
حق چاپ 2020 نویسندگان TF-Agents.
شروع کنید
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
برپایی
اگر وابستگی های زیر را نصب نکرده اید، اجرا کنید:
pip install tf-agents
واردات
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
معرفی
مسئله راهزن چند مسلح (MAB) یک مورد خاص از یادگیری تقویتی است: یک عامل با انجام برخی اقدامات پس از مشاهده برخی از وضعیت های محیط، پاداش ها را در یک محیط جمع آوری می کند. تفاوت اصلی بین RL عمومی و MAB این است که در MAB، ما فرض می کنیم که عمل انجام شده توسط عامل بر وضعیت بعدی محیط تأثیر نمی گذارد. بنابراین، عوامل انتقال حالت، پاداش اعتباری به اقدامات گذشته، یا "برنامه ریزی از پیش" برای رسیدن به حالت های غنی از پاداش را مدل نمی کنند.
همانطور که در حوزه های دیگر RL، هدف از یک عامل MAB است برای پیدا کردن یک سیاست است که جمع آوری به عنوان پاداش آنجا که ممکن است. با این حال، این اشتباه است که همیشه سعی کنیم از عملی که بالاترین پاداش را می دهد سوء استفاده کنیم، زیرا در این صورت این شانس وجود دارد که اگر به اندازه کافی کاوش نکنیم، اقدامات بهتری را از دست بدهیم. این مشکل اصلی در (MAB) حل شود، اغلب به نام معضل اکتشاف بهره برداری.
محیط های راهزن، سیاست ها و عوامل برای MAB را می توان در زیرشاخه یافت tf_agents / راهزنان .
محیط ها
در TF-نمایندگی، طبقه محیط زیست نقش دادن اطلاعات در وضعیت فعلی در خدمت (این نام مشاهده یا زمینه)، دریافت یک عمل به عنوان ورودی، انجام انتقال دولت، و خروجی پاداش. این کلاس همچنین از تنظیم مجدد زمانی که یک قسمت به پایان می رسد مراقبت می کند تا یک قسمت جدید شروع شود. این است که با فراخوانی یک متوجه reset تابع زمانی که یک دولت به عنوان "آخرین" از قسمت برچسب.
برای جزئیات بیشتر، نگاه کنید به آموزش TF-نمایندگی محیط .
همانطور که در بالا ذکر شد، MAB با RL عمومی تفاوت دارد زیرا اقدامات بر مشاهدات بعدی تأثیر نمی گذارد. تفاوت دیگر این است که در Bandits، هیچ "اپیزود" وجود ندارد: هر مرحله زمانی، مستقل از مراحل زمانی قبلی، با یک مشاهده جدید شروع می شود.
برای اینکه مطمئن شوید مشاهدات مستقل و به دور انتزاعی مفهوم قسمت RL هستند، مشتق شده از معرفی می کنیم PyEnvironment و TFEnvironment : BanditPyEnvironment و BanditTFEnvironment . این کلاسها دو تابع عضو خصوصی را نشان میدهند که باید توسط کاربر پیادهسازی شوند:
@abc.abstractmethod
def _observe(self):
و
@abc.abstractmethod
def _apply_action(self, action):
_observe تابع یک مشاهده می گرداند. سپس، خط مشی اقدامی را بر اساس این مشاهده انتخاب می کند. _apply_action دریافت که اقدام به عنوان یک ورودی، و پاداش مربوط می گرداند. این توابع عضو خصوصی توسط توابع به نام reset و step بود.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
بالا ابزار کلاس انتزاعی موقت PyEnvironment را _reset و _step توابع و در معرض توابع انتزاعی _observe و _apply_action به زیر کلاس اجرا می شود.
یک نمونه ساده کلاس محیطی
کلاس زیر یک محیط بسیار ساده را ارائه می دهد که مشاهده یک عدد صحیح تصادفی بین 2- و 2 است، 3 عمل ممکن است (0، 1، 2) و پاداش حاصلضرب عمل و مشاهده است.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
اکنون می توانیم از این محیط برای دریافت مشاهدات و دریافت پاداش برای اعمال خود استفاده کنیم.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
محیط های TF
در واقع می توان یک محیط راهزن توسط subclassing تعریف BanditTFEnvironment به محیط RL، و یا، به طور مشابه، می توان یک تعریف BanditPyEnvironment و قرار دادن آن با TFPyEnvironment . برای سادگی، در این آموزش به سراغ گزینه دوم می رویم.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
سیاست های
سیاست در یک مشکل راهزن کار به همان شیوه به عنوان یک مشکل RL: آن را فراهم عمل (و یا یک توزیع از اعمال)، با توجه به مشاهدات به عنوان ورودی می باشد.
برای جزئیات بیشتر، نگاه کنید به آموزش TF-نمایندگی سیاست .
همانطور که با محیط، دو راه برای ساخت یک سیاست وجود دارد: در واقع می توان ایجاد PyPolicy و قرار دادن آن با TFPyPolicy ، یا به طور مستقیم یک ایجاد TFPolicy . در اینجا ما انتخاب می کنیم که با روش مستقیم برویم.
از آنجایی که این مثال بسیار ساده است، می توانیم خط مشی بهینه را به صورت دستی تعریف کنیم. عمل فقط به علامت مشاهده بستگی دارد، 0 زمانی که منفی است و 2 زمانی که مثبت است.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
اکنون میتوانیم یک مشاهده از محیط درخواست کنیم، سیاست را برای انتخاب یک اقدام فراخوانی کنیم، سپس محیط پاداش را بهدست میآورد:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
نحوه پیاده سازی محیط های راهزن تضمین می کند که هر بار که قدمی برمی داریم، نه تنها پاداش عملی را که انجام داده ایم، بلکه مشاهده بعدی را نیز دریافت می کنیم.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
عوامل
اکنون که محیطهای راهزن و سیاستهای راهزن داریم، زمان آن فرا رسیده است که عوامل راهزن را نیز تعریف کنیم، که بر اساس نمونههای آموزشی تغییر خطمشی را انجام دهند.
API برای عوامل راهزن کند که از عوامل RL متفاوت است: عامل فقط نیاز به پیاده سازی _initialize و _train روش ها، و تعریف یک policy و یک collect_policy .
یک محیط پیچیده تر
قبل از اینکه مامور راهزن خود را بنویسیم، باید محیطی داشته باشیم که تشخیص آن کمی سخت تر باشد. به ادویه تا چیز فقط یک کمی، محیط زیست بعدی هم همیشه خواهد داد reward = observation * action و یا reward = -observation * action . این زمانی تصمیم گیری می شود که محیط اولیه شود.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
سیاست پیچیده تر
یک محیط پیچیده تر نیاز به سیاست پیچیده تری دارد. ما به سیاستی نیاز داریم که رفتار محیط زیربنایی را تشخیص دهد. سه موقعیت وجود دارد که سیاست باید به آنها رسیدگی کند:
- عامل هنوز متوجه نشده است که کدام نسخه از محیط در حال اجرا است.
- عامل تشخیص داد که نسخه اصلی محیط در حال اجرا است.
- عامل تشخیص داد که نسخه برگردانده شده محیط در حال اجرا است.
تعریف می کنیم tf_variable نام _situation برای ذخیره این اطلاعات کد گذاری شده به عنوان مقدار در [0, 2] ، و سپس رفتار سیاست درآمده است.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
عامل
اکنون زمان آن است که عاملی را تعریف کنیم که نشانه محیط را تشخیص می دهد و خط مشی را به درستی تنظیم می کند.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
در کد بالا، عامل سیاست تعریف می کند، و متغیر situation توسط عامل و سیاست به اشتراک گذاشته.
همچنین، پارامتر experience از _train تابع است و این مسیر:
مسیرها
در TF-نمایندگی ها، trajectories هستند تاپل که حاوی نمونه از مراحل قبلی گرفته شده نام برد. سپس این نمونه ها توسط نماینده برای آموزش و به روز رسانی خط مشی استفاده می شود. در RL، مسیرها باید حاوی اطلاعاتی در مورد وضعیت فعلی، وضعیت بعدی و اینکه آیا قسمت فعلی به پایان رسیده است یا خیر. از آنجایی که در دنیای Bandit ما به این چیزها نیاز نداریم، یک تابع کمکی برای ایجاد یک مسیر راه اندازی می کنیم:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
آموزش یک نماینده
اکنون تمام قطعات برای آموزش عامل راهزن ما آماده است.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
از خروجی می توان دریافت که پس از مرحله دوم (مگر اینکه مشاهده در مرحله اول 0 باشد)، خط مشی اقدام را به روش صحیح انتخاب می کند و بنابراین پاداش جمع آوری شده همیشه غیر منفی است.
یک نمونه راهزن متنی واقعی
در بقیه این آموزش، ما با استفاده از از قبل اجرا محیط و عوامل از کتابخانه TF-نمایندگی راهزنان.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
محیط تصادفی ثابت با توابع پرداخت خطی
محیط های مورد استفاده در این مثال است StationaryStochasticPyEnvironment . این محیط یک تابع (معمولاً پر سر و صدا) را برای دادن مشاهدات (زمینه) به عنوان پارامتر می گیرد، و برای هر بازوی یک تابع (همچنین پر سر و صدا) می گیرد که پاداش را بر اساس مشاهدات داده شده محاسبه می کند. در مثال ما، بافت را به طور یکنواخت از یک مکعب d-بعدی نمونه برداری می کنیم، و توابع پاداش، توابع خطی زمینه، به اضافه مقداری نویز گاوسی هستند.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
نماینده LinUCB
عامل زیر را پیاده سازی LinUCB الگوریتم.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
پشیمانی متریک
مهم ترین متریک راهزنان، تاسف است، محاسبه به عنوان تفاوت بین پاداش جمع آوری شده توسط عامل و پاداش مورد انتظار از یک سیاست اوراکل که دسترسی به توابع پاداش از محیط زیست است. RegretMetric بنابراین نیاز به یک تابع baseline_reward_fn که محاسبه بهترین پاداش مورد انتظار دست یافتنی با توجه به مشاهدات. برای مثال، ما باید حداکثر معادلهای بدون نویز توابع پاداش را که قبلاً برای محیط تعریف کردهایم، بگیریم.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
آموزش
اکنون تمام اجزایی را که در بالا معرفی کردیم را کنار هم می گذاریم: محیط زیست، سیاست و عامل. ما اجرای سیاست در محیط زیست و آموزش خروجی داده ها با کمک یک راننده، و آموزش عامل در داده ها.
توجه داشته باشید که دو پارامتر وجود دارد که با هم تعداد مراحل انجام شده را مشخص می کنند. num_iterations مشخص چند بار ما اجرا حلقه مربی، در حالی که راننده را steps_per_loop مراحل در هر تکرار. دلیل اصلی حفظ هر دوی این پارامترها این است که برخی از عملیات در هر تکرار انجام می شود، در حالی که برخی توسط راننده در هر مرحله انجام می شود. به عنوان مثال، عامل train تابع تنها یک بار در هر تکرار نامیده می شود. مبادله در اینجا این است که اگر بیشتر تمرین کنیم، سیاست ما «تازهتر» است، از سوی دیگر، آموزش در دستههای بزرگتر ممکن است زمان کارآمدتری داشته باشد.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
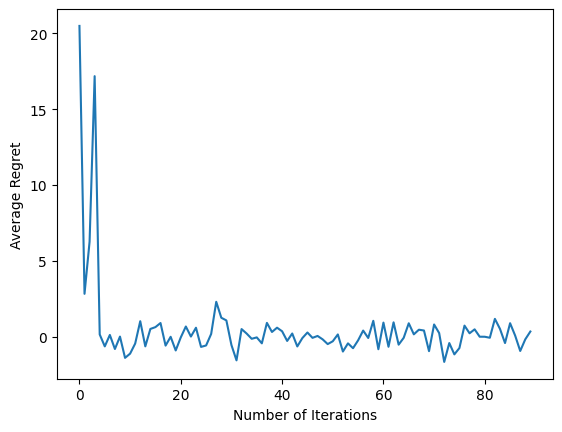
پس از اجرای آخرین قطعه کد، نمودار حاصل (امیدواریم) نشان میدهد که با آموزش نماینده، میانگین پشیمانی کاهش مییابد و با توجه به مشاهده، خطمشی بهتر میشود تا بفهمد عمل درست چیست.
بعد چه می شود؟
برای دیدن نمونه های بیشتر به کار، لطفا ببینید راهزنان / عوامل / نمونه دایرکتوری است که نمونه های آماده برای اجرا برای عوامل و محیط های مختلف.
کتابخانه TF-Agents همچنین قادر به مدیریت راهزنان چند مسلح با ویژگی های هر بازو است. برای این منظور، ما خواننده را به هر بازوی راهزن مراجعه آموزش .