
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial demonstra o treinamento de uma Rede Neural Convolucional (CNN) simples para classificar imagens CIFAR . Como este tutorial usa a API Keras Sequential , criar e treinar seu modelo levará apenas algumas linhas de código.
Importar TensorFlow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
Baixe e prepare o conjunto de dados CIFAR10
O conjunto de dados CIFAR10 contém 60.000 imagens coloridas em 10 classes, com 6.000 imagens em cada classe. O conjunto de dados é dividido em 50.000 imagens de treinamento e 10.000 imagens de teste. As classes são mutuamente exclusivas e não há sobreposição entre elas.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
Verifique os dados
Para verificar se o conjunto de dados parece correto, vamos plotar as primeiras 25 imagens do conjunto de treinamento e exibir o nome da classe abaixo de cada imagem:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

Crie a base convolucional
As 6 linhas de código abaixo definem a base convolucional usando um padrão comum: uma pilha de camadas Conv2D e MaxPooling2D .
Como entrada, uma CNN recebe tensores de forma (image_height, image_width, color_channels), ignorando o tamanho do lote. Se você é novo nessas dimensões, color_channels se refere a (R,G,B). Neste exemplo, você configurará sua CNN para processar entradas de forma (32, 32, 3), que é o formato das imagens CIFAR. Você pode fazer isso passando o argumento input_shape para sua primeira camada.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
Vamos exibir a arquitetura do seu modelo até agora:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
Acima, você pode ver que a saída de cada camada Conv2D e MaxPooling2D é um tensor 3D de forma (altura, largura, canais). As dimensões de largura e altura tendem a diminuir à medida que você se aprofunda na rede. O número de canais de saída para cada camada Conv2D é controlado pelo primeiro argumento (por exemplo, 32 ou 64). Normalmente, à medida que a largura e a altura diminuem, você pode (computacionalmente) adicionar mais canais de saída em cada camada Conv2D.
Adicione camadas densas no topo
Para completar o modelo, você alimentará o último tensor de saída da base convolucional (de forma (4, 4, 64)) em uma ou mais camadas Dense para realizar a classificação. Camadas densas recebem vetores como entrada (que são 1D), enquanto a saída atual é um tensor 3D. Primeiro, você achatará (ou desenrolará) a saída 3D para 1D e, em seguida, adicionará uma ou mais camadas Densas no topo. O CIFAR tem 10 classes de saída, então você usa uma camada Dense final com 10 saídas.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
Aqui está a arquitetura completa do seu modelo:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
O resumo da rede mostra que (4, 4, 64) as saídas foram achatadas em vetores de forma (1024) antes de passar por duas camadas Densas.
Compilar e treinar o modelo
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
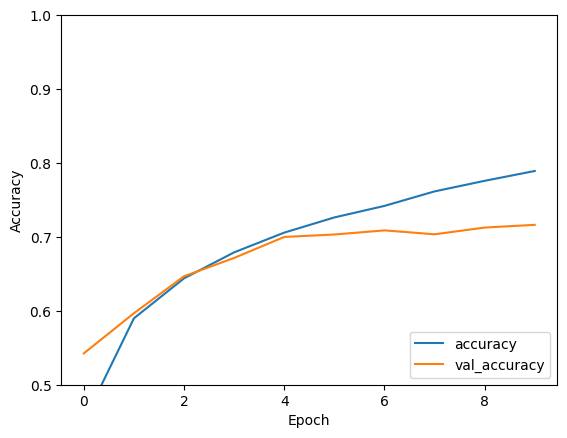
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
Avalie o modelo
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
print(test_acc)
0.7192000150680542
Sua CNN simples alcançou uma precisão de teste de mais de 70%. Nada mal para algumas linhas de código! Para outro estilo CNN, confira o exemplo de início rápido do TensorFlow 2 para especialistas que usa a API de subclassificação Keras e tf.GradientTape .