
| |
|
 GitHubでソースを表示 GitHubでソースを表示 |
このチュートリアルでは、TensorFlow で CSV データを使用する方法の例を示します。
これには2つの主要な部分があります。
- Loading the data off disk
- Pre-processing it into a form suitable for training.
このチュートリアルでは、読み込みに焦点を当て、前処理の簡単な例をいくつか実演します。前処理レイヤーの使用方法の詳細については、前処理レイヤーの使用ガイドと Keras 前処理レイヤーを使用した構造化データの分類チュートリアルを参照してください。
MNIST モデルをビルドする
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
2022-12-15 01:04:36.061220: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-15 01:04:36.061327: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-15 01:04:36.061337: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
インメモリデータ
小さな CSV データセットの場合、TensorFlow モデルをトレーニングする最も簡単な方法は、pandas データフレームまたは NumPy 配列としてメモリを読み込むことです。
比較的単純な例は、アワビデータセットです。
- データセットが小さい。
- すべての入力特徴量は、制限された範囲の浮動小数点値です。
データを pandas DataFrame にダウンロードする方法は次のとおりです。
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
データセットには、海のカタツムリの一種であるアワビの一連の測定値が含まれています。

「アワビ貝殻」 (作成者:Nicki Dugan Pogue、CC BY-SA 2.0)
このデータセットの名目上のタスクは、他の測定値から年齢を予測することなので、トレーニング用に特徴とラベルを分離します。
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
このデータセットでは、すべての特徴を同じように扱います。特徴を単一の NumPy アレイにパックします。
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
次に、回帰モデルで年齢を予測します。入力テンソルは 1 つしかないため、ここでは keras.Sequential モデルで十分です。
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.keras.losses.MeanSquaredError(),
optimizer = tf.keras.optimizers.Adam())
モデルをトレーニングするには、特徴とラベルをModel.fitに渡します。
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 2s 2ms/step - loss: 69.3848 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 13.1364 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.5679 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.1167 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.7009 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.3671 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 7.0970 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.8937 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7407 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6308 <keras.callbacks.History at 0x7fbf1fb844f0>
CSV データを使用してモデルをトレーニングする最も基本的な方法を見てきました。次に、前処理を適用して数値列を正規化する方法を学習します。
基本的な前処理
モデルへの入力を正規化することをお勧めします。Keras 前処理レイヤーは、この正規化をモデルに組み込むための便利な方法を提供します。
tf.keras.layers.Normalization レイヤーは、各列の平均と分散を事前に計算し、これらを使用してデータを正規化します。
まず、レイヤーを作成します。
normalize = layers.Normalization()
次に、Normalization.adapt() メソッドを使用して、正規化レイヤーをデータに適合させます。
注意: トレーニングデータは、PreprocessingLayer.adapt メソッドでのみ使用してください。検証データやテストデータは使用しないでください。
normalize.adapt(abalone_features)
次に、モデルで正規化レイヤーを使用します。
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.keras.losses.MeanSquaredError(),
optimizer = tf.keras.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 90.6943 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 49.7763 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 14.3816 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 5.5163 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0134 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9706 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9489 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9391 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9388 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9338 <keras.callbacks.History at 0x7fbf102177f0>
混合データ型
The "Titanic" dataset contains information about the passengers on the Titanic. The nominal task on this dataset is to predict who survived.

Image from Wikimedia
{kind=link}
The raw data can easily be loaded as a Pandas DataFrame, but is not immediately usable as input to a TensorFlow model.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
データ型と範囲が異なるため、特徴を NumPy 配列に単純にスタックして、tf.keras.Sequential モデルに渡すことはできません。各列は個別に処理する必要があります。
1 つのオプションとして、データをオフラインで前処理して(任意のツールを使用して)、カテゴリカル列を数値列に変換してから、処理された出力を TensorFlow モデルに渡すことができます。このアプローチの欠点は、モデルを保存してエクスポートすると、前処理が一緒に保存されないことです。Keras 前処理レイヤーはモデルの一部であるため、この問題を回避できます。
この例では、Keras Functional API を使用して前処理ロジックを実装するモデルを構築します。サブクラス化によって行うこともできます。
Functional API は、「シンボリック」テンソルで動作します。 通常の「eager」テンソルには値があります。 対照的に、これらの「シンボリック」テンソルはそうではありません。代わりに、実行されている演算を追跡し、後で実行できる計算の表現を構築します。 簡単な例を次に示します。
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
前処理モデルを構築するには、まず、CSV 列の名前とデータ型に一致する一連のシンボリック keras.Input オブジェクトを構築します。
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
前処理ロジックの最初のステップは、数値入力を連結して、正規化レイヤーを介して実行することです。
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
シンボリック前処理の結果をすべて収集して、後で連結します。
preprocessed_inputs = [all_numeric_inputs]
文字列入力の場合は、tf.keras.layers.StringLookup 関数を使用して、文字列から語彙の整数インデックスにマップします。次に、tf.keras.layers.CategoryEncoding を使用して、インデックスをモデルに適した float32 データに変換します。
tf.keras.layers.CategoryEncoding レイヤーのデフォルト設定は、入力ごとにワンホットベクターを作成します。tf.keras.layers.Embedding も機能します。 このトピックの詳細については、前処理レイヤーガイドおよび Keras 前処理レイヤーを使用して構造化データを分類するチュートリアルを参照してください。
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(num_tokens=lookup.vocabulary_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
収集された inputs と processed_inputs を使用すると、前処理されたすべての入力を連結して、前処理を処理するモデルを構築できます。
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
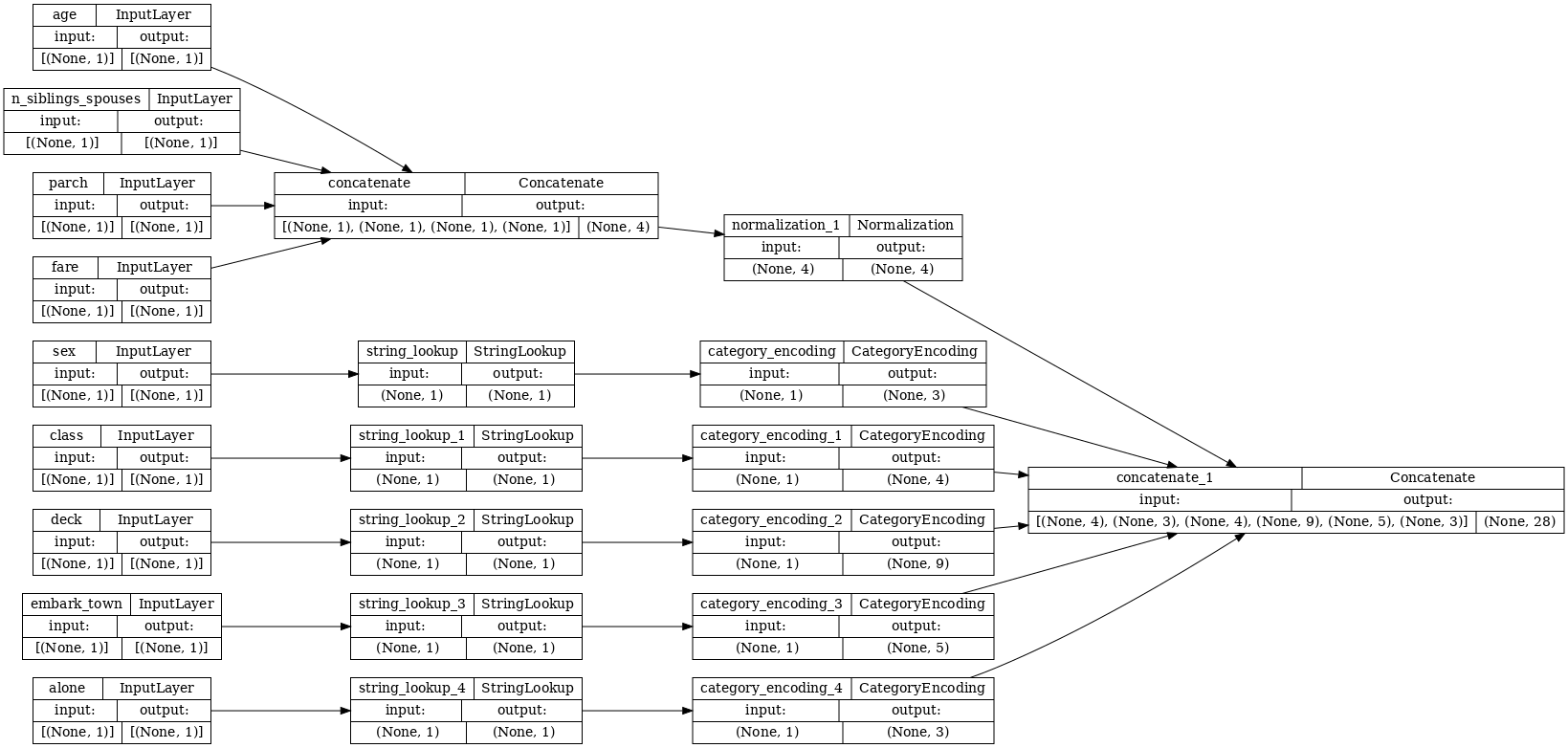
このmodelには、入力の前処理のみが含まれています。実行して、データに対して何が行われるかを確認できます。 Keras モデルは、Pandas DataFramesを自動的に変換しません。これは、1 つのテンソルに変換する必要があるのか、テンソルのディクショナリに変換する必要があるのかが明確でないためです。ここでは、テンソルのディクショナリに変換します。
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
最初のトレーニングサンプルをスライスしてこの前処理モデルに渡すと、数値特徴と文字列のワンホットがすべて連結されていることがわかります。
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
次に、この上にモデルを構築します。
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
モデルをトレーニングする際に、特徴のディクショナリをx、ラベルをyとして渡します。
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.6127 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5131 Epoch 3/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4796 Epoch 4/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4598 Epoch 5/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4468 Epoch 6/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4389 Epoch 7/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4312 Epoch 8/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4279 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4245 Epoch 10/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4237 <keras.callbacks.History at 0x7fbf1006c850>
前処理はモデルの一部であるため、モデルを保存して別の場所で再読み込みしても、同じ結果を得ることができます。
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.903]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.903]], shape=(1, 1), dtype=float32)
tf.data を使用する
前のセクションでは、モデルのトレーニングの際に、モデルに組み込まれているデータのシャッフルとバッチ処理に依存しました。
入力データパイプラインをさらに制御する必要がある場合、またはメモリに簡単に収まらないデータを使用する必要がある場合は、tf.dataを使用します。
詳細については、tf.data: TensorFlow 入力パイプラインをビルドするガイドをご覧ください。
インメモリデータ
tf.data を CSV データに適用する最初の例として、次のコードで前のセクションの特徴のディクショナリを手動でスライスします。各インデックスは、特徴ごとにそのインデックスを取得します。
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
実行して、最初のサンプルを出力します。
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
メモリデータローダーの最も基本的なtf.data.Datasetは、Dataset.from_tensor_slicesコンストラクタです。これにより、TensorFlowで上記のslices関数の一般化されたバージョンを実装するtf.data.Datasetが返されます。
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
他の Python 反復可能と同様に、tf.data.Datasetを反復できます。
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
from_tensor_slices関数は、ネストされたディクショナリーまたはタプルの任意の構造を処理できます。次のコードは、(features_dict, labels)ペアのデータセットを作成します。
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
このDatasetを使用してモデルをトレーニングするには、少なくともshuffleとbatchのデータが必要です。
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
featuresとlabelsをModel.fitに渡す代わりに、データセットを渡します。
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 4ms/step - loss: 0.4218 Epoch 2/5 20/20 [==============================] - 0s 4ms/step - loss: 0.4229 Epoch 3/5 20/20 [==============================] - 0s 4ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 4ms/step - loss: 0.4209 Epoch 5/5 20/20 [==============================] - 0s 4ms/step - loss: 0.4213 <keras.callbacks.History at 0x7fc0092aef10>
単一のファイルから
これまでのところ、このチュートリアルはインメモリデータを扱ってきました。tf.dataは、データパイプラインを構築するための非常にスケーラブルなツールキットであり、CSV ファイルの読み込みを処理するためのいくつかの関数を提供します。
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 30874/30874 [==============================] - 0s 0us/step
次に、ファイルから CSV データを読み取り、tf.data.Datasetを作成します。
(完全なドキュメントについては、tf.data.experimental.make_csv_dataset を参照してください。)
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/data/experimental/ops/readers.py:572: ignore_errors (from tensorflow.python.data.experimental.ops.error_ops) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.ignore_errors` instead.
この関数には以下のような多くの便利な機能が含まれているため、データを簡単に操作できます。
- 列ヘッダーをディクショナリキーとして使用する。
- それぞれの列の型を自動的に決定する。
注意: tf.data.experimental.make_csv_dataset で num_epochs 引数を設定してください。
そうしないと、tf.data.Dataset のデフォルトの動作は無限ループです。
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'male' b'male' b'male'] age : [29. 2. 9. 42. 32.] n_siblings_spouses : [1 4 4 1 0] parch : [0 1 2 0 0] fare : [66.6 39.688 31.388 27. 56.496] class : [b'First' b'Third' b'Third' b'Second' b'Third'] deck : [b'C' b'unknown' b'unknown' b'unknown' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Southampton' b'Southampton' b'Southampton'] alone : [b'n' b'n' b'n' b'n' b'y'] label : [0 0 0 0 1]
注意: 上記のセルを 2 回実行すると、異なる結果が生成されます。tf.data.experimental.make_csv_dataset のデフォルト設定には、shuffle_buffer_size=1000 が含まれます。これは、この小さなデータセットには十分ですが、実際のデータセットには適切ではない場合があります。
また、その場でデータを解凍することもできます。 これは、都市州間高速道路交通データセットを含む gzip 圧縮された CSV ファイルです。

画像出典:Wikimedia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 405373/405373 [==============================] - 0s 0us/step
圧縮ファイルから直接読み取るようにcompression_type引数を設定します。
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [285.65 267.15 284.61 275.36 296.48] rain_1h : [0.25 0. 0. 0. 0. ] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [92 90 0 90 0] weather_main : [b'Rain' b'Clouds' b'Clear' b'Drizzle' b'Clear'] weather_description : [b'light rain' b'overcast clouds' b'Sky is Clear' b'light intensity drizzle' b'Sky is Clear'] date_time : [b'2013-06-06 00:00:00' b'2013-02-12 21:00:00' b'2013-08-04 07:00:00' b'2013-05-04 18:00:00' b'2013-08-14 17:00:00'] label : [ 655 2669 1132 4431 6136]
注意: tf.dataパイプラインでこれらの日時文字列を解析する必要がある場合は、tfa.text.parse_timeを使用できます。
キャッシング
CSV データの解析にはオーバーヘッドがあります。小さなモデルの場合、これがトレーニングのボトルネックになる可能性があります。
ユースケースによっては、Dataset.cache または tf.data.experimental.snapshot を使用して、CSV データが最初のエポックでのみ解析されるようにすることをお勧めします。
cacheメソッドとsnapshotメソッドの主な違いは、cacheファイルは、それらを作成した TensorFlow プロセスでのみ使用できることですが、snapshotファイルは他のプロセスで読み取ることができます。
たとえば、traffic_volume_csv_gz_ds を 20 回繰り返すと、キャッシュなしで最大15秒、キャッシュありで最大 2 秒かかります。
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 15.6 s, sys: 4.14 s, total: 19.8 s Wall time: 11.5 s
注意: Dataset.cache は、最初のエポックからのデータを保存し、順番に再生します。したがって、cache を使用すると、パイプラインの早い段階でシャッフルが無効になります。以下では、Dataset.shuffleは、Dataset.cache の後に追加されます。
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.86 s, sys: 297 ms, total: 2.15 s Wall time: 1.68 s
注意: tf.data.experimental.snapshot ファイルは、使用中のデータセットの一時ストレージ用です。これは、長期保存用の形式ではありません。このファイル形式は内部の詳細と見なされ、TensorFlow バージョン間で保証されません。
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.88 s, sys: 854 ms, total: 3.73 s Wall time: 1.96 s
CSV ファイルの読み込みによってデータの読み込みが遅くなり、Dataset.cache と tf.data.experimental.snapshot がユースケースに不十分な場合は、データをより合理化された形式に再度エンコードすることを検討してください。
複数のファイル
このセクションのこれまでのすべての例は、tf.dataなしで簡単に実行できます。 tf.dataが単純化できるのは、ファイルの収集を処理するときだけです。
たとえば、文字フォント画像データセットは、フォントごとに1つずつの CSV ファイルのコレクションとして配布されます。

画像出典:Pixabay、Willi Heidelbach
データセットをダウンロードし、そのファイルを確認します。
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160313983/160313983 [==============================] - 3s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
多数のファイルを処理する場合、glob スタイルの file_pattern を tf.data.experimental.make_csv_dataset 関数に渡すことができます。ファイルの順序は、反復ごとにシャッフルされます。
num_parallel_reads引数を使用して、並列に読み取り、共にインターリーブされるファイルの数を設定します。
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
これらの CSV ファイルでは、画像が 1 行にフラット化されています。列名の形式は r{row}c{column} です。以下は最初のバッチです。
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'BASKERVILLE' b'CANDARA' b'IMPACT' b'BERNARD' b'VLADIMIR' b'MYANMAR' b'TAI' b'PHAGSPA' b'COURIER' b'PHAGSPA'] fontVariant : [b'BASKERVILLE OLD FACE' b'CANDARA' b'IMPACT' b'BERNARD MT CONDENSED' b'VLADIMIR SCRIPT' b'MYANMAR TEXT' b'MICROSOFT TAI LE' b'MICROSOFT PHAGSPA' b'scanned' b'MICROSOFT PHAGSPA'] m_label : [ 48 8311 1089 733 218 43518 210 8227 51 8245] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 0 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [33 41 44 29 23 23 20 62 0 43] m_left : [22 22 22 37 28 24 29 24 0 24] originalH : [46 24 45 8 57 67 63 10 20 15] originalW : [29 14 28 28 61 64 49 6 15 7] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 1 1 1 1 1 255 1 255] r0c1 : [ 1 255 1 1 1 1 1 255 1 255] r0c2 : [ 1 255 1 1 1 1 1 255 1 255] r0c3 : [ 1 255 13 1 1 1 1 86 1 255] ... [total: 412 features]
オプション:パッキングフィールド
以上のように、各ピクセルを別々の列で操作することは望ましくありません。このデータセットを使用する前に、必ずピクセルをイメージテンソルにパックしてください。
次に、列名を解析して各例の画像を作成するコードを示します。
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
その関数をデータセット内の各バッチに適用します。
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
結果の画像をプロットします。
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

下位レベルの関数
このチュートリアルでは、CSV データを読み取るための最高レベルのユーティリティに焦点を当ててきました。ユースケースが基本的なパターンに適合しない場合に上級ユーザーに役立つ API が他の 2 つあります。
tf.io.decode_csv: テキストの行を CSV 列テンソルのリストに解析するための関数。tf.data.experimental.CsvDataset: 下位レベルの CSV データセットコンストラクタ。
このセクションでは、tf.data.experimental.make_csv_dataset により提供される機能を再作成して、この低レベルの機能をどのように使用できるかを示します。
tf.io.decode_csv
この関数は、文字列または文字列のリストを列のリストにデコードします。
tf.data.experimental.make_csv_dataset とは異なり、この関数は列のデータ型を推測しようとしません。列ごとの正しい型の値を含む record_defaults のリストを提供することにより、列の型を指定します。
次のように tf.io.decode_csv を使用してタイタニックデータを文字列として読み取ります。
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
それらを実際のタイプで解析するには、対応する型のrecord_defaultsのリストを作成します。
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
注意: CSV テキストの個々の行を呼び出すよりも、行の大きなバッチで tf.io.decode_csv を呼び出す方が効率的です。
tf.data.experimental.CsvDataset
tf.data.experimental.CsvDataset クラスは、tf.data.experimental.make_csv_dataset 関数の便利な機能(列ヘッダーの解析、列の型推論、自動シャッフル、ファイルのインターリーブ)なしで、最小限の CSV Dataset インターフェースを提供します。
このコンストラクタは、tf.io.decode_csv と同じ方法で record_defaults を使用します。
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
上記のコードは基本的に次と同等です。
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
複数のファイル
tf.data.experimental.CsvDataset を使用してフォントデータセットを解析するには、最初に record_defaults の列の型を決定する必要があります。まず、1 つのファイルの最初の行を調べます。
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
最初の 2 つのフィールドのみが文字列で、残りは int または float です。コンマを数えることで特徴の総数を取得できます。
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
tf.data.experimental.CsvDataset コンストラクタは、入力ファイルのリストを取得できますが、それらを順番に読み取ります。CSV のリストの最初のファイルは AGENCY.csv です。
font_csvs[0]
'fonts/AGENCY.csv'
したがって、ファイルのリストを CsvDataset に渡すと、AGENCY.csv のレコードが最初に読み取られます。
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
複数のファイルをインターリーブするには、Dataset.interleaveを使用します。
CSV ファイル名を含む初期データセットは次のとおりです。
font_files = tf.data.Dataset.list_files("fonts/*.csv")
これにより、各エポックのファイル名がシャッフルされます。
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/SNAP.csv'
b'fonts/CALIBRI.csv'
b'fonts/IMPACT.csv'
b'fonts/FELIX TITLING.csv'
b'fonts/VINER.csv'
...
Epoch 2:
b'fonts/BOOK.csv'
b'fonts/IMPACT.csv'
b'fonts/JAVANESE.csv'
b'fonts/CURLZ.csv'
b'fonts/TIMES.csv'
...
interleaveメソッドは、親Datasetの各要素に対して子Datasetを作成するmap_funcを取ります。
ここでは、ファイルのデータセットの各要素から tf.data.experimental.CsvDataset を作成します。
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
インターリーブによって返される Dataset は、子 Dataset の数を循環することによって要素を返します。以下でデータセットが cycle_length=3 で 3 つのフォントファイルをどのように循環するかに注目してください。
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
/tmpfs/tmp/ipykernel_523702/998453860.py:5: DeprecationWarning: an integer is required (got type numpy.float32). Implicit conversion to integers using __int__ is deprecated, and may be removed in a future version of Python. fonts_dict['character'].append(chr(row[2].numpy()))
性能
前述のとおり、文字列のバッチで実行する場合、tf.io.decode_csv の方が効率的です。
大きなバッチサイズを使用する場合は、これを利用して CSV の読み込みパフォーマンスを向上させることができます(ただし、最初に caching を試してください)。
組み込みローダー 20 では、2048 サンプルのバッチは約 17 秒かかります。
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 50.3 s, sys: 4.49 s, total: 54.8 s Wall time: 21.2 s
テキスト行のバッチをdecode_csvに渡すと、約 5 秒で高速に実行されます。
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 4.24 s, sys: 51.5 ms, total: 4.29 s Wall time: 721 ms
大きなバッチを使用して CSV パフォーマンスを向上させる別の例については、過剰適合および過少学習チュートリアルを参照してください。
このようなアプローチは機能する可能性がありますが、Dataset.cache や tf.data.experimental.snapshot などの他のオプションやデータをより合理化された形式に再エンコードすることを検討してください。