
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel montre comment mettre en œuvre la méthode Actor-Critic à l'aide de TensorFlow pour former un agent sur l'environnement Open AI Gym CartPole-V0. Le lecteur est supposé avoir une certaine familiarité avec les méthodes de gradient de politique d'apprentissage par renforcement.
Méthodes Acteur-Critique
Les méthodes d'acteur-critique sont des méthodes d'apprentissage par différence temporelle (TD) qui représentent la fonction politique indépendamment de la fonction de valeur.
Une fonction de politique (ou politique) renvoie une distribution de probabilité sur les actions que l'agent peut entreprendre en fonction de l'état donné. Une fonction de valeur détermine le rendement attendu pour un agent commençant à un état donné et agissant selon une politique particulière pour toujours.
Dans la méthode Acteur-Critique, la politique est appelée l' acteur qui propose un ensemble d'actions possibles compte tenu d'un état, et la fonction de valeur estimée est appelée critique , qui évalue les actions prises par l' acteur en fonction de la politique donnée .
Dans ce didacticiel, l' acteur et le critique seront représentés à l'aide d'un réseau de neurones à deux sorties.
CartPole-v0
Dans l' environnement CartPole-v0 , un poteau est attaché à un chariot se déplaçant le long d'une piste sans friction. La perche démarre debout et le but de l'agent est de l'empêcher de tomber en appliquant une force de -1 ou +1 sur le chariot. Une récompense de +1 est donnée pour chaque pas de temps où la perche reste droite. Un épisode se termine lorsque (1) le poteau est à plus de 15 degrés de la verticale ou (2) le chariot se déplace à plus de 2,4 unités du centre.
Le problème est considéré comme "résolu" lorsque la récompense totale moyenne pour l'épisode atteint 195 sur 100 essais consécutifs.
Installer
Importez les packages nécessaires et configurez les paramètres globaux.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
Modèle
L' acteur et le critique seront modélisés à l'aide d'un réseau de neurones qui génère respectivement les probabilités d'action et la valeur critique. Ce didacticiel utilise le sous-classement de modèle pour définir le modèle.
Pendant le passage vers l'avant, le modèle prendra l'état comme entrée et produira à la fois les probabilités d'action et la valeur critique \(V\), qui modélise la fonction de valeur dépendante de l'état . L'objectif est de former un modèle qui choisit des actions en fonction d'une politique \(\pi\) qui maximise le rendement attendu.
Pour Cartpole-v0, il existe quatre valeurs représentant l'état : la position du chariot, la vitesse du chariot, l'angle du pôle et la vitesse du pôle respectivement. L'agent peut effectuer deux actions pour pousser le chariot respectivement vers la gauche (0) et la droite (1).
Reportez-vous à la page wiki CartPole-v0 d'OpenAI Gym pour plus d'informations.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
Entraînement
Pour former l'agent, vous suivrez ces étapes :
- Exécutez l'agent sur l'environnement pour collecter des données d'entraînement par épisode.
- Calculez le rendement attendu à chaque pas de temps.
- Calculez la perte pour le modèle combiné acteur-critique.
- Calculez les gradients et mettez à jour les paramètres du réseau.
- Répétez 1 à 4 jusqu'à ce que le critère de réussite ou le nombre maximal d'épisodes soit atteint.
1. Collecte des données d'entraînement
Comme dans l'apprentissage supervisé, pour entraîner le modèle acteur-critique, vous devez disposer de données d'entraînement. Cependant, afin de collecter ces données, le modèle devrait être "exécuté" dans l'environnement.
Les données d'entraînement sont collectées pour chaque épisode. Ensuite, à chaque pas de temps, la passe avant du modèle sera exécutée sur l'état de l'environnement afin de générer des probabilités d'action et la valeur critique en fonction de la politique actuelle paramétrée par les poids du modèle.
L'action suivante sera échantillonnée à partir des probabilités d'action générées par le modèle, qui seraient ensuite appliquées à l'environnement, provoquant la génération de l'état et de la récompense suivants.
Ce processus est implémenté dans la fonction run_episode , qui utilise les opérations TensorFlow afin qu'il puisse ensuite être compilé dans un graphique TensorFlow pour une formation plus rapide. Notez que tf.TensorArray s ont été utilisés pour prendre en charge l'itération Tensor sur des tableaux de longueur variable.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. Calcul des rendements attendus
La séquence de récompenses pour chaque pas de temps \(t\), \(\{r_{t}\}^{T}_{t=1}\) collecté au cours d'un épisode est convertie en une séquence de rendements attendus \(\{G_{t}\}^{T}_{t=1}\) dans laquelle la somme des récompenses est prise du pas de temps actuel \(t\) à \(T\) et chaque la récompense est multipliée par un facteur de réduction décroissant de manière exponentielle \(\gamma\):
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
Depuis \(\gamma\in(0,1)\), les récompenses plus éloignées du pas de temps actuel ont moins de poids.
Intuitivement, le rendement attendu implique simplement que les récompenses maintenant sont meilleures que les récompenses plus tard. Au sens mathématique, il s'agit de s'assurer que la somme des récompenses converge.
Pour stabiliser la formation, la séquence résultante des rendements est également standardisée (c'est-à-dire pour avoir une moyenne nulle et un écart-type unitaire).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. La perte critique de l'acteur
Puisqu'un modèle hybride acteur-critique est utilisé, la fonction de perte choisie est une combinaison de pertes d'acteur et de critique pour la formation, comme indiqué ci-dessous :
\[L = L_{actor} + L_{critic}\]
Perte d'acteur
La perte d'acteur est basée sur des gradients de politique avec le critique comme ligne de base dépendante de l'état et calculée avec des estimations à échantillon unique (par épisode).
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
où:
- \(T\) : le nombre de pas de temps par épisode, qui peut varier par épisode
- \(s_{t}\): l'état au pas de temps \(t\)
- \(a_{t}\): action choisie au pas de temps \(t\) état donné \(s\)
- \(\pi_{\theta}\): est la politique (acteur) paramétrée par \(\theta\)
- \(V^{\pi}_{\theta}\): est la fonction de valeur (critique) également paramétrée par \(\theta\)
- \(G = G_{t}\): le retour attendu pour un état donné, paire d'actions au pas de temps \(t\)
Un terme négatif est ajouté à la somme puisque l'idée est de maximiser les probabilités d'actions produisant des récompenses plus élevées en minimisant la perte combinée.
Avantage
Le terme \(G - V\) dans notre formulation \(L_{actor}\) est appelé l' avantage , qui indique dans quelle mesure une action est mieux donnée à un état particulier par rapport à une action aléatoire sélectionnée selon la politique \(\pi\) pour cet état.
Bien qu'il soit possible d'exclure une ligne de base, cela peut entraîner une forte variance pendant la formation. Et la bonne chose à propos du choix du critique \(V\) comme ligne de base est qu'il s'est entraîné pour être aussi proche que possible de \(G\), ce qui entraîne une variance plus faible.
De plus, sans la critique, l'algorithme essaierait d'augmenter les probabilités pour les actions entreprises sur un état particulier en fonction du rendement attendu, ce qui peut ne pas faire beaucoup de différence si les probabilités relatives entre les actions restent les mêmes.
Par exemple, supposons que deux actions pour un état donné produisent le même rendement attendu. Sans le critique, l'algorithme essaierait d'augmenter la probabilité de ces actions en fonction de l'objectif \(J\). Avec le critique, il peut s'avérer qu'il n'y a aucun avantage (\(G - V = 0\)) et donc aucun avantage à augmenter les probabilités des actions et l'algorithme mettrait les gradients à zéro.
Perte critique
La formation de \(V\) pour qu'elle soit aussi proche que possible de \(G\) peut être configurée comme un problème de régression avec la fonction de perte suivante :
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
où \(L_{\delta}\) est la perte de Huber , qui est moins sensible aux valeurs aberrantes dans les données que la perte d'erreur au carré.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. Définir l'étape de formation pour mettre à jour les paramètres
Toutes les étapes ci-dessus sont combinées dans une étape de formation exécutée à chaque épisode. Toutes les étapes menant à la fonction de perte sont exécutées avec le contexte tf.GradientTape pour permettre une différenciation automatique.
Ce didacticiel utilise l'optimiseur Adam pour appliquer les dégradés aux paramètres du modèle.
La somme des récompenses non actualisées, episode_reward , est également calculée à cette étape. Cette valeur sera utilisée plus tard pour évaluer si le critère de succès est rempli.
Le contexte tf.function est appliqué à la fonction train_step afin qu'il puisse être compilé dans un graphique TensorFlow appelable, ce qui peut conduire à une accélération 10x de la formation.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. Exécutez la boucle d'entraînement
La formation est exécutée en exécutant l'étape de formation jusqu'à ce que le critère de réussite ou le nombre maximum d'épisodes soit atteint.
Un enregistrement en cours des récompenses d'épisode est conservé dans une file d'attente. Une fois que 100 essais sont atteints, la récompense la plus ancienne est supprimée à l'extrémité gauche (queue) de la file d'attente et la plus récente est ajoutée en tête (à droite). Une somme courante des récompenses est également maintenue pour l'efficacité de calcul.
Selon votre temps d'exécution, l'entraînement peut se terminer en moins d'une minute.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
Visualisation
Après la formation, il serait bon de visualiser comment le modèle se comporte dans l'environnement. Vous pouvez exécuter les cellules ci-dessous pour générer une animation GIF d'un épisode du modèle. Notez que des packages supplémentaires doivent être installés pour OpenAI Gym afin de restituer correctement les images de l'environnement dans Colab.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
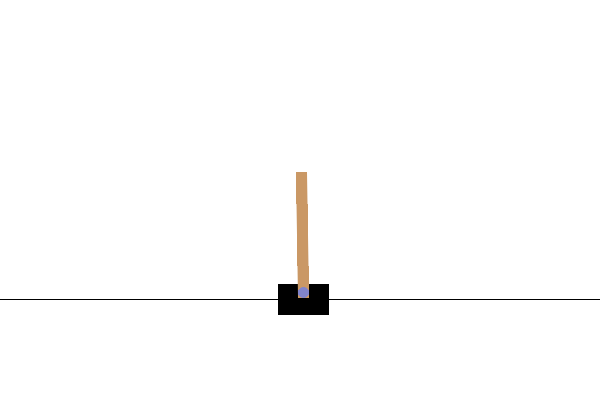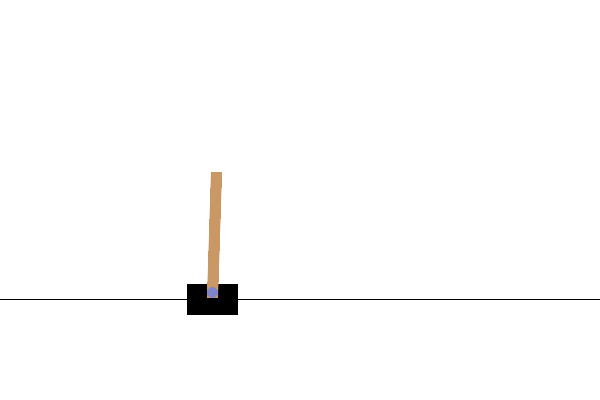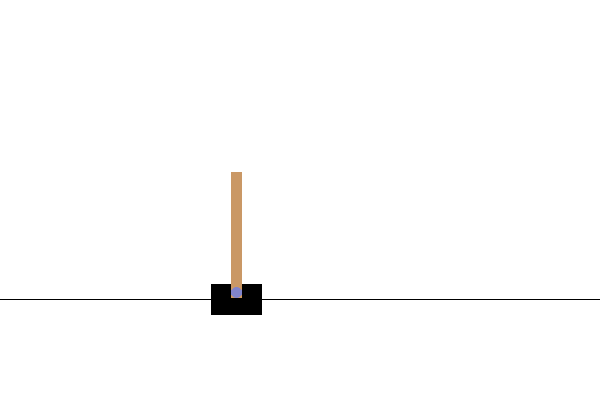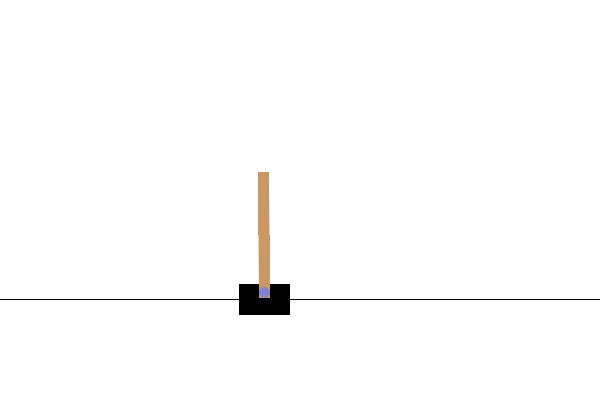
Prochaines étapes
Ce didacticiel a montré comment implémenter la méthode critique d'acteur à l'aide de Tensorflow.
Dans une prochaine étape, vous pouvez essayer de former un modèle sur un environnement différent dans OpenAI Gym.
Pour plus d'informations sur les méthodes critiques d'acteur et le problème Cartpole-v0, vous pouvez consulter les ressources suivantes :
- Méthode de critique d'acteur
- Conférence de critique d'acteur (CAL)
- Problème de contrôle d'apprentissage Cartpole [Barto, et al. 1983]
Pour plus d'exemples d'apprentissage par renforcement dans TensorFlow, vous pouvez consulter les ressources suivantes :