
| |
 GitHubでソースを表示 GitHubでソースを表示 |
|
回帰問題では、価格や確率といった連続的な値の出力を予測することが目的となります。これは、分類問題の目的が、(たとえば、写真にリンゴが写っているかオレンジが写っているかといった)離散的なラベルを予測することであるのとは対照的です。
このノートブックでは、古典的な Auto MPG データセットを使用し、1970 年代後半から 1980 年台初めの自動車の燃費を予測するモデルを構築します。この目的のため、モデルにはこの時期の多数の自動車の仕様を読み込ませます。仕様には、気筒数、排気量、馬力、重量などが含まれています。
このサンプルではtf.keras APIを使用しています。詳細はこのガイドを参照してください。
# Use seaborn for pairplot.pip install -q seaborn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Make NumPy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2022-08-09 01:44:03.878370: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2022-08-09 01:44:04.562175: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvrtc.so.11.1: cannot open shared object file: No such file or directory 2022-08-09 01:44:04.562514: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvrtc.so.11.1: cannot open shared object file: No such file or directory 2022-08-09 01:44:04.562528: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly. 2.10.0-rc0
Auto MPG データセット
このデータセットはUCI Machine Learning Repositoryから入手可能です。
データの取得
まず、データセットをダウンロードします。
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
データのクレンジング
このデータセットには、いくつか欠損値があります。
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
この最初のチュートリアルでは簡単化のためこれらの行を削除します。
dataset = dataset.dropna()
"Origin" 列はカテゴリであり、数値ではないので、pd.get_dummies でワンホットに変換します。
注意: keras.Model を設定して、このような変換を行うことができます。これについては、このチュートリアルでは取り上げません。例については、前処理レイヤーまたは CSV データの読み込みのチュートリアルをご覧ください。
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
dataset.tail()
データをトレーニング用セットとテスト用セットに分割
次に、データセットをトレーニングセットとテストセットに分割します。モデルの最終評価ではテストセットを使用します。
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
データの観察
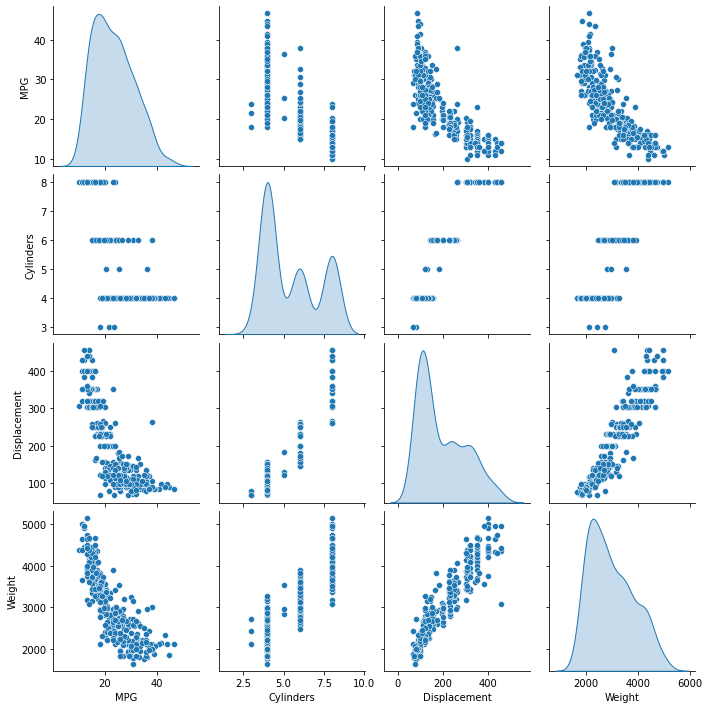
トレーニング用セットの列のいくつかのペアの同時分布を見てみます。
一番上の行を見ると、燃費 (MPG) が他のすべてのパラメータの関数であることは明らかです。他の行を見ると、それらが互いの関数であることが明らかです。
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f390cadddc0>
全体の統計値も見てみましょう。
train_dataset.describe().transpose()
ラベルと特徴量の分離
ラベル、すなわち目的変数を特徴量から分離します。このラベルは、モデルに予測させたい数量です。
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
正規化
統計の表を見て、それぞれの特徴量の範囲がどれほど違っているかに注目してください。
train_dataset.describe().transpose()[['mean', 'std']]
スケールや値の範囲が異なる特徴量を正規化するのはよい習慣です。
これが重要な理由の 1 つは、特徴にモデルの重みが掛けられるためです。したがって、出力のスケールと勾配のスケールは、入力のスケールの影響を受けます。
モデルは特徴量の正規化なしで収束する可能性がありますが、正規化によりトレーニングがはるかに安定します。
注意: ここでは、簡単にするため実行しますが、ワンホット特徴を正規化する利点はありません。前処理レイヤーの使用方法の詳細については、前処理レイヤーの使用ガイドと Keras 前処理レイヤーを使用した構造化データの分類チュートリアルを参照してください。
正規化レイヤー
preprocessing.Normalization レイヤーは、その前処理をモデルに組み込むためのクリーンでシンプルな方法です。
まず、レイヤーを作成します。
normalizer = tf.keras.layers.Normalization(axis=-1)
次にデータに .adapt() します。
normalizer.adapt(np.array(train_features))
これにより、平均と分散が計算され、レイヤーに保存されます。
print(normalizer.mean.numpy())
[[ 5.478 195.318 104.869 2990.252 15.559 75.898 0.178 0.197
0.624]]
レイヤーが呼び出されると、入力データが返され、各特徴は個別に正規化されます。
first = np.array(train_features[:1])
with np.printoptions(precision=2, suppress=True):
print('First example:', first)
print()
print('Normalized:', normalizer(first).numpy())
First example: [[ 4. 90. 75. 2125. 14.5 74. 0. 0. 1. ]] Normalized: [[-0.87 -1.01 -0.79 -1.03 -0.38 -0.52 -0.47 -0.5 0.78]]
線形回帰
DNN モデルを構築する前に、単一変数および複数変数を使用した線形回帰から始めます。
1 つの変数
単一変数の線形回帰から始めて、Horsepower から MPG を予測します。
tf.keras を使用したモデルのトレーニングは、通常、モデルアーキテクチャを定義することから始まります。ここでは、tf.keras.Sequential モデルを使用します。このモデルは、一連のステップを表します。
単一変数の線形回帰モデルには、次の 2 つのステップがあります。
- 入力
horsepowerを正規化します。 - 線形変換 (\(y = mx+b\)) を適用して、
layers.Denseを使用して 1 つの出力を生成します。
入力の数は、input_shape 引数により設定できます。また、モデルを初めて実行するときに自動的に設定することもできます。
まず、馬力 Normalization レイヤーを作成します。
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
Sequential モデルを作成します。
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 2
Non-trainable params: 3
_________________________________________________________________
このモデルは、Horsepower から MPG を予測します。
トレーニングされていないモデルを最初の 10 の馬力の値で実行します。出力は良くありませんが、期待される形状が (10,1) であることがわかります。
horsepower_model.predict(horsepower[:10])
1/1 [==============================] - 0s 361ms/step
array([[ 0.524],
[ 0.296],
[-0.968],
[ 0.735],
[ 0.665],
[ 0.261],
[ 0.788],
[ 0.665],
[ 0.173],
[ 0.296]], dtype=float32)
モデルが構築されたら、Model.compile() メソッドを使用してトレーニング手順を構成します。コンパイルするための最も重要な引数は、loss と optimizer です。これらは、最適化されるもの (mean_absolute_error) とその方法 (optimizers.Adam を使用)を定義するためです。
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
トレーニングを構成したら、Model.fit() を使用してトレーニングを実行します。
%%time
history = horsepower_model.fit(
train_features['Horsepower'],
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 5.74 s, sys: 1.59 s, total: 7.32 s Wall time: 4.69 s
history オブジェクトに保存された数値を使ってモデルのトレーニングの様子を可視化します。
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plot_loss(history)
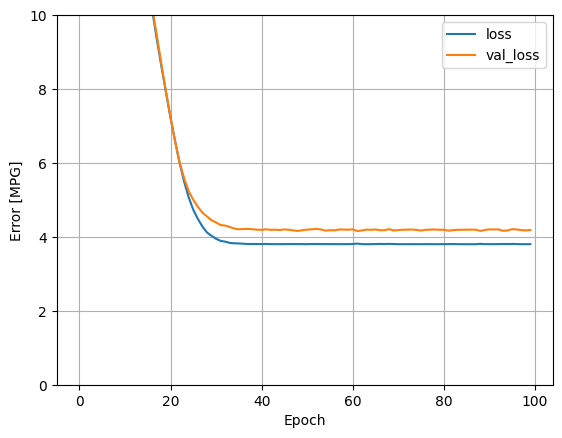
後で使用するために、テスト用セットの結果を収集します。
test_results = {}
test_results['horsepower_model'] = horsepower_model.evaluate(
test_features['Horsepower'],
test_labels, verbose=0)
これは単一変数の回帰であるため、入力の関数としてモデルの予測を簡単に確認できます。
x = tf.linspace(0.0, 250, 251)
y = horsepower_model.predict(x)
8/8 [==============================] - 0s 2ms/step
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Data')
plt.plot(x, y, color='k', label='Predictions')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x, y)
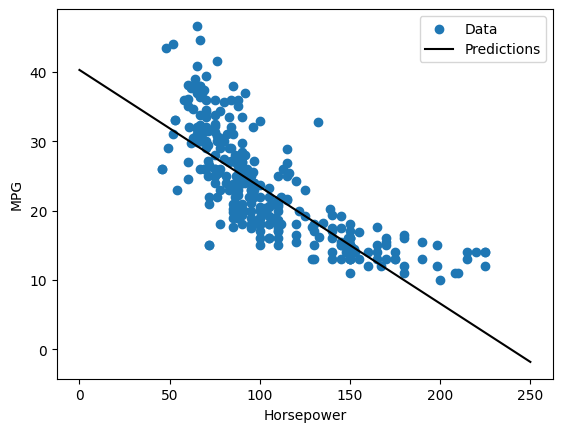
複数の入力
ほぼ同じ設定を使用して、複数の入力に基づく予測を実行することができます。このモデルでは、\(m\) が行列で、\(b\) がベクトルですが、同じ \(y = mx+b\) を実行します。
ここでは、データセット全体に適合した Normalization レイヤーを使用します。
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
入力のバッチでこのモデルを呼び出すと、各例に対して units=1 出力が生成されます。
linear_model.predict(train_features[:10])
1/1 [==============================] - 0s 50ms/step
array([[ 0.34 ],
[-0.635],
[ 1.53 ],
[-1.483],
[-0.969],
[-0.55 ],
[-1.092],
[-1.881],
[ 0.499],
[ 0.644]], dtype=float32)
モデルを呼び出すと、その重み行列が作成されます。これで、kernel (\(y=mx+b\) の \(m\)) の形状が (9,1) であることがわかります。
linear_model.layers[1].kernel
<tf.Variable 'dense_1/kernel:0' shape=(9, 1) dtype=float32, numpy=
array([[ 0.264],
[-0.682],
[ 0.315],
[ 0.405],
[-0.112],
[-0.742],
[-0.734],
[-0.378],
[-0.531]], dtype=float32)>
Keras Model.compile でモデルを構成し、Model.fit で 100 エポックトレーニングします。
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
%%time
history = linear_model.fit(
train_features,
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 5.91 s, sys: 1.53 s, total: 7.44 s Wall time: 4.73 s
この回帰モデルですべての入力を使用すると、入力が 1 つだけの horsepower_model よりもトレーニングエラーや検証エラーが大幅に低くなります。
plot_loss(history)
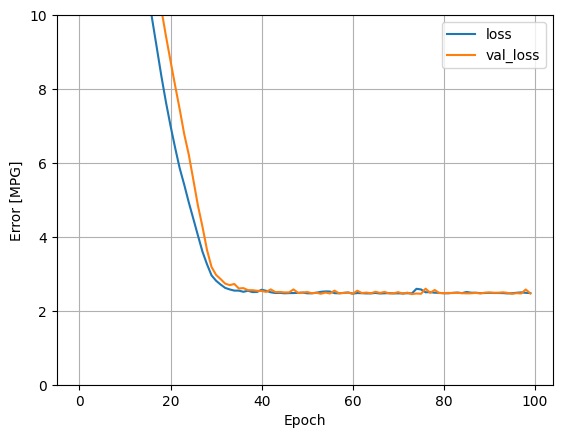
後で使用するために、テスト用セットの結果を収集します。
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
DNN 回帰
前のセクションでは、単一および複数の入力の線形モデルを実装しました。
このセクションでは、単一入力および複数入力の DNN モデルを実装します。コードは基本的に同じですが、モデルが拡張されていくつかの「非表示」の非線形レイヤーが含まれる点が異なります。「非表示」とは、入力または出力に直接接続されていないことを意味します。
コードは基本的に同じですが、モデルが拡張されていくつかの「非表示」の非線形レイヤーが含まれる点が異なります。「非表示」とは、入力または出力に直接接続されていないことを意味します。
これらのモデルには、線形モデルよりも多少多くのレイヤーが含まれます。
- 前と同じく正規化レイヤー。(単一入力モデルの場合は
horsepower_normalizer、複数入力モデルの場合はnormalizerを使用)。 relu非線形性を使用する 2 つの非表示の非線形Denseレイヤー。- 線形単一出力レイヤー
どちらも同じトレーニング手順を使用するため、compile メソッドは以下の build_and_compile_model 関数に含まれています。
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model
DNN と単一入力を使用した回帰
入力 'Horsepower'、正規化レイヤー horsepower_normalizer(前に定義)のみを使用して DNN モデルを作成します。
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
このモデルには、線形モデルよりも多少多くのトレーニング可能なレイヤーが含まれます。
dnn_horsepower_model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense_2 (Dense) (None, 64) 128
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 4,356
Trainable params: 4,353
Non-trainable params: 3
_________________________________________________________________
Keras Model.fit を使用してモデルをトレーニングします。
%%time
history = dnn_horsepower_model.fit(
train_features['Horsepower'],
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 6.03 s, sys: 1.52 s, total: 7.55 s Wall time: 4.9 s
このモデルは、単一入力の線形 horsepower_model よりもわずかに優れています。
plot_loss(history)
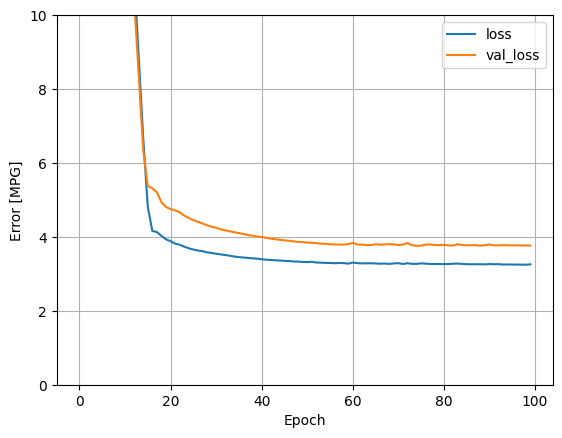
Horsepower の関数として予測をプロットすると、このモデルが非表示のレイヤーにより提供される非線形性をどのように利用するかがわかります。
x = tf.linspace(0.0, 250, 251)
y = dnn_horsepower_model.predict(x)
8/8 [==============================] - 0s 2ms/step
plot_horsepower(x, y)
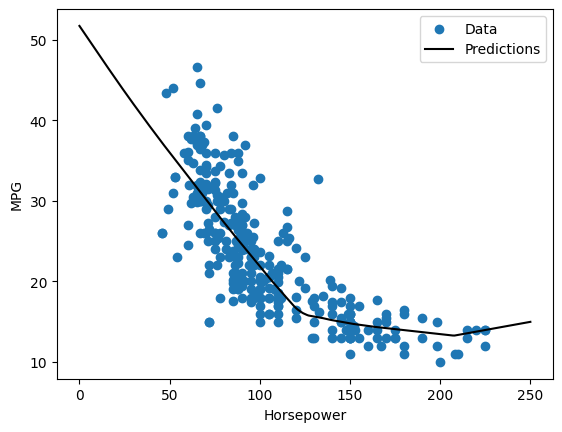
後で使用するために、テスト用セットの結果を収集します。
test_results['dnn_horsepower_model'] = dnn_horsepower_model.evaluate(
test_features['Horsepower'], test_labels,
verbose=0)
完全モデル
すべての入力を使用してこのプロセスを繰り返すと、検証データセットの性能がわずかに向上します。
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization (Normalizatio (None, 9) 19
n)
dense_5 (Dense) (None, 64) 640
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 4,884
Trainable params: 4,865
Non-trainable params: 19
_________________________________________________________________
%%time
history = dnn_model.fit(
train_features,
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 6.09 s, sys: 1.49 s, total: 7.58 s Wall time: 4.86 s
plot_loss(history)
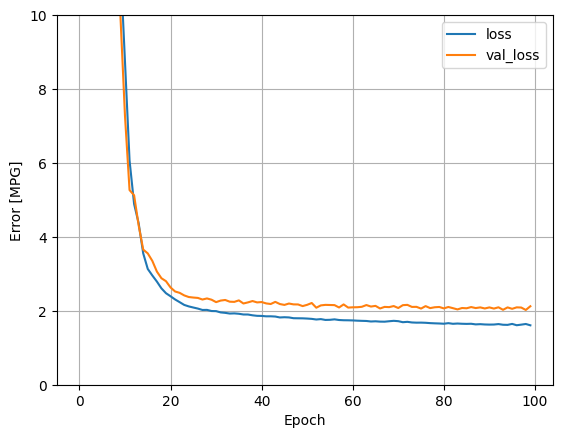
後で使用するために、テスト用セットの結果を収集します。
test_results['dnn_model'] = dnn_model.evaluate(test_features, test_labels, verbose=0)
性能
すべてのモデルがトレーニングされたので、テスト用セットの性能を確認します。
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
これらの結果は、トレーニング中に見られる検証エラーと一致します。
モデルを使った予測
Keras Model.predict を使用して、テストセットの dnn_model で予測を行い、損失を確認します。
test_predictions = dnn_model.predict(test_features).flatten()
a = plt.axes(aspect='equal')
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
lims = [0, 50]
plt.xlim(lims)
plt.ylim(lims)
_ = plt.plot(lims, lims)
3/3 [==============================] - 0s 2ms/step
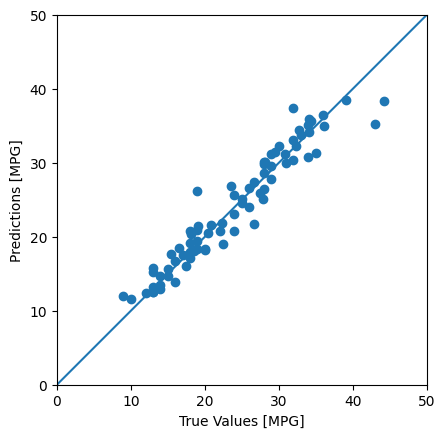
モデルの予測精度は妥当です。
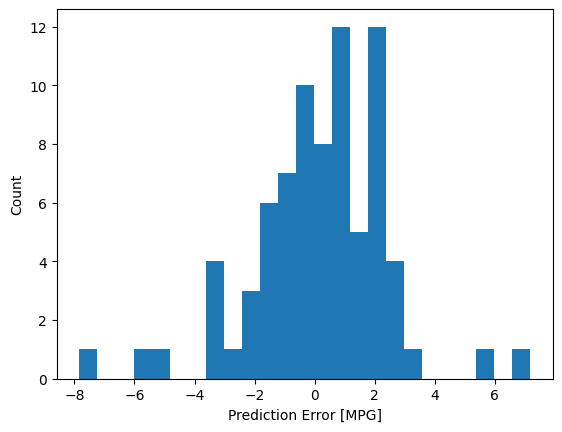
次に、エラー分布を見てみましょう。
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')
モデルに満足している場合は、後で使用できるように保存します。
dnn_model.save('dnn_model')
INFO:tensorflow:Assets written to: dnn_model/assets
モデルを再度読み込むと、同じ出力が得られます。
reloaded = tf.keras.models.load_model('dnn_model')
test_results['reloaded'] = reloaded.evaluate(
test_features, test_labels, verbose=0)
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
まとめ
このノートブックでは、回帰問題を扱うためのテクニックをいくつか紹介しました。
- 平均二乗誤差 (MSE) (
tf.keras.losses.MeanSquaredError) および 平均絶対誤差 (MAE) (tf.keras.losses.MeanAbsoluteError) は回帰問題に使われる一般的な損失関数です。MAE は外れ値の影響を受けにくくなっています。分類問題には異なる損失関数が使われます。 - 同様に、回帰問題に使われる評価指標も分類問題とは異なります。
- 入力数値特徴量の範囲が異なっている場合、特徴量ごとにおなじ範囲に正規化するべきです。
- 過適合は DNN モデルの一般的な問題ですが、このチュートリアルでは問題ではありませんでした。これに関する詳細については、オーバーフィットとアンダーフィットのチュートリアルを参照してください。
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.