
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub |
ה-API של tf.data מאפשר לך לבנות צינורות קלט מורכבים מחלקים פשוטים הניתנים לשימוש חוזר. לדוגמה, הצינור של מודל תמונה עשוי לצבור נתונים מקבצים במערכת קבצים מבוזרת, להחיל הפרעות אקראיות על כל תמונה ולמזג תמונות שנבחרו באקראי לקבוצה לצורך אימון. הצינור של מודל טקסט עשוי לכלול חילוץ סמלים מנתוני טקסט גולמיים, המרתם להטמעת מזהים עם טבלת חיפוש, ושילוב רצפים באורכים שונים. ה-API של tf.data מאפשר לטפל בכמויות גדולות של נתונים, לקרוא מפורמטים שונים של נתונים ולבצע טרנספורמציות מורכבות.
ה-API של tf.data מציג הפשטה של tf.data.Dataset המייצגת רצף של אלמנטים, שבהם כל אלמנט מורכב ממרכיב אחד או יותר. לדוגמה, בצינור תמונה, אלמנט עשוי להיות דוגמה לאימון יחיד, עם זוג רכיבי טנסור המייצגים את התמונה והתווית שלה.
ישנן שתי דרכים שונות ליצור מערך נתונים:
מקור נתונים בונה
Datasetנתונים מנתונים המאוחסנים בזיכרון או בקובץ אחד או יותר.טרנספורמציה של נתונים בונה מערך נתונים מאובייקט
tf.data.Datasetאחד או יותר.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
מכניקה בסיסית
כדי ליצור צינור קלט, עליך להתחיל עם מקור נתונים . לדוגמה, כדי לבנות Dataset נתונים מנתונים בזיכרון, אתה יכול להשתמש ב- tf.data.Dataset.from_tensors() או tf.data.Dataset.from_tensor_slices() . לחלופין, אם נתוני הקלט שלך מאוחסנים בקובץ בפורמט TFRecord המומלץ, תוכל להשתמש ב- tf.data.TFRecordDataset() .
ברגע שיש לך אובייקט Dataset , אתה יכול להפוך אותו Dataset חדש על ידי שרשור קריאות לשיטת ה- tf.data.Dataset . לדוגמה, אתה יכול להחיל טרנספורמציות לכל אלמנט כגון Dataset.map() , ושינויים מרובי אלמנטים כגון Dataset.batch() . עיין בתיעוד עבור tf.data.Dataset לרשימה מלאה של טרנספורמציות.
Dataset ערכת הנתונים הוא פייתון שניתן לחזור עליו. זה מאפשר לצרוך את האלמנטים שלו באמצעות לולאת for:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
או על ידי יצירה מפורשת של איטרטור Python באמצעות iter וצריכת האלמנטים שלו באמצעות next :
it = iter(dataset)
print(next(it).numpy())
8
לחלופין, ניתן לצרוך רכיבי מערך נתונים באמצעות ה- reduce transformation, אשר מפחית את כל הרכיבים כדי לייצר תוצאה אחת. הדוגמה הבאה ממחישה כיצד להשתמש בטרנספורמציה reduce כדי לחשב את הסכום של מערך נתונים של מספרים שלמים.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
מבנה מערך הנתונים
מערך נתונים מייצר רצף של אלמנטים , כאשר כל אלמנט הוא אותו מבנה (מקונן) של רכיבים . רכיבים בודדים של המבנה יכולים להיות מכל סוג שניתן לייצוג על ידי tf.TypeSpec , כולל tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray או tf.data.Dataset .
מבני Python שניתן להשתמש בהם כדי לבטא את המבנה (המקונן) של אלמנטים כוללים tuple , dict , NamedTuple ו- OrderedDict . בפרט, list אינה מבנה חוקי לביטוי המבנה של רכיבי מערך נתונים. הסיבה לכך היא שמשתמשי tf.data מוקדמים הרגישו מאוד לגבי כניסות list (למשל שהועברו ל- tf.data.Dataset.from_tensors ) שנארזו אוטומטית כטנסורים ויציאות list (למשל, ערכי החזרה של פונקציות מוגדרות על ידי משתמש) נאלצות לכדי tuple . כתוצאה מכך, אם תרצה שקלט list יטופל כמבנה, עליך להמיר אותו ל- tuple ואם תרצה שפלט list יהיה רכיב בודד, עליך לארוז אותו במפורש באמצעות tf.stack .
המאפיין Dataset.element_spec מאפשר לך לבדוק את הסוג של כל רכיב רכיב. המאפיין מחזיר מבנה מקונן של אובייקטי tf.TypeSpec , התואם למבנה האלמנט, שעשוי להיות רכיב בודד, תוספת של רכיבים או טופלה מקוננת של רכיבים. לדוגמה:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Dataset של ערכות הנתונים תומכות במערכי נתונים מכל מבנה. בעת שימוש Dataset.map() ו- Dataset.filter() , המחילות פונקציה על כל אלמנט, מבנה האלמנט קובע את הארגומנטים של הפונקציה:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
קריאת נתוני קלט
צורכת מערכי NumPy
ראה טעינת מערכי NumPy לדוגמאות נוספות.
אם כל נתוני הקלט שלך מתאימים לזיכרון, הדרך הפשוטה ביותר ליצור מהם ערכת Dataset היא להמיר אותם לאובייקטי tf.Tensor ולהשתמש ב- Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
צורכת מחוללי Python
מקור נתונים נפוץ נוסף שניתן להטמיע בקלות כ- tf.data.Dataset הוא מחולל הפיתון.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
Dataset.from_generator ממיר את מחולל הפיתון ל- tf.data.Dataset מתפקד במלואו.
הקונסטרוקטור לוקח קריאת טלפון כקלט, לא איטרטור. זה מאפשר לו להפעיל מחדש את הגנרטור כאשר הוא מגיע לסוף. זה דורש ארגומנט args אופציונלי, אשר מועבר כארגומנטים של הניתן להתקשרות.
הארגומנט output_types נדרש מכיוון tf.data בונה tf.Graph באופן פנימי, וקצוות גרפים דורשים tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
הארגומנט output_shapes אינו נדרש אך מומלץ מאוד מכיוון שפעולות TensorFlow רבות אינן תומכות בטנסורים עם דירוג לא ידוע. אם האורך של ציר מסוים אינו ידוע או משתנה, הגדר אותו כ- None ב- output_shapes .
חשוב גם לציין שה- output_shapes ו- output_types לפי אותם כללי קינון כמו שיטות מערך נתונים אחרות.
הנה מחולל לדוגמה שמדגים את שני ההיבטים, הוא מחזיר tuples של מערכים, כאשר המערך השני הוא וקטור עם אורך לא ידוע.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
הפלט הראשון הוא int32 והשני הוא float32 .
הפריט הראשון הוא סקלר, צורה () , והשני הוא וקטור באורך לא ידוע, צורה (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
כעת ניתן להשתמש בו כמו tf.data.Dataset רגיל. שים לב שבעת אצווה של מערך נתונים עם צורה משתנה, עליך להשתמש ב- Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
לקבלת דוגמה מציאותית יותר, נסה לעטוף את preprocessing.image.ImageDataGenerator כ- tf.data.Dataset .
ראשית הורידו את הנתונים:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
צור את התמונה. image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
צריכת נתוני TFRecord
ראה טעינת TFRecords לקבלת דוגמה מקצה לקצה.
ה-API של tf.data תומך במגוון פורמטים של קבצים כך שתוכל לעבד מערכי נתונים גדולים שאינם מתאימים לזיכרון. לדוגמה, פורמט הקובץ TFRecord הוא פורמט בינארי פשוט מכוון רשומות שבו יישומי TensorFlow רבים משתמשים לנתוני אימון. המחלקה tf.data.TFRecordDataset מאפשרת לך להזרים את התוכן של קובץ TFRecord אחד או יותר כחלק מצינור קלט.
להלן דוגמה באמצעות קובץ הבדיקה של שלטי שמות הרחוב הצרפתיים (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
הארגומנט של filenames לאתחול TFRecordDataset יכול להיות מחרוזת, רשימה של מחרוזות או tf.Tensor של מחרוזות. לכן אם יש לך שתי קבוצות של קבצים למטרות הדרכה ואימות, אתה יכול ליצור שיטת יצרן שמייצרת את מערך הנתונים, תוך שימוש בשמות קבצים כארגומנט קלט:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
פרויקטים רבים של TensorFlow משתמשים ברשומות tf.train.Example ברצף בקבצי TFRecord שלהם. יש לפענח אותם לפני שניתן לבדוק אותם:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
צריכת נתוני טקסט
ראה טעינת טקסט לדוגמא מקצה לקצה.
מערכי נתונים רבים מופצים כקובץ טקסט אחד או יותר. ה- tf.data.TextLineDataset מספק דרך קלה לחלץ שורות מקובץ טקסט אחד או יותר. בהינתן שם קובץ אחד או יותר, TextLineDataset ייצור אלמנט אחד בעל ערך מחרוזת לכל שורה של קבצים אלה.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
להלן השורות הראשונות של הקובץ הראשון:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
כדי להחליף שורות בין קבצים השתמש ב- Dataset.interleave . זה מקל על ערבוב קבצים יחד. להלן השורה הראשונה, השנייה והשלישית מכל תרגום:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
כברירת מחדל, TextLineDataset מניב כל שורה של כל קובץ, מה שאולי לא רצוי, למשל, אם הקובץ מתחיל בשורת כותרת, או מכיל הערות. ניתן להסיר שורות אלו באמצעות ההמרה של Dataset.skip() או Dataset.filter() . כאן, אתה מדלג על השורה הראשונה, ואז מסנן כדי למצוא רק ניצולים.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
צורכת נתוני CSV
ראה טעינת קבצי CSV וטעינת Pandas DataFrames לקבלת דוגמאות נוספות.
פורמט קובץ CSV הוא פורמט פופולרי לאחסון נתונים טבלאיים בטקסט רגיל.
לדוגמה:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
אם הנתונים שלך מתאימים לזיכרון, אותה שיטת Dataset.from_tensor_slices עובדת על מילונים, ומאפשרת לייבא נתונים אלה בקלות:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
גישה מדרגית יותר היא לטעון מהדיסק לפי הצורך.
מודול tf.data מספק שיטות לחילוץ רשומות מקובץ CSV אחד או יותר התואמים ל- RFC 4180 .
הפונקציה experimental.make_csv_dataset היא הממשק ברמה גבוהה לקריאת קבוצות של קבצי csv. הוא תומך בהסקת סוג עמודות ובתכונות רבות אחרות, כמו אצווה וערבוב, כדי להפוך את השימוש לפשוט.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
אתה יכול להשתמש בארגומנט select_columns אם אתה צריך רק תת-קבוצה של עמודות.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
יש גם מחלקה experimental.CsvDataset ברמה נמוכה יותר המספקת בקרה עדינה יותר. זה לא תומך בהסקת סוג עמודה. במקום זאת עליך לציין את הסוג של כל עמודה.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
אם כמה עמודות ריקות, ממשק ברמה נמוכה זה מאפשר לך לספק ערכי ברירת מחדל במקום סוגי עמודות.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
כברירת מחדל, CsvDataset מניב כל עמודה של כל שורה בקובץ, מה שאולי לא רצוי, למשל אם הקובץ מתחיל בשורת כותרת שיש להתעלם ממנה, או אם חלק מהעמודות אינן נדרשות בקלט. ניתן להסיר את השורות והשדות הללו באמצעות הארגומנטים header ו- select_cols בהתאמה.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
צורכת סטים של קבצים
ישנם מערכי נתונים רבים המופצים כסט של קבצים, כאשר כל קובץ הוא דוגמה.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
ספריית השורש מכילה ספרייה עבור כל מחלקה:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
הקבצים בכל ספריית מחלקה הם דוגמאות:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
קרא את הנתונים באמצעות הפונקציה tf.io.read_file וחלץ את התווית מהנתיב, והחזרת זוגות (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
שילוב רכיבי מערך נתונים
אצווה פשוטה
הצורה הפשוטה ביותר של אצווה עורמת n רכיבים עוקבים של מערך נתונים לרכיב בודד. הטרנספורמציה של Dataset.batch() עושה בדיוק את זה, עם אותם אילוצים כמו tf.stack() , המוחל על כל רכיב של האלמנטים: כלומר עבור כל רכיב i , כל האלמנטים חייבים להיות בעלי טנסור באותה צורה בדיוק.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
בעוד tf.data מנסה להפיץ מידע על צורה, הגדרות ברירת המחדל של Dataset.batch גורמות לגודל אצווה לא ידוע מכיוון שהאצווה האחרונה עשויה לא להיות מלאה. שימו לב ל- None s בצורה:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
השתמש בארגומנט drop_remainder כדי להתעלם מאותה אצווה אחרונה, ולקבל התפשטות צורה מלאה:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
אצווה טנסורים עם ריפוד
המתכון שלמעלה עובד עבור טנסורים שכולם בעלי אותו גודל. עם זאת, מודלים רבים (למשל דגמי רצף) עובדים עם נתוני קלט שיכולים להיות בגודל משתנה (למשל רצפים באורכים שונים). כדי לטפל במקרה זה, הטרנספורמציה של Dataset.padded_batch מאפשרת לך לבצע אצווה של טנסורים בעלי צורה שונה על ידי ציון מימד אחד או יותר שבהם הם עשויים להיות מרופדים.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
הטרנספורמציה של Dataset.padded_batch מאפשרת לך להגדיר ריפוד שונה עבור כל מימד של כל רכיב, והוא עשוי להיות באורך משתנה (מסומן ב- None בדוגמה למעלה) או באורך קבוע. אפשר גם לעקוף את ערך הריפוד, שברירת המחדל הוא 0.
תהליכי עבודה בהדרכה
עיבוד תקופות מרובות
ה-API של tf.data מציע שתי דרכים עיקריות לעיבוד תקופות מרובות של אותם נתונים.
הדרך הפשוטה ביותר לחזור על מערך נתונים בתקופות מרובות היא להשתמש בטרנספורמציה של Dataset.repeat() . ראשית, צור מערך נתונים של נתונים טיטאניים:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
החלת Dataset.repeat() ללא ארגומנטים תחזור על הקלט ללא הגבלת זמן.
הטרנספורמציה של Dataset.repeat משרשרת את הטיעונים שלו מבלי לאותת על סיום עידן אחד ותחילת העידן הבא. מסיבה זו, Dataset.batch שהוחל לאחר Dataset.repeat יניב קבוצות אשר חוצות את גבולות העידן:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
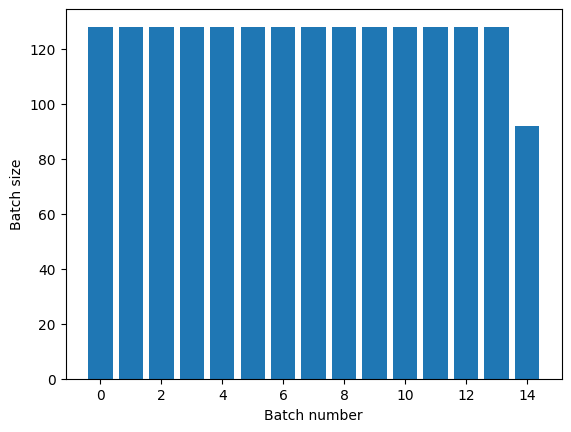
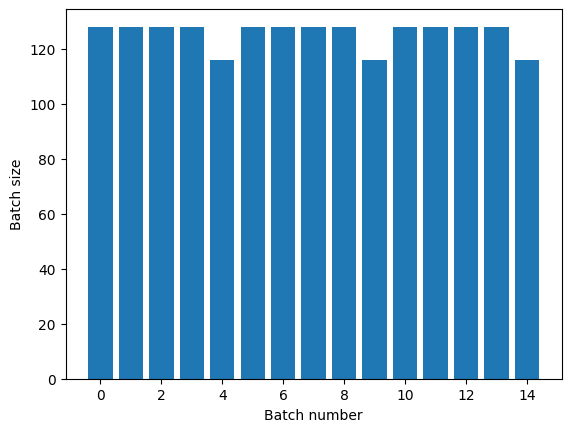
אם אתה צריך הפרדת עידן ברורה, שים את Dataset.batch לפני החזרה:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
אם תרצה לבצע חישוב מותאם אישית (למשל כדי לאסוף נתונים סטטיסטיים) בסוף כל תקופה, הכי פשוט להפעיל מחדש את איטרציית הנתונים בכל תקופה:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
ערבוב אקראי של נתוני קלט
הטרנספורמציה של Dataset.shuffle() שומרת על מאגר בגודל קבוע ובוחרת את הרכיב הבא באופן אחיד באקראי מאותו מאגר.
הוסף אינדקס למערך הנתונים כדי שתוכל לראות את האפקט:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
מכיוון שה- buffer_size הוא 100, וגודל האצווה הוא 20, האצווה הראשונה לא מכילה אלמנטים עם אינדקס מעל 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
כמו עם Dataset.batch , הסדר ביחס ל- Dataset.repeat משנה.
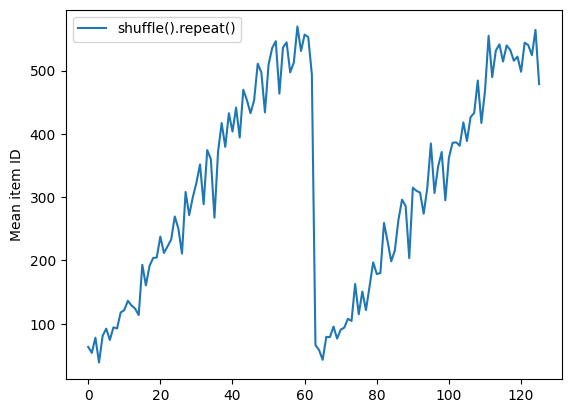
Dataset.shuffle לא מסמן את סופה של תקופה עד שמאגר ה-shuffle ריק. אז ערבוב הממוקם לפני חזרה יציג כל רכיב של תקופה אחת לפני שתעבור לתקופה הבאה:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
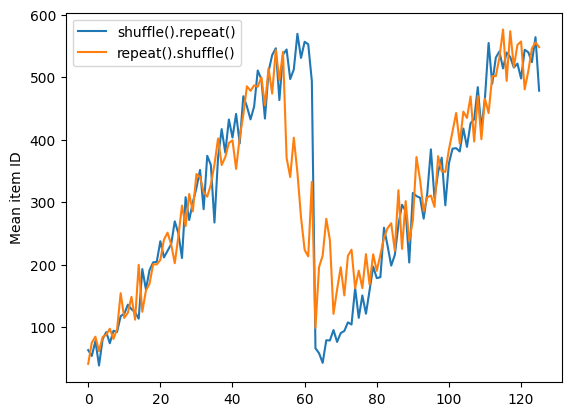
אבל חזרה לפני ערבוב מערבבת את גבולות העידן יחד:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
עיבוד מוקדם של נתונים
הטרנספורמציה של Dataset.map(f) מייצרת מערך נתונים חדש על ידי החלת פונקציה נתונה f על כל רכיב במערך הקלט. היא מבוססת על הפונקציה map() המיושמת בדרך כלל על רשימות (ומבנים אחרים) בשפות תכנות פונקציונליות. הפונקציה f לוקחת את אובייקטי tf.Tensor המייצגים אלמנט בודד בקלט, ומחזירה את אובייקטי tf.Tensor שייצגו אלמנט בודד במערך הנתונים החדש. היישום שלו משתמש בפעולות TensorFlow סטנדרטיות כדי להפוך אלמנט אחד למשנהו.
סעיף זה מכסה דוגמאות נפוצות לשימוש ב- Dataset.map() .
פענוח נתוני תמונה ושינוי גודלם
בעת אימון רשת עצבית על נתוני תמונה מהעולם האמיתי, לעתים קרובות יש צורך להמיר תמונות בגדלים שונים לגודל נפוץ, כך שניתן יהיה לצרף אותן לגודל קבוע.
בנה מחדש את מערך הנתונים של שמות קבצי הפרחים:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
כתוב פונקציה שמבצעת מניפולציות על רכיבי הנתונים.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
תבדוק שזה עובד.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

מפה אותו על מערך הנתונים.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


יישום לוגיקה שרירותית של Python
מטעמי ביצועים, השתמש בפעולות TensorFlow לעיבוד מקדים של הנתונים שלך במידת האפשר. עם זאת, לפעמים שימושי לקרוא לספריות Python חיצוניות בעת ניתוח נתוני הקלט שלך. אתה יכול להשתמש tf.py_function() Dataset.map() .
לדוגמה, אם אתה רוצה להחיל סיבוב אקראי, למודול tf.image יש רק tf.image.rot90 , שהוא לא מאוד שימושי להגדלת תמונה.
כדי להדגים את tf.py_function , נסה להשתמש בפונקציה scipy.ndimage.rotate במקום זאת:
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

כדי להשתמש בפונקציה זו עם Dataset.map חלות אותן אזהרות כמו עם Dataset.from_generator , עליך לתאר את צורות ההחזרה והסוגים בעת החלת הפונקציה:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


ניתוח tf.Example הודעות חוצץ של פרוטוקול לדוגמה
צינורות קלט רבים מחלצים הודעות מאגר פרוטוקול tf.train.Example מפורמט TFRecord. כל רשומת tf.train.Example מכילה "פיצ'רים" אחת או יותר, וצינור הקלט ממיר בדרך כלל תכונות אלה לטנזורים.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
אתה יכול לעבוד עם tf.train.Example מחוץ ל- tf.data.Dataset כדי להבין את הנתונים:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
חלונות של סדרות זמן
לדוגמא של סדרת זמן מקצה לקצה, ראה: חיזוי סדרות זמן .
נתוני סדרות זמן מאורגנים לעתים קרובות עם ציר הזמן שלם.
השתמש ב- Dataset.range פשוט כדי להדגים:
range_ds = tf.data.Dataset.range(100000)
בדרך כלל, מודלים המבוססים על סוג זה של נתונים ירצו פרוסת זמן רציפה.
הגישה הפשוטה ביותר תהיה אצווה של הנתונים:
באמצעות batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
לחלופין, כדי ליצור תחזיות צפופות צעד אחד לתוך העתיד, תוכל לשנות את התכונות והתוויות בצעד אחד ביחס זה לזה:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
כדי לחזות חלון שלם במקום היסט קבוע, ניתן לפצל את הקבוצות לשני חלקים:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
כדי לאפשר חפיפה מסוימת בין התכונות של אצווה אחת לתוויות של אצווה אחרת, השתמש ב- Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
שימוש window
בזמן השימוש ב- Dataset.batch עובד, ישנם מצבים שבהם ייתכן שתזדקק לשליטה עדינה יותר. שיטת Dataset.window מעניקה לך שליטה מלאה, אך דורשת טיפול מסוים: היא מחזירה ערכת Dataset של Datasets . ראה מבנה מערך הנתונים לפרטים.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
שיטת Dataset.flat_map יכולה לקחת מערך נתונים של מערכי נתונים ולשטח אותו למערך נתונים בודד:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
כמעט בכל המקרים, תחילה תרצה לבצע .batch את מערך הנתונים:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
כעת, אתה יכול לראות שהארגומנט shift שולט בכמה כל חלון עובר.
אם תחבר את זה, תוכל לכתוב את הפונקציה הזו:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
אז קל לחלץ תוויות, כמו קודם:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
דגימה מחדש
כאשר עובדים עם מערך נתונים שהוא מאוד לא מאוזן בכיתה, ייתכן שתרצה לדגום מחדש את מערך הנתונים. tf.data מספק שתי שיטות לעשות זאת. מערך ההונאות בכרטיסי אשראי הוא דוגמה טובה לבעיה מסוג זה.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
עכשיו, בדוק את התפלגות השיעורים, היא מוטה מאוד:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
גישה נפוצה לאימון עם מערך נתונים לא מאוזן היא לאזן אותו. tf.data כולל מספר שיטות המאפשרות זרימת עבודה זו:
דגימת מערכי נתונים
גישה אחת לדגימה מחדש של מערך נתונים היא להשתמש ב- sample_from_datasets . זה ישים יותר כאשר יש לך data.Dataset עבור כל מחלקה.
כאן, פשוט השתמש במסנן כדי ליצור אותם מנתוני הונאה בכרטיס האשראי:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
כדי להשתמש ב- tf.data.Dataset.sample_from_datasets , העבר את מערכי הנתונים והמשקל עבור כל אחד מהם:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
כעת מערך הנתונים מייצר דוגמאות של כל מחלקה עם הסתברות של 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
דגימה מחדש של דחייה
בעיה אחת בגישת Dataset.sample_from_datasets לעיל היא שהיא זקוקה ל- tf.data.Dataset נפרד לכל מחלקה. אתה יכול להשתמש ב- Dataset.filter כדי ליצור את שני מערכי הנתונים האלה, אבל זה גורם לכך שכל הנתונים נטענים פעמיים.
ניתן להחיל את שיטת data.Dataset.rejection_resample על מערך נתונים כדי לאזן אותו מחדש, תוך טעינתו פעם אחת בלבד. אלמנטים יוסרו ממערך הנתונים כדי להשיג איזון.
data.Dataset.rejection_resample לוקח ארגומנט class_func . class_func זה מוחל על כל רכיב מערך נתונים, ומשמש כדי לקבוע לאיזו מחלקה דוגמה שייכת למטרות איזון.
המטרה כאן היא לאזן את התפלגות התווית, והרכיבים של creditcard_ds הם כבר זוגות (features, label) . אז ה- class_func רק צריך להחזיר את התוויות האלה:
def class_func(features, label):
return label
שיטת הדגימה מחדש עוסקת בדוגמאות בודדות, כך שבמקרה זה עליך unbatch את מערך הנתונים לפני החלת שיטה זו.
השיטה צריכה התפלגות מטרה, ואופציונלית אומדן התפלגות ראשוני בתור תשומות.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
שיטת rejection_resample מחזירה (class, example) זוגות כאשר class היא הפלט של ה- class_func . במקרה זה, example כבר הייתה זוג (feature, label) , אז השתמש map כדי לשחרר את העותק הנוסף של התוויות:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
כעת מערך הנתונים מייצר דוגמאות של כל מחלקה עם הסתברות של 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
איטרטור מחסום
Tensorflow תומך בנטילת מחסומים כך שכאשר תהליך האימון שלך מתחיל מחדש, הוא יכול לשחזר את המחסום העדכני ביותר כדי לשחזר את רוב ההתקדמות שלו. בנוסף לבדיקת משתני המודל, אתה יכול גם לבדוק את ההתקדמות של איטרטור הנתונים. זה יכול להיות שימושי אם יש לך מערך נתונים גדול ואינך רוצה להפעיל את מערך הנתונים מההתחלה בכל הפעלה מחדש. עם זאת, שים לב שנקודות הבידוק האיטרטור עשויות להיות גדולות, שכן טרנספורמציות כגון shuffle prefetch דורשות רכיבי חציצה בתוך האיטרטור.
כדי לכלול את האיטרטור שלך במחסום, העבר את tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
שימוש ב-tf.data עם tf.keras
ה-API של tf.keras מפשט היבטים רבים של יצירה וביצוע של מודלים של למידת מכונה. ממשקי ה-API של .fit() ו-. .evaluate() ו-. .predict() תומכים במערך נתונים כקלט. להלן מערך נתונים מהיר והגדרת מודל:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
העברת מערך נתונים של זוגות (feature, label) היא כל מה שנדרש עבור Model.fit ו- Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
אם אתה מעביר מערך נתונים אינסופי, למשל על ידי קריאה Dataset.repeat() , אתה רק צריך להעביר גם את הארגומנט steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
להערכה ניתן לעבור את מספר שלבי ההערכה:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
עבור מערכי נתונים ארוכים, הגדר את מספר השלבים להערכה:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
התוויות אינן נדרשות בעת קריאת Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
אבל מתעלמים מהתוויות אם אתה מעביר מערך נתונים המכיל אותן:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)