
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel crée un exemple contradictoire à l'aide de l'attaque Fast Gradient Signed Method (FGSM), comme décrit dans Expliquer et exploiter les exemples contradictoires de Goodfellow et al . Ce fut l'une des premières et des plus populaires attaques visant à tromper un réseau de neurones.
Qu'est-ce qu'un exemple contradictoire ?
Les exemples contradictoires sont des entrées spécialisées créées dans le but de confondre un réseau de neurones, entraînant la mauvaise classification d'une entrée donnée. Ces entrées notoires sont indiscernables à l'œil humain, mais empêchent le réseau d'identifier le contenu de l'image. Il existe plusieurs types d'attaques de ce type, cependant, l'accent est mis ici sur l'attaque par la méthode du signe de gradient rapide, qui est une attaque par boîte blanche dont le but est d'assurer une mauvaise classification. Une attaque en boîte blanche est l'endroit où l'attaquant a un accès complet à la figurine attaquée. L'un des exemples les plus célèbres d'une image contradictoire présentée ci-dessous est tiré de l'article susmentionné.

Ici, en commençant par l'image d'un panda, l'attaquant ajoute de petites perturbations (distorsions) à l'image d'origine, ce qui conduit le modèle à étiqueter cette image comme un gibbon, avec une grande confiance. Le processus d'ajout de ces perturbations est expliqué ci-dessous.
Méthode de signe de gradient rapide
La méthode du signe de gradient rapide fonctionne en utilisant les gradients du réseau de neurones pour créer un exemple contradictoire. Pour une image d'entrée, le procédé utilise les gradients de la perte par rapport à l'image d'entrée pour créer une nouvelle image qui maximise la perte. Cette nouvelle image est appelée image contradictoire. Cela peut se résumer à l'aide de l'expression suivante :
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
où
- adv_x : Image contradictoire.
- x : image d'entrée d'origine.
- y : Etiquette d'entrée d'origine.
- \(\epsilon\) : Multiplicateur pour s'assurer que les perturbations sont faibles.
- \(\theta\) : paramètres du modèle.
- \(J\) : Perte.
Une propriété intrigante ici est le fait que les gradients sont pris par rapport à l'image d'entrée. Ceci est fait parce que l'objectif est de créer une image qui maximise la perte. Une méthode pour y parvenir consiste à déterminer dans quelle mesure chaque pixel de l'image contribue à la valeur de perte et à ajouter une perturbation en conséquence. Cela fonctionne assez rapidement car il est facile de trouver comment chaque pixel d'entrée contribue à la perte en utilisant la règle de la chaîne et en trouvant les gradients requis. Par conséquent, les gradients sont pris par rapport à l'image. De plus, puisque le modèle n'est plus entraîné (ainsi le gradient n'est pas pris par rapport aux variables entraînables, c'est-à-dire les paramètres du modèle), les paramètres du modèle restent donc constants. Le seul but est de tromper un modèle déjà formé.
Alors essayons de tromper un modèle pré-entraîné. Dans ce tutoriel, le modèle est le modèle MobileNetV2 , pré-entraîné sur ImageNet .
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
Chargeons le modèle MobileNetV2 pré-entraîné et les noms de classe ImageNet.
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
Image originale
Utilisons un exemple d'image d'un Labrador Retriever par Mirko CC-BY-SA 3.0 de Wikimedia Common et créons-en des exemples contradictoires. La première étape consiste à le prétraiter afin qu'il puisse être alimenté en entrée du modèle MobileNetV2.
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
Regardons l'image.
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

Créer l'image de l'adversaire
Mise en œuvre de la méthode de signe de gradient rapide
La première étape consiste à créer des perturbations qui seront utilisées pour déformer l'image originale résultant en une image contradictoire. Comme mentionné, pour cette tâche, les gradients sont pris par rapport à l'image.
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
Les perturbations qui en résultent peuvent également être visualisées.
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
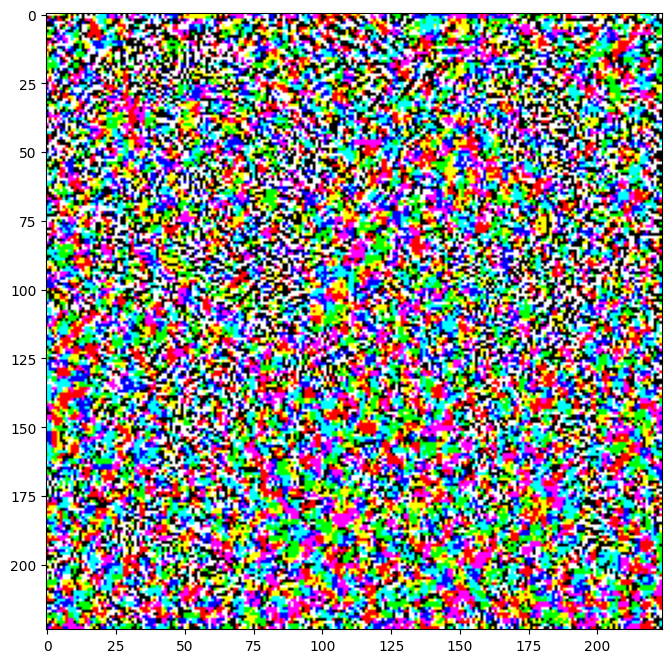
Essayons ceci pour différentes valeurs d'epsilon et observons l'image résultante. Vous remarquerez qu'à mesure que la valeur d'epsilon augmente, il devient plus facile de tromper le réseau. Cependant, cela vient comme un compromis qui fait que les perturbations deviennent plus identifiables.
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



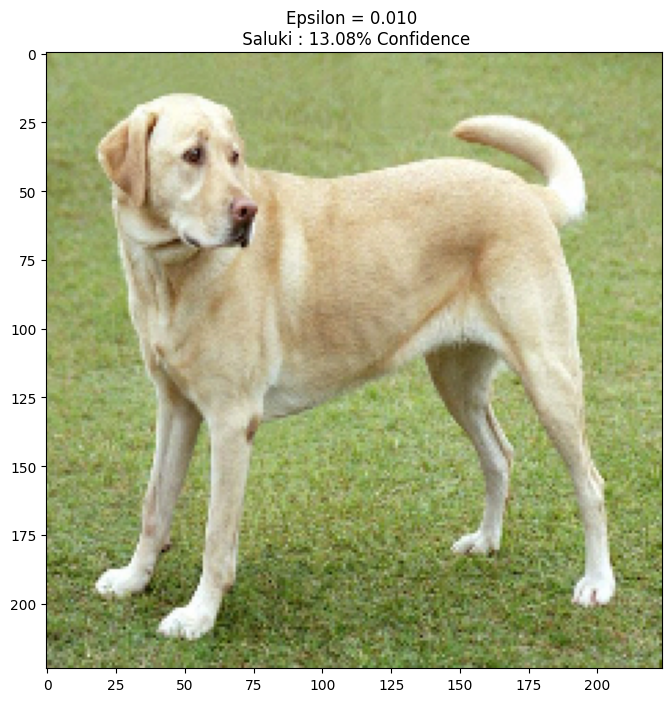
Prochaines étapes
Maintenant que vous connaissez les attaques contradictoires, essayez ceci sur différents ensembles de données et différentes architectures. Vous pouvez également créer et entraîner votre propre modèle, puis tenter de le tromper en utilisant la même méthode. Vous pouvez également essayer de voir comment la confiance dans les prédictions varie lorsque vous changez d'epsilon.
Bien que puissante, l'attaque présentée dans ce didacticiel n'était que le début de la recherche sur les attaques contradictoires, et de nombreux articles ont créé des attaques plus puissantes depuis lors. Outre les attaques contradictoires, la recherche a également conduit à la création de défenses, qui visent à créer des modèles d'apprentissage automatique robustes. Vous pouvez consulter ce document d'enquête pour une liste complète des attaques et des défenses adverses.
Pour de nombreuses autres implémentations d'attaques et de défenses contradictoires, vous pouvez consulter la bibliothèque d'exemples de confrontation CleverHans .