
सामान्य
क्या EvalSavenModel अभी भी आवश्यक है?
पहले टीएफएमए को सभी मेट्रिक्स को एक विशेष EvalSavedModel का उपयोग करके टेंसरफ़्लो ग्राफ़ के भीतर संग्रहीत करने की आवश्यकता होती थी। अब, beam.CombineFn कार्यान्वयन का उपयोग करके टीएफ ग्राफ़ के बाहर मैट्रिक्स की गणना की जा सकती है।
कुछ मुख्य अंतर हैं:
-
EvalSavedModelट्रेनर से एक विशेष निर्यात की आवश्यकता होती है जबकि एक सर्विंग मॉडल का उपयोग प्रशिक्षण कोड में आवश्यक किसी भी बदलाव के बिना किया जा सकता है। - जब
EvalSavedModelउपयोग किया जाता है, तो प्रशिक्षण के समय जोड़े गए कोई भी मेट्रिक्स मूल्यांकन के समय स्वचालित रूप से उपलब्ध होते हैं।EvalSavedModelके बिना इन मेट्रिक्स को फिर से जोड़ा जाना चाहिए।- इस नियम का अपवाद यह है कि यदि केरस मॉडल का उपयोग किया जाता है तो मेट्रिक्स को स्वचालित रूप से भी जोड़ा जा सकता है क्योंकि केरस सहेजे गए मॉडल के साथ-साथ मीट्रिक जानकारी भी सहेजता है।
क्या टीएफएमए इन-ग्राफ़ मेट्रिक्स और बाहरी मेट्रिक्स दोनों के साथ काम कर सकता है?
टीएफएमए एक हाइब्रिड दृष्टिकोण का उपयोग करने की अनुमति देता है जहां कुछ मेट्रिक्स की गणना ग्राफ़ में की जा सकती है जबकि अन्य की गणना बाहर की जा सकती है। यदि आपके पास वर्तमान में EvalSavedModel है तो आप इसका उपयोग जारी रख सकते हैं।
दो मामले हैं:
- फीचर निष्कर्षण और मीट्रिक गणना दोनों के लिए टीएफएमए
EvalSavedModelका उपयोग करें, लेकिन अतिरिक्त कॉम्बिनर-आधारित मीट्रिक भी जोड़ें। इस मामले में आपकोEvalSavedModelसे सभी इन-ग्राफ़ मेट्रिक्स के साथ-साथ कंबाइनर-आधारित से कोई भी अतिरिक्त मेट्रिक्स मिलेगा जो पहले समर्थित नहीं हो सकता है। - फीचर/भविष्यवाणी निष्कर्षण के लिए टीएफएमए
EvalSavedModelका उपयोग करें लेकिन सभी मेट्रिक्स गणनाओं के लिए कंबाइनर-आधारित मेट्रिक्स का उपयोग करें। यह मोड उपयोगी है यदिEvalSavedModelमें फीचर ट्रांसफॉर्मेशन मौजूद हैं जिन्हें आप स्लाइसिंग के लिए उपयोग करना चाहते हैं, लेकिन ग्राफ़ के बाहर सभी मीट्रिक गणना करना पसंद करते हैं।
स्थापित करना
कौन से मॉडल प्रकार समर्थित हैं?
टीएफएमए केरस मॉडल, जेनेरिक टीएफ2 सिग्नेचर एपीआई पर आधारित मॉडल, साथ ही टीएफ अनुमानक आधारित मॉडल का समर्थन करता है (हालांकि उपयोग के मामले के आधार पर अनुमानक आधारित मॉडल को उपयोग करने के लिए एक EvalSavedModel आवश्यकता हो सकती है)।
समर्थित मॉडल प्रकारों और किसी भी प्रतिबंध की पूरी सूची के लिए get_started मार्गदर्शिका देखें।
मैं देशी केरस आधारित मॉडल के साथ काम करने के लिए टीएफएमए कैसे स्थापित करूं?
निम्नलिखित मान्यताओं के आधार पर केरस मॉडल के लिए एक उदाहरण कॉन्फ़िगरेशन है:
- सहेजा गया मॉडल सर्विंग के लिए है और हस्ताक्षर नाम
serving_defaultका उपयोग करता है (इसेmodel_specs[0].signature_nameउपयोग करके बदला जा सकता है)। -
model.compile(...)से निर्मित मेट्रिक्स का मूल्यांकन किया जाना चाहिए (इसे tfma.EvalConfig के भीतरoptions.include_default_metricके माध्यम से अक्षम किया जा सकता है)।
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
कॉन्फ़िगर किए जा सकने वाले अन्य प्रकार के मेट्रिक्स के बारे में अधिक जानकारी के लिए मेट्रिक्स देखें।
मैं सामान्य TF2 हस्ताक्षर आधारित मॉडल के साथ काम करने के लिए TFMA को कैसे सेटअप करूं?
निम्नलिखित एक सामान्य TF2 मॉडल के लिए एक उदाहरण कॉन्फ़िगरेशन है। नीचे, signature_name उस विशिष्ट हस्ताक्षर का नाम है जिसका उपयोग मूल्यांकन के लिए किया जाना चाहिए।
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
कॉन्फ़िगर किए जा सकने वाले अन्य प्रकार के मेट्रिक्स के बारे में अधिक जानकारी के लिए मेट्रिक्स देखें।
मैं अनुमानक आधारित मॉडल के साथ काम करने के लिए टीएफएमए कैसे स्थापित करूं?
इस मामले में तीन विकल्प हैं.
विकल्प1: सर्विंग मॉडल का उपयोग करें
यदि इस विकल्प का उपयोग किया जाता है तो प्रशिक्षण के दौरान जोड़े गए किसी भी मेट्रिक्स को मूल्यांकन में शामिल नहीं किया जाएगा।
निम्नलिखित एक उदाहरण कॉन्फ़िगरेशन है जिसमें मान लिया गया है कि serving_default उपयोग किया गया हस्ताक्षर नाम है:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
कॉन्फ़िगर किए जा सकने वाले अन्य प्रकार के मेट्रिक्स के बारे में अधिक जानकारी के लिए मेट्रिक्स देखें।
विकल्प 2: अतिरिक्त कंबाइनर-आधारित मेट्रिक्स के साथ EvalSavenModel का उपयोग करें
इस मामले में, फीचर/भविष्यवाणी निष्कर्षण और मूल्यांकन दोनों के लिए EvalSavedModel का उपयोग करें और अतिरिक्त कॉम्बिनर आधारित मेट्रिक्स भी जोड़ें।
निम्नलिखित एक उदाहरण कॉन्फ़िगरेशन है:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
अन्य प्रकार के मेट्रिक्स के बारे में अधिक जानकारी के लिए मेट्रिक्स देखें जिन्हें कॉन्फ़िगर किया जा सकता है और EvalSavenModel को सेट करने के बारे में अधिक जानकारी के लिए EvalSaredModel देखें।
विकल्प3: केवल फ़ीचर/भविष्यवाणी निष्कर्षण के लिए EvalSavenModel मॉडल का उपयोग करें
विकल्प(2) के समान, लेकिन सुविधा/भविष्यवाणी निष्कर्षण के लिए केवल EvalSavedModel का उपयोग करें। यह विकल्प उपयोगी है यदि केवल बाहरी मेट्रिक्स वांछित हैं, लेकिन ऐसे फीचर परिवर्तन भी हैं जिन्हें आप स्लाइस करना चाहेंगे। विकल्प (1) के समान प्रशिक्षण के दौरान जोड़े गए किसी भी मेट्रिक्स को मूल्यांकन में शामिल नहीं किया जाएगा।
इस मामले में कॉन्फिगरेशन ऊपर जैसा ही है, केवल include_default_metrics अक्षम है।
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
अन्य प्रकार के मेट्रिक्स के बारे में अधिक जानकारी के लिए मेट्रिक्स देखें जिन्हें कॉन्फ़िगर किया जा सकता है और EvalSavenModel को सेट करने के बारे में अधिक जानकारी के लिए EvalSaredModel देखें।
मैं केरस मॉडल-टू-एस्टीमेटर आधारित मॉडल के साथ काम करने के लिए टीएफएमए कैसे सेटअप करूं?
केरस model_to_estimator सेटअप अनुमानक कॉन्फ़िगरेशन के समान है। हालाँकि मॉडल से अनुमानक कैसे काम करता है इसके बारे में कुछ विशिष्ट अंतर हैं। विशेष रूप से, मॉडल-टू-एसिमटेटर अपने आउटपुट को एक डिक्ट के रूप में लौटाता है जहां डिक्ट कुंजी संबंधित केरस मॉडल में अंतिम आउटपुट परत का नाम है (यदि कोई नाम प्रदान नहीं किया गया है, तो केरस आपके लिए एक डिफ़ॉल्ट नाम चुनेगा) जैसे कि dense_1 या output_1 )। टीएफएमए परिप्रेक्ष्य से, यह व्यवहार मल्टी-आउटपुट मॉडल के लिए आउटपुट के समान है, भले ही अनुमानक का मॉडल केवल एक मॉडल के लिए हो। इस अंतर को ध्यान में रखने के लिए, आउटपुट नाम सेट करने के लिए एक अतिरिक्त चरण की आवश्यकता है। हालाँकि, वही तीन विकल्प अनुमानक के रूप में लागू होते हैं।
अनुमानक आधारित कॉन्फ़िगरेशन के लिए आवश्यक परिवर्तनों का एक उदाहरण निम्नलिखित है:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
मैं पूर्व-गणना (यानी मॉडल-अज्ञेयवादी) भविष्यवाणियों के साथ काम करने के लिए टीएफएमए कैसे स्थापित करूं? ( TFRecord और tf.Example )
पूर्व-गणना की गई भविष्यवाणियों के साथ काम करने के लिए टीएफएमए को कॉन्फ़िगर करने के लिए, डिफ़ॉल्ट tfma.PredictExtractor अक्षम किया जाना चाहिए और अन्य इनपुट सुविधाओं के साथ भविष्यवाणियों को पार्स करने के लिए tfma.InputExtractor कॉन्फ़िगर किया जाना चाहिए। यह लेबल और वज़न के साथ-साथ भविष्यवाणियों के लिए उपयोग की जाने वाली फ़ीचर कुंजी के नाम के साथ tfma.ModelSpec कॉन्फ़िगर करके पूरा किया जाता है।
निम्नलिखित एक उदाहरण सेटअप है:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
कॉन्फ़िगर किए जा सकने वाले मेट्रिक्स के बारे में अधिक जानकारी के लिए मेट्रिक्स देखें।
ध्यान दें कि यद्यपि tfma.ModelSpec कॉन्फ़िगर किया जा रहा है, लेकिन वास्तव में एक मॉडल का उपयोग नहीं किया जा रहा है (यानी कोई tfma.EvalSharedModel नहीं है)। मॉडल विश्लेषण चलाने के लिए कॉल इस प्रकार दिख सकती है:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
मैं पूर्व-गणना (यानी मॉडल-अज्ञेयवादी) भविष्यवाणियों के साथ काम करने के लिए टीएफएमए कैसे स्थापित करूं? ( pd.DataFrame )
छोटे डेटासेट के लिए जो मेमोरी में फिट हो सकते हैं, TFRecord का एक विकल्प एक pandas.DataFrame s है। TFMA tfma.analyze_raw_data API का उपयोग करके pandas.DataFrame s पर काम कर सकता है। tfma.MetricsSpec और tfma.SlicingSpec की व्याख्या के लिए, सेटअप गाइड देखें। कॉन्फ़िगर किए जा सकने वाले मेट्रिक्स के बारे में अधिक जानकारी के लिए मेट्रिक्स देखें।
निम्नलिखित एक उदाहरण सेटअप है:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
मेट्रिक्स
किस प्रकार के मेट्रिक्स समर्थित हैं?
टीएफएमए विभिन्न प्रकार के मेट्रिक्स का समर्थन करता है जिनमें शामिल हैं:
- प्रतिगमन मेट्रिक्स
- बाइनरी वर्गीकरण मेट्रिक्स
- मल्टी-क्लास/मल्टी-लेबल वर्गीकरण मेट्रिक्स
- सूक्ष्म औसत/मैक्रो औसत मेट्रिक्स
- क्वेरी/रैंकिंग आधारित मेट्रिक्स
क्या मल्टी-आउटपुट मॉडल के मेट्रिक्स समर्थित हैं?
हाँ। अधिक विवरण के लिए मेट्रिक्स गाइड देखें.
क्या एकाधिक-मॉडल के मेट्रिक्स समर्थित हैं?
हाँ। अधिक विवरण के लिए मेट्रिक्स गाइड देखें.
क्या मीट्रिक सेटिंग्स (नाम, आदि) को अनुकूलित किया जा सकता है?
हाँ। मेट्रिक कॉन्फ़िगरेशन में config सेटिंग्स जोड़कर मेट्रिक्स सेटिंग्स को अनुकूलित किया जा सकता है (उदाहरण के लिए विशिष्ट थ्रेशोल्ड सेट करना, आदि)। देखें मेट्रिक्स गाइड में अधिक विवरण हैं।
क्या कस्टम मेट्रिक्स समर्थित हैं?
हाँ। या तो एक कस्टम tf.keras.metrics.Metric कार्यान्वयन लिखकर या एक कस्टम beam.CombineFn कार्यान्वयन लिखकर। मेट्रिक्स गाइड में अधिक विवरण हैं.
किस प्रकार के मेट्रिक्स समर्थित नहीं हैं?
जब तक आपके मीट्रिक की गणना beam.CombineFn का उपयोग करके की जा सकती है, तब तक मीट्रिक के प्रकारों पर कोई प्रतिबंध नहीं है जिनकी गणना tfma.metrics.Metric के आधार पर की जा सकती है। यदि tf.keras.metrics.Metric से प्राप्त मीट्रिक के साथ काम कर रहे हैं तो निम्नलिखित मानदंडों को पूरा किया जाना चाहिए:
- प्रत्येक उदाहरण पर मीट्रिक के लिए स्वतंत्र रूप से पर्याप्त आँकड़ों की गणना करना संभव होना चाहिए, फिर इन पर्याप्त आँकड़ों को सभी उदाहरणों में जोड़कर संयोजित करें, और इन पर्याप्त आँकड़ों से केवल मीट्रिक मान निर्धारित करें।
- उदाहरण के लिए, सटीकता के लिए पर्याप्त आँकड़े "कुल सही" और "कुल उदाहरण" हैं। व्यक्तिगत उदाहरणों के लिए इन दो संख्याओं की गणना करना और उन उदाहरणों के लिए सही मान प्राप्त करने के लिए उन्हें उदाहरणों के समूह में जोड़ना संभव है। अंतिम सटीकता की गणना "कुल सही / कुल उदाहरण" का उपयोग करके की जा सकती है।
ऐड-ऑन
क्या मैं अपने मॉडल में निष्पक्षता या पूर्वाग्रह का मूल्यांकन करने के लिए टीएफएमए का उपयोग कर सकता हूं?
टीएफएमए में एक फेयरनेसइंडिकेटर्स ऐड-ऑन शामिल है जो वर्गीकरण मॉडल में अनपेक्षित पूर्वाग्रह के प्रभावों के मूल्यांकन के लिए निर्यात-पश्चात मेट्रिक्स प्रदान करता है।
अनुकूलन
यदि मुझे और अधिक अनुकूलन की आवश्यकता हो तो क्या होगा?
टीएफएमए बहुत लचीला है और आपको कस्टम Extractors , Evaluators और/या Writers का उपयोग करके पाइपलाइन के लगभग सभी हिस्सों को अनुकूलित करने की अनुमति देता है। आर्किटेक्चर दस्तावेज़ में इन अमूर्तताओं पर अधिक विस्तार से चर्चा की गई है।
समस्या निवारण, डिबगिंग और सहायता प्राप्त करना
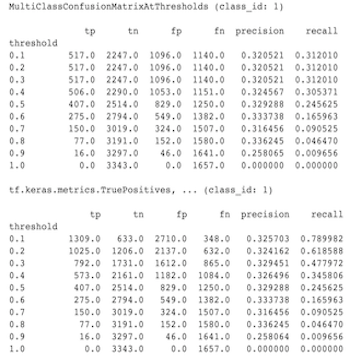
मल्टीक्लास कन्फ्यूजनमैट्रिक्स मेट्रिक्स बाइनराइज्ड कन्फ्यूजनमैट्रिक्स मेट्रिक्स से मेल क्यों नहीं खाते
ये वास्तव में अलग-अलग गणनाएँ हैं। बाइनराइज़ेशन प्रत्येक वर्ग आईडी के लिए स्वतंत्र रूप से तुलना करता है (यानी प्रत्येक वर्ग के लिए पूर्वानुमान की तुलना प्रदान की गई सीमा के विरुद्ध अलग से की जाती है)। इस मामले में दो या दो से अधिक वर्गों के लिए यह संभव है कि वे सभी भविष्यवाणी से मेल खाते हों क्योंकि उनका अनुमानित मूल्य सीमा से अधिक था (यह कम सीमा पर और भी अधिक स्पष्ट होगा)। मल्टीक्लास कन्फ्यूजन मैट्रिक्स के मामले में, अभी भी केवल एक ही सही अनुमानित मूल्य है और यह या तो वास्तविक मूल्य से मेल खाता है या नहीं। दहलीज का उपयोग केवल भविष्यवाणी को बिना किसी वर्ग से मेल खाने के लिए मजबूर करने के लिए किया जाता है यदि यह सीमा से कम है। सीमा जितनी अधिक होगी, द्विआधारी वर्ग की भविष्यवाणी का मिलान करना उतना ही कठिन होगा। इसी तरह, सीमा जितनी कम होगी, द्विआधारी वर्ग की भविष्यवाणियों का मिलान करना उतना ही आसान होगा। इसका मतलब है कि थ्रेसहोल्ड > 0.5 पर बाइनराइज्ड मान और मल्टीक्लास मैट्रिक्स मान करीब संरेखित होंगे और थ्रेशोल्ड <0.5 पर वे अधिक दूर होंगे।
उदाहरण के लिए, मान लें कि हमारे पास 10 कक्षाएं हैं जहां कक्षा 2 की भविष्यवाणी 0.8 की संभावना के साथ की गई थी, लेकिन वास्तविक कक्षा कक्षा 1 थी जिसकी संभावना 0.15 थी। यदि आप कक्षा 1 पर बाइनराइज़ करते हैं और 0.1 की सीमा का उपयोग करते हैं, तो कक्षा 1 को सही माना जाएगा (0.15 > 0.1) इसलिए इसे टीपी के रूप में गिना जाएगा, हालांकि, मल्टीक्लास मामले के लिए, कक्षा 2 को सही माना जाएगा (0.8 > 0.1) और चूँकि कक्षा 1 वास्तविक थी, इसे एफएन के रूप में गिना जाएगा। क्योंकि कम सीमा पर अधिक मूल्यों को सकारात्मक माना जाएगा, सामान्य तौर पर मल्टीक्लास कन्फ्यूजन मैट्रिक्स की तुलना में बाइनराइज्ड कन्फ्यूजन मैट्रिक्स के लिए उच्च टीपी और एफपी गणना होगी, और इसी तरह कम टीएन और एफएन होंगे।
निम्नलिखित मल्टीक्लासकॉन्फ्यूजनमैट्रिक्सएटथ्रेशोल्ड्स और किसी एक वर्ग के बाइनराइजेशन से संबंधित गणनाओं के बीच देखे गए अंतर का एक उदाहरण है।
मेरी परिशुद्धता@1 और रिकॉल@1 मेट्रिक्स का मान समान क्यों है?
1 के शीर्ष k मान पर परिशुद्धता और रिकॉल एक ही चीज़ हैं। परिशुद्धता TP / (TP + FP) के बराबर है और रिकॉल TP / (TP + FN) के बराबर है। शीर्ष भविष्यवाणी हमेशा सकारात्मक होती है और या तो लेबल से मेल खाएगी या मेल नहीं खाएगी। दूसरे शब्दों में, N उदाहरणों के साथ, TP + FP = N । हालाँकि, यदि लेबल शीर्ष भविष्यवाणी से मेल नहीं खाता है, तो इसका मतलब यह भी है कि एक गैर-शीर्ष k भविष्यवाणी का मिलान किया गया था और शीर्ष k को 1 पर सेट करने के साथ, सभी गैर-शीर्ष 1 भविष्यवाणियाँ 0 होंगी। इसका मतलब है कि FN (N - TP) होना चाहिए (N - TP) या N = TP + FN । अंतिम परिणाम precision@1 = TP / N = recall@1 है। ध्यान दें कि यह केवल तभी लागू होता है जब प्रति उदाहरण एक ही लेबल हो, मल्टी-लेबल के लिए नहीं।
मेरे माध्य_लेबल और माध्य_भविष्यवाणी मेट्रिक्स हमेशा 0.5 क्यों होते हैं?
ऐसा संभवतः इसलिए होता है क्योंकि मेट्रिक्स को बाइनरी वर्गीकरण समस्या के लिए कॉन्फ़िगर किया गया है, लेकिन मॉडल केवल एक के बजाय दोनों वर्गों के लिए संभावनाओं को आउटपुट कर रहा है। यह सामान्य है जब टेंसरफ्लो के वर्गीकरण एपीआई का उपयोग किया जाता है। इसका समाधान यह है कि आप उस वर्ग को चुनें जिसके आधार पर आप भविष्यवाणियाँ करना चाहते हैं और फिर उस वर्ग पर बाइनराइज़ करें। उदाहरण के लिए:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
मल्टीलेबल कन्फ्यूजनमैट्रिक्सप्लॉट की व्याख्या कैसे करें?
किसी विशेष लेबल को देखते हुए, MultiLabelConfusionMatrixPlot (और संबंधित MultiLabelConfusionMatrix ) का उपयोग अन्य लेबलों के परिणामों और उनकी भविष्यवाणियों की तुलना करने के लिए किया जा सकता है जब चुना गया लेबल वास्तव में सत्य था। उदाहरण के लिए, मान लें कि हमारे पास तीन वर्ग हैं bird , plane और superman और हम यह इंगित करने के लिए चित्रों को वर्गीकृत कर रहे हैं कि क्या उनमें इनमें से किसी एक या अधिक वर्गों का समावेश है। MultiLabelConfusionMatrix प्रत्येक वास्तविक वर्ग के कार्टेशियन उत्पाद को एक दूसरे वर्ग (जिसे पूर्वानुमानित वर्ग कहा जाता है) के विरुद्ध गणना करेगा। ध्यान दें कि जबकि युग्मन (actual, predicted) है, predicted वर्ग आवश्यक रूप से सकारात्मक भविष्यवाणी नहीं करता है, यह केवल वास्तविक बनाम अनुमानित मैट्रिक्स में अनुमानित कॉलम का प्रतिनिधित्व करता है। उदाहरण के लिए, मान लें कि हमने निम्नलिखित आव्यूहों की गणना की है:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot में इस डेटा को प्रदर्शित करने के तीन तरीके हैं। सभी मामलों में तालिका को पढ़ने का तरीका वास्तविक वर्ग के परिप्रेक्ष्य से पंक्ति दर पंक्ति होता है।
1) कुल पूर्वानुमान गणना
इस मामले में, किसी दी गई पंक्ति (यानी वास्तविक वर्ग) के लिए अन्य वर्गों के लिए TP + FP गणना क्या थी। उपरोक्त गणनाओं के लिए, हमारा प्रदर्शन इस प्रकार होगा:
| पूर्वानुमानित पक्षी | पूर्वानुमानित विमान | सुपरमैन की भविष्यवाणी की | |
|---|---|---|---|
| वास्तविक पक्षी | 6 | 4 | 2 |
| वास्तविक विमान | 4 | 4 | 4 |
| वास्तविक सुपरमैन | 5 | 5 | 4 |
जब चित्रों में वास्तव में एक bird था तो हमने उनमें से 6 की सही भविष्यवाणी की। साथ ही हमने plane भी 4 बार (या तो सही या गलत) और superman (या तो सही या गलत) 2 बार भविष्यवाणी की।
2) गलत भविष्यवाणी गणना
इस मामले में, किसी दी गई पंक्ति (यानी वास्तविक वर्ग) के लिए अन्य वर्गों के लिए FP गणना क्या थी। उपरोक्त गणनाओं के लिए, हमारा प्रदर्शन इस प्रकार होगा:
| पूर्वानुमानित पक्षी | पूर्वानुमानित विमान | सुपरमैन की भविष्यवाणी की | |
|---|---|---|---|
| वास्तविक पक्षी | 0 | 2 | 1 |
| वास्तविक विमान | 1 | 0 | 3 |
| वास्तविक सुपरमैन | 2 | 3 | 0 |
जब तस्वीरों में वास्तव में एक bird था तो हमने 2 बार plane और 1 बार superman गलत भविष्यवाणी की।
3) गलत नकारात्मक गणना
इस मामले में, किसी दी गई पंक्ति (यानी वास्तविक वर्ग) के लिए अन्य वर्गों के लिए FN गणना क्या थी। उपरोक्त गणनाओं के लिए, हमारा प्रदर्शन इस प्रकार होगा:
| पूर्वानुमानित पक्षी | पूर्वानुमानित विमान | सुपरमैन की भविष्यवाणी की | |
|---|---|---|---|
| वास्तविक पक्षी | 2 | 2 | 4 |
| वास्तविक विमान | 1 | 4 | 3 |
| वास्तविक सुपरमैन | 2 | 2 | 5 |
जब तस्वीरों में वास्तव में एक bird था तो हम दो बार इसकी भविष्यवाणी करने में विफल रहे। वहीं, हम 2 बार plane और 4 बार superman भविष्यवाणी करने में असफल रहे।
मुझे पूर्वानुमान कुंजी नहीं मिली के बारे में त्रुटि क्यों मिलती है?
कुछ मॉडल अपनी भविष्यवाणी को शब्दकोश के रूप में आउटपुट करते हैं। उदाहरण के लिए, बाइनरी वर्गीकरण समस्या के लिए एक TF अनुमानक एक शब्दकोश को आउटपुट करता है जिसमें probabilities , class_ids आदि शामिल होते हैं। ज्यादातर मामलों में TFMA में predictions , probabilities आदि जैसे सामान्य रूप से उपयोग किए जाने वाले कुंजी नामों को खोजने के लिए डिफ़ॉल्ट होते हैं। हालांकि, यदि आपका मॉडल बहुत अनुकूलित है तो यह हो सकता है TFMA द्वारा अज्ञात नामों के अंतर्गत आउटपुट कुंजियाँ। इन मामलों में आउटपुट को संग्रहीत कुंजी के नाम की पहचान करने के लिए tfma.ModelSpec में एक prediciton_key सेटिंग जोड़ी जानी चाहिए।