
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel montre comment créer et former un réseau antagoniste génératif conditionnel (cGAN) appelé pix2pix qui apprend un mappage des images d'entrée aux images de sortie, comme décrit dans Image-to-image translation with conditional adversarial networks par Isola et al. (2017). pix2pix n'est pas spécifique à une application - il peut être appliqué à un large éventail de tâches, y compris la synthèse de photos à partir de cartes d'étiquettes, la génération de photos colorisées à partir d'images en noir et blanc, la transformation de photos Google Maps en images aériennes et même la transformation de croquis en photos.
Dans cet exemple, votre réseau générera des images de façades de bâtiments à l'aide de la base de données de façades CMP fournie par le Center for Machine Perception de l' Université technique tchèque de Prague . Pour faire court, vous utiliserez une copie prétraitée de cet ensemble de données créé par les auteurs de pix2pix.
Dans le pix2pix cGAN, vous conditionnez les images d'entrée et générez les images de sortie correspondantes. Les cGAN ont été proposés pour la première fois dans Conditional Generative Adversarial Nets (Mirza et Osindero, 2014)
L'architecture de votre réseau contiendra :
- Un générateur avec une architecture basée sur U-Net .
- Un discriminateur représenté par un classificateur convolutif PatchGAN (proposé dans l' article pix2pix ).
Notez que chaque époque peut prendre environ 15 secondes sur un seul GPU V100.
Vous trouverez ci-dessous quelques exemples de la sortie générée par le pix2pix cGAN après un entraînement de 200 époques sur le jeu de données des façades (étapes de 80 k).


Importer TensorFlow et d'autres bibliothèques
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
Charger le jeu de données
Téléchargez les données de la base de données CMP Facade (30 Mo). Des ensembles de données supplémentaires sont disponibles dans le même format ici . Dans Colab, vous pouvez sélectionner d'autres ensembles de données dans le menu déroulant. Notez que certains des autres ensembles de données sont beaucoup plus volumineux ( edges2handbags est de 8 Go).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
Chaque image originale est de taille 256 x 512 contenant deux images 256 x 256 :
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
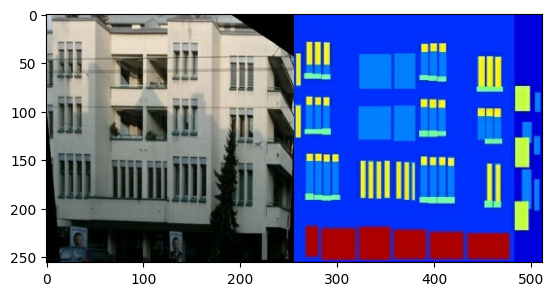
Vous devez séparer les images de façade de bâtiment réelles des images d'étiquette d'architecture, qui seront toutes de taille 256 x 256 .
Définissez une fonction qui charge les fichiers image et génère deux tenseurs d'image :
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
Tracez un échantillon des images d'entrée (image de l'étiquette de l'architecture) et réelles (photo de la façade du bâtiment) :
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
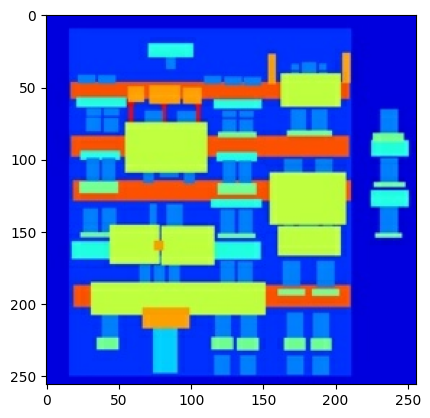
Comme décrit dans l' article pix2pix , vous devez appliquer une gigue et une mise en miroir aléatoires pour prétraiter l'ensemble d'apprentissage.
Définissez plusieurs fonctions qui :
- Redimensionnez chaque image
256 x 256à une hauteur et une largeur plus grandes—286 x 286. - Recadrez-le au hasard à
256 x 256. - Retournez aléatoirement l'image horizontalement, c'est-à-dire de gauche à droite (miroir aléatoire).
- Normalisez les images dans la plage
[-1, 1].
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
Vous pouvez inspecter certaines des sorties prétraitées :
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
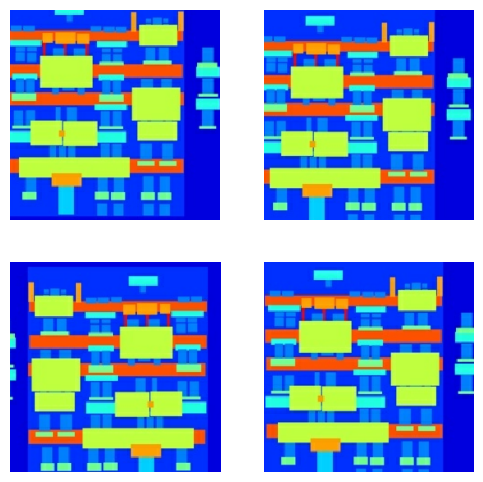
Après avoir vérifié que le chargement et le prétraitement fonctionnent, définissons quelques fonctions d'assistance qui chargent et prétraitent les ensembles d'apprentissage et de test :
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
Construire un pipeline d'entrée avec tf.data
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
Construire le générateur
Le générateur de votre pix2pix cGAN est un U-Net modifié . Un U-Net se compose d'un encodeur (downsampler) et d'un décodeur (upsampler). (Vous pouvez en savoir plus à ce sujet dans le didacticiel sur la segmentation d'images et sur le site Web du projet U-Net .)
- Chaque bloc dans l'encodeur est : Convolution -> Normalisation par lots -> Leaky ReLU
- Chaque bloc dans le décodeur est : Convolution transposée -> Normalisation par lots -> Dropout (appliqué aux 3 premiers blocs) -> ReLU
- Il y a des sauts de connexion entre l'encodeur et le décodeur (comme dans le U-Net).
Définissez le sous-échantillonneur (encodeur) :
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
Définissez le suréchantillonneur (décodeur) :
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
Définissez le générateur avec le sous-échantillonneur et le suréchantillonneur :
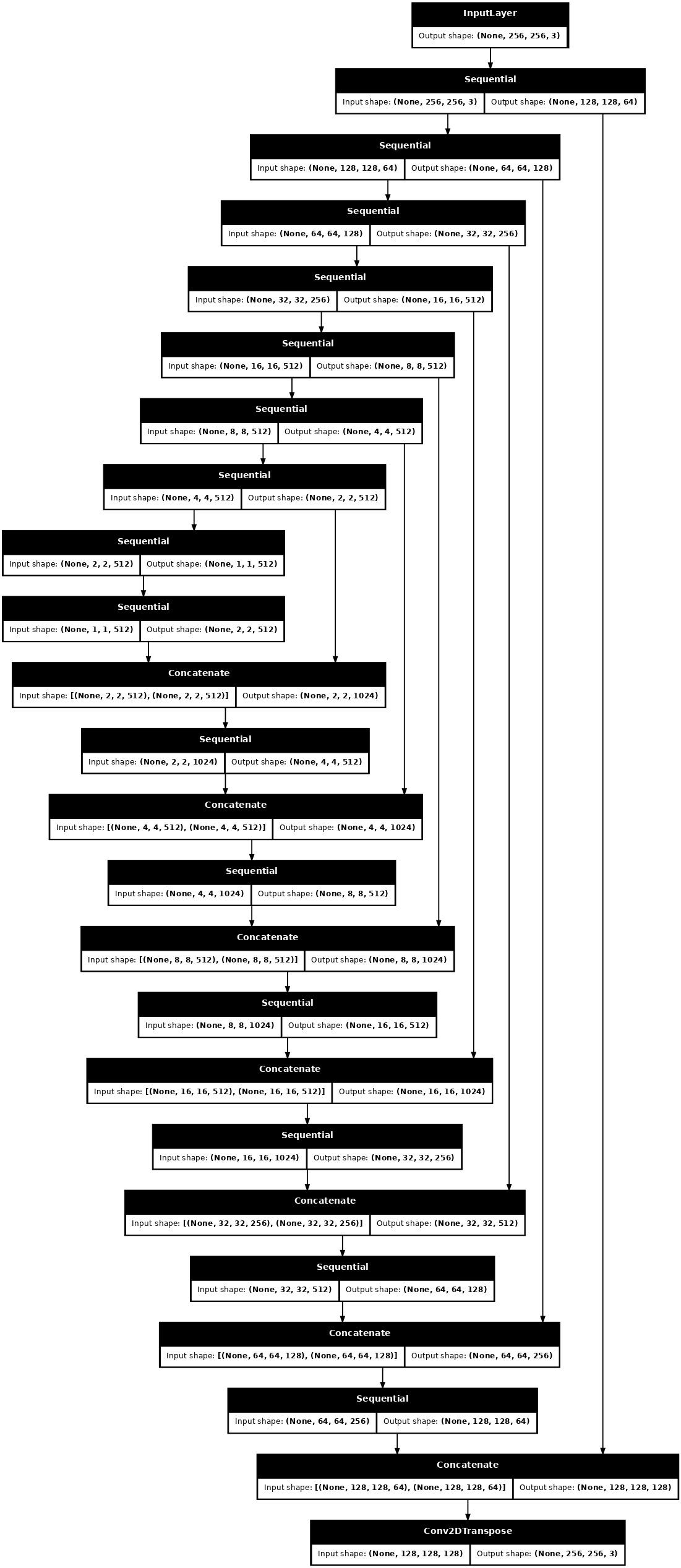
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Visualisez l'architecture du modèle de générateur :
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
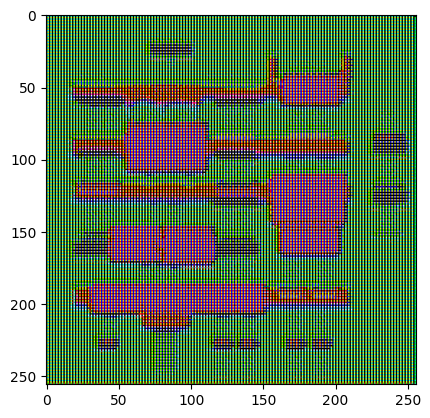
Testez le générateur :
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
Définir la perte du générateur
Les GAN apprennent une perte qui s'adapte aux données, tandis que les cGAN apprennent une perte structurée qui pénalise une éventuelle structure qui diffère de la sortie du réseau et de l'image cible, comme décrit dans l' article pix2pix .
- La perte du générateur est une perte d'entropie croisée sigmoïde des images générées et un tableau d' images.
- L'article pix2pix mentionne également la perte L1, qui est une MAE (erreur absolue moyenne) entre l'image générée et l'image cible.
- Cela permet à l'image générée de devenir structurellement similaire à l'image cible.
- La formule pour calculer la perte totale du générateur est
gan_loss + LAMBDA * l1_loss, oùLAMBDA = 100. Cette valeur a été décidée par les auteurs de l'article.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
La procédure de formation pour le générateur est la suivante :

Construire le discriminateur
Le discriminateur dans le pix2pix cGAN est un classificateur convolutif PatchGAN - il essaie de classer si chaque patch d'image est réel ou non, comme décrit dans l' article pix2pix .
- Chaque bloc du discriminateur est : Convolution -> Normalisation par lots -> Leaky ReLU.
- La forme de la sortie après la dernière couche est
(batch_size, 30, 30, 1). - Chaque patch d'image
30 x 30de la sortie classe une partie70 x 70de l'image d'entrée. - Le discriminateur reçoit 2 entrées :
- L'image d'entrée et l'image cible, qu'elle doit classer comme réelles.
- L'image d'entrée et l'image générée (la sortie du générateur), qu'il doit classer comme fausse.
- Utilisez
tf.concat([inp, tar], axis=-1)pour concaténer ces 2 entrées ensemble.
Définissons le discriminateur :
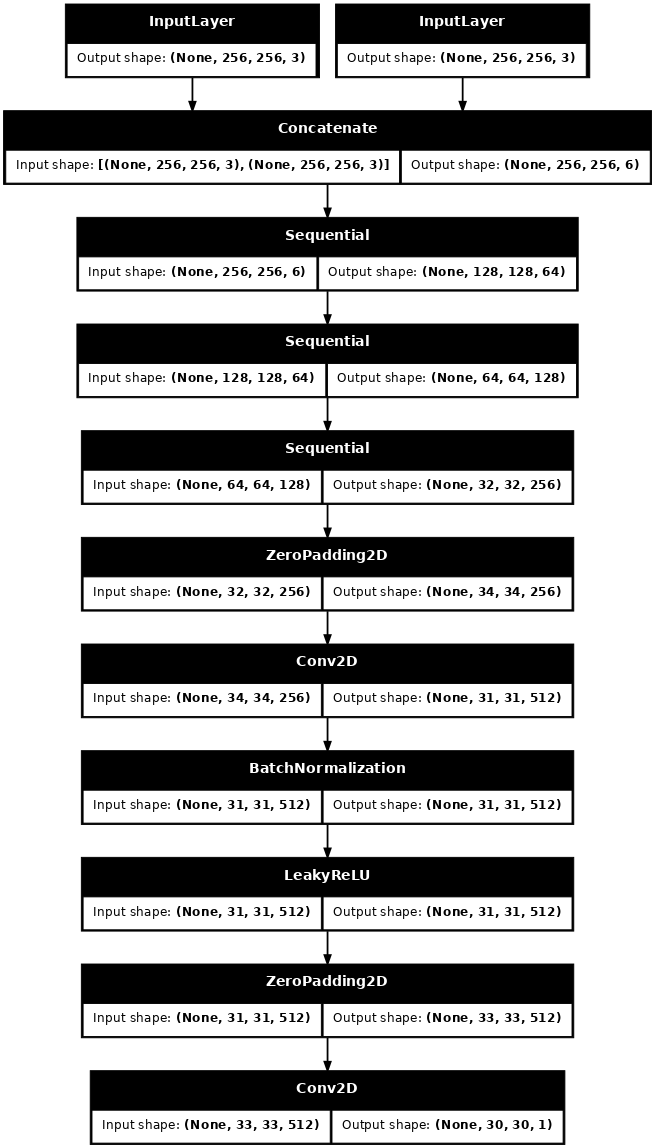
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
Visualisez l'architecture du modèle de discriminateur :
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
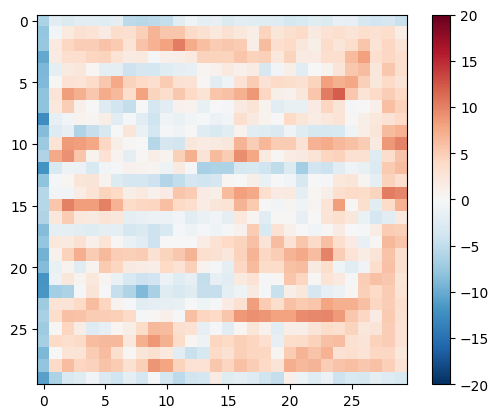
Testez le discriminateur :
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>
Définir la perte du discriminateur
- La fonction
discriminator_lossprend 2 entrées : images réelles et images générées . -
real_lossest une perte d'entropie croisée sigmoïde des images réelles et un tableau d'images (car ce sont les images réelles) . -
generated_lossest une perte d'entropie croisée sigmoïde des images générées et un tableau de zéros (puisqu'il s'agit de fausses images) . - La
total_lossest la somme dereal_lossetgenerated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
La procédure d'apprentissage du discriminateur est illustrée ci-dessous.
Pour en savoir plus sur l'architecture et les hyperparamètres vous pouvez vous référer à l' article pix2pix .

Définir les optimiseurs et un économiseur de points de contrôle
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Générer des images
Écrivez une fonction pour tracer des images pendant l'entraînement.
- Transmettez les images de l'ensemble de test au générateur.
- Le générateur traduira alors l'image d'entrée en sortie.
- La dernière étape consiste à tracer les prédictions et le tour est joué !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Testez la fonction :
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

Entraînement
- Pour chaque exemple, l'entrée génère une sortie.
- Le discriminateur reçoit l'
input_imageet l'image générée comme première entrée. La deuxième entrée estinput_imageettarget_image. - Ensuite, calculez le générateur et la perte du discriminateur.
- Ensuite, calculez les gradients de perte par rapport aux variables du générateur et du discriminateur (entrées) et appliquez-les à l'optimiseur.
- Enfin, enregistrez les pertes sur TensorBoard.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
La boucle d'entraînement proprement dite. Étant donné que ce didacticiel peut s'exécuter sur plusieurs ensembles de données et que la taille des ensembles de données varie considérablement, la boucle de formation est configurée pour fonctionner par étapes au lieu d'époques.
- Itère sur le nombre d'étapes.
- Toutes les 10 étapes, imprimez un point (
.). - Toutes les 1 000 étapes : effacez l'affichage et exécutez
generate_imagespour afficher la progression. - Toutes les 5 000 étapes : enregistrez un point de contrôle.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
Cette boucle d'entraînement enregistre des journaux que vous pouvez afficher dans TensorBoard pour suivre la progression de l'entraînement.
Si vous travaillez sur une machine locale, vous lancerez un processus TensorBoard distinct. Lorsque vous travaillez dans un notebook, lancez la visionneuse avant de commencer la formation pour surveiller avec TensorBoard.
Pour lancer la visionneuse, collez ce qui suit dans une cellule de code :
%load_ext tensorboard
%tensorboard --logdir {log_dir}
Enfin, exécutez la boucle d'entraînement :
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
Si vous souhaitez partager publiquement les résultats de TensorBoard , vous pouvez télécharger les journaux sur TensorBoard.dev en copiant ce qui suit dans une cellule de code.
tensorboard dev upload --logdir {log_dir}
Vous pouvez afficher les résultats d'une exécution précédente de ce notebook sur TensorBoard.dev .
TensorBoard.dev est une expérience gérée pour l'hébergement, le suivi et le partage d'expériences de ML avec tout le monde.
Il peut également être inclus en ligne à l'aide d'un <iframe> :
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
L'interprétation des journaux est plus subtile lors de la formation d'un GAN (ou d'un cGAN comme pix2pix) par rapport à un simple modèle de classification ou de régression. Choses à rechercher :
- Vérifier que ni le modèle générateur ni le modèle discriminateur n'ont "gagné". Si le
gen_gan_lossou ledisc_lossdevient très faible, c'est un indicateur que ce modèle domine l'autre, et vous n'entraînez pas avec succès le modèle combiné. - La valeur
log(2) = 0.69est un bon point de référence pour ces pertes, car elle indique une perplexité de 2 - le discriminateur est, en moyenne, également incertain sur les deux options. - Pour le
disc_loss, une valeur inférieure à0.69signifie que le discriminateur fait mieux que random sur l'ensemble combiné d'images réelles et générées. - Pour le
gen_gan_loss, une valeur inférieure à0.69signifie que le générateur fait mieux que random pour tromper le discriminateur. - Au fur et à mesure que l'entraînement progresse, le
gen_l1_lossdevrait diminuer.
Restaurer le dernier point de contrôle et tester le réseau
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
Générer des images à l'aide du jeu de test
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




