
Panduan ini menunjukkan cara menggunakan alat yang tersedia dengan TensorFlow Profiler untuk melacak performa model TensorFlow Anda. Anda akan mempelajari cara memahami performa model Anda pada host (CPU), perangkat (GPU), atau pada kombinasi host dan perangkat.
Pembuatan profil membantu memahami konsumsi sumber daya perangkat keras (waktu dan memori) dari berbagai operasi (operasi) TensorFlow dalam model Anda dan mengatasi hambatan kinerja dan, pada akhirnya, membuat model dieksekusi lebih cepat.
Panduan ini akan memandu Anda tentang cara menginstal Profiler, berbagai alat yang tersedia, berbagai mode cara Profiler mengumpulkan data performa, dan beberapa praktik terbaik yang direkomendasikan untuk mengoptimalkan performa model.
Jika Anda ingin membuat profil performa model Anda di Cloud TPU, lihat panduan Cloud TPU .
Instal prasyarat Profiler dan GPU
Instal plugin Profiler untuk TensorBoard dengan pip. Perhatikan bahwa Profiler memerlukan TensorFlow dan TensorBoard versi terbaru (>=2.2).
pip install -U tensorboard_plugin_profile
Untuk membuat profil di GPU, Anda harus:
- Memenuhi persyaratan driver GPU NVIDIA® dan CUDA® Toolkit yang tercantum pada persyaratan perangkat lunak dukungan GPU TensorFlow .
Pastikan NVIDIA® CUDA® Profiling Tools Interface (CUPTI) ada di jalur:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Jika Anda tidak memiliki CUPTI di jalurnya, tambahkan direktori instalasinya ke variabel lingkungan $LD_LIBRARY_PATH dengan menjalankan:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Kemudian, jalankan kembali perintah ldconfig di atas untuk memverifikasi bahwa perpustakaan CUPTI telah ditemukan.
Selesaikan masalah hak istimewa
Saat Anda menjalankan pembuatan profil dengan CUDA® Toolkit di lingkungan Docker atau di Linux, Anda mungkin mengalami masalah terkait dengan hak istimewa CUPTI yang tidak mencukupi ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Buka Dokumen Pengembang NVIDIA untuk mempelajari lebih lanjut tentang bagaimana Anda dapat mengatasi masalah ini di Linux.
Untuk mengatasi masalah hak istimewa CUPTI di lingkungan Docker, jalankan
docker run option '--privileged=true'
Alat profiler
Akses Profiler dari tab Profil di TensorBoard, yang hanya muncul setelah Anda mengambil beberapa data model.
Profiler memiliki pilihan alat untuk membantu analisis kinerja:
- Halaman Ikhtisar
- Penganalisis Saluran Pipa Masukan
- Statistik TensorFlow
- Penampil Jejak
- Statistik Kernel GPU
- Alat Profil Memori
- Penampil Pod
Halaman ikhtisar
Halaman ikhtisar memberikan tampilan tingkat atas tentang kinerja model Anda selama pengoperasian profil. Halaman ini menampilkan halaman ikhtisar gabungan untuk host dan semua perangkat Anda, serta beberapa rekomendasi untuk meningkatkan performa pelatihan model Anda. Anda juga dapat memilih masing-masing host di menu tarik-turun Host.
Halaman gambaran umum menampilkan data sebagai berikut:
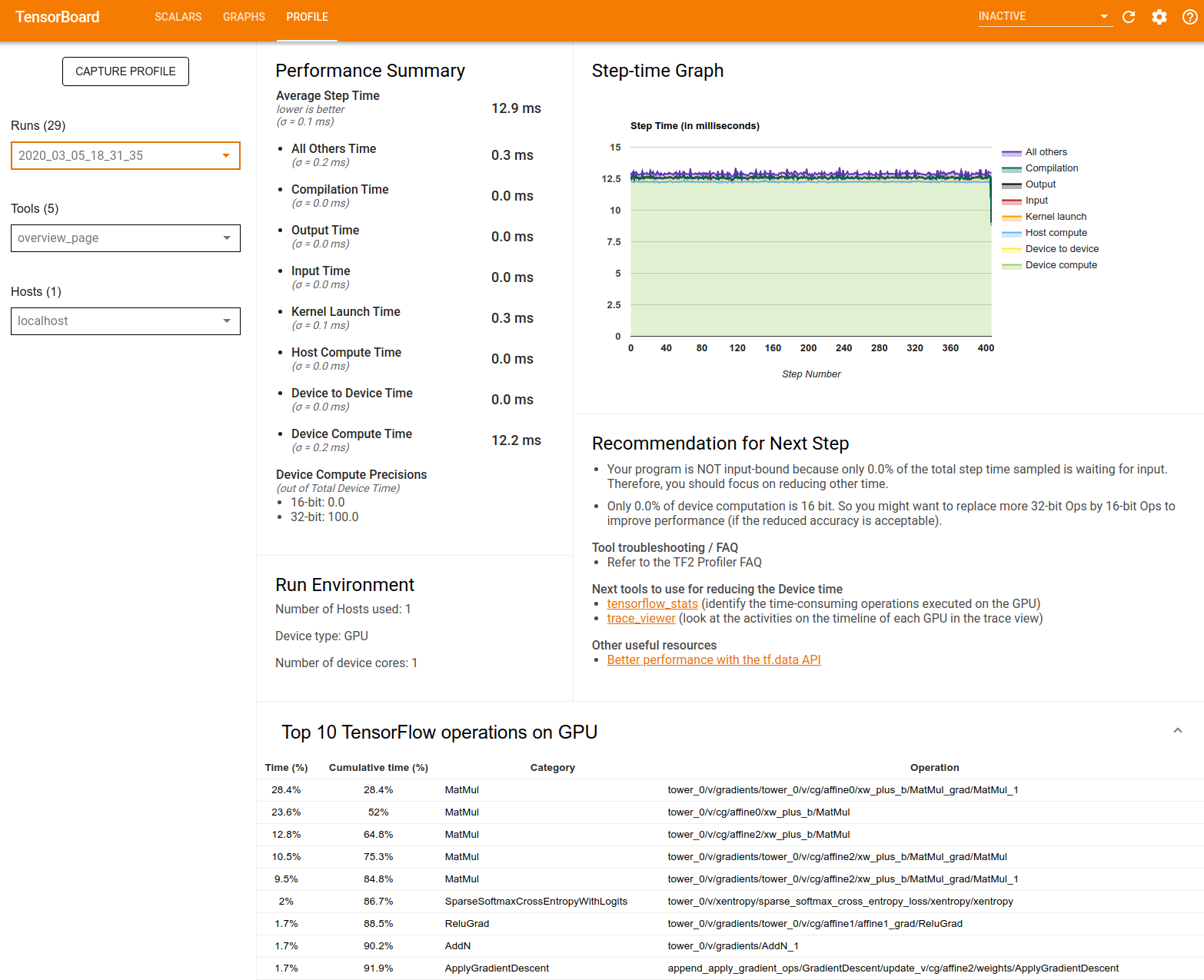
Ringkasan Performa : Menampilkan ringkasan tingkat tinggi performa model Anda. Ringkasan kinerja memiliki dua bagian:
Perincian waktu langkah: Mengelompokkan waktu langkah rata-rata menjadi beberapa kategori berdasarkan waktu yang dihabiskan:
- Kompilasi: Waktu yang dihabiskan untuk mengkompilasi kernel.
- Input: Waktu yang dihabiskan untuk membaca data input.
- Keluaran: Waktu yang dihabiskan untuk membaca data keluaran.
- Peluncuran kernel: Waktu yang dihabiskan oleh host untuk meluncurkan kernel
- Waktu komputasi host..
- Waktu komunikasi antar perangkat.
- Waktu komputasi di perangkat.
- Yang lainnya, termasuk overhead Python.
Ketepatan komputasi perangkat - Melaporkan persentase waktu komputasi perangkat yang menggunakan komputasi 16 dan 32-bit.
Grafik Waktu Langkah : Menampilkan grafik waktu langkah perangkat (dalam milidetik) pada semua langkah yang diambil sampelnya. Setiap langkah dibagi menjadi beberapa kategori (dengan warna berbeda) berdasarkan waktu yang dihabiskan. Area merah sesuai dengan porsi waktu langkah perangkat diam menunggu data input dari host. Area hijau menunjukkan berapa lama perangkat benar-benar berfungsi.
10 operasi TensorFlow teratas pada perangkat (misalnya GPU) : Menampilkan operasi pada perangkat yang berjalan paling lama.
Setiap baris menampilkan waktu operasi (sebagai persentase waktu yang dibutuhkan oleh semua operasi), waktu kumulatif, kategori, dan nama.
Run Environment : Menampilkan ringkasan tingkat tinggi dari lingkungan yang dijalankan model termasuk:
- Jumlah host yang digunakan.
- Jenis perangkat (GPU/TPU).
- Jumlah inti perangkat.
Rekomendasi untuk Langkah Berikutnya : Melaporkan ketika model terikat pada input dan merekomendasikan alat yang dapat Anda gunakan untuk menemukan dan mengatasi hambatan kinerja model.
Penganalisis pipa masukan
Saat program TensorFlow membaca data dari file, program tersebut dimulai di bagian atas grafik TensorFlow secara pipeline. Proses pembacaan dibagi menjadi beberapa tahap pengolahan data yang dihubungkan secara seri, dimana keluaran dari satu tahap merupakan masukan ke tahap berikutnya. Sistem pembacaan data ini disebut pipa masukan .
Alur tipikal untuk membaca catatan dari file memiliki tahapan berikut:
- Pembacaan berkas.
- Pemrosesan awal file (opsional).
- Transfer file dari host ke perangkat.
Saluran masukan yang tidak efisien dapat memperlambat aplikasi Anda. Suatu aplikasi dianggap terikat masukan jika aplikasi tersebut menghabiskan sebagian besar waktunya di saluran masukan. Gunakan wawasan yang diperoleh dari penganalisis saluran masukan untuk memahami di mana saluran masukan tidak efisien.
Penganalisis jalur masukan akan segera memberi tahu Anda apakah program Anda terikat pada masukan dan memandu Anda melalui analisis sisi perangkat dan host untuk men-debug hambatan kinerja pada tahap mana pun dalam jalur masukan.
Periksa panduan tentang performa saluran masukan untuk mengetahui praktik terbaik yang direkomendasikan guna mengoptimalkan saluran masukan data Anda.
Dasbor jalur pipa masukan
Untuk membuka penganalisis alur input, pilih Profile , lalu pilih input_pipeline_analyzer dari dropdown Alat .
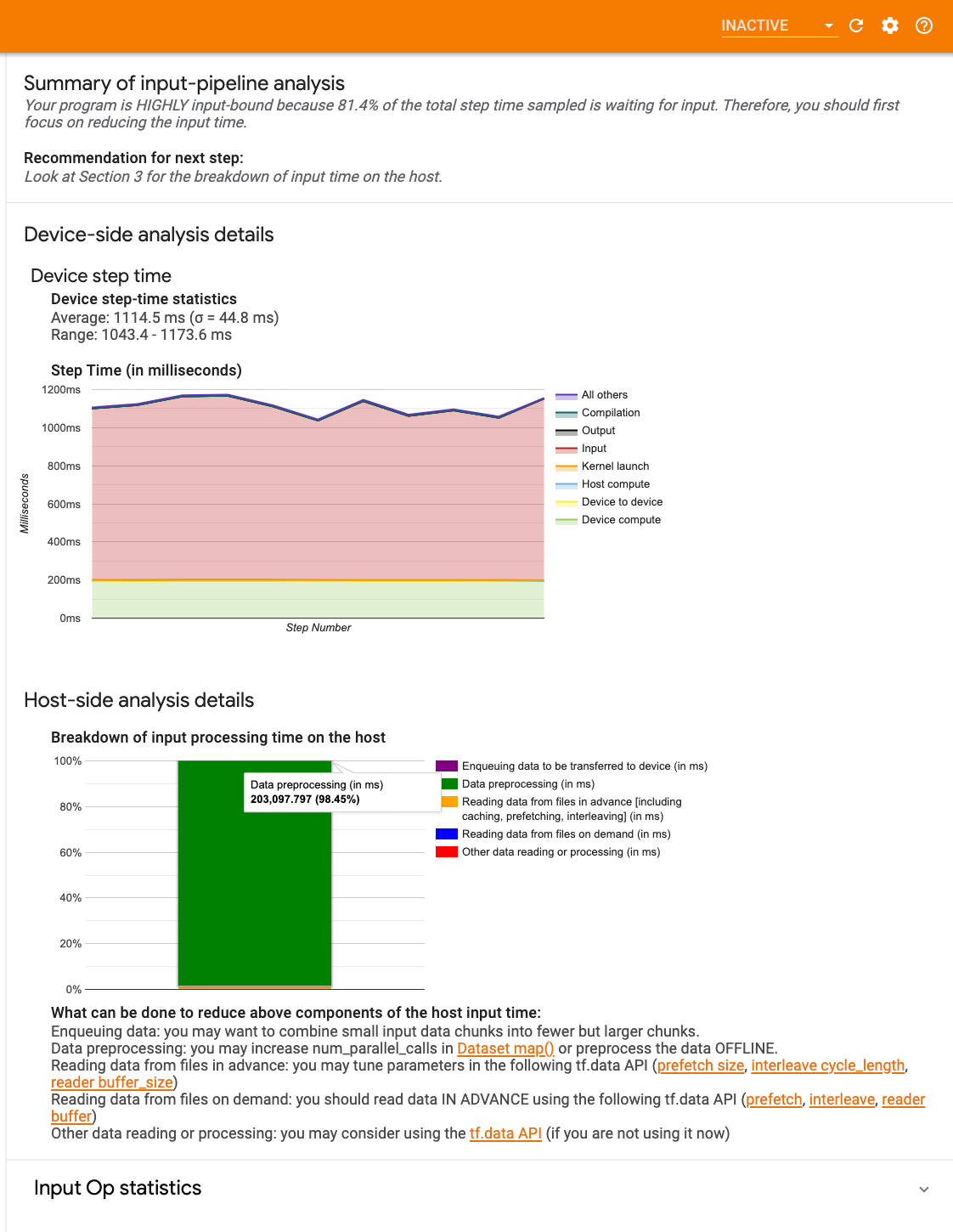
Dasbor berisi tiga bagian:
- Ringkasan : Meringkas keseluruhan saluran masukan dengan informasi apakah aplikasi Anda terikat masukan dan, jika ya, seberapa banyak.
- Analisis sisi perangkat : Menampilkan hasil analisis sisi perangkat secara mendetail, termasuk waktu langkah perangkat dan rentang waktu yang dihabiskan perangkat untuk menunggu data masukan di seluruh inti pada setiap langkah.
- Analisis sisi host : Menampilkan analisis rinci pada sisi host, termasuk perincian waktu pemrosesan input pada host.
Ringkasan alur masukan
Ringkasan melaporkan jika program Anda terikat dengan masukan dengan menampilkan persentase waktu yang dihabiskan perangkat untuk menunggu masukan dari host. Jika Anda menggunakan alur masukan standar yang telah diinstrumentasi, alat tersebut akan melaporkan di mana sebagian besar waktu pemrosesan masukan dihabiskan.
Analisis sisi perangkat
Analisis sisi perangkat memberikan wawasan tentang waktu yang dihabiskan di perangkat dibandingkan di host dan berapa banyak waktu yang dihabiskan perangkat untuk menunggu data input dari host.
- Waktu langkah diplot terhadap nomor langkah : Menampilkan grafik waktu langkah perangkat (dalam milidetik) pada semua langkah yang diambil sampelnya. Setiap langkah dibagi menjadi beberapa kategori (dengan warna berbeda) berdasarkan waktu yang dihabiskan. Area merah sesuai dengan porsi waktu langkah perangkat diam menunggu data input dari host. Area hijau menunjukkan berapa lama perangkat benar-benar berfungsi.
- Statistik waktu langkah : Melaporkan rata-rata, deviasi standar, dan rentang ([minimum, maksimum]) waktu langkah perangkat.
Analisis sisi tuan rumah
Analisis sisi host melaporkan perincian waktu pemrosesan input (waktu yang dihabiskan untuk operasi API tf.data ) pada host ke dalam beberapa kategori:
- Membaca data dari file sesuai permintaan : Waktu yang dihabiskan untuk membaca data dari file tanpa melakukan cache, prefetching, dan interleaving.
- Membaca data dari file terlebih dahulu : Waktu yang dihabiskan untuk membaca file, termasuk caching, prefetching, dan interleaving.
- Pemrosesan awal data : Waktu yang dihabiskan untuk operasi prapemrosesan, seperti dekompresi gambar.
- Mengantrikan data untuk ditransfer ke perangkat : Waktu yang dihabiskan untuk memasukkan data ke dalam antrean masuk sebelum mentransfer data ke perangkat.
Perluas Statistik Operasi Input untuk memeriksa statistik operasi input individual dan kategorinya yang dikelompokkan berdasarkan waktu eksekusi.
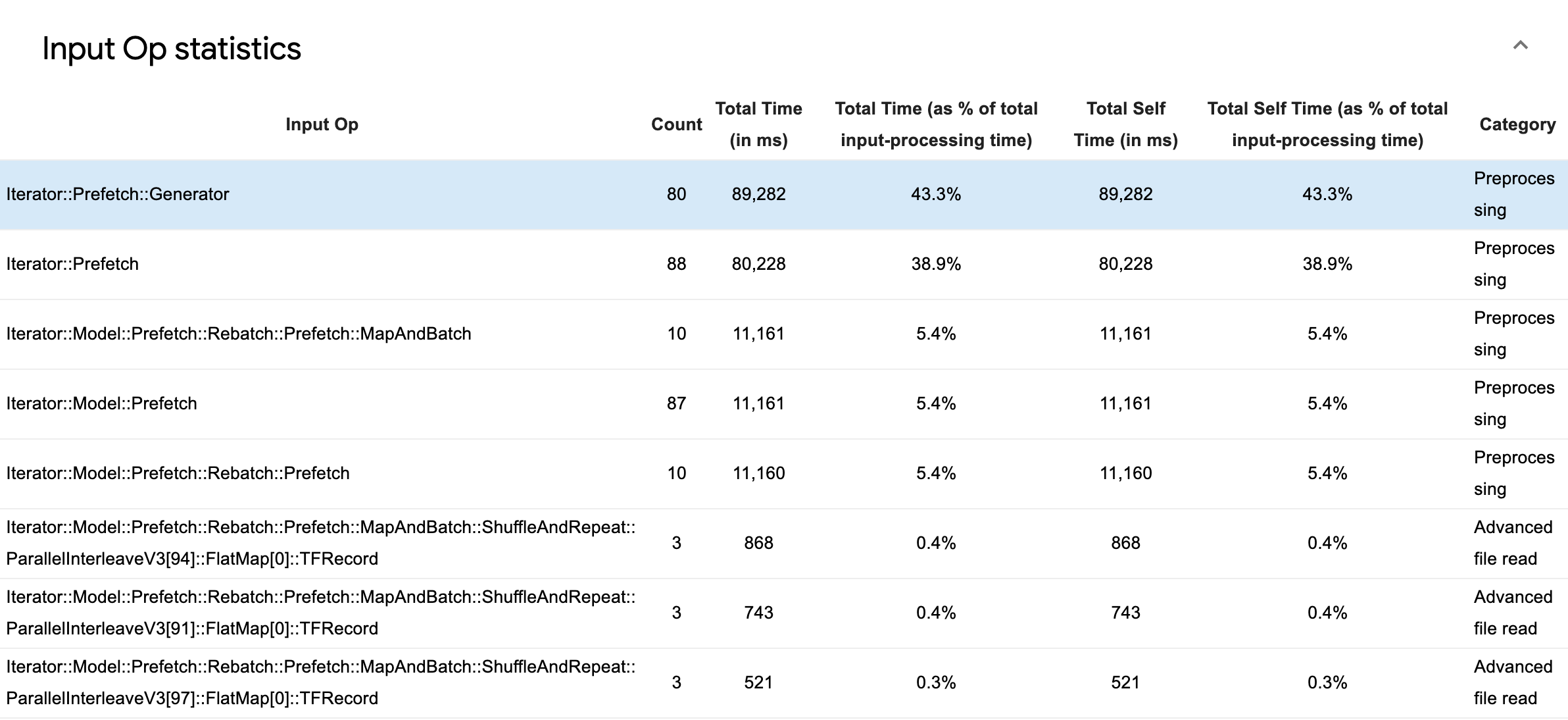
Tabel data sumber akan muncul dengan setiap entri berisi informasi berikut:
- Input Op : Menampilkan nama operasi TensorFlow dari operasi input.
- Hitungan : Menampilkan jumlah total eksekusi operasi selama periode pembuatan profil.
- Total Waktu (dalam ms) : Menampilkan jumlah kumulatif waktu yang dihabiskan pada masing-masing instance tersebut.
- Total Waktu % : Menampilkan total waktu yang dihabiskan dalam suatu operasi sebagai pecahan dari total waktu yang dihabiskan dalam pemrosesan input.
- Total Waktu Mandiri (dalam ms) : Menampilkan jumlah kumulatif waktu mandiri yang dihabiskan pada masing-masing instans tersebut. Waktu mandiri di sini mengukur waktu yang dihabiskan di dalam badan fungsi, tidak termasuk waktu yang dihabiskan dalam fungsi yang dipanggilnya.
- Total Waktu Mandiri % . Menampilkan total waktu mandiri sebagai bagian dari total waktu yang dihabiskan untuk pemrosesan input.
- Kategori . Menampilkan kategori pemrosesan operasi input.
Statistik TensorFlow
Alat TensorFlow Stats menampilkan performa setiap operasi (operasi) TensorFlow yang dijalankan pada host atau perangkat selama sesi pembuatan profil.
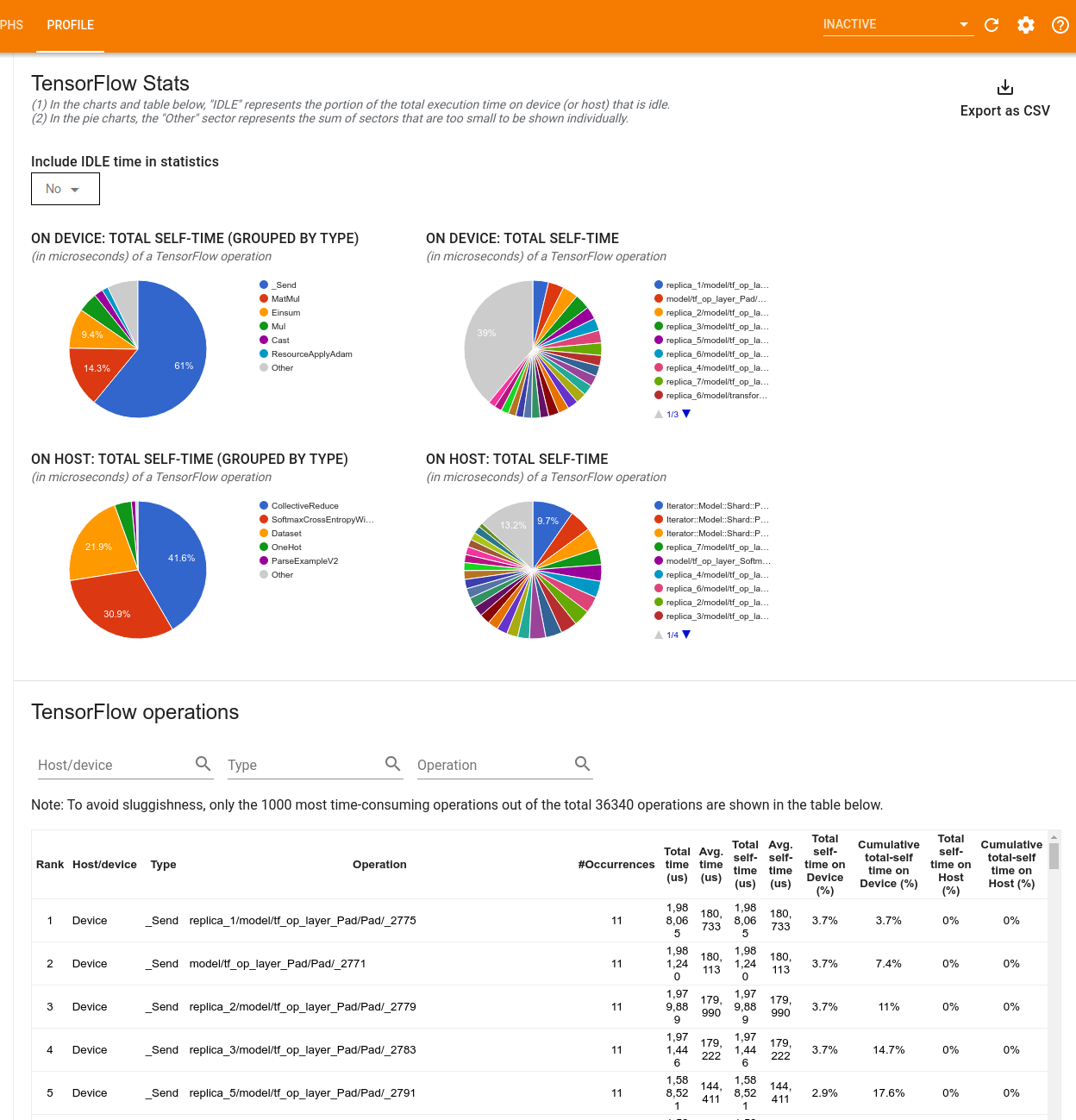
Alat ini menampilkan informasi kinerja dalam dua panel:
Panel atas menampilkan hingga empat diagram lingkaran:
- Distribusi waktu eksekusi mandiri setiap operasi pada host.
- Distribusi waktu eksekusi mandiri setiap jenis operasi pada host.
- Distribusi waktu eksekusi mandiri setiap operasi pada perangkat.
- Distribusi waktu eksekusi mandiri setiap jenis operasi pada perangkat.
Panel bawah menampilkan tabel yang melaporkan data tentang operasi TensorFlow dengan satu baris untuk setiap operasi dan satu kolom untuk setiap jenis data (urutkan kolom dengan mengklik judul kolom). Klik tombol Ekspor sebagai CSV di sisi kanan panel atas untuk mengekspor data dari tabel ini sebagai file CSV.
Perhatikan bahwa:
Jika ada operasi yang memiliki operasi turunan:
- Total waktu "akumulasi" suatu operasi mencakup waktu yang dihabiskan di dalam operasi turunan.
- Total waktu "mandiri" dari sebuah operasi tidak termasuk waktu yang dihabiskan di dalam operasi anak.
Jika operasi dijalankan pada host:
- Persentase total waktu mandiri pada perangkat yang dikeluarkan oleh operasi ini adalah 0.
- Persentase kumulatif total waktu mandiri pada perangkat hingga dan termasuk operasi ini adalah 0.
Jika operasi dijalankan pada perangkat:
- Persentase total waktu mandiri pada host yang dikeluarkan oleh operasi ini adalah 0.
- Persentase kumulatif dari total waktu mandiri pada host hingga dan termasuk operasi ini akan menjadi 0.
Anda dapat memilih untuk memasukkan atau mengecualikan waktu menganggur dalam diagram lingkaran dan tabel.
Penampil jejak
Penampil jejak menampilkan garis waktu yang memperlihatkan:
- Durasi operasi yang dijalankan oleh model TensorFlow Anda
- Bagian mana dari sistem (host atau perangkat) yang menjalankan operasi. Biasanya, host menjalankan operasi masukan, memproses data pelatihan terlebih dahulu, dan mentransfernya ke perangkat, sementara perangkat menjalankan pelatihan model sebenarnya.
Penampil jejak memungkinkan Anda mengidentifikasi masalah kinerja pada model Anda, lalu mengambil langkah untuk mengatasinya. Misalnya, pada tingkat tinggi, Anda dapat mengidentifikasi apakah pelatihan input atau model menghabiskan sebagian besar waktu. Dengan menelusuri lebih jauh, Anda dapat mengidentifikasi operasi mana yang membutuhkan waktu paling lama untuk dieksekusi. Perlu diperhatikan bahwa penampil jejak dibatasi hingga 1 juta peristiwa per perangkat.
Antarmuka penampil jejak
Saat Anda membuka penampil jejak, penampil jejak tersebut akan menampilkan proses terbaru Anda:
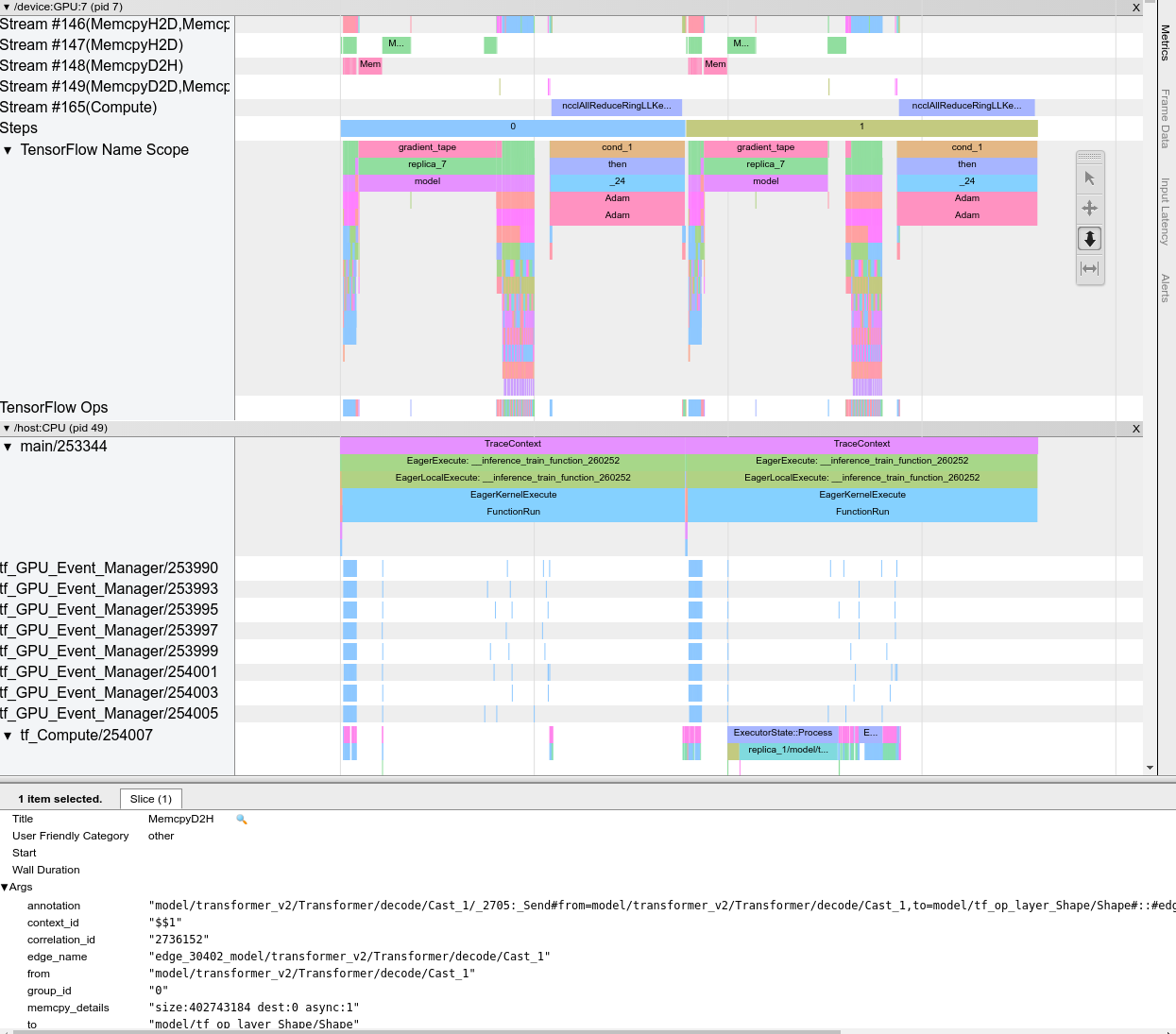
Layar ini berisi elemen utama berikut:
- Panel Timeline : Menampilkan operasi yang dijalankan perangkat dan host seiring waktu.
- Panel detail : Menampilkan informasi tambahan untuk operasi yang dipilih di panel Timeline.
Panel Timeline berisi elemen berikut:
- Bilah atas : Berisi berbagai kontrol tambahan.
- Sumbu waktu : Menampilkan waktu relatif terhadap awal pelacakan.
- Label bagian dan trek : Setiap bagian berisi beberapa trek dan memiliki segitiga di sebelah kiri yang dapat Anda klik untuk meluaskan dan menciutkan bagian tersebut. Ada satu bagian untuk setiap elemen pemrosesan dalam sistem.
- Pemilih alat : Berisi berbagai alat untuk berinteraksi dengan penampil jejak seperti Zoom, Geser, Pilih, dan Pengaturan Waktu. Gunakan alat Timing untuk menandai interval waktu.
- Peristiwa : Ini menunjukkan waktu selama operasi dijalankan atau durasi peristiwa meta, seperti langkah pelatihan.
Bagian dan trek
Penampil jejak berisi bagian berikut:
- Satu bagian untuk setiap node perangkat , diberi label dengan nomor chip perangkat dan node perangkat dalam chip (misalnya,
/device:GPU:0 (pid 0)). Setiap bagian node perangkat berisi trek berikut:- Step : Menampilkan durasi langkah pelatihan yang sedang berjalan di perangkat
- TensorFlow Ops : Menampilkan operasi yang dijalankan pada perangkat
- XLA Ops : Menampilkan operasi (ops) XLA yang berjalan di perangkat jika XLA adalah compiler yang digunakan (setiap operasi TensorFlow diterjemahkan menjadi satu atau beberapa ops XLA. Compiler XLA menerjemahkan ops XLA menjadi kode yang berjalan di perangkat).
- Satu bagian untuk thread yang berjalan pada CPU mesin host, diberi label "Host Threads" . Bagian ini berisi satu track untuk setiap thread CPU. Perhatikan bahwa Anda dapat mengabaikan informasi yang ditampilkan di samping label bagian.
Acara
Peristiwa dalam garis waktu ditampilkan dalam warna berbeda; warnanya sendiri tidak memiliki arti khusus.
Penampil jejak juga dapat menampilkan jejak panggilan fungsi Python di program TensorFlow Anda. Jika Anda menggunakan API tf.profiler.experimental.start , Anda dapat mengaktifkan penelusuran Python dengan menggunakan Nametuple ProfilerOptions saat memulai pembuatan profil. Alternatifnya, jika Anda menggunakan mode pengambilan sampel untuk pembuatan profil, Anda dapat memilih tingkat penelusuran dengan menggunakan opsi tarik-turun dalam dialog Ambil Profil .
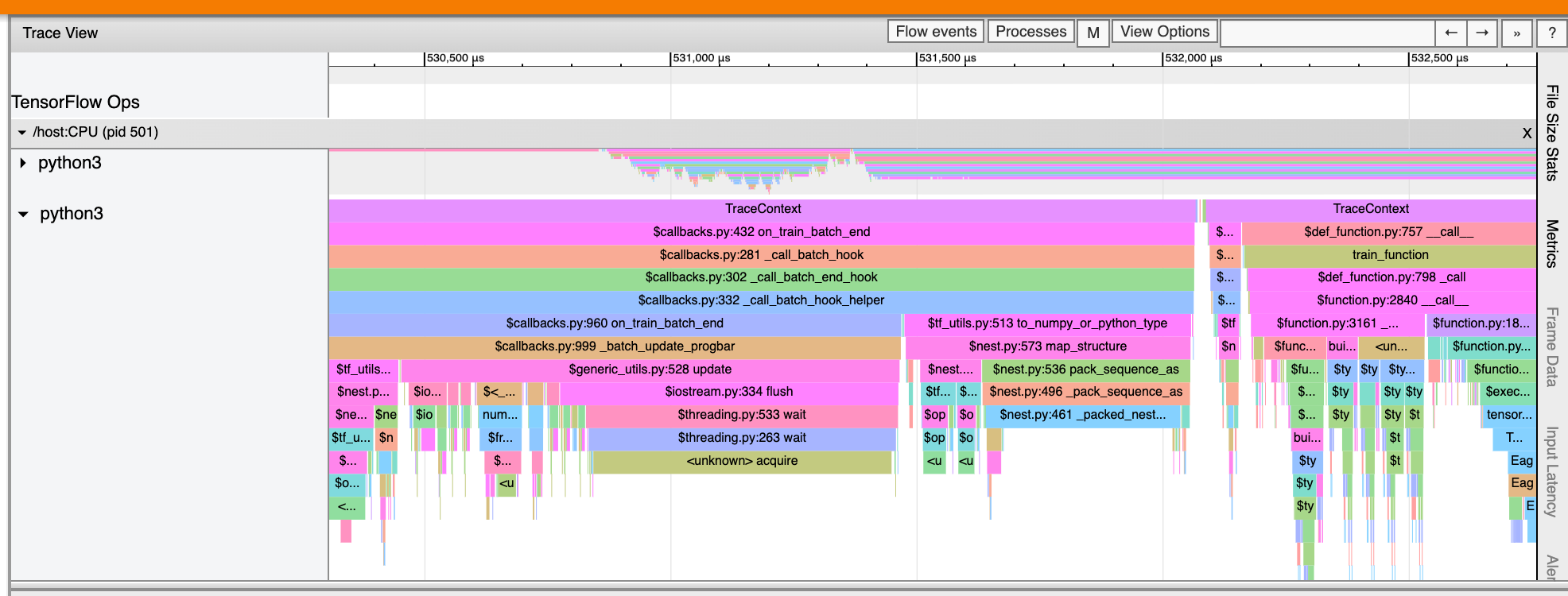
Statistik kernel GPU
Alat ini menunjukkan statistik kinerja dan operasi asal untuk setiap kernel yang dipercepat GPU.
Alat ini menampilkan informasi dalam dua panel:
Panel atas menampilkan diagram lingkaran yang menunjukkan kernel CUDA yang memiliki total waktu berlalu tertinggi.
Panel bawah menampilkan tabel dengan data berikut untuk setiap pasangan operasi kernel yang unik:
- Peringkat dalam urutan menurun dari total durasi GPU yang telah berlalu yang dikelompokkan berdasarkan pasangan operasi kernel.
- Nama kernel yang diluncurkan.
- Jumlah register GPU yang digunakan oleh kernel.
- Ukuran total memori bersama (bersama statis + dinamis) yang digunakan dalam byte.
- Dimensi blok dinyatakan sebagai
blockDim.x, blockDim.y, blockDim.z. - Dimensi kisi dinyatakan sebagai
gridDim.x, gridDim.y, gridDim.z. - Apakah operasi tersebut memenuhi syarat untuk menggunakan Tensor Cores .
- Apakah kernel berisi instruksi Tensor Core.
- Nama operasi yang meluncurkan kernel ini.
- Jumlah kemunculan pasangan operasi kernel ini.
- Total waktu GPU yang berlalu dalam mikrodetik.
- Rata-rata waktu berlalu GPU dalam mikrodetik.
- Waktu GPU minimum yang berlalu dalam mikrodetik.
- Waktu GPU maksimum yang berlalu dalam mikrodetik.
Alat profil memori
Alat Profil Memori memantau penggunaan memori perangkat Anda selama interval pembuatan profil. Anda dapat menggunakan alat ini untuk:
- Debug masalah kehabisan memori (OOM) dengan menunjukkan dengan tepat penggunaan memori puncak dan alokasi memori yang sesuai untuk operasi TensorFlow. Anda juga dapat men-debug masalah OOM yang mungkin timbul saat Anda menjalankan inferensi multi-penyewa .
- Debug masalah fragmentasi memori.
Alat profil memori menampilkan data dalam tiga bagian:
- Ringkasan Profil Memori
- Grafik Garis Waktu Memori
- Tabel Perincian Memori
Ringkasan profil memori
Bagian ini menampilkan ringkasan tingkat tinggi profil memori program TensorFlow Anda seperti yang ditunjukkan di bawah ini:
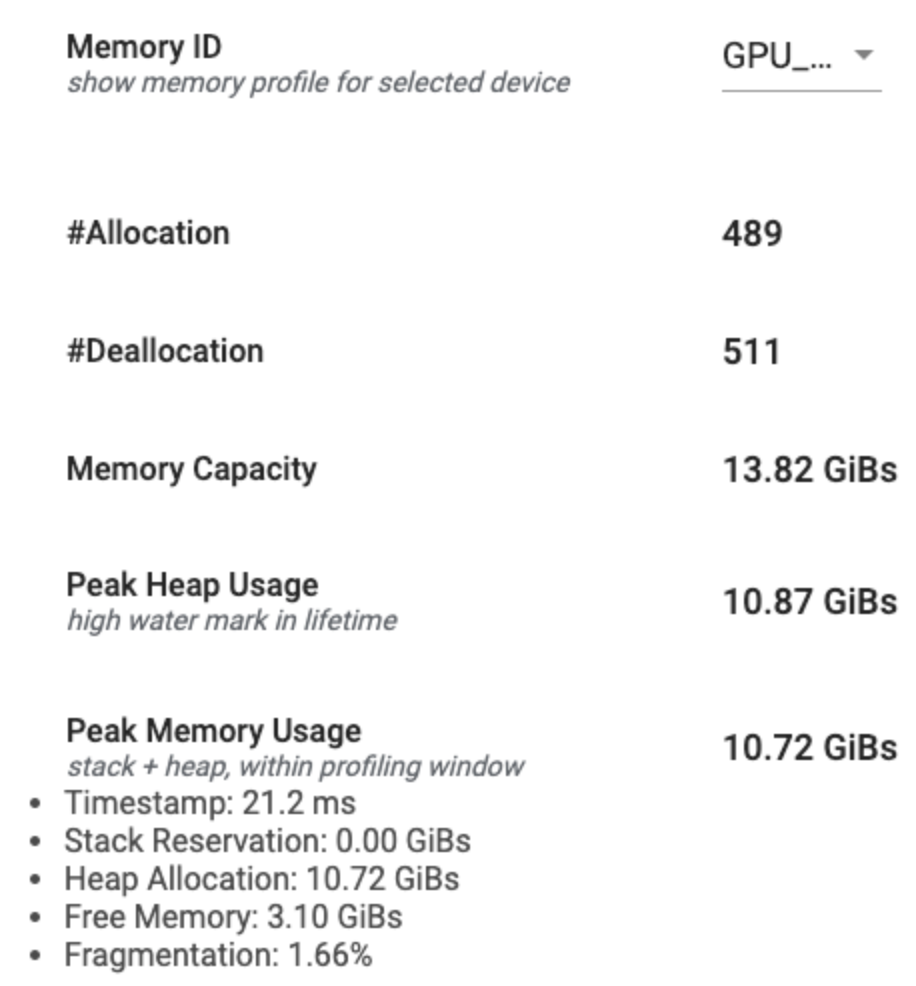
Ringkasan profil memori memiliki enam bidang:
- ID Memori : Dropdown yang mencantumkan semua sistem memori perangkat yang tersedia. Pilih sistem memori yang ingin Anda lihat dari dropdown.
- #Allocation : Jumlah alokasi memori yang dibuat selama interval pembuatan profil.
- #Deallocation : Jumlah dealokasi memori dalam interval pembuatan profil
- Kapasitas Memori : Kapasitas total (dalam GiB) sistem memori yang Anda pilih.
- Penggunaan Tumpukan Puncak : Penggunaan memori puncak (dalam GiB) sejak model mulai berjalan.
- Penggunaan Memori Puncak : Penggunaan memori puncak (dalam GiB) dalam interval pembuatan profil. Bidang ini berisi sub-bidang berikut:
- Stempel Waktu : Stempel waktu saat penggunaan memori puncak terjadi pada Grafik Timeline.
- Reservasi Tumpukan : Jumlah memori yang dicadangkan pada tumpukan (dalam GiB).
- Alokasi Heap : Jumlah memori yang dialokasikan pada heap (dalam GiBs).
- Memori Bebas : Jumlah memori bebas (dalam GiB). Kapasitas Memori adalah jumlah total Reservasi Tumpukan, Alokasi Tumpukan, dan Memori Bebas.
- Fragmentasi : Persentase fragmentasi (lebih rendah lebih baik). Ini dihitung sebagai persentase
(1 - Size of the largest chunk of free memory / Total free memory).
Grafik garis waktu memori
Bagian ini menampilkan plot penggunaan memori (dalam GiB) dan persentase fragmentasi terhadap waktu (dalam ms).
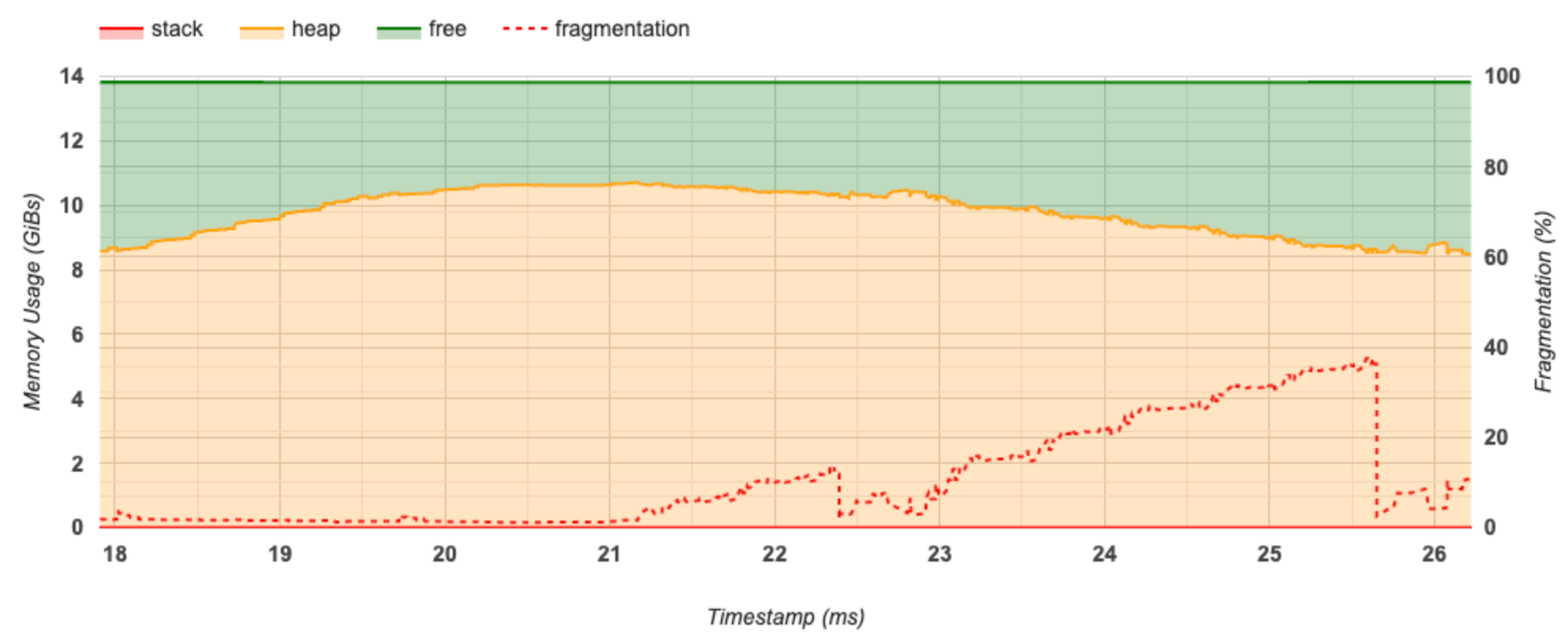
Sumbu X mewakili garis waktu (dalam ms) dari interval pembuatan profil. Sumbu Y di sebelah kiri menunjukkan penggunaan memori (dalam GiB) dan sumbu Y di sebelah kanan menunjukkan persentase fragmentasi. Pada setiap titik waktu pada sumbu X, total memori dipecah menjadi tiga kategori: tumpukan (berwarna merah), heap (berwarna oranye), dan bebas (berwarna hijau). Arahkan kursor ke stempel waktu tertentu untuk melihat detail tentang peristiwa alokasi/dealokasi memori pada saat itu seperti di bawah ini:
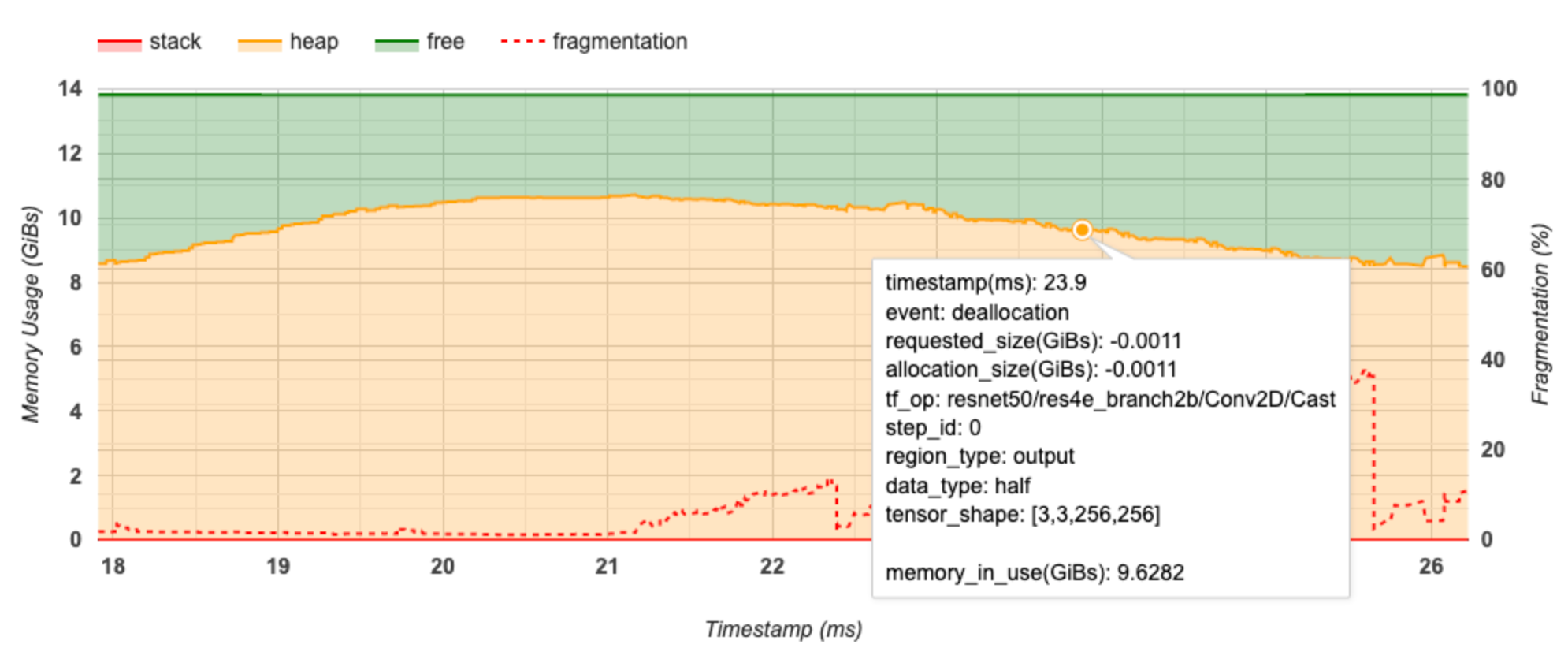
Jendela pop-up menampilkan informasi berikut:
- timestamp(ms) : Lokasi acara yang dipilih di timeline.
- event : Jenis acara (alokasi atau dealokasi).
- request_size(GiBs) : Jumlah memori yang diminta. Ini akan menjadi angka negatif untuk peristiwa dealokasi.
- alokasi_ukuran(GiBs) : Jumlah sebenarnya memori yang dialokasikan. Ini akan menjadi angka negatif untuk peristiwa dealokasi.
- tf_op : Operasi TensorFlow yang meminta alokasi/dealokasi.
- step_id : Langkah pelatihan di mana peristiwa ini terjadi.
- region_type : Tipe entitas data yang digunakan untuk memori yang dialokasikan ini. Nilai yang mungkin adalah
tempuntuk sementara,outputuntuk aktivasi dan gradien, danpersist/dynamicuntuk bobot dan konstanta. - data_type : Tipe elemen tensor (misalnya, uint8 untuk integer 8-bit yang tidak ditandatangani).
- tensor_shape : Bentuk tensor yang dialokasikan/dibatalkan alokasinya.
- memory_in_use(GiBs) : Total memori yang digunakan pada saat ini.
Tabel rincian memori
Tabel ini menunjukkan alokasi memori aktif pada titik penggunaan memori puncak dalam interval pembuatan profil.
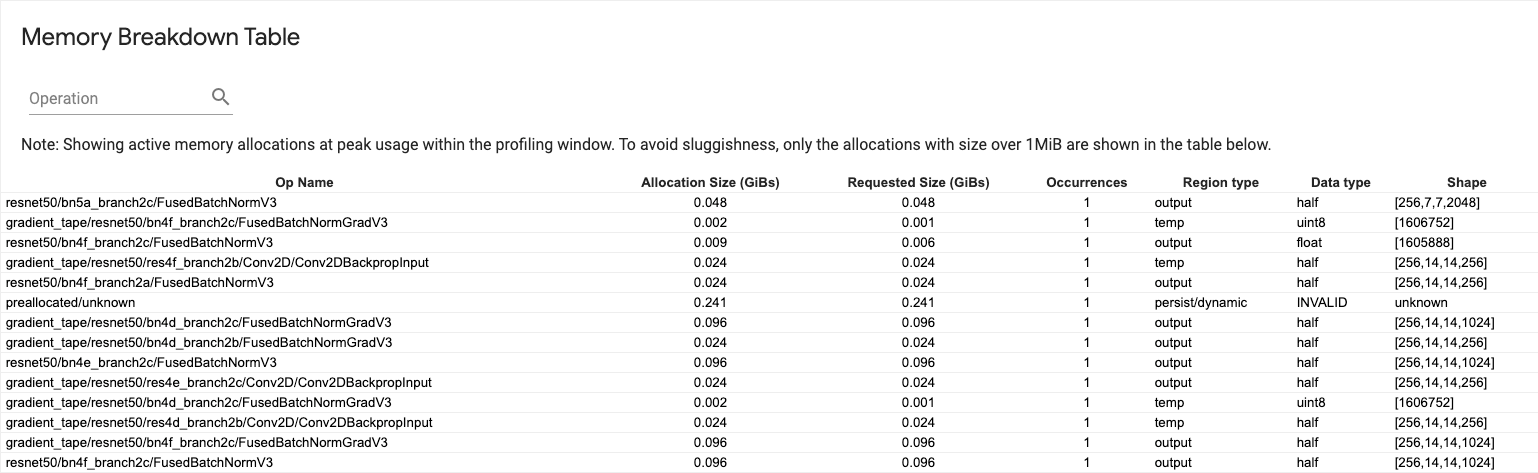
Terdapat satu baris untuk setiap Operasi TensorFlow dan setiap baris memiliki kolom berikut:
- Nama Operasi : Nama operasi TensorFlow.
- Ukuran Alokasi (GiBs) : Jumlah total memori yang dialokasikan untuk operasi ini.
- Ukuran yang Diminta (GiBs) : Jumlah total memori yang diminta untuk operasi ini.
- Kejadian : Jumlah alokasi untuk operasi ini.
- Tipe wilayah : Tipe entitas data yang digunakan untuk memori yang dialokasikan ini. Nilai yang mungkin adalah
tempuntuk sementara,outputuntuk aktivasi dan gradien, danpersist/dynamicuntuk bobot dan konstanta. - Tipe data : Tipe elemen tensor.
- Bentuk : Bentuk tensor yang dialokasikan.
Penampil pod
Alat Penampil Pod menunjukkan perincian langkah pelatihan di seluruh pekerja.
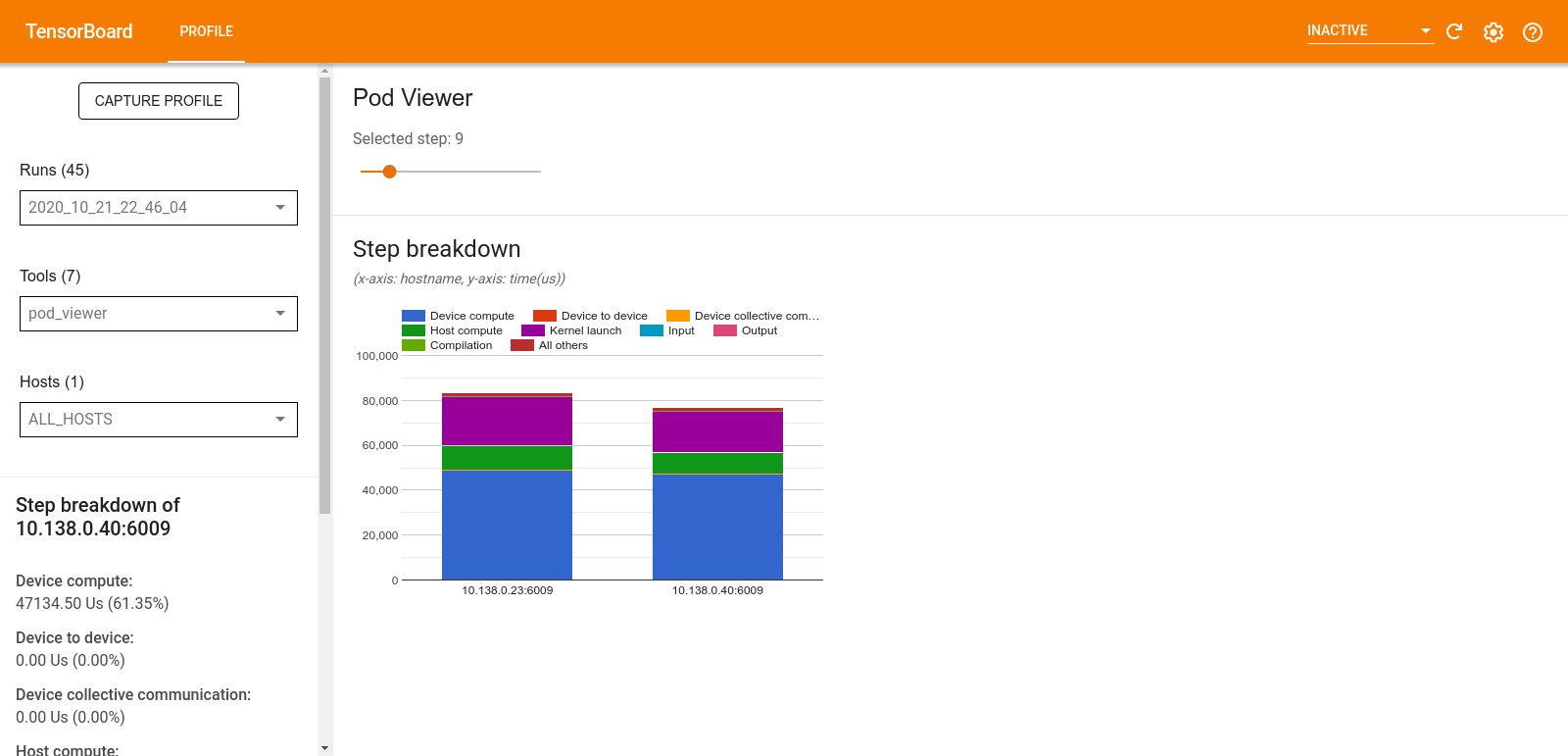
- Panel atas memiliki penggeser untuk memilih nomor langkah.
- Panel bawah menampilkan bagan kolom bertumpuk. Ini adalah tampilan tingkat tinggi dari kategori waktu langkah yang dipecah dan ditempatkan di atas satu sama lain. Setiap kolom bertumpuk mewakili pekerja unik.
- Saat Anda mengarahkan kursor ke kolom bertumpuk, kartu di sisi kiri menampilkan detail lebih lanjut tentang perincian langkah.
analisis kemacetan tf.data
Alat analisis kemacetan tf.data secara otomatis mendeteksi kemacetan di saluran masukan tf.data di program Anda dan memberikan rekomendasi tentang cara memperbaikinya. Ia bekerja dengan program apa pun yang menggunakan tf.data apa pun platformnya (CPU/GPU/TPU). Analisis dan rekomendasinya didasarkan pada panduan ini.
Ini mendeteksi kemacetan dengan mengikuti langkah-langkah berikut:
- Temukan host yang paling terikat dengan masukan.
- Temukan eksekusi paling lambat dari pipeline input
tf.data. - Rekonstruksi grafik alur masukan dari jejak profiler.
- Temukan jalur kritis dalam grafik pipa masukan.
- Identifikasi transformasi paling lambat pada jalur kritis sebagai hambatan.
UI dibagi menjadi tiga bagian: Ringkasan Analisis Kinerja , Ringkasan Semua Saluran Masukan , dan Grafik Saluran Masukan .
Ringkasan analisis kinerja

Bagian ini memberikan ringkasan analisis. Ini melaporkan saluran input tf.data lambat yang terdeteksi di profil. Bagian ini juga menunjukkan host dengan input terbanyak dan pipeline input paling lambat dengan latensi maksimal. Yang paling penting, hal ini mengidentifikasi bagian mana dari saluran masukan yang menjadi hambatan dan bagaimana cara memperbaikinya. Informasi kemacetan diberikan dengan tipe iterator dan nama panjangnya.
Cara membaca nama panjang iterator tf.data
Nama panjang diformat sebagai Iterator::<Dataset_1>::...::<Dataset_n> . Dalam nama panjang, <Dataset_n> cocok dengan tipe iterator dan kumpulan data lain dalam nama panjang mewakili transformasi hilir.
Misalnya, pertimbangkan himpunan data alur masukan berikut:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Nama panjang iterator dari kumpulan data di atas adalah:
| Tipe Iterator | Nama Panjang |
|---|---|
| Jangkauan | Iterator::Batch::Ulangi::Peta::Rentang |
| Peta | Iterator::Batch::Ulangi::Peta |
| Mengulang | Iterator::Batch::Ulangi |
| Kelompok | Iterator::Batch |
Ringkasan semua saluran pipa masukan
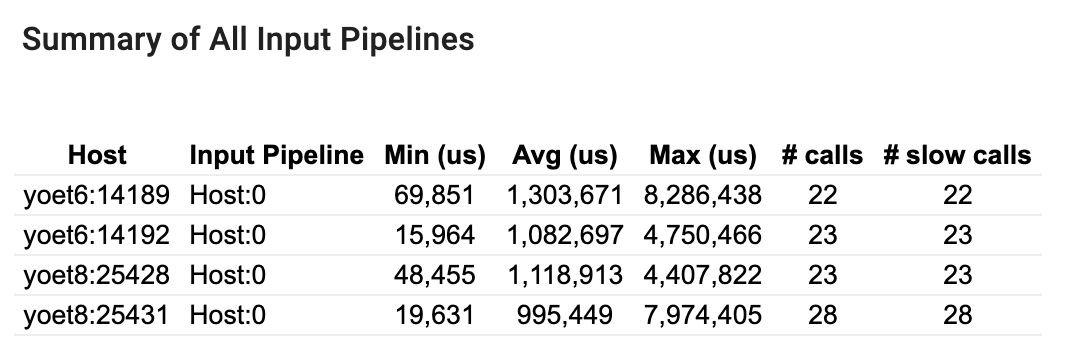
Bagian ini memberikan ringkasan semua saluran masukan di semua host. Biasanya ada satu saluran masukan. Saat menggunakan strategi distribusi, ada satu saluran masukan host yang menjalankan kode tf.data program dan beberapa saluran masukan perangkat yang mengambil data dari saluran masukan host dan mentransfernya ke perangkat.
Untuk setiap saluran masukan, ini menunjukkan statistik waktu eksekusinya. Panggilan dianggap lambat jika memerlukan waktu lebih dari 50 s.
Grafik jalur pipa masukan

Bagian ini memperlihatkan grafik alur masukan dengan informasi waktu eksekusi. Anda dapat menggunakan "Host" dan "Input Pipeline" untuk memilih host dan pipeline input mana yang ingin dilihat. Eksekusi pipa input diurutkan berdasarkan waktu eksekusi dalam urutan menurun yang dapat Anda pilih menggunakan dropdown Peringkat .
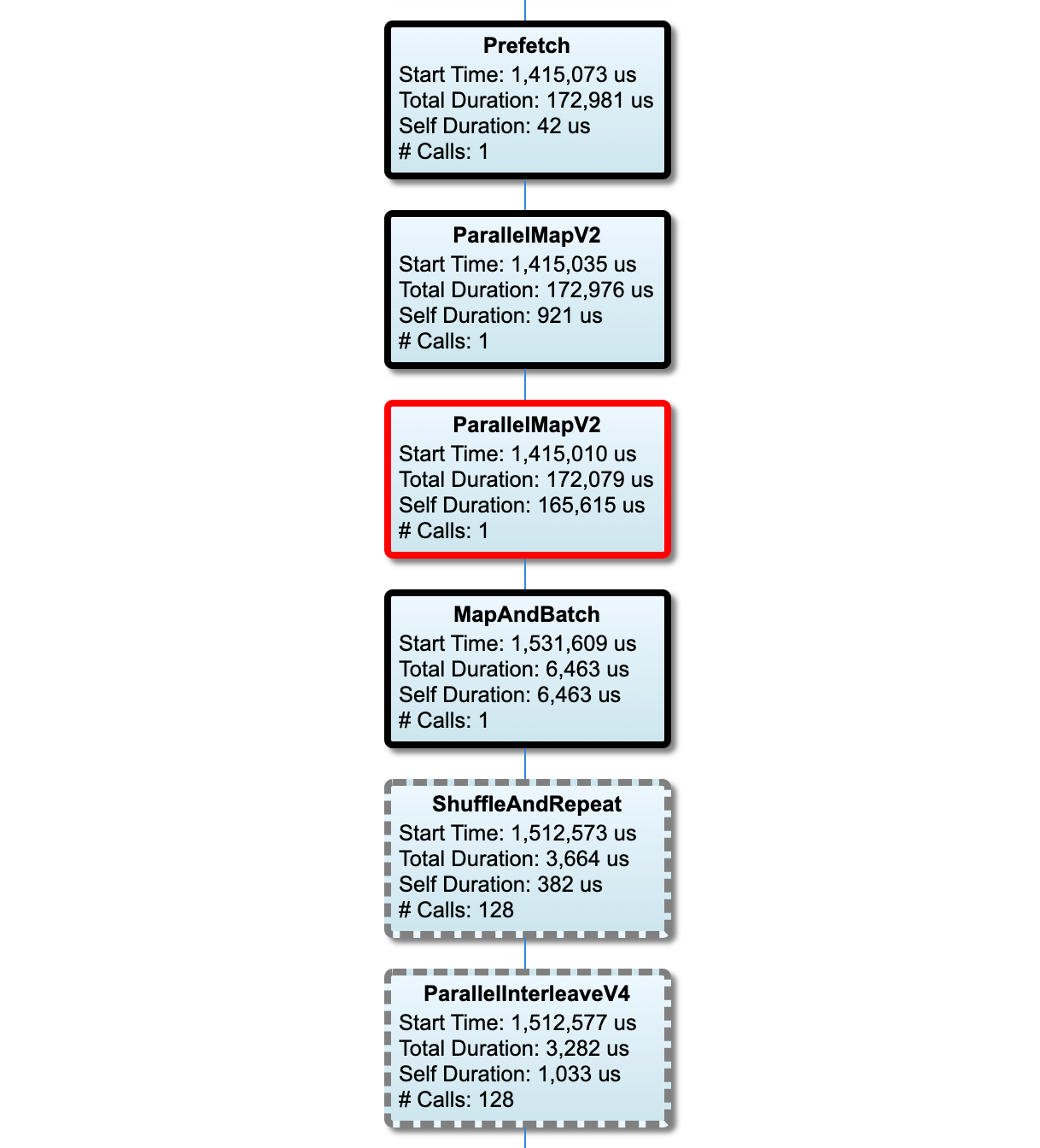
Node pada jalur kritis memiliki garis tebal. Node bottleneck, yaitu node dengan waktu mandiri terlama pada jalur kritis, memiliki garis tepi berwarna merah. Node non-kritis lainnya memiliki garis putus-putus berwarna abu-abu.
Di setiap node, Waktu Mulai menunjukkan waktu mulai eksekusi. Node yang sama dapat dieksekusi beberapa kali, misalnya, jika ada operasi Batch di pipa input. Jika dieksekusi beberapa kali, ini adalah waktu mulai eksekusi pertama.
Durasi Total adalah waktu dinding eksekusi. Jika dieksekusi beberapa kali, ini adalah jumlah waktu dinding dari semua eksekusi.
Self Time adalah Total Waktu tanpa waktu yang tumpang tindih dengan node turunannya.
"# Panggilan" adalah berapa kali pipa input dieksekusi.
Kumpulkan data kinerja
TensorFlow Profiler mengumpulkan aktivitas host dan jejak GPU model TensorFlow Anda. Anda dapat mengonfigurasi Profiler untuk mengumpulkan data kinerja melalui mode terprogram atau mode pengambilan sampel.
API Profil
Anda dapat menggunakan API berikut untuk melakukan pembuatan profil.
Mode terprogram menggunakan TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Mode terprogram menggunakan
tf.profilerFunction APItf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Mode terprogram menggunakan pengelola konteks
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Mode pengambilan sampel: Lakukan pembuatan profil sesuai permintaan dengan menggunakan
tf.profiler.experimental.server.startuntuk memulai server gRPC dengan menjalankan model TensorFlow Anda. Setelah memulai server gRPC dan menjalankan model, Anda dapat mengambil profil melalui tombol Ambil Profil di plugin profil TensorBoard. Gunakan skrip di bagian Instal profiler di atas untuk meluncurkan instance TensorBoard jika belum berjalan.Sebagai contoh,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Contoh untuk membuat profil beberapa pekerja:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
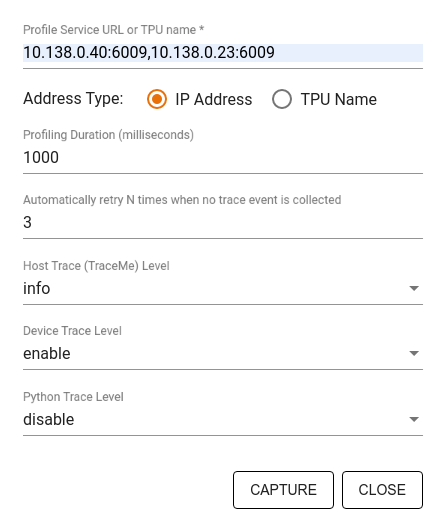
Gunakan dialog Capture Profile untuk menentukan:
- Daftar URL layanan profil atau nama TPU yang dipisahkan koma.
- Durasi pembuatan profil.
- Tingkat pelacakan panggilan fungsi perangkat, host, dan Python.
- Berapa kali Anda ingin Profiler mencoba mengambil kembali profil jika pada awalnya tidak berhasil.
Membuat profil loop pelatihan khusus
Untuk membuat profil loop pelatihan khusus dalam kode TensorFlow Anda, lengkapi loop pelatihan dengan tf.profiler.experimental.Trace API untuk menandai batas langkah untuk Profiler.
Argumen name digunakan sebagai awalan untuk nama langkah, argumen kata kunci step_num ditambahkan pada nama langkah, dan argumen kata kunci _r membuat peristiwa jejak ini diproses sebagai peristiwa langkah oleh Profiler.
Sebagai contoh,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Hal ini akan mengaktifkan analisis kinerja berbasis langkah Profiler dan menyebabkan peristiwa langkah muncul di penampil jejak.
Pastikan Anda menyertakan iterator himpunan data dalam konteks tf.profiler.experimental.Trace untuk analisis pipa masukan yang akurat.
Cuplikan kode di bawah ini adalah anti-pola:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Membuat profil kasus penggunaan
Profiler mencakup sejumlah kasus penggunaan di empat sumbu berbeda. Beberapa kombinasi saat ini didukung dan kombinasi lainnya akan ditambahkan di masa mendatang. Beberapa kasus penggunaan adalah:
- Pembuatan profil lokal vs. jarak jauh : Ini adalah dua cara umum untuk menyiapkan lingkungan pembuatan profil Anda. Dalam pembuatan profil lokal, API pembuatan profil dipanggil pada mesin yang sama dengan yang dijalankan model Anda, misalnya, stasiun kerja lokal dengan GPU. Dalam pembuatan profil jarak jauh, API pembuatan profil dipanggil di mesin yang berbeda dari tempat model Anda dieksekusi, misalnya, di Cloud TPU.
- Membuat profil beberapa pekerja : Anda dapat membuat profil beberapa mesin saat menggunakan kemampuan pelatihan terdistribusi TensorFlow.
- Platform perangkat keras : Profil CPU, GPU, dan TPU.
Tabel di bawah memberikan ringkasan singkat tentang kasus penggunaan yang didukung TensorFlow yang disebutkan di atas:
| API Profil | Lokal | Terpencil | Banyak pekerja | Platform Perangkat Keras |
|---|---|---|---|---|
| Panggilan Balik TensorBoard Keras | Didukung | Tidak Didukung | Tidak Didukung | CPU, GPU |
tf.profiler.experimental memulai/menghentikan API | Didukung | Tidak Didukung | Tidak Didukung | CPU, GPU |
tf.profiler.experimental client.trace API | Didukung | Didukung | Didukung | CPU, GPU, TPU |
| API manajer konteks | Didukung | Tidak didukung | Tidak Didukung | CPU, GPU |
Praktik terbaik untuk performa model yang optimal
Gunakan rekomendasi berikut sebagaimana berlaku untuk model TensorFlow Anda untuk mencapai performa optimal.
Secara umum, lakukan semua transformasi pada perangkat dan pastikan Anda menggunakan pustaka versi terbaru yang kompatibel seperti cuDNN dan Intel MKL untuk platform Anda.
Optimalkan saluran data masukan
Gunakan data dari [#input_pipeline_analyzer] untuk mengoptimalkan pipeline input data Anda. Pipeline input data yang efisien dapat secara drastis meningkatkan kecepatan eksekusi model Anda dengan mengurangi waktu idle perangkat. Cobalah untuk menerapkan praktik terbaik yang dirinci dalam panduan Performa lebih baik dengan tf.data API dan di bawah ini untuk membuat saluran input data Anda lebih efisien.
Secara umum, memparalelkan operasi apa pun yang tidak perlu dijalankan secara berurutan dapat mengoptimalkan jalur input data secara signifikan.
Dalam banyak kasus, ada gunanya mengubah urutan beberapa panggilan atau menyesuaikan argumen sedemikian rupa sehingga paling sesuai untuk model Anda. Saat mengoptimalkan pipeline data masukan, lakukan benchmark hanya pada pemuat data tanpa langkah-langkah pelatihan dan propagasi mundur untuk mengukur efek pengoptimalan secara independen.
Coba jalankan model Anda dengan data sintetis untuk memeriksa apakah pipeline input merupakan hambatan performa.
Gunakan
tf.data.Dataset.sharduntuk pelatihan multi-GPU. Pastikan Anda melakukan sharding sejak awal dalam loop input untuk mencegah pengurangan throughput. Saat bekerja dengan TFRecords, pastikan Anda membagi daftar TFRecords dan bukan konten TFRecords.Paralelkan beberapa operasi dengan mengatur nilai
num_parallel_callssecara dinamis menggunakantf.data.AUTOTUNE.Pertimbangkan untuk membatasi penggunaan
tf.data.Dataset.from_generatorkarena lebih lambat dibandingkan dengan operasi TensorFlow murni.Pertimbangkan untuk membatasi penggunaan
tf.py_functionkarena tidak dapat diserialkan dan tidak didukung untuk dijalankan di TensorFlow yang didistribusikan.Gunakan
tf.data.Optionsuntuk mengontrol optimasi statis pada pipa input.
Baca juga panduan analisis kinerja tf.data untuk panduan lebih lanjut tentang mengoptimalkan saluran input Anda.
Optimalkan augmentasi data
Saat bekerja dengan data gambar, jadikan augmentasi data Anda lebih efisien dengan melakukan transmisi ke tipe data berbeda setelah menerapkan transformasi spasial, seperti membalik, memotong, memutar, dll.
Gunakan NVIDIA® DALI
Dalam beberapa kasus, seperti ketika Anda memiliki sistem dengan rasio GPU terhadap CPU yang tinggi, semua optimasi di atas mungkin tidak cukup untuk menghilangkan kemacetan dalam pemuat data yang disebabkan karena keterbatasan siklus CPU.
Jika Anda menggunakan GPU NVIDIA® untuk aplikasi computer vision dan audio deep learning, pertimbangkan untuk menggunakan Data Loading Library ( DALI ) untuk mempercepat pipeline data.
Periksa NVIDIA® DALI: Dokumentasi pengoperasian untuk daftar operasi DALI yang didukung.
Gunakan threading dan eksekusi paralel
Jalankan operasi pada beberapa thread CPU dengan tf.config.threading API untuk menjalankannya lebih cepat.
TensorFlow secara otomatis menyetel jumlah thread paralelisme secara default. Kumpulan thread yang tersedia untuk menjalankan operasi TensorFlow bergantung pada jumlah thread CPU yang tersedia.
Kontrol percepatan paralel maksimum untuk satu operasi dengan menggunakan tf.config.threading.set_intra_op_parallelism_threads . Perhatikan bahwa jika Anda menjalankan beberapa operasi secara paralel, semuanya akan berbagi kumpulan thread yang tersedia.
Jika Anda memiliki operasi non-pemblokiran independen (operasi tanpa jalur terarah di antara operasi tersebut pada grafik), gunakan tf.config.threading.set_inter_op_parallelism_threads untuk menjalankannya secara bersamaan menggunakan kumpulan thread yang tersedia.
Aneka ragam
Saat bekerja dengan model yang lebih kecil pada GPU NVIDIA®, Anda dapat mengatur tf.compat.v1.ConfigProto.force_gpu_compatible=True untuk memaksa semua tensor CPU dialokasikan dengan memori yang disematkan CUDA guna memberikan peningkatan signifikan pada performa model. Namun, berhati-hatilah saat menggunakan opsi ini untuk model yang tidak diketahui/sangat besar karena hal ini dapat berdampak negatif pada kinerja host (CPU).
Meningkatkan kinerja perangkat
Ikuti praktik terbaik yang dirinci di sini dan dalam panduan pengoptimalan performa GPU untuk mengoptimalkan performa model TensorFlow di perangkat.
Jika Anda menggunakan GPU NVIDIA, catat penggunaan GPU dan memori ke file CSV dengan menjalankan:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Konfigurasikan tata letak data
Saat bekerja dengan data yang berisi informasi saluran (seperti gambar), optimalkan format tata letak data agar saluran lebih disukai (NHWC daripada NCHW).
Format data saluran terakhir meningkatkan pemanfaatan Tensor Core dan memberikan peningkatan performa yang signifikan terutama dalam model konvolusional jika digabungkan dengan AMP. Tata letak data NCHW masih dapat dioperasikan oleh Tensor Cores, tetapi menimbulkan overhead tambahan karena operasi transpos otomatis.
Anda dapat mengoptimalkan tata letak data untuk memilih tata letak NHWC dengan menyetel data_format="channels_last" untuk lapisan seperti tf.keras.layers.Conv2D , tf.keras.layers.Conv3D , dan tf.keras.layers.RandomRotation .
Gunakan tf.keras.backend.set_image_data_format untuk menyetel format tata letak data default untuk API backend Keras.
Maksimalkan cache L2
Saat bekerja dengan GPU NVIDIA®, jalankan cuplikan kode di bawah ini sebelum loop pelatihan untuk memaksimalkan granularitas pengambilan L2 hingga 128 byte.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Konfigurasikan penggunaan thread GPU
Mode thread GPU menentukan bagaimana thread GPU digunakan.
Atur mode utas ke gpu_private untuk memastikan bahwa preprocessing tidak mencuri semua utas GPU. Ini akan mengurangi keterlambatan peluncuran kernel selama pelatihan. Anda juga dapat mengatur jumlah utas per GPU. Atur nilai -nilai ini menggunakan variabel lingkungan.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Konfigurasikan opsi memori GPU
Secara umum, tingkatkan ukuran batch dan skala model untuk lebih memanfaatkan GPU dan mendapatkan throughput yang lebih tinggi. Perhatikan bahwa meningkatkan ukuran batch akan mengubah akurasi model sehingga model perlu diskalakan dengan menyetel hiperparameter seperti tingkat pembelajaran untuk memenuhi akurasi target.
Juga, gunakan tf.config.experimental.set_memory_growth untuk memungkinkan memori GPU tumbuh untuk mencegah semua memori yang tersedia dari sepenuhnya dialokasikan ke OP yang hanya membutuhkan sebagian kecil dari memori. Ini memungkinkan proses lain yang mengonsumsi memori GPU berjalan pada perangkat yang sama.
Untuk mempelajari lebih lanjut, periksa panduan pertumbuhan memori GPU yang membatasi dalam panduan GPU untuk mempelajari lebih lanjut.
Aneka ragam
Tingkatkan ukuran mini-batch pelatihan (jumlah sampel pelatihan yang digunakan per perangkat dalam satu iterasi loop pelatihan) dengan jumlah maksimum yang cocok tanpa kesalahan keluar dari memori (OOM) pada GPU. Meningkatkan dampak ukuran batch akurasi model - jadi pastikan Anda skala model dengan menyetel hiperparameter untuk memenuhi akurasi target.
Nonaktifkan pelaporan kesalahan OOM selama alokasi tensor dalam kode produksi. Setel
report_tensor_allocations_upon_oom=Falseditf.compat.v1.RunOptions.Untuk model dengan lapisan konvolusi, hapus penambahan bias jika menggunakan normalisasi batch. Normalisasi batch menggeser nilai dengan rata -rata dan ini menghilangkan kebutuhan untuk memiliki istilah bias yang konstan.
Gunakan statistik TF untuk mengetahui seberapa efisien OP OP yang dijalankan.
Gunakan
tf.functionuntuk melakukan perhitungan dan secara opsional, aktifkanjit_compile=True(tf.function(jit_compile=True). Untuk mempelajari lebih lanjut, buka menggunakan XLA TF.Function .Minimalkan operasi python host antara langkah -langkah dan mengurangi panggilan balik. Hitung metrik setiap beberapa langkah, bukan pada setiap langkah.
Buat unit komputasi perangkat sibuk.
Kirim data ke beberapa perangkat secara paralel.
Pertimbangkan untuk menggunakan representasi numerik 16-bit , seperti
fp16-format titik mengambang setengah presisi yang ditentukan oleh IEEE-atau format bfloat16 titik mengambang otak.
Sumber daya tambahan
- Profiler TensorFlow: Tutorial Kinerja Model Profil dengan Keras dan Tensorboard di mana Anda dapat menerapkan saran dalam panduan ini.
- Profil kinerja di TensorFlow 2 berbicara dari TensorFlow Dev Summit 2020.
- Demo TensorFlow Profiler dari Tensorflow Dev Summit 2020.
Keterbatasan yang diketahui
Profiling beberapa GPU di TensorFlow 2.2 dan TensorFlow 2.3
TensorFlow 2.2 dan 2.3 mendukung beberapa profil GPU hanya untuk sistem host tunggal; Beberapa profil GPU untuk sistem multi-host tidak didukung. Untuk profil konfigurasi GPU multi-pekerja, setiap pekerja harus diprofilkan secara mandiri. Dari TensorFlow 2.4 beberapa pekerja dapat diprofilkan menggunakan tf.profiler.experimental.client.trace API.
CUDA® Toolkit 10.2 atau lebih baru diperlukan untuk membuat profil beberapa GPU. Sebagai TensorFlow 2.2 dan 2.3 Mendukung versi Toolkit CUDA® hanya hingga 10.1, Anda perlu membuat tautan simbolik ke libcudart.so.10.1 dan libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1