
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทช่วยสอนนี้มีข้อมูลเบื้องต้นเกี่ยวกับการฝังคำ คุณจะฝึกการฝังคำของคุณเองโดยใช้โมเดล Keras แบบง่ายๆ สำหรับงานการจัดประเภทความรู้สึก จากนั้นแสดงภาพใน Embedding Projector (แสดงในภาพด้านล่าง)

แสดงข้อความเป็นตัวเลข
โมเดลการเรียนรู้ของเครื่องใช้เวกเตอร์ (อาร์เรย์ของตัวเลข) เป็นอินพุต เมื่อทำงานกับข้อความ สิ่งแรกที่คุณต้องทำคือคิดกลยุทธ์ในการแปลงสตริงเป็นตัวเลข (หรือเพื่อ "เวกเตอร์" ข้อความ) ก่อนป้อนลงในโมเดล ในส่วนนี้ คุณจะดูกลยุทธ์สามประการในการทำเช่นนั้น
การเข้ารหัสแบบร้อนครั้งเดียว
สำหรับแนวคิดแรก คุณอาจเข้ารหัสแต่ละคำในคำศัพท์ของคุณแบบ "หนึ่งเดียว" พิจารณาประโยคที่ว่า "แมวนั่งบนเสื่อ" คำศัพท์ (หรือคำเฉพาะ) ในประโยคนี้คือ (cat, mat, on, sat, the) ในการแสดงแต่ละคำ คุณจะต้องสร้างเวกเตอร์ศูนย์ที่มีความยาวเท่ากับคำศัพท์ จากนั้นใส่หนึ่งในดัชนีที่สอดคล้องกับคำนั้น แนวทางนี้แสดงในแผนภาพต่อไปนี้
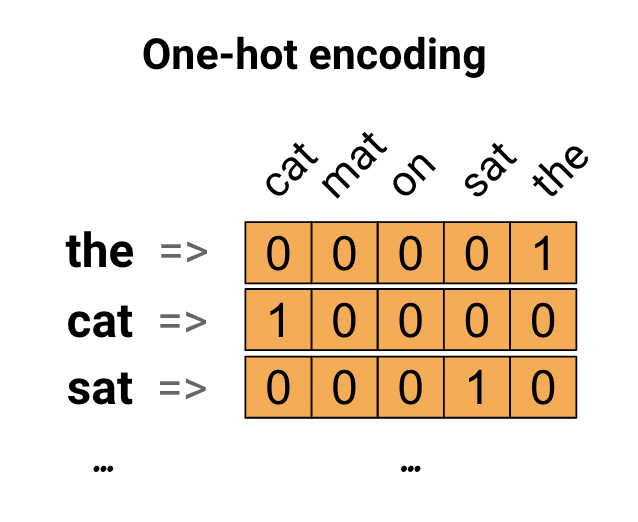
ในการสร้างเวกเตอร์ที่มีการเข้ารหัสของประโยค คุณสามารถต่อเวกเตอร์ยอดนิยมสำหรับแต่ละคำได้
เข้ารหัสแต่ละคำด้วยตัวเลขที่ไม่ซ้ำกัน
วิธีที่สองที่คุณอาจลองคือเข้ารหัสแต่ละคำโดยใช้ตัวเลขที่ไม่ซ้ำกัน จากตัวอย่างข้างต้น คุณสามารถกำหนด 1 ให้กับ "cat", 2 ให้กับ "mat" เป็นต้น จากนั้นคุณสามารถเข้ารหัสประโยค "The cat sat on the mat" เป็นเวกเตอร์หนาแน่นเช่น [5, 1, 4, 3, 5, 2] วิธีนี้มีประสิทธิภาพ แทนที่จะเป็นเวกเตอร์กระจัดกระจาย ตอนนี้คุณมีเวกเตอร์ที่หนาแน่น (โดยที่องค์ประกอบทั้งหมดเต็ม)
อย่างไรก็ตาม มีข้อเสียสองประการสำหรับแนวทางนี้:
การเข้ารหัสจำนวนเต็มเป็นไปตามอำเภอใจ (ไม่จับความสัมพันธ์ใดๆ ระหว่างคำ)
การเข้ารหัสจำนวนเต็มอาจเป็นเรื่องยากสำหรับแบบจำลองในการตีความ ตัวอย่างเช่น ตัวแยกประเภทเชิงเส้น เรียนรู้น้ำหนักตัวเดียวสำหรับแต่ละจุดสนใจ เนื่องจากไม่มีความสัมพันธ์ระหว่างความคล้ายคลึงกันของคำสองคำใดๆ และความคล้ายคลึงกันของการเข้ารหัส การรวมน้ำหนักคุณลักษณะนี้จึงไม่มีความหมาย
การฝังคำ
การฝังคำช่วยให้เราใช้การแสดงที่มีประสิทธิภาพและหนาแน่น ซึ่งคำที่คล้ายกันมีการเข้ารหัสที่คล้ายคลึงกัน ที่สำคัญ คุณไม่จำเป็นต้องระบุการเข้ารหัสนี้ด้วยมือ การฝังเป็นเวกเตอร์หนาแน่นของค่าจุดลอยตัว (ความยาวของเวกเตอร์เป็นพารามิเตอร์ที่คุณระบุ) แทนที่จะระบุค่าสำหรับการฝังด้วยตนเอง ค่าเหล่านี้เป็นพารามิเตอร์ที่ฝึกได้ (น้ำหนักที่โมเดลเรียนรู้ระหว่างการฝึก เช่นเดียวกับที่โมเดลเรียนรู้น้ำหนักสำหรับเลเยอร์ที่หนาแน่น) เป็นเรื่องปกติที่จะเห็นการฝังคำที่มี 8 มิติ (สำหรับชุดข้อมูลขนาดเล็ก) มากถึง 1024 มิติเมื่อทำงานกับชุดข้อมูลขนาดใหญ่ การฝังในมิติที่สูงขึ้นสามารถจับความสัมพันธ์ที่ละเอียดระหว่างคำต่างๆ แต่ต้องใช้ข้อมูลมากขึ้นในการเรียนรู้
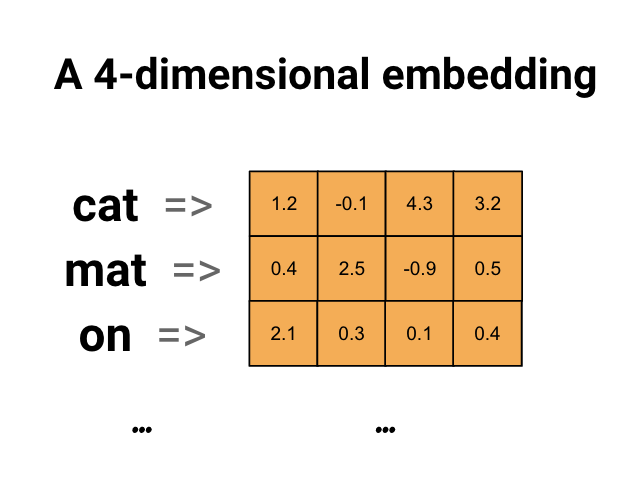
ด้านบนเป็นไดอะแกรมสำหรับการฝังคำ แต่ละคำจะแสดงเป็นเวกเตอร์ 4 มิติของค่าจุดลอยตัว อีกวิธีในการคิดการฝังคือเป็น "ตารางค้นหา" หลังจากเรียนรู้น้ำหนักเหล่านี้แล้ว คุณสามารถเข้ารหัสแต่ละคำได้โดยค้นหาเวกเตอร์หนาแน่นที่ตรงกับในตาราง
ติดตั้ง
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
ดาวน์โหลดชุดข้อมูล IMDb
คุณจะใช้ ชุดข้อมูลบทวิจารณ์ภาพยนตร์ขนาดใหญ่ ผ่านบทช่วยสอน คุณจะฝึกโมเดลตัวแยกประเภทความเชื่อมั่นในชุดข้อมูลนี้ และเรียนรู้การฝังตั้งแต่ต้นจนจบในกระบวนการ หากต้องการอ่านเพิ่มเติมเกี่ยวกับการโหลดชุดข้อมูลตั้งแต่เริ่มต้น โปรดดู บทแนะนำการโหลดข้อความ
ดาวน์โหลดชุดข้อมูลโดยใช้ยูทิลิตี้ไฟล์ Keras และดูไดเรกทอรี
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
ลองดูที่ train/ ไดเรกทอรี มีโฟลเดอร์ pos และ neg พร้อมบทวิจารณ์ภาพยนตร์ที่ระบุว่าเป็นบวกและลบตามลำดับ คุณจะใช้บทวิจารณ์จากโฟลเดอร์ pos และ neg เพื่อฝึกโมเดลการจำแนกประเภทไบนารี
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
ไดเร็กทอรี train ยังมีโฟลเดอร์เพิ่มเติมซึ่งควรลบออกก่อนสร้างชุดข้อมูลการฝึก
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
ถัดไป สร้าง tf.data.Dataset โดยใช้ tf.keras.utils.text_dataset_from_directory คุณสามารถอ่านเพิ่มเติมเกี่ยวกับการใช้ยูทิลิตี้นี้ได้ใน บทแนะนำการจัดหมวดหมู่ข้อความ นี้
ใช้ไดเร็กทอรี train เพื่อสร้างทั้งชุดข้อมูลรถไฟและการตรวจสอบความถูกต้องโดยแบ่งเป็น 20% สำหรับการตรวจสอบ
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
ดูบทวิจารณ์ภาพยนตร์สองสามรายการและป้ายกำกับ (1: positive, 0: negative) จากชุดข้อมูลรถไฟ
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
กำหนดค่าชุดข้อมูลสำหรับประสิทธิภาพ
นี่เป็นวิธีการสำคัญสองวิธีที่คุณควรใช้เมื่อโหลดข้อมูลเพื่อให้แน่ใจว่า I/O จะไม่ถูกบล็อก
.cache() เก็บข้อมูลในหน่วยความจำหลังจากที่โหลดจากดิสก์แล้ว เพื่อให้แน่ใจว่าชุดข้อมูลจะไม่กลายเป็นคอขวดขณะฝึกโมเดลของคุณ หากชุดข้อมูลของคุณใหญ่เกินไปที่จะใส่ลงในหน่วยความจำ คุณสามารถใช้วิธีนี้เพื่อสร้างแคชบนดิสก์ที่มีประสิทธิภาพ ซึ่งอ่านได้มีประสิทธิภาพมากกว่าไฟล์ขนาดเล็กจำนวนมาก
.prefetch() ทับซ้อนการประมวลผลข้อมูลล่วงหน้าและการดำเนินการโมเดลขณะฝึก
คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับทั้งสองวิธี รวมถึงวิธีแคชข้อมูลลงดิสก์ใน คู่มือประสิทธิภาพข้อมูล
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
การใช้เลเยอร์การฝัง
Keras ทำให้ง่ายต่อการใช้การฝังคำ ลองดูที่เลเยอร์ การฝัง
เลเยอร์การฝังสามารถเข้าใจได้ว่าเป็นตารางค้นหาที่แมปจากดัชนีจำนวนเต็ม (ซึ่งย่อมาจากคำเฉพาะ) กับเวกเตอร์ที่หนาแน่น (การฝัง) มิติข้อมูล (หรือความกว้าง) ของการฝังเป็นพารามิเตอร์ที่คุณสามารถทดลองเพื่อดูว่าสิ่งใดใช้ได้ผลดีสำหรับปัญหาของคุณ เช่นเดียวกับที่คุณจะทดลองกับจำนวนเซลล์ประสาทในเลเยอร์หนาแน่น
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
เมื่อคุณสร้างเลเยอร์การฝัง น้ำหนักสำหรับการฝังจะถูกสุ่มเริ่มต้น (เช่นเดียวกับเลเยอร์อื่นๆ) ในระหว่างการฝึก พวกเขาจะค่อยๆ ปรับเปลี่ยนโดยการแพร่กลับ เมื่อได้รับการฝึกอบรมแล้ว การฝังคำที่เรียนรู้จะเข้ารหัสความคล้ายคลึงกันระหว่างคำอย่างคร่าวๆ (ตามที่ได้เรียนรู้สำหรับปัญหาเฉพาะที่แบบจำลองของคุณได้รับการฝึกอบรม)
หากคุณส่งจำนวนเต็มไปยังเลเยอร์การฝัง ผลลัพธ์จะแทนที่จำนวนเต็มแต่ละจำนวนด้วยเวกเตอร์จากตารางการฝัง:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
สำหรับปัญหาข้อความหรือลำดับ เลเยอร์การฝังจะใช้เทนเซอร์ 2 มิติของจำนวนเต็ม ของรูปร่าง (samples, sequence_length) โดยที่แต่ละรายการคือลำดับของจำนวนเต็ม สามารถฝังลำดับความยาวผันแปรได้ คุณสามารถป้อนลงในเลเยอร์การฝังด้านบนชุดงานที่มีรูปร่าง (32, 10) (ชุดที่มี 32 ลำดับของความยาว 10) หรือ (64, 15) (ชุดที่มี 64 ชุดที่มีความยาว 15)
เทนเซอร์ที่ส่งคืนมีแกนมากกว่าอินพุตหนึ่งแกน เวกเตอร์การฝังจะจัดแนวตามแกนสุดท้ายใหม่ ส่งชุดอินพุต (2, 3) และเอาต์พุตคือ (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
เมื่อได้รับชุดของลำดับเป็นอินพุต เลเยอร์การฝังจะส่งกลับเทนเซอร์จุดลอยตัว 3 มิติ ของรูปร่าง (samples, sequence_length, embedding_dimensionality) ในการแปลงจากลำดับความยาวผันแปรไปเป็นการแทนค่าคงที่ มีแนวทางมาตรฐานที่หลากหลาย คุณสามารถใช้ RNN, Attention หรือการรวมเลเยอร์ก่อนที่จะส่งต่อไปยังเลเยอร์ Dense บทช่วยสอนนี้ใช้การรวมเนื่องจากเป็นวิธีที่ง่ายที่สุด การ จัดประเภทข้อความด้วยบทช่วยสอน RNN เป็นขั้นตอนต่อไปที่ดี
การประมวลผลข้อความล่วงหน้า
ถัดไป กำหนดขั้นตอนการประมวลผลล่วงหน้าของชุดข้อมูลที่จำเป็นสำหรับแบบจำลองการจัดประเภทความคิดเห็นของคุณ เริ่มต้นเลเยอร์ TextVectorization ด้วยพารามิเตอร์ที่ต้องการเพื่อทำให้บทวิจารณ์ภาพยนตร์เป็นแบบเวกเตอร์ คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับการใช้เลเยอร์นี้ในบทช่วยสอน การจัดประเภทข้อความ
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
สร้างแบบจำลองการจัดประเภท
ใช้ Keras Sequential API เพื่อกำหนดรูปแบบการจัดประเภทความคิดเห็น ในกรณีนี้คือรูปแบบสไตล์ "ถุงคำต่อเนื่อง"
- เลเยอร์
TextVectorizationแปลงสตริงเป็นดัชนีคำศัพท์ คุณได้เริ่มต้นvectorize_layerเป็นเลเยอร์ TextVectorization และสร้างคำศัพท์โดยเรียกtext_dsบนadaptตอนนี้ vectorize_layer สามารถใช้เป็นเลเยอร์แรกของโมเดลการจัดประเภทแบบ end-to-end ของคุณได้ โดยป้อนสตริงที่แปลงแล้วลงในเลเยอร์การฝัง เลเยอร์
Embeddingจะใช้คำศัพท์ที่เข้ารหัสเป็นจำนวนเต็มและค้นหาเวกเตอร์การฝังสำหรับดัชนีคำแต่ละคำ เวกเตอร์เหล่านี้เรียนรู้เหมือนรถไฟจำลอง เวกเตอร์เพิ่มมิติให้กับอาร์เรย์เอาต์พุต มิติผลลัพธ์คือ:(batch, sequence, embedding)เลเยอร์
GlobalAveragePooling1Dส่งคืนเวกเตอร์เอาต์พุตที่มีความยาวคงที่สำหรับแต่ละตัวอย่างโดยการหาค่าเฉลี่ยบนมิติลำดับ ซึ่งช่วยให้โมเดลสามารถจัดการกับอินพุตของความยาวผันแปรได้ด้วยวิธีที่ง่ายที่สุดเวกเตอร์เอาต์พุตความยาวคงที่ถูกวางท่อผ่านเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ (
Dense) โดยมีหน่วยที่ซ่อนอยู่ 16 หน่วยเลเยอร์สุดท้ายเชื่อมต่ออย่างหนาแน่นด้วยโหนดเอาต์พุตเดียว
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
รวบรวมและฝึกโมเดล
คุณจะใช้ TensorBoard เพื่อแสดงภาพเมตริกรวมถึงการสูญเสียและความแม่นยำ สร้าง tf.keras.callbacks.TensorBoard
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
รวบรวมและฝึกโมเดลโดยใช้เครื่องมือเพิ่มประสิทธิภาพ Adam และการสูญเสีย BinaryCrossentropy
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
ด้วยวิธีการนี้ โมเดลจะมีความแม่นยำในการตรวจสอบประมาณ 78% (โปรดทราบว่าโมเดลมีความเหมาะสมมากเกินไป เนื่องจากความแม่นยำในการฝึกสูงขึ้น)
คุณสามารถดูสรุปแบบจำลองเพื่อเรียนรู้เพิ่มเติมเกี่ยวกับแต่ละเลเยอร์ของแบบจำลองได้
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
เห็นภาพเมทริกโมเดลใน TensorBoard
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
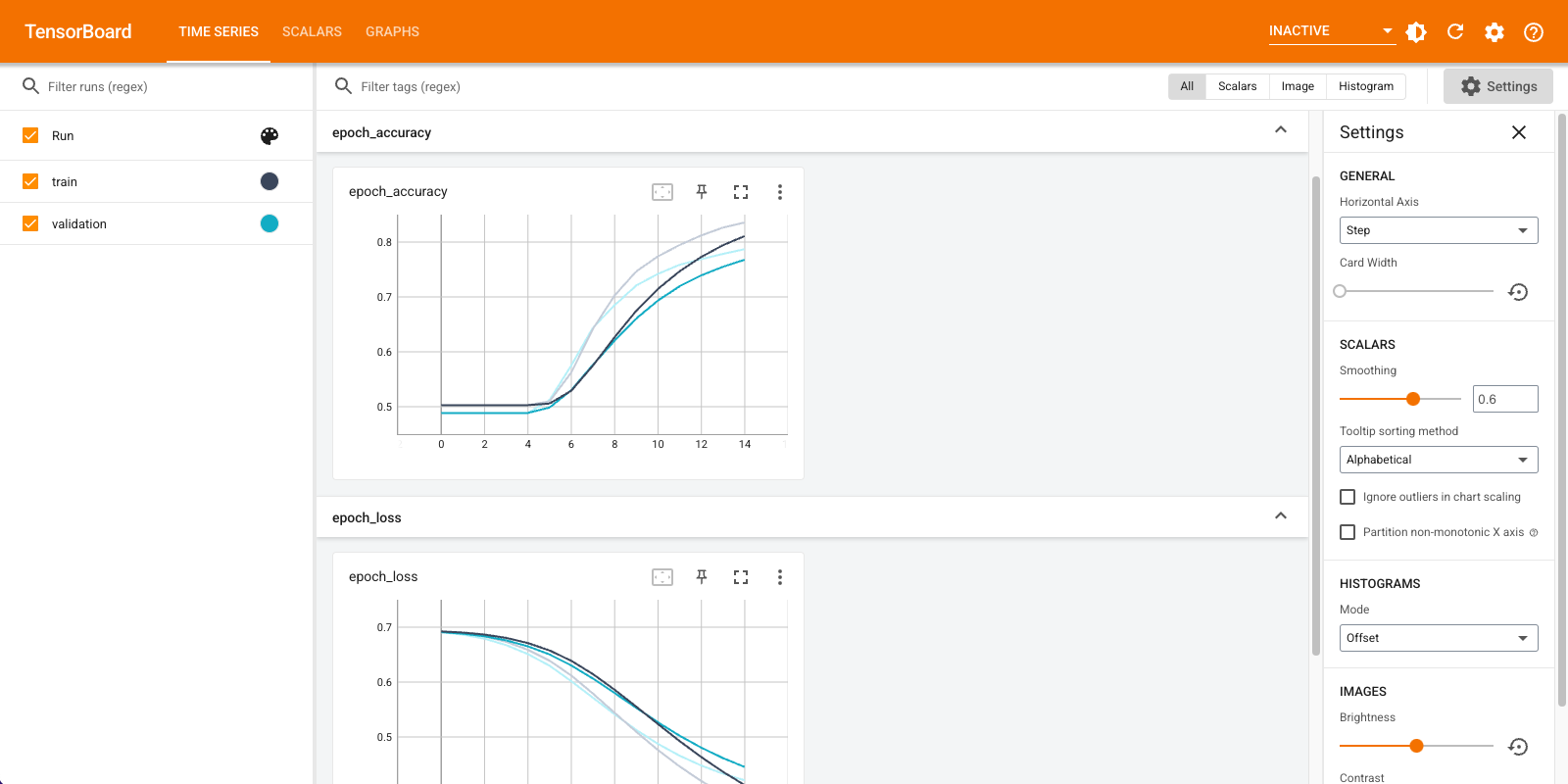
ดึงการฝังคำที่ผ่านการฝึกอบรมและบันทึกลงในดิสก์
ถัดไป เรียกค้นคำว่า embeddings ที่เรียนรู้ระหว่างการฝึก การฝังเป็นน้ำหนักของเลเยอร์การฝังในโมเดล เมทริกซ์น้ำหนักมีรูปร่าง (vocab_size, embedding_dimension)
รับน้ำหนักจากโมเดลโดยใช้ get_layer() และ get_weights() get_vocabulary() จัดเตรียมคำศัพท์เพื่อสร้างไฟล์ข้อมูลเมตาด้วยหนึ่งโทเค็นต่อบรรทัด
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
เขียนน้ำหนักลงดิสก์ ในการใช้ Embedding Projector คุณจะต้องอัปโหลดไฟล์สองไฟล์ในรูปแบบแท็บที่แยกจากกัน: ไฟล์เวกเตอร์ (ที่มีการฝัง) และไฟล์ข้อมูลเมตา (ประกอบด้วยคำ)
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
หากคุณกำลังใช้งานบทช่วยสอนนี้ใน Colaboratory คุณสามารถใช้ตัวอย่างต่อไปนี้เพื่อดาวน์โหลดไฟล์เหล่านี้ไปยังเครื่องท้องถิ่นของคุณ (หรือใช้เบราว์เซอร์ไฟล์ View -> Table of contents -> File browser )
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
เห็นภาพการฝัง
หากต้องการเห็นภาพการฝัง ให้อัปโหลดไปยังโปรเจ็กเตอร์ฝัง
เปิด Embedding Projector (สามารถเรียกใช้ในอินสแตนซ์ TensorBoard ในพื้นที่ได้)
คลิกที่ "โหลดข้อมูล"
อัปโหลดสองไฟล์ที่คุณสร้างไว้ด้านบน:
vecs.tsvและmeta.tsv
การฝังที่คุณฝึกฝนจะปรากฏขึ้น คุณสามารถค้นหาคำเพื่อค้นหาเพื่อนบ้านที่ใกล้ที่สุด เช่น ลองค้นหาคำว่า "สวย" คุณอาจเห็นเพื่อนบ้านชอบ "วิเศษ"
ขั้นตอนถัดไป
บทช่วยสอนนี้แสดงวิธีฝึกและแสดงภาพการฝังคำตั้งแต่เริ่มต้นในชุดข้อมูลขนาดเล็ก
หากต้องการฝึกการฝังคำโดยใช้อัลกอริทึม Word2Vec ให้ลองใช้บทช่วยสอน Word2Vec
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการประมวลผลข้อความขั้นสูง โปรดอ่าน โมเดล Transformer เพื่อการทำความเข้าใจภาษา