
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel montre comment générer des images de chiffres manuscrits à l'aide d'un réseau DCGAN ( Deep Convolutional Generative Adversarial Network ). Le code est écrit à l'aide de l' API séquentielle Keras avec une boucle d'entraînement tf.GradientTape .
Que sont les GAN ?
Les réseaux antagonistes génératifs (GAN) sont l'une des idées les plus intéressantes de l'informatique aujourd'hui. Deux modèles sont formés simultanément par un processus contradictoire. Un générateur ("l'artiste") apprend à créer des images qui semblent réelles, tandis qu'un discriminateur ("le critique d'art") apprend à distinguer les vraies images des fausses.
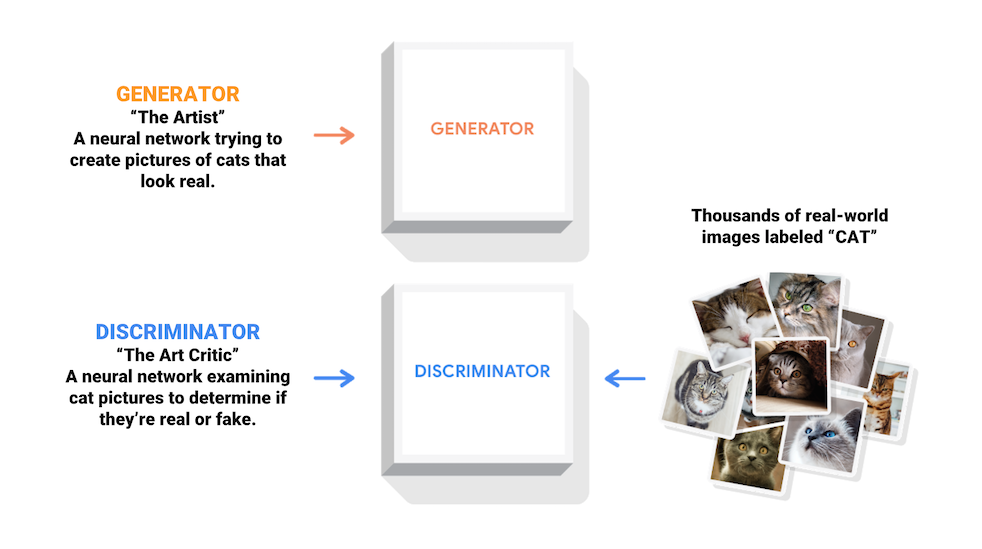
Au cours de l'entraînement, le générateur s'améliore progressivement pour créer des images qui semblent réelles, tandis que le discriminateur s'améliore pour les différencier. Le processus atteint l'équilibre lorsque le discriminateur ne peut plus distinguer les images réelles des fausses.
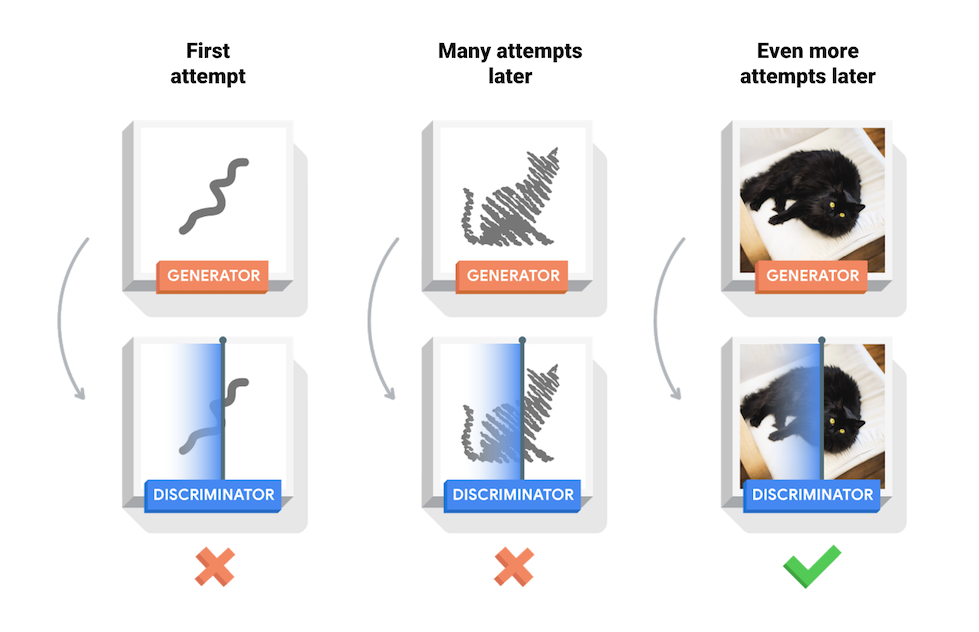
Ce bloc-notes illustre ce processus sur le jeu de données MNIST. L'animation suivante montre une série d'images produites par le générateur lors de son apprentissage sur 50 époques. Les images commencent par un bruit aléatoire et ressemblent de plus en plus à des chiffres écrits à la main au fil du temps.

Pour en savoir plus sur les GAN, consultez le cours Intro to Deep Learning du MIT.
Installer
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
Charger et préparer le jeu de données
Vous utiliserez le jeu de données MNIST pour former le générateur et le discriminateur. Le générateur générera des chiffres manuscrits ressemblant aux données MNIST.
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
Créer les modèles
Le générateur et le discriminateur sont définis à l'aide de l' API séquentielle Keras .
Le générateur
Le générateur utilise tf.keras.layers.Conv2DTranspose (suréchantillonnage) pour produire une image à partir d'une graine (bruit aléatoire). Commencez avec un calque Dense qui prend cette graine en entrée, puis suréchantillonnez plusieurs fois jusqu'à ce que vous atteigniez la taille d'image souhaitée de 28x28x1. Notez l'activation de tf.keras.layers.LeakyReLU pour chaque couche, à l'exception de la couche de sortie qui utilise tanh.
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
Utilisez le générateur (pas encore formé) pour créer une image.
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

Le discriminateur
Le discriminateur est un classificateur d'images basé sur CNN.
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
Utilisez le discriminateur (pas encore formé) pour classer les images générées comme réelles ou fausses. Le modèle sera formé pour générer des valeurs positives pour les images réelles et des valeurs négatives pour les images factices.
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
Définir la perte et les optimiseurs
Définissez les fonctions de perte et les optimiseurs pour les deux modèles.
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
Perte de discriminateur
Cette méthode quantifie la capacité du discriminateur à distinguer les vraies images des fausses. Il compare les prédictions du discriminateur sur des images réelles à un tableau de 1, et les prédictions du discriminateur sur de fausses images (générées) à un tableau de 0.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
Perte du générateur
La perte du générateur quantifie à quel point il a réussi à tromper le discriminateur. Intuitivement, si le générateur fonctionne bien, le discriminateur classera les fausses images comme vraies (ou 1). Ici, comparez les décisions des discriminateurs sur les images générées à un tableau de 1.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
Le discriminateur et les optimiseurs de générateur sont différents puisque vous entraînerez deux réseaux séparément.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
Enregistrer les points de contrôle
Ce bloc-notes montre également comment enregistrer et restaurer des modèles, ce qui peut être utile en cas d'interruption d'une longue tâche d'entraînement.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Définir la boucle d'entraînement
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
La boucle d'apprentissage commence avec le générateur recevant une graine aléatoire en entrée. Cette graine est utilisée pour produire une image. Le discriminateur est ensuite utilisé pour classer les images réelles (tirées de l'ensemble d'apprentissage) et les fausses images (produites par le générateur). La perte est calculée pour chacun de ces modèles, et les gradients sont utilisés pour mettre à jour le générateur et le discriminateur.
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
Générer et enregistrer des images
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Former le modèle
Appelez la méthode train() définie ci-dessus pour entraîner simultanément le générateur et le discriminateur. Notez que la formation des GAN peut être délicate. Il est important que le générateur et le discriminateur ne se surpassent pas (par exemple, qu'ils s'entraînent à un rythme similaire).
Au début de la formation, les images générées ressemblent à du bruit aléatoire. Au fur et à mesure que la formation progresse, les chiffres générés sembleront de plus en plus réels. Après environ 50 époques, ils ressemblent aux chiffres MNIST. Cela peut prendre environ une minute/époque avec les paramètres par défaut de Colab.
train(train_dataset, EPOCHS)

Restaurez le dernier point de contrôle.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
Créer un GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

Utilisez imageio pour créer un gif animé à partir des images enregistrées lors de la formation.
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Prochaines étapes
Ce tutoriel a montré le code complet nécessaire pour écrire et former un GAN. À l'étape suivante, vous souhaiterez peut-être expérimenter un ensemble de données différent, par exemple l'ensemble de données Large-scale Celeb Faces Attributes (CelebA) disponible sur Kaggle . Pour en savoir plus sur les GAN, consultez le didacticiel NIPS 2016 : Réseaux antagonistes génératifs .