
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial muestra cómo cargar y preprocesar un conjunto de datos de imagen de tres maneras:
- Primero, utilizará utilidades de preprocesamiento de Keras de alto nivel (como
tf.keras.utils.image_dataset_from_directory) y capas (comotf.keras.layers.Rescaling) para leer un directorio de imágenes en el disco. - A continuación, escribirá su propia canalización de entrada desde cero utilizando tf.data .
- Finalmente, descargará un conjunto de datos del amplio catálogo disponible en TensorFlow Datasets .
Configuración
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Descargar el conjunto de datos de flores
Este tutorial utiliza un conjunto de datos de varios miles de fotos de flores. El conjunto de datos de flores contiene cinco subdirectorios, uno por clase:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
Después de descargar (218 MB), ahora debería tener disponible una copia de las fotos de flores. Hay 3.670 imágenes en total:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Cada directorio contiene imágenes de ese tipo de flor. Aquí hay algunas rosas:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Cargue datos usando una utilidad Keras
Carguemos estas imágenes fuera del disco utilizando la útil utilidad tf.keras.utils.image_dataset_from_directory .
Crear un conjunto de datos
Defina algunos parámetros para el cargador:
batch_size = 32
img_height = 180
img_width = 180
Es una buena práctica usar una división de validación al desarrollar su modelo. Usarás el 80% de las imágenes para entrenamiento y el 20% para validación.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Puede encontrar los nombres de clase en el atributo class_names en estos conjuntos de datos.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Visualiza los datos
Aquí están las primeras nueve imágenes del conjunto de datos de entrenamiento.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
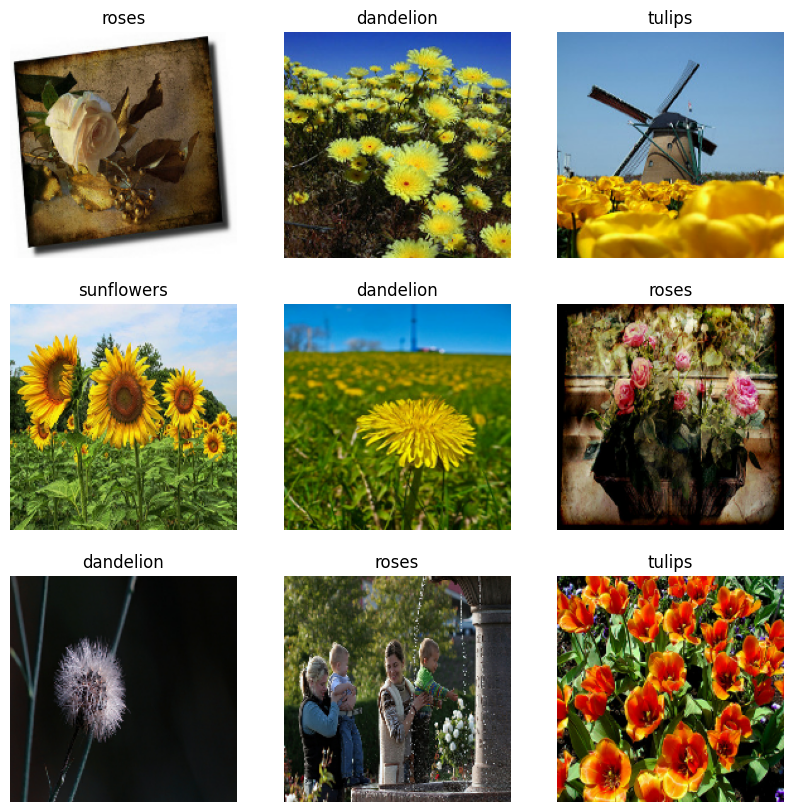
Puede entrenar un modelo usando estos conjuntos de datos pasándolos a model.fit (que se muestra más adelante en este tutorial). Si lo desea, también puede iterar manualmente sobre el conjunto de datos y recuperar lotes de imágenes:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch es un tensor de la forma (32, 180, 180, 3) . Este es un lote de 32 imágenes de forma 180x180x3 (la última dimensión se refiere a los canales de color RGB). El label_batch es un tensor de la forma (32,) , estas son las etiquetas correspondientes a las 32 imágenes.
Puede llamar a .numpy() en cualquiera de estos tensores para convertirlos en numpy.ndarray .
Estandarizar los datos
Los valores del canal RGB están en el rango [0, 255] . Esto no es ideal para una red neuronal; en general, debe buscar que sus valores de entrada sean pequeños.
Aquí, estandarizará los valores para que estén en el rango [0, 1] usando tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
Hay dos formas de usar esta capa. Puede aplicarlo al conjunto de datos llamando a Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
O puede incluir la capa dentro de la definición de su modelo para simplificar la implementación. Aquí utilizará el segundo enfoque.
Configurar el conjunto de datos para el rendimiento
Asegurémonos de utilizar la captación previa almacenada en búfer para que pueda obtener datos del disco sin que la E/S se convierta en un bloqueo. Estos son dos métodos importantes que debe usar al cargar datos:
-
Dataset.cachemantiene las imágenes en la memoria después de que se cargan fuera del disco durante la primera época. Esto asegurará que el conjunto de datos no se convierta en un cuello de botella mientras entrena su modelo. Si su conjunto de datos es demasiado grande para caber en la memoria, también puede usar este método para crear un caché en disco de alto rendimiento. -
Dataset.prefetchsuperpone el preprocesamiento de datos y la ejecución del modelo durante el entrenamiento.
Los lectores interesados pueden obtener más información sobre ambos métodos, así como sobre cómo almacenar datos en caché en el disco, en la sección Precarga de la guía Mejor rendimiento con la API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
entrenar a un modelo
Para completar, mostrará cómo entrenar un modelo simple utilizando los conjuntos de datos que acaba de preparar.
El modelo secuencial consta de tres bloques de convolución ( tf.keras.layers.Conv2D ) con una capa de agrupación máxima ( tf.keras.layers.MaxPooling2D ) en cada uno de ellos. Hay una capa totalmente conectada ( tf.keras.layers.Dense ) con 128 unidades encima que se activa mediante una función de activación de ReLU ( 'relu' ). Este modelo no se ha ajustado de ninguna manera: el objetivo es mostrarle la mecánica utilizando los conjuntos de datos que acaba de crear. Para obtener más información sobre la clasificación de imágenes, visite el tutorial de clasificación de imágenes .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
Elija el optimizador tf.keras.optimizers.Adam y la función de pérdida tf.keras.losses.SparseCategoricalCrossentropy . Para ver la precisión del entrenamiento y la validación para cada época de entrenamiento, pase el argumento de metrics a Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Puede notar que la precisión de la validación es baja en comparación con la precisión del entrenamiento, lo que indica que su modelo se está sobreajustando. Puede obtener más información sobre el sobreajuste y cómo reducirlo en este tutorial .
Uso de tf.data para un control más preciso
La utilidad de preprocesamiento de Keras anterior, tf.keras.utils.image_dataset_from_directory , es una forma conveniente de crear un tf.data.Dataset a partir de un directorio de imágenes.
Para un control de grano más fino, puede escribir su propia canalización de entrada usando tf.data . Esta sección muestra cómo hacerlo, comenzando con las rutas de archivo del archivo TGZ que descargó anteriormente.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
La estructura de árbol de los archivos se puede utilizar para compilar una lista de nombres de class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Divida el conjunto de datos en conjuntos de entrenamiento y validación:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
Puede imprimir la longitud de cada conjunto de datos de la siguiente manera:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Escriba una función breve que convierta una ruta de archivo en un par (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
Use Dataset.map para crear un conjunto de datos de pares de image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Configurar el conjunto de datos para el rendimiento
Para entrenar un modelo con este conjunto de datos, querrá los datos:
- Estar bien barajado.
- Para ser dosificado.
- Los lotes estarán disponibles lo antes posible.
Estas características se pueden agregar usando la API tf.data . Para obtener más detalles, visite la guía Rendimiento de canalización de entrada .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
Visualiza los datos
Puede visualizar este conjunto de datos de manera similar al que creó anteriormente:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
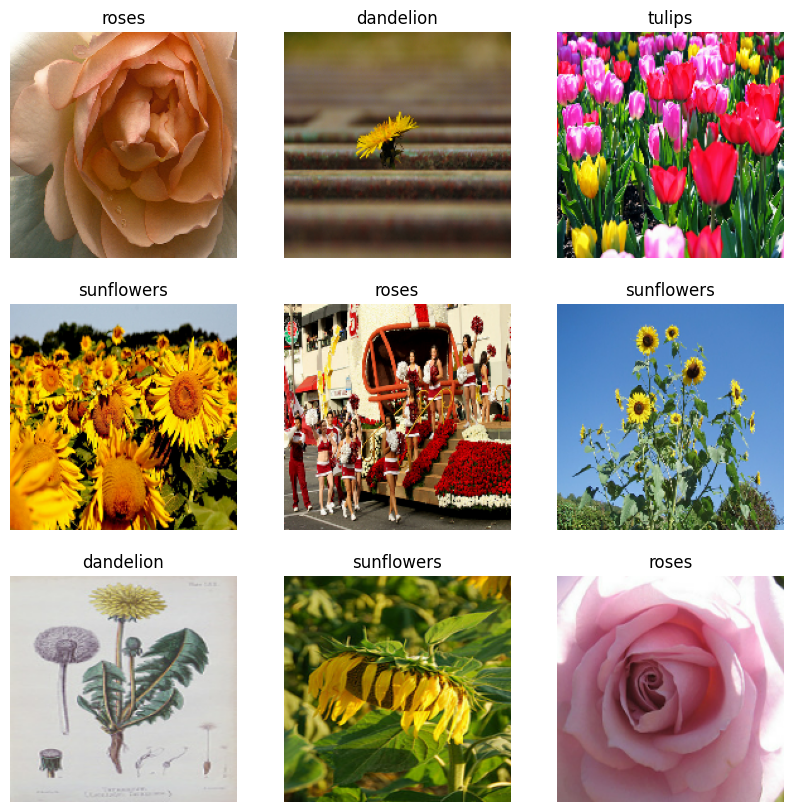
Continuar entrenando al modelo
Ahora ha creado manualmente un tf.data.Dataset similar al creado por tf.keras.utils.image_dataset_from_directory arriba. Puedes seguir entrenando al modelo con él. Como antes, entrenarás durante unas pocas épocas para que el tiempo de ejecución sea corto.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
Uso de conjuntos de datos de TensorFlow
Hasta ahora, este tutorial se ha centrado en cargar datos fuera del disco. También puede encontrar un conjunto de datos para usar explorando el amplio catálogo de conjuntos de datos fáciles de descargar en TensorFlow Datasets .
Como previamente cargó el conjunto de datos Flowers fuera del disco, ahora importémoslo con TensorFlow Datasets.
Descarga el conjunto de datos de Flowers usando TensorFlow Datasets:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
El conjunto de datos de flores tiene cinco clases:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Recuperar una imagen del conjunto de datos:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Como antes, recuerde agrupar, mezclar y configurar los conjuntos de entrenamiento, validación y prueba para el rendimiento:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
Puede encontrar un ejemplo completo de cómo trabajar con el conjunto de datos de Flowers y los conjuntos de datos de TensorFlow visitando el tutorial de aumento de datos .
Próximos pasos
Este tutorial mostró dos formas de cargar imágenes fuera del disco. En primer lugar, aprendió a cargar y preprocesar un conjunto de datos de imagen utilizando las capas y utilidades de preprocesamiento de Keras. A continuación, aprendió a escribir una canalización de entrada desde cero utilizando tf.data . Finalmente, aprendió a descargar un conjunto de datos de TensorFlow Datasets.
Para sus próximos pasos:
- Puede obtener información sobre cómo agregar aumento de datos .
- Para obtener más información sobre
tf.data, puede visitar la guía tf.data: Build TensorFlow input pipelines .