
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub |
מדריך זה מספק דוגמאות לשימוש בנתוני CSV עם TensorFlow.
ישנם שני חלקים עיקריים לכך:
- טעינת הנתונים מהדיסק
- עיבוד מראש לצורה המתאימה לאימון.
מדריך זה מתמקד בטעינה ונותן כמה דוגמאות מהירות של עיבוד מקדים. למדריך המתמקד בהיבט העיבוד המקדים, עיין במדריך ובמדריך שכבות העיבוד המקדים .
להכין
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
בנתוני זיכרון
עבור כל מערך נתונים קטן של CSV, הדרך הפשוטה ביותר לאמן עליו מודל TensorFlow היא לטעון אותו לזיכרון כ-Pandaframe או כמערך NumPy.
דוגמה פשוטה יחסית היא מערך הנתונים של abalone .
- מערך הנתונים קטן.
- כל תכונות הקלט הן כולן ערכי נקודה צפה בטווח מוגבל.
הנה איך להוריד את הנתונים ל- Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
מערך הנתונים מכיל סט מדידות של אבלון , סוג של חלזון ים.

"שריון אבלון" (מאת ניקי דוגן פוג , CC BY-SA 2.0)
המשימה הנומינלית עבור מערך נתונים זה היא לחזות את הגיל משאר המדידות, לכן הפרידו את התכונות והתוויות לאימון:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
עבור מערך נתונים זה תתייחס לכל התכונות באופן זהה. ארוז את התכונות במערך NumPy יחיד.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
לאחר מכן בצע מודל רגרסיה לחזות את הגיל. מכיוון שיש רק טנזור קלט בודד, מספיק כאן מודל keras.Sequential .
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
כדי לאמן את הדגם הזה, העבר את התכונות והתוויות אל Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
זה עתה ראית את הדרך הבסיסית ביותר לאמן מודל באמצעות נתוני CSV. לאחר מכן, תלמד כיצד להחיל עיבוד מקדים כדי לנרמל עמודות מספריות.
עיבוד מקדים בסיסי
זה תרגול טוב לנרמל את התשומות למודל שלך. שכבות העיבוד המקדים של Keras מספקות דרך נוחה לבנות את הנורמליזציה הזו לתוך המודל שלך.
השכבה תחשב מראש את הממוצע והשונות של כל עמודה ותשתמש באלה כדי לנרמל את הנתונים.
ראשית אתה יוצר את השכבה:
normalize = layers.Normalization()
לאחר מכן אתה משתמש בשיטת Normalization.adapt() כדי להתאים את שכבת הנורמליזציה לנתונים שלך.
normalize.adapt(abalone_features)
לאחר מכן השתמש בשכבת הנורמליזציה במודל שלך:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
סוגי נתונים מעורבים
מערך הנתונים של "טיטאניק" מכיל מידע על הנוסעים בטיטאניק. המשימה הנומינלית במערך הנתונים הזה היא לחזות מי שרד.

תמונה מויקימדיה
{kind=link}
ניתן לטעון את הנתונים הגולמיים בקלות כ-Pandas DataFrame , אך אינם ניתנים לשימוש מיידי כקלט למודל TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
בגלל סוגי הנתונים והטווחים השונים, אתה לא יכול פשוט לערום את התכונות לתוך מערך NumPy ולהעביר אותו למודל keras.Sequential . יש לטפל בכל עמודה בנפרד.
כאפשרות אחת, תוכל לעבד מראש את הנתונים שלך במצב לא מקוון (באמצעות כל כלי שתרצה) כדי להמיר עמודות קטגוריות לעמודות מספריות, ואז להעביר את הפלט המעובד למודל TensorFlow שלך. החיסרון בגישה זו הוא שאם אתה שומר וייצא את המודל שלך, העיבוד המקדים לא נשמר איתו. שכבות העיבוד המקדים של Keras נמנעות מבעיה זו מכיוון שהן חלק מהמודל.
בדוגמה זו, תבנה מודל שמיישם את הלוגיקה של העיבוד המקדים באמצעות ה-API הפונקציונלי של Keras . אתה יכול גם לעשות את זה על ידי סיווג משנה .
ה-API הפונקציונלי פועל על טנסורים "סמליים". לטנזורים "להוטים" רגילים יש ערך. לעומת זאת הטנזורים ה"סמליים" הללו לא. במקום זאת הם עוקבים אחר הפעולות המופעלות עליהם, ובונים ייצוג של החישוב, שתוכל להפעיל מאוחר יותר. הנה דוגמה מהירה:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
כדי לבנות את מודל העיבוד המקדים, התחל בבניית קבוצה של אובייקטים סמליים של keras.Input , התואמים את השמות וסוגי הנתונים של עמודות ה-CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
השלב הראשון בלוגיקת העיבוד המקדים שלך הוא לשרור את הכניסות המספריות יחד, ולהריץ אותן דרך שכבת נורמליזציה:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
אסוף את כל תוצאות העיבוד המקדים הסמליות, כדי לשרשר אותן מאוחר יותר.
preprocessed_inputs = [all_numeric_inputs]
עבור קלט המחרוזת השתמש בפונקציה tf.keras.layers.StringLookup כדי למפות ממחרוזות למדדים שלמים באוצר מילים. לאחר מכן, השתמש ב- tf.keras.layers.CategoryEncoding כדי להמיר את האינדקסים לנתוני float32 המתאימים למודל.
הגדרות ברירת המחדל עבור שכבת tf.keras.layers.CategoryEncoding יוצרות וקטור חם אחד עבור כל קלט. שכבות. layers.Embedding תעבוד גם. עיין במדריך שכבות העיבוד המקדים ובמדריך למידע נוסף בנושא זה.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
עם אוסף inputs processed_inputs , אתה יכול לשרשר את כל התשומות המעובדות יחד, ולבנות מודל שמטפל בעיבוד המקדים:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
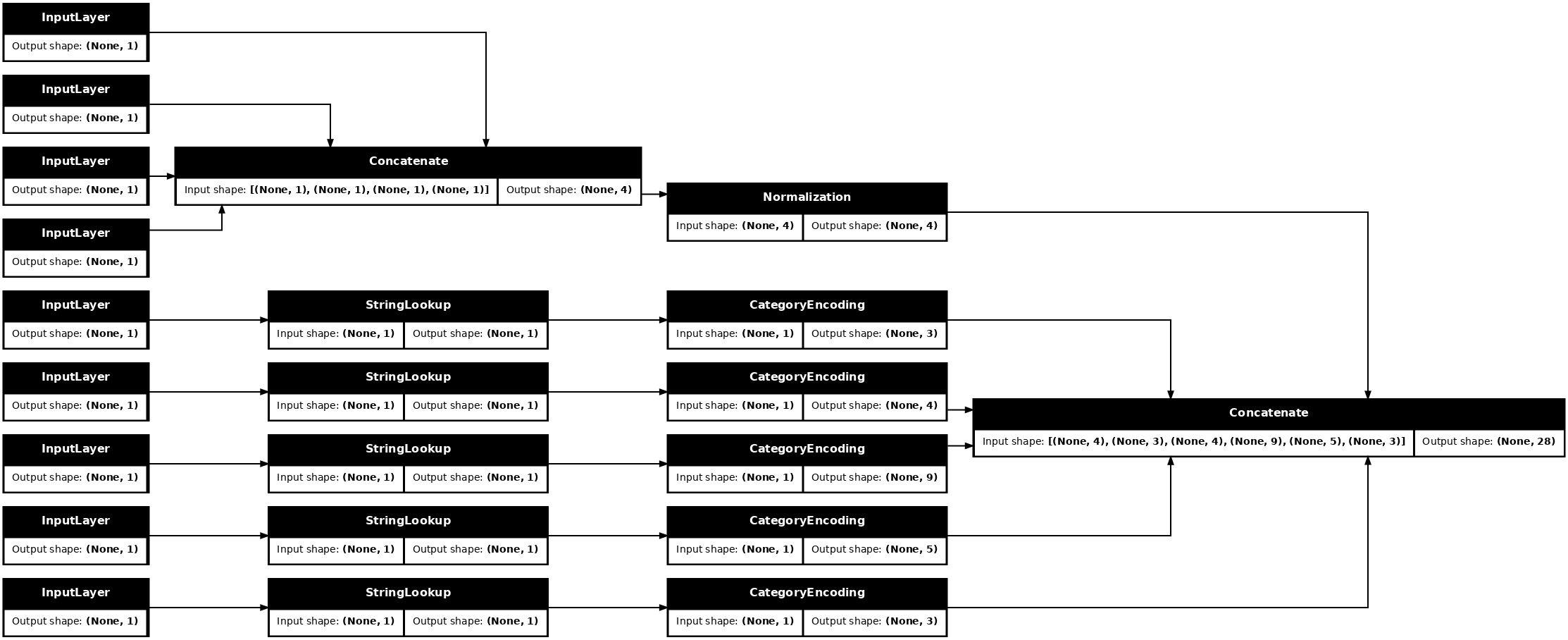
model זה רק מכיל את העיבוד המקדים של הקלט. אתה יכול להפעיל אותו כדי לראות מה זה עושה לנתונים שלך. דגמי Keras אינם ממירים אוטומטית את Pandas DataFrames כי לא ברור אם יש להמיר אותם לטנזור אחד או למילון טנזורים. אז המר את זה למילון טנסורים:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
חתך את דוגמה האימון הראשונה והעביר אותה למודל העיבוד המקדים הזה, אתה רואה את התכונות המספריות ואת המחרוזת החמה אחת משולבים כולם יחד:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
עכשיו בנה את המודל על זה:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
כאשר אתה מאמן את המודל, העבר את מילון התכונות כ- x , ואת התווית כ- y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
מכיוון שהעיבוד המקדים הוא חלק מהמודל, אתה יכול לשמור את המודל ולטעון אותו מחדש במקום אחר ולקבל תוצאות זהות:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
שימוש ב-tf.data
בסעיף הקודם הסתמכתם על ערבוב הנתונים המובנים של הדגם ואצווה בזמן אימון הדגם.
אם אתה צריך יותר שליטה על צינור נתוני הקלט או צריך להשתמש בנתונים שלא מתאימים בקלות לזיכרון: השתמש ב- tf.data .
לדוגמאות נוספות עיין במדריך tf.data .
פועל בנתוני הזיכרון
כדוגמה ראשונה להחלת tf.data על נתוני CSV שקול את הקוד הבא כדי לחתוך באופן ידני את מילון התכונות מהסעיף הקודם. עבור כל אינדקס, זה לוקח את האינדקס הזה עבור כל תכונה:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
הפעל את זה והדפיס את הדוגמה הראשונה:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
ה- tf.data.Dataset הבסיסי ביותר בטעינת הנתונים בזיכרון הוא Dataset.from_tensor_slices . זה מחזיר tf.data.Dataset שמיישם גרסה כללית של פונקציית slices לעיל, ב-TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
אתה יכול לבצע איטרציה על tf.data.Dataset כמו כל פיתון אחר שניתן לחזור עליו:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
הפונקציה from_tensor_slices יכולה להתמודד עם כל מבנה של מילונים או tuples מקוננים. הקוד הבא יוצר מערך נתונים של (features_dict, labels) זוגות:
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
כדי להכשיר מודל באמצעות ערכת Dataset זו, תצטרך לפחות shuffle batch את הנתונים.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
במקום להעביר features labels ל- Model.fit , אתה מעביר את מערך הנתונים:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
מקובץ בודד
עד כה מדריך זה עבד עם נתונים בזיכרון. tf.data הוא ערכת כלים ניתנת להרחבה לבניית צינורות נתונים, ומספקת מספר פונקציות לטיפול בטעינת קבצי CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
כעת קרא את נתוני ה-CSV מהקובץ וצור tf.data.Dataset .
(לתיעוד המלא, ראה tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
פונקציה זו כוללת תכונות נוחות רבות כך שקל לעבוד איתם את הנתונים. זה כולל:
- שימוש בכותרות העמודות כמפתחות מילון.
- קביעה אוטומטית של סוג כל עמודה.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
זה גם יכול לדחוס את הנתונים תוך כדי תנועה. להלן קובץ CSV ב-gzip המכיל את מערך התעבורה הבין-מדינתי של המטרו

תמונה מויקימדיה
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
הגדר את הארגומנט compression_type לקרוא ישירות מהקובץ הדחוס:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
שמירה במטמון
יש תקורה מסוימת לניתוח נתוני ה-CSV. עבור דגמים קטנים זה יכול להיות צוואר הבקבוק באימון.
בהתאם למקרה השימוש שלך, ייתכן שיהיה רעיון טוב להשתמש ב- Dataset.cache או ב- data.experimental.snapshot כך שנתוני ה-CSV ינותחו רק בתקופה הראשונה.
ההבדל העיקרי בין שיטות cache ל- snapshot הוא שניתן להשתמש בקבצי cache רק בתהליך TensorFlow שיצר אותם, אך ניתן לקרוא קבצי snapshot על ידי תהליכים אחרים.
לדוגמה, איטרציה על traffic_volume_csv_gz_ds 20 פעמים, לוקחת ~15 שניות ללא שמירה במטמון, או ~2 שניות עם שמירה במטמון.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
אם טעינת הנתונים שלך מואטת על ידי טעינת קובצי csv, cache snapshot המצב אינם מספיקים למקרה השימוש שלך, שקול לקידוד מחדש את הנתונים שלך לפורמט יעיל יותר.
מספר קבצים
כל הדוגמאות עד כה בחלק זה יכולות להיעשות בקלות ללא tf.data . מקום אחד שבו tf.data באמת יכול לפשט דברים הוא כאשר עוסקים באוספים של קבצים.
לדוגמה, מערך התמונות של גופן התווים מופץ כאוסף של קבצי csv, אחד לכל גופן.

תמונה מאת וילי היידלבך מפיקסביי
הורד את מערך הנתונים והסתכל על הקבצים בפנים:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
כשאתה מתמודד עם חבורה של קבצים אתה יכול להעביר file_pattern בסגנון גלוב לפונקציה experimental.make_csv_dataset . סדר הקבצים נערבב בכל איטרציה.
השתמש בארגומנט num_parallel_reads כדי להגדיר כמה קבצים נקראים במקביל ומשולבים יחד.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
לקבצי CSV אלה יש את התמונות משטחות לשורה אחת. שמות העמודות מעוצבים r{row}c{column} . הנה האצווה הראשונה:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
אופציונלי: שדות אריזה
אתה כנראה לא רוצה לעבוד עם כל פיקסל בעמודות נפרדות כמו זה. לפני שתנסה להשתמש במערך הנתונים הזה, הקפד לארוז את הפיקסלים לתוך טנסור תמונה.
הנה קוד שמנתח את שמות העמודות כדי לבנות תמונות לכל דוגמה:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
החל את הפונקציה הזו על כל אצווה במערך הנתונים:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
תכנן את התמונות שהתקבלו:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

פונקציות ברמה נמוכה יותר
עד כה הדרכה זו התמקדה בכלי השירות ברמה הגבוהה ביותר לקריאת נתוני CSV. ישנם שני ממשקי API נוספים שעשויים להועיל למשתמשים מתקדמים אם מקרה השימוש שלך אינו מתאים לתבניות הבסיסיות.
-
tf.io.decode_csv- פונקציה לניתוח שורות טקסט לתוך רשימה של טנסור עמודות CSV. -
tf.data.experimental.CsvDataset- בונה מערך csv ברמה נמוכה יותר.
סעיף זה יוצר מחדש את הפונקציונליות שסופקה על ידי make_csv_dataset , כדי להדגים כיצד ניתן להשתמש בפונקציונליות ברמה נמוכה יותר.
tf.io.decode_csv
פונקציה זו מפענחת מחרוזת, או רשימה של מחרוזות לרשימה של עמודות.
שלא כמו make_csv_dataset פונקציה זו לא מנסה לנחש סוגי נתונים של עמודות. אתה מציין את סוגי העמודות על ידי מתן רשימה של record_defaults המכילה ערך מהסוג הנכון, עבור כל עמודה.
כדי לקרוא את נתוני הטיטאניק כמחרוזות באמצעות decode_csv היית אומר:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
כדי לנתח אותם עם הסוגים האמיתיים שלהם, צור רשימה של record_defaults מהסוגים המתאימים:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
המחלקה tf.data.experimental.CsvDataset מספקת ממשק מינימלי של ערכת Dataset של CSV ללא תכונות הנוחות של פונקציית make_csv_dataset : ניתוח כותרות עמודות, הסקת סוג עמודות, ערבוב אוטומטי, שזירת קבצים.
הקונסטרוקטור הבא משתמש ב- record_defaults באותו אופן כמו io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
הקוד שלמעלה שווה ערך ל:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
מספר קבצים
כדי לנתח את מערך הנתונים של הגופנים באמצעות experimental.CsvDataset , תחילה עליך לקבוע את סוגי העמודות עבור record_defaults . התחל על ידי בדיקת השורה הראשונה של קובץ אחד:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
רק שני השדות הראשונים הם מחרוזות, השאר הם ints או floats, ואתה יכול לקבל את המספר הכולל של תכונות על ידי ספירת הפסים:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
CsvDatasaet יכול לקחת רשימה של קבצי קלט, אבל קורא אותם ברצף. הקובץ הראשון ברשימת קובצי ה-CSV הוא AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
אז כאשר אתה מעביר את רשימת הקבצים ל- CsvDataaset , הרשומות מ- AGENCY.csv נקראות תחילה:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
כדי לשלב מספר קבצים, השתמש ב- Dataset.interleave .
להלן מערך נתונים ראשוני המכיל את שמות קבצי ה-CSV:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
זה מערבב את שמות הקבצים בכל תקופה:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
שיטת map_func interleave ילד- Dataset עבור כל רכיב של האב- Dataset .
כאן, אתה רוצה ליצור CsvDataset מכל רכיב במערך הנתונים של הקבצים:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
ערכת הנתונים Dataset על ידי השזירה מחזירה אלמנטים על ידי מעבר על מספר מערכי הנתונים של Dataset . שים לב, להלן, כיצד מערך הנתונים עובר במחזוריות של שלושה קובצי גופנים cycle_length=3 :
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
ביצועים
מוקדם יותר, צוין ש- io.decode_csv יעיל יותר כאשר הוא פועל על אצווה של מחרוזות.
אפשר לנצל עובדה זו, כאשר משתמשים בגדלים גדולים של אצווה, כדי לשפר את ביצועי טעינת ה-CSV (אך נסה קודם לשמור במטמון ).
עם מטעין 20 המובנה, 2048 אצוות לדוגמה לוקחות בערך 17 שניות.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
העברת קבוצות של שורות טקסט ל- decode_csv פועלת מהר יותר, תוך כ-5 שניות:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
לדוגמא נוספת להגברת ביצועי ה-CSV על-ידי שימוש באצווה גדולה, ראה את המדריך ל-overfit ו-underfit .
גישה מסוג זה עשויה לעבוד, אך שקול אפשרויות אחרות כמו cache snapshot , או קידוד מחדש של הנתונים שלך לפורמט יעיל יותר.