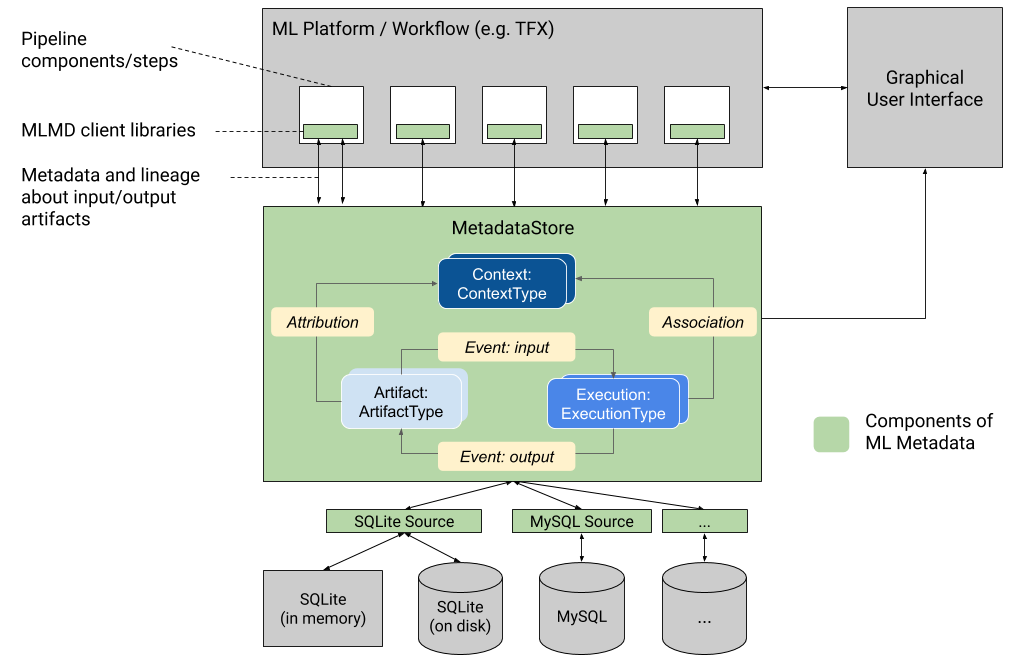
Backend penyimpanan metadata dan konfigurasi koneksi penyimpanan
Objek MetadataStore menerima konfigurasi koneksi yang sesuai dengan backend penyimpanan yang digunakan.
- Database Palsu menyediakan DB dalam memori (menggunakan SQLite) untuk eksperimen cepat dan pengoperasian lokal. Basis data dihapus ketika objek penyimpanan dimusnahkan.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite membaca dan menulis file dari disk.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL terhubung ke server MySQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
Demikian pula, ketika menggunakan instance MySQL dengan Google CloudSQL ( quickstart , connect-overview ), seseorang juga dapat menggunakan opsi SSL jika berlaku.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL terhubung ke server PostgreSQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
Demikian pula, ketika menggunakan instance PostgreSQL dengan Google CloudSQL ( quickstart , connect-overview ), seseorang juga dapat menggunakan opsi SSL jika berlaku.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
Model data
Penyimpanan Metadata menggunakan model data berikut untuk merekam dan mengambil metadata dari backend penyimpanan.
-
ArtifactTypemenjelaskan tipe artefak dan propertinya yang disimpan di penyimpanan metadata. Anda dapat mendaftarkan jenis ini dengan cepat dengan penyimpanan metadata dalam kode, atau Anda dapat memuatnya di penyimpanan dari format serial. Setelah Anda mendaftarkan suatu jenis, definisinya tersedia sepanjang masa penyimpanan. -
Artifactmendeskripsikan instance spesifik dariArtifactType, dan propertinya yang ditulis ke penyimpanan metadata. -
ExecutionTypemenjelaskan tipe komponen atau langkah dalam alur kerja, dan parameter runtime-nya. -
Executionadalah rekaman eksekusi komponen atau langkah dalam alur kerja ML dan parameter runtime. Eksekusi dapat dianggap sebagai turunan dariExecutionType. Eksekusi dicatat saat Anda menjalankan alur atau langkah ML. -
Eventadalah catatan hubungan antara artefak dan eksekusi. Saat eksekusi terjadi, peristiwa mencatat setiap artefak yang digunakan oleh eksekusi, dan setiap artefak yang dihasilkan. Catatan ini memungkinkan pelacakan silsilah di seluruh alur kerja. Dengan melihat semua kejadian, MLMD mengetahui eksekusi apa yang terjadi dan artefak apa yang dibuat sebagai hasilnya. MLMD kemudian dapat melakukan perulangan kembali dari artefak apa pun ke semua input hulunya. -
ContextTypemenjelaskan tipe grup konseptual artefak dan eksekusi dalam alur kerja, dan properti strukturalnya. Misalnya: proyek, proses pipeline, eksperimen, pemilik, dll. -
Contextadalah turunan dariContextType. Ini menangkap informasi yang dibagikan dalam grup. Misalnya: nama proyek, id penerapan daftar perubahan, anotasi eksperimen, dll. Ia memiliki nama unik yang ditentukan pengguna di dalamContextType-nya. -
Attributionadalah catatan hubungan antara artefak dan konteks. -
Associationadalah catatan hubungan antara eksekusi dan konteks.
Fungsi MLMD
Melacak masukan dan keluaran semua komponen/langkah dalam alur kerja ML dan silsilahnya memungkinkan platform ML mengaktifkan beberapa fitur penting. Daftar berikut ini memberikan ikhtisar tidak lengkap mengenai beberapa manfaat utama.
- Daftar semua Artefak dari tipe tertentu. Contoh: semua Model yang telah dilatih.
- Muat dua Artefak dengan tipe yang sama untuk perbandingan. Contoh: membandingkan hasil dari dua percobaan.
- Tampilkan DAG dari semua eksekusi terkait serta artefak masukan dan keluarannya dalam suatu konteks. Contoh: memvisualisasikan alur kerja eksperimen untuk proses debug dan penemuan.
- Ulangi kembali semua peristiwa untuk melihat bagaimana artefak dibuat. Contoh: melihat data apa yang dimasukkan ke dalam model; menerapkan rencana penyimpanan data.
- Identifikasi semua artefak yang dibuat menggunakan artefak tertentu. Contoh: lihat semua Model yang dilatih dari kumpulan data tertentu; tandai model berdasarkan data yang buruk.
- Tentukan apakah eksekusi telah dijalankan pada input yang sama sebelumnya. Contoh: menentukan apakah suatu komponen/langkah telah menyelesaikan pekerjaan yang sama dan keluaran sebelumnya dapat digunakan kembali.
- Rekam dan kueri konteks alur kerja yang dijalankan. Contoh: melacak pemilik dan daftar perubahan yang digunakan untuk menjalankan alur kerja; mengelompokkan garis keturunan berdasarkan eksperimen; mengelola artefak berdasarkan proyek.
- Kemampuan memfilter node deklaratif pada properti dan node lingkungan 1-hop. Contoh: mencari artefak dari suatu jenis dan dalam konteks saluran tertentu; mengembalikan artefak yang diketik di mana nilai properti tertentu berada dalam rentang tertentu; temukan eksekusi sebelumnya dalam konteks dengan masukan yang sama.
Lihat tutorial MLMD untuk contoh yang menunjukkan cara menggunakan API MLMD dan penyimpanan metadata untuk mengambil informasi silsilah.
Integrasikan Metadata ML ke dalam Alur Kerja ML Anda
Jika Anda adalah pengembang platform yang tertarik untuk mengintegrasikan MLMD ke dalam sistem Anda, gunakan contoh alur kerja di bawah ini untuk menggunakan API MLMD tingkat rendah guna melacak pelaksanaan tugas pelatihan. Anda juga dapat menggunakan API Python tingkat tinggi di lingkungan notebook untuk mencatat metadata eksperimen.
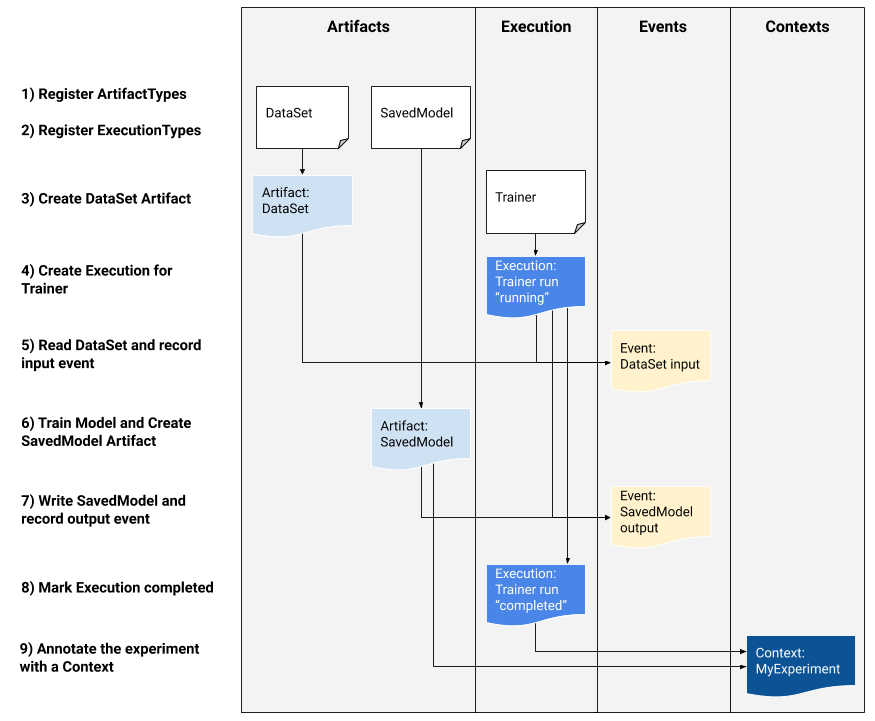
1) Daftarkan jenis artefak
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) Daftarkan jenis eksekusi untuk semua langkah dalam alur kerja ML
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) Buat artefak DataSet ArtifactType
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) Buat eksekusi eksekusi Trainer
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) Tentukan peristiwa input dan baca data
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) Deklarasikan artefak keluaran
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) Catat peristiwa keluaran
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) Tandai eksekusi telah selesai
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) Kelompokkan artefak dan eksekusi dalam konteks menggunakan artefak atribusi dan pernyataan
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
Gunakan MLMD dengan server gRPC jarak jauh
Anda dapat menggunakan MLMD dengan server gRPC jarak jauh seperti yang ditunjukkan di bawah ini:
- Mulai server
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
Secara default, server menggunakan db dalam memori palsu per permintaan dan tidak menyimpan metadata di seluruh panggilan. Itu juga dapat dikonfigurasi dengan MLMD MetadataStoreServerConfig untuk menggunakan file SQLite atau instance MySQL. Konfigurasi dapat disimpan dalam file protobuf teks dan diteruskan ke biner dengan --metadata_store_server_config_file=path_to_the_config_file .
Contoh file MetadataStoreServerConfig dalam format protobuf teks:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- Buat rintisan klien dan gunakan dengan Python
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- Gunakan MLMD dengan panggilan RPC
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
Sumber daya
Pustaka MLMD memiliki API tingkat tinggi yang dapat dengan mudah Anda gunakan dengan pipeline ML Anda. Lihat dokumentasi MLMD API untuk detail selengkapnya.
Lihat Pemfilteran Node Deklaratif MLMD untuk mempelajari cara menggunakan kemampuan pemfilteran node deklaratif MLMD pada properti dan node lingkungan 1 lompatan.
Lihat juga tutorial MLMD untuk mempelajari cara menggunakan MLMD untuk melacak garis keturunan komponen saluran Anda.
MLMD menyediakan utilitas untuk menangani migrasi skema dan data di seluruh rilis. Lihat Panduan MLMD untuk lebih jelasnya.