
عام
هل لا يزال نموذج EvalSavedModel مطلوبًا؟
في السابق، كانت TFMA تطلب تخزين جميع المقاييس ضمن رسم بياني لتدفق التوتر باستخدام EvalSavedModel خاص. الآن، يمكن حساب المقاييس خارج الرسم البياني TF باستخدام تطبيقات beam.CombineFn .
بعض الاختلافات الرئيسية هي:
- يتطلب
EvalSavedModelتصديرًا خاصًا من المدرب، بينما يمكن استخدام نموذج التقديم دون إجراء أي تغييرات مطلوبة على كود التدريب. - عند استخدام
EvalSavedModel، فإن أي مقاييس تتم إضافتها في وقت التدريب تكون متاحة تلقائيًا في وقت التقييم. بدونEvalSavedModelيجب إعادة إضافة هذه المقاييس.- الاستثناء لهذه القاعدة هو أنه في حالة استخدام نموذج keras، يمكن أيضًا إضافة المقاييس تلقائيًا لأن keras يحفظ معلومات المقياس بجانب النموذج المحفوظ.
هل يمكن لـ TFMA العمل مع كل من المقاييس الموجودة في الرسم البياني والمقاييس الخارجية؟
يسمح TFMA باستخدام نهج مختلط حيث يمكن حساب بعض المقاييس في الرسم البياني بينما يمكن حساب المقاييس الأخرى في الخارج. إذا كان لديك حاليًا EvalSavedModel ، فيمكنك الاستمرار في استخدامه.
هناك حالتان:
- استخدم TFMA
EvalSavedModelلكل من استخراج الميزات والحسابات المترية ولكن يمكنك أيضًا إضافة مقاييس إضافية قائمة على الموحد. في هذه الحالة، ستحصل على جميع المقاييس الموجودة في الرسم البياني منEvalSavedModelبالإضافة إلى أي مقاييس إضافية من الموحد الذي ربما لم يكن مدعومًا من قبل. - استخدم TFMA
EvalSavedModelلاستخراج الميزات/التنبؤ ولكن استخدم المقاييس المستندة إلى الموحد لجميع حسابات المقاييس. يعد هذا الوضع مفيدًا إذا كانت هناك تحويلات ميزات موجودة فيEvalSavedModelوالتي ترغب في استخدامها للتقطيع، ولكنك تفضل إجراء جميع الحسابات المترية خارج الرسم البياني.
يثبت
ما هي أنواع النماذج المدعومة؟
يدعم TFMA نماذج keras، والنماذج المستندة إلى واجهات برمجة التطبيقات العامة لتوقيع TF2، بالإضافة إلى النماذج المستندة إلى مقدر TF (على الرغم من أنه اعتمادًا على حالة الاستخدام، قد تتطلب النماذج المستندة إلى المقدر استخدام EvalSavedModel ).
راجع دليل get_started للحصول على القائمة الكاملة لأنواع النماذج المدعومة وأي قيود.
كيف أقوم بإعداد TFMA للعمل مع نموذج أصلي يعتمد على keras؟
فيما يلي مثال لتكوين نموذج keras بناءً على الافتراضات التالية:
- النموذج المحفوظ مخصص للعرض ويستخدم اسم التوقيع
serving_default(يمكن تغيير هذا باستخدامmodel_specs[0].signature_name). - يجب تقييم المقاييس المضمنة من
model.compile(...)(يمكن تعطيل ذلك عبرoptions.include_default_metricداخل tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
راجع المقاييس للحصول على مزيد من المعلومات حول أنواع المقاييس الأخرى التي يمكن تكوينها.
كيف أقوم بإعداد TFMA للعمل مع نموذج عام يعتمد على توقيعات TF2؟
فيما يلي مثال لتكوين نموذج TF2 عام. أدناه، signature_name هو اسم التوقيع المحدد الذي يجب استخدامه للتقييم.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
راجع المقاييس للحصول على مزيد من المعلومات حول أنواع المقاييس الأخرى التي يمكن تكوينها.
كيف أقوم بإعداد TFMA للعمل مع نموذج قائم على المقدر؟
في هذه الحالة هناك ثلاثة خيارات.
الخيار 1: استخدام نموذج العرض
إذا تم استخدام هذا الخيار، فلن يتم تضمين أي مقاييس تمت إضافتها أثناء التدريب في التقييم.
فيما يلي مثال على التكوين بافتراض أن serving_default هو اسم التوقيع المستخدم:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
راجع المقاييس للحصول على مزيد من المعلومات حول أنواع المقاييس الأخرى التي يمكن تكوينها.
الخيار 2: استخدم EvalSavedModel مع المقاييس الإضافية المستندة إلى المُجمِّع
في هذه الحالة، استخدم EvalSavedModel لاستخراج وتقييم الميزات/التنبؤات وأيضًا إضافة مقاييس إضافية تعتمد على المُجمِّع.
فيما يلي مثال على التكوين:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
راجع المقاييس لمزيد من المعلومات حول أنواع المقاييس الأخرى التي يمكن تكوينها و EvalSavedModel لمزيد من المعلومات حول إعداد EvalSavedModel.
الخيار 3: استخدم نموذج EvalSavedModel فقط لاستخراج الميزات/التنبؤ
يشبه الخيار (2)، ولكن استخدم EvalSavedModel فقط لاستخراج الميزة/التنبؤ. يعد هذا الخيار مفيدًا في حالة الرغبة في المقاييس الخارجية فقط، ولكن هناك تحويلات للميزات ترغب في تقسيمها. كما هو الحال مع الخيار (1)، لن يتم تضمين أي مقاييس تتم إضافتها أثناء التدريب في التقييم.
في هذه الحالة، يكون التكوين هو نفسه كما هو مذكور أعلاه، ويتم تعطيل include_default_metrics فقط.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
راجع المقاييس لمزيد من المعلومات حول أنواع المقاييس الأخرى التي يمكن تكوينها و EvalSavedModel لمزيد من المعلومات حول إعداد EvalSavedModel.
كيف أقوم بإعداد TFMA للعمل مع نموذج قائم على نموذج إلى مقدر keras؟
يشبه إعداد keras model_to_estimator تكوين المقدر. ومع ذلك، هناك بعض الاختلافات الخاصة بكيفية عمل النموذج للمقدر. على وجه الخصوص، يقوم نموذج إلى مُحاكي بإرجاع مخرجاته في شكل إملاء حيث يكون مفتاح الإملاء هو اسم طبقة الإخراج الأخيرة في نموذج keras المرتبط (إذا لم يتم توفير اسم، فسوف تختار keras اسمًا افتراضيًا لك مثل dense_1 أو output_1 ). من منظور TFMA، يشبه هذا السلوك ما يمكن أن يكون مخرجات لنموذج متعدد المخرجات على الرغم من أن النموذج الذي يتم تقديره قد يكون لنموذج واحد فقط. لمراعاة هذا الاختلاف، يلزم اتخاذ خطوة إضافية لإعداد اسم الإخراج. ومع ذلك، تنطبق نفس الخيارات الثلاثة كمقدر.
فيما يلي مثال على التغييرات المطلوبة للتكوين القائم على المقدر:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
كيف أقوم بإعداد TFMA للعمل مع التنبؤات المحسوبة مسبقًا (أي غير المعتمدة على النموذج)؟ ( TFRecord و tf.Example )
من أجل تكوين TFMA للعمل مع التنبؤات المحسوبة مسبقًا، يجب تعطيل tfma.PredictExtractor الافتراضي ويجب تكوين tfma.InputExtractor لتحليل التنبؤات مع ميزات الإدخال الأخرى. يتم تحقيق ذلك عن طريق تكوين tfma.ModelSpec باسم مفتاح الميزة المستخدم للتنبؤات جنبًا إلى جنب مع التسميات والأوزان.
فيما يلي مثال على الإعداد:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
راجع المقاييس للحصول على مزيد من المعلومات حول المقاييس التي يمكن تكوينها.
لاحظ أنه على الرغم من تكوين tfma.ModelSpec ، إلا أنه لا يتم استخدام النموذج فعليًا (أي لا يوجد tfma.EvalSharedModel ). قد تبدو الدعوة لتشغيل تحليل النموذج كما يلي:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
كيف أقوم بإعداد TFMA للعمل مع التنبؤات المحسوبة مسبقًا (أي غير المعتمدة على النموذج)؟ ( pd.DataFrame )
بالنسبة لمجموعات البيانات الصغيرة التي يمكن احتواؤها في الذاكرة، فإن البديل لـ TFRecord هو pandas.DataFrame s. يمكن أن يعمل TFMA على pandas.DataFrame s باستخدام tfma.analyze_raw_data API. للحصول على شرح حول tfma.MetricsSpec و tfma.SlicingSpec ، راجع دليل الإعداد . راجع المقاييس للحصول على مزيد من المعلومات حول المقاييس التي يمكن تكوينها.
فيما يلي مثال على الإعداد:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
المقاييس
ما أنواع المقاييس المدعومة؟
يدعم TFMA مجموعة واسعة من المقاييس بما في ذلك:
- مقاييس الانحدار
- مقاييس التصنيف الثنائية
- مقاييس التصنيف متعددة الفئات/متعددة التصنيفات
- المتوسط الجزئي / المتوسط الكلي المقاييس
- الاستعلام/المقاييس القائمة على الترتيب
هل يتم دعم المقاييس من النماذج متعددة المخرجات؟
نعم. راجع دليل المقاييس لمزيد من التفاصيل.
هل يتم دعم المقاييس من نماذج متعددة؟
نعم. راجع دليل المقاييس لمزيد من التفاصيل.
هل يمكن تخصيص إعدادات المقياس (الاسم، وما إلى ذلك)؟
نعم. يمكن تخصيص إعدادات المقاييس (على سبيل المثال، تحديد حدود محددة، وما إلى ذلك) عن طريق إضافة إعدادات config إلى تكوين المقياس. انظر دليل المقاييس يحتوي على مزيد من التفاصيل.
هل المقاييس المخصصة مدعومة؟
نعم. إما عن طريق كتابة تطبيق tf.keras.metrics.Metric مخصص أو عن طريق كتابة تطبيق beam.CombineFn مخصص. يحتوي دليل المقاييس على مزيد من التفاصيل.
ما أنواع المقاييس غير المدعومة؟
طالما يمكن حساب المقياس الخاص بك باستخدامشعاع beam.CombineFn ، فلا توجد قيود على أنواع المقاييس التي يمكن حسابها بناءً على tfma.metrics.Metric . إذا كنت تستخدم مقياسًا مشتقًا من tf.keras.metrics.Metric ، فيجب استيفاء المعايير التالية:
- يجب أن يكون من الممكن حساب إحصائيات كافية للمقياس في كل مثال بشكل مستقل، ثم دمج هذه الإحصائيات الكافية عن طريق إضافتها عبر جميع الأمثلة، وتحديد قيمة المقياس من هذه الإحصائيات الكافية فقط.
- على سبيل المثال، من أجل الدقة، تكون الإحصائيات الكافية "صحيحة تمامًا" و"أمثلة إجمالية". من الممكن حساب هذين الرقمين للأمثلة الفردية، وإضافتهما لمجموعة من الأمثلة للحصول على القيم الصحيحة لتلك الأمثلة. يمكن حساب الدقة النهائية باستخدام "إجمالي الأمثلة الصحيحة/الإجمالية".
الإضافات
هل يمكنني استخدام TFMA لتقييم العدالة أو التحيز في النموذج الخاص بي؟
يتضمن TFMA وظيفة إضافية لمؤشرات العدالة توفر مقاييس ما بعد التصدير لتقييم تأثيرات التحيز غير المقصود في نماذج التصنيف.
التخصيص
ماذا لو كنت بحاجة إلى مزيد من التخصيص؟
يتميز TFMA بالمرونة الشديدة ويسمح لك بتخصيص جميع أجزاء خط الأنابيب تقريبًا باستخدام Extractors و/أو Evaluators و/أو Writers المخصصين. تمت مناقشة هذه التجريدات بمزيد من التفصيل في وثيقة الهندسة المعمارية .
استكشاف الأخطاء وإصلاحها وتصحيح الأخطاء والحصول على المساعدة
لماذا لا تتطابق مقاييس MultiClassConfusionMatrix مع مقاييس ConfusionMatrix الثنائية
هذه في الواقع حسابات مختلفة. تقوم عملية Binarization بإجراء مقارنة لكل معرف فئة بشكل مستقل (أي تتم مقارنة التنبؤ لكل فئة بشكل منفصل مع الحدود المقدمة). في هذه الحالة، من الممكن أن تشير فئتان أو أكثر إلى أنها تطابقت مع التنبؤ لأن قيمتها المتوقعة كانت أكبر من العتبة (سيكون هذا أكثر وضوحًا عند العتبات الأدنى). في حالة مصفوفة الارتباك متعددة الفئات، لا يزال هناك قيمة واحدة متوقعة حقيقية فقط وهي إما تطابق القيمة الفعلية أو لا تطابقها. يتم استخدام العتبة فقط لإجبار التنبؤ على عدم مطابقة أي فئة إذا كانت أقل من العتبة. كلما ارتفعت العتبة، زادت صعوبة مطابقة تنبؤات الفصل الثنائي. وبالمثل، كلما انخفضت العتبة، أصبح من الأسهل مطابقة تنبؤات الفصل الثنائي. يعني أنه عند العتبات > 0.5، ستكون القيم الثنائية وقيم المصفوفة متعددة الفئات أكثر محاذاة، وعند العتبات < 0.5 ستكون متباعدة.
على سبيل المثال، لنفترض أن لدينا 10 فئات حيث تم التنبؤ بالفئة 2 باحتمال 0.8، لكن الفئة الفعلية كانت الفئة 1 والتي كان احتمالها 0.15. إذا قمت بإجراء عملية ثنائية على الفئة 1 واستخدمت عتبة 0.1، فسيتم اعتبار الفئة 1 صحيحة (0.15 > 0.1) لذلك سيتم احتسابها على أنها TP، ومع ذلك، بالنسبة للحالة متعددة الفئات، سيتم اعتبار الفئة 2 صحيحة (0.8 > 0.1) وبما أن الفئة 1 كانت الفعلية، فسيتم احتسابها على أنها FN. لأنه عند العتبات الأدنى سيتم اعتبار المزيد من القيم إيجابية، بشكل عام سيكون هناك عدد TP وFP أعلى لمصفوفة الارتباك الثنائية مقارنة بمصفوفة الارتباك متعددة الفئات، وبالمثل أقل TN وFN.
ما يلي هو مثال على الاختلافات الملحوظة بين MultiClassConfusionMatrixAtThresholds والأعداد المقابلة من الثنائية لإحدى الفئات.
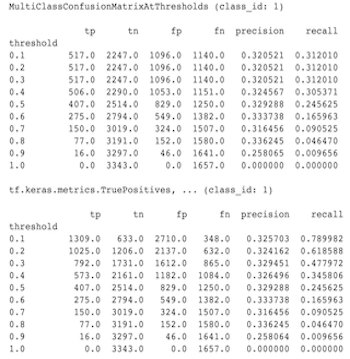
لماذا يكون لمقاييس الدقة@1 والاستدعاء@1 نفس القيمة؟
عند القيمة العليا k البالغة 1، فإن الدقة والاستدعاء هما نفس الشيء. الدقة تساوي TP / (TP + FP) والاستدعاء يساوي TP / (TP + FN) . يكون التنبؤ الأعلى دائمًا إيجابيًا وسيتطابق مع التسمية أو لا يتطابق معها. بمعنى آخر، مع أمثلة N ، TP + FP = N . ومع ذلك، إذا كانت التسمية لا تتطابق مع التنبؤ العلوي، فهذا يعني أيضًا أن التنبؤ غير العلوي k قد تمت مطابقته ومع تعيين أعلى k على 1، ستكون جميع التنبؤات غير العليا 1 0. وهذا يعني أن FN يجب أن يكون (N - TP) أو N = TP + FN . والنتيجة النهائية هي precision@1 = TP / N = recall@1 . لاحظ أن هذا ينطبق فقط عندما يكون هناك تصنيف واحد لكل مثال، وليس للتسميات المتعددة.
لماذا تكون مقاييس mean_label وmean_prediction دائمًا 0.5؟
يحدث هذا على الأرجح بسبب تكوين المقاييس لمشكلة تصنيف ثنائي، لكن النموذج يقوم بإخراج الاحتمالات لكلا الفئتين بدلاً من فئة واحدة فقط. يعد هذا أمرًا شائعًا عند استخدام واجهة برمجة تطبيقات التصنيف الخاصة بـ Tensorflow . الحل هو اختيار الفئة التي ترغب في أن تعتمد عليها التوقعات ثم إجراء عملية ثنائية على تلك الفئة. على سبيل المثال:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
كيفية تفسير MultiLabelConfusionMatrixPlot؟
بالنظر إلى تسمية معينة، يمكن استخدام MultiLabelConfusionMatrixPlot (وما يرتبط بها من MultiLabelConfusionMatrix ) لمقارنة نتائج التسميات الأخرى وتوقعاتها عندما تكون التسمية المختارة صحيحة بالفعل. على سبيل المثال، لنفترض أن لدينا ثلاث فئات: bird ، plane ، superman ، ونقوم بتصنيف الصور للإشارة إلى ما إذا كانت تحتوي على واحدة أو أكثر من أي من هذه الفئات. سوف يقوم MultiLabelConfusionMatrix بحساب المنتج الديكارتي لكل فئة فعلية مقابل كل فئة أخرى (تسمى الفئة المتوقعة). لاحظ أنه على الرغم من أن الاقتران (actual, predicted) ، فإن الفئة predicted لا تعني بالضرورة توقعًا إيجابيًا، فهي تمثل فقط العمود المتوقع في المصفوفة الفعلية مقابل المصفوفة المتوقعة. على سبيل المثال، لنفترض أننا قمنا بحساب المصفوفات التالية:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
لدى MultiLabelConfusionMatrixPlot ثلاث طرق لعرض هذه البيانات. وفي جميع الحالات، تكون طريقة قراءة الجدول صفًا تلو الآخر من منظور الفصل الفعلي.
1) إجمالي عدد التنبؤ
في هذه الحالة، بالنسبة لصف معين (أي فئة فعلية)، ما هي أعداد TP + FP للفئات الأخرى. بالنسبة للأعداد المذكورة أعلاه، سيكون عرضنا كما يلي:
| طائر متوقع | الطائرة المتوقعة | توقع سوبرمان | |
|---|---|---|---|
| طائر حقيقي | 6 | 4 | 2 |
| الطائرة الفعلية | 4 | 4 | 4 |
| سوبرمان حقيقي | 5 | 5 | 4 |
عندما كانت الصور تحتوي بالفعل على bird ، توقعنا بشكل صحيح 6 منها. وفي الوقت نفسه، توقعنا أيضًا plane (سواء بشكل صحيح أو خطأ) 4 مرات superman (سواء بشكل صحيح أو خطأ) مرتين.
2) عدد التنبؤ غير صحيح
في هذه الحالة، بالنسبة لصف معين (أي فئة فعلية)، ما هي أعداد FP للفئات الأخرى. بالنسبة للأعداد المذكورة أعلاه، سيكون عرضنا كما يلي:
| طائر متوقع | الطائرة المتوقعة | توقع سوبرمان | |
|---|---|---|---|
| طائر حقيقي | 0 | 2 | 1 |
| الطائرة الفعلية | 1 | 0 | 3 |
| سوبرمان حقيقي | 2 | 3 | 0 |
عندما كانت الصور تحتوي بالفعل على bird فقد توقعنا بشكل غير صحيح plane مرتين superman مرة واحدة.
3) العد السلبي الكاذب
في هذه الحالة، بالنسبة لصف معين (أي فئة فعلية)، ما هو عدد FN للفئات الأخرى. بالنسبة للأعداد المذكورة أعلاه، سيكون عرضنا كما يلي:
| طائر متوقع | الطائرة المتوقعة | توقع سوبرمان | |
|---|---|---|---|
| طائر حقيقي | 2 | 2 | 4 |
| الطائرة الفعلية | 1 | 4 | 3 |
| سوبرمان حقيقي | 2 | 2 | 5 |
عندما كانت الصور تحتوي بالفعل على bird ، فشلنا في التنبؤ به مرتين. وفي الوقت نفسه، فشلنا في التنبؤ plane مرتين superman 4 مرات.
لماذا أحصل على خطأ بشأن عدم العثور على مفتاح التنبؤ؟
تقوم بعض النماذج بإخراج تنبؤاتها في شكل قاموس. على سبيل المثال، يقوم مقدر TF لمشكلة التصنيف الثنائي بإخراج قاموس يحتوي على probabilities و class_ids وما إلى ذلك. في معظم الحالات، يكون لدى TFMA إعدادات افتراضية للعثور على أسماء المفاتيح شائعة الاستخدام مثل predictions probabilities وما إلى ذلك. ومع ذلك، إذا كان النموذج الخاص بك مخصصًا للغاية، فقد يكون من الممكن مفاتيح الإخراج تحت أسماء غير معروفة بواسطة TFMA. في هذه الحالات، يجب إضافة إعداد prediciton_key إلى tfma.ModelSpec لتحديد اسم المفتاح الذي يتم تخزين الإخراج تحته.