
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Ringkasan
Tutorial ini mendemonstrasikan augmentasi data: teknik untuk meningkatkan keragaman set pelatihan Anda dengan menerapkan transformasi acak (namun realistis), seperti rotasi gambar.
Anda akan belajar bagaimana menerapkan augmentasi data dalam dua cara:
- Gunakan lapisan prapemrosesan Keras, seperti
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlip, dantf.keras.layers.RandomRotation. - Gunakan metode
tf.image, sepertitf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_crop, dantf.image.stateless_random*.
Mempersiapkan
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Unduh kumpulan data
Tutorial ini menggunakan dataset tf_flowers . Untuk kenyamanan, unduh kumpulan data menggunakan TensorFlow Datasets . Jika Anda ingin mempelajari cara lain untuk mengimpor data, lihat tutorial memuat gambar .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Dataset bunga memiliki lima kelas.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Mari ambil gambar dari kumpulan data dan gunakan untuk mendemonstrasikan augmentasi data.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Gunakan lapisan pra-pemrosesan Keras
Mengubah ukuran dan mengubah skala
Anda dapat menggunakan lapisan prapemrosesan Keras untuk mengubah ukuran gambar ke bentuk yang konsisten (dengan tf.keras.layers.Resizing ), dan untuk mengubah skala nilai piksel (dengan tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
Anda dapat memvisualisasikan hasil penerapan lapisan ini ke gambar.
result = resize_and_rescale(image)
_ = plt.imshow(result)
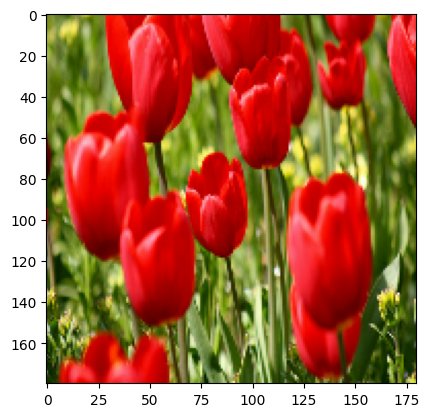
Pastikan piksel berada dalam rentang [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Augmentasi data
Anda juga dapat menggunakan lapisan prapemrosesan Keras untuk augmentasi data, seperti tf.keras.layers.RandomFlip dan tf.keras.layers.RandomRotation .
Mari buat beberapa lapisan pra-pemrosesan dan terapkan berulang kali ke gambar yang sama.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Ada berbagai lapisan prapemrosesan yang dapat Anda gunakan untuk augmentasi data termasuk tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom , dan lainnya.
Dua opsi untuk menggunakan lapisan prapemrosesan Keras
Ada dua cara Anda dapat menggunakan lapisan prapemrosesan ini, dengan pertukaran yang penting.
Opsi 1: Jadikan lapisan pra-pemrosesan bagian dari model Anda
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
Ada dua poin penting yang harus diperhatikan dalam kasus ini:
Augmentasi data akan berjalan di perangkat, secara sinkron dengan seluruh lapisan Anda, dan mendapat manfaat dari akselerasi GPU.
Saat Anda mengekspor model Anda menggunakan
model.save, lapisan prapemrosesan akan disimpan bersama dengan model Anda yang lain. Jika nanti Anda menerapkan model ini, itu akan secara otomatis menstandardisasi gambar (sesuai dengan konfigurasi lapisan Anda). Ini dapat menyelamatkan Anda dari upaya untuk mengimplementasikan kembali logika sisi server itu.
Opsi 2: Terapkan lapisan prapemrosesan ke kumpulan data Anda
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
Dengan pendekatan ini, Anda menggunakan Dataset.map untuk membuat kumpulan data yang menghasilkan kumpulan gambar yang diperbesar. Pada kasus ini:
- Augmentasi data akan terjadi secara asinkron pada CPU, dan tidak memblokir. Anda dapat tumpang tindih pelatihan model Anda di GPU dengan prapemrosesan data, menggunakan
Dataset.prefetch, yang ditunjukkan di bawah ini. - Dalam hal ini lapisan prapemrosesan tidak akan diekspor dengan model saat Anda memanggil
Model.save. Anda harus melampirkannya ke model Anda sebelum menyimpannya atau menerapkannya kembali di sisi server. Setelah pelatihan, Anda dapat memasang lapisan prapemrosesan sebelum mengekspor.
Anda dapat menemukan contoh opsi pertama di tutorial Klasifikasi gambar . Mari kita tunjukkan opsi kedua di sini.
Terapkan lapisan pra-pemrosesan ke kumpulan data
Konfigurasikan set data pelatihan, validasi, dan pengujian dengan lapisan prapemrosesan Keras yang Anda buat sebelumnya. Anda juga akan mengonfigurasi kumpulan data untuk kinerja, menggunakan pembacaan paralel dan pengambilan buffered untuk menghasilkan kumpulan dari disk tanpa I/O menjadi pemblokiran. (Pelajari lebih lanjut kinerja kumpulan data di Kinerja yang lebih baik dengan panduan tf.data API .)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
Latih seorang model
Untuk kelengkapan, Anda sekarang akan melatih model menggunakan kumpulan data yang baru saja Anda siapkan.
Model Sequential terdiri dari tiga blok konvolusi ( tf.keras.layers.Conv2D ) dengan lapisan pooling maks ( tf.keras.layers.MaxPooling2D ) di masing-masing blok. Ada lapisan yang sepenuhnya terhubung ( tf.keras.layers.Dense ) dengan 128 unit di atasnya yang diaktifkan oleh fungsi aktivasi ReLU ( 'relu' ). Model ini belum disetel untuk akurasi (tujuannya adalah untuk menunjukkan kepada Anda mekanismenya).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Pilih fungsi kehilangan tf.keras.optimizers.Adam dan tf.keras.losses.SparseCategoricalCrossentropy . Untuk melihat akurasi pelatihan dan validasi untuk setiap periode pelatihan, teruskan argumen metrics ke Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Latih untuk beberapa zaman:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Augmentasi data khusus
Anda juga dapat membuat lapisan augmentasi data khusus.
Bagian tutorial ini menunjukkan dua cara untuk melakukannya:
- Pertama, Anda akan membuat lapisan
tf.keras.layers.Lambda. Ini adalah cara yang baik untuk menulis kode ringkas. - Selanjutnya, Anda akan menulis layer baru melalui subclassing , yang memberi Anda lebih banyak kontrol.
Kedua lapisan akan secara acak membalikkan warna dalam gambar, menurut beberapa kemungkinan.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

Selanjutnya, terapkan lapisan khusus dengan mensubklasifikasikan :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Kedua lapisan ini dapat digunakan seperti yang dijelaskan pada opsi 1 dan 2 di atas.
Menggunakan tf.image
Utilitas pra-pemrosesan Keras di atas nyaman digunakan. Namun, untuk kontrol yang lebih baik, Anda dapat menulis jalur atau lapisan augmentasi data Anda sendiri menggunakan tf.data dan tf.image . (Anda mungkin juga ingin melihat TensorFlow Addons Image: Operations dan TensorFlow I/O: Color Space Conversions .)
Karena set data bunga sebelumnya dikonfigurasi dengan augmentasi data, mari impor ulang untuk memulai yang baru:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Ambil gambar untuk dikerjakan:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Mari gunakan fungsi berikut untuk memvisualisasikan dan membandingkan gambar asli dan gambar yang diperbesar secara berdampingan:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Augmentasi data
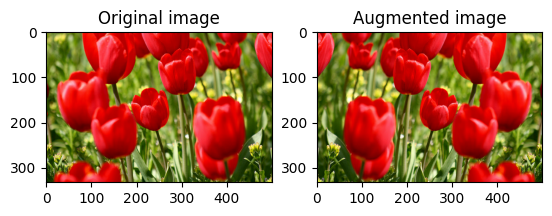
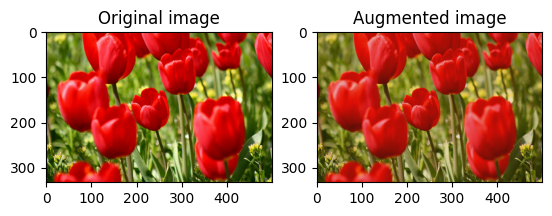
Balikkan gambar
Balikkan gambar baik secara vertikal maupun horizontal dengan tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
Skala abu-abu gambar
Anda dapat membuat gambar skala abu-abu dengan tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

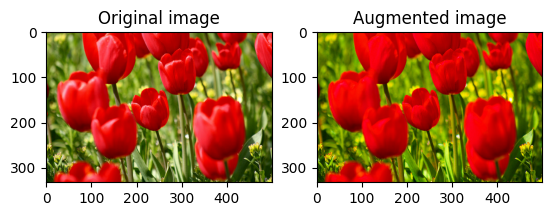
Menjenuhkan gambar
Saturasi gambar dengan tf.image.adjust_saturation dengan memberikan faktor saturasi:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
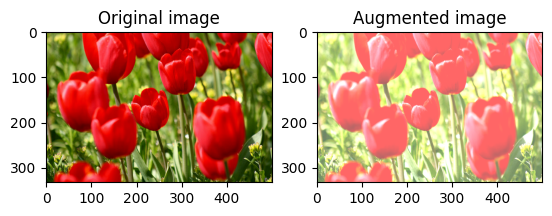
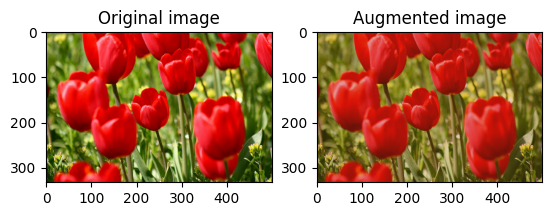
Ubah kecerahan gambar
Ubah kecerahan gambar dengan tf.image.adjust_brightness dengan memberikan faktor kecerahan:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
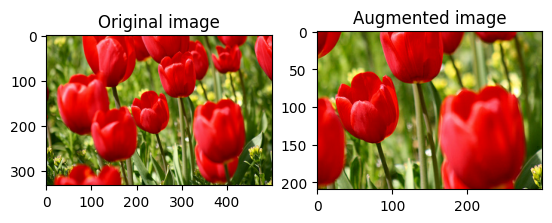
Pangkas gambar di tengah
Pangkas gambar dari tengah ke atas ke bagian gambar yang Anda inginkan menggunakan tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
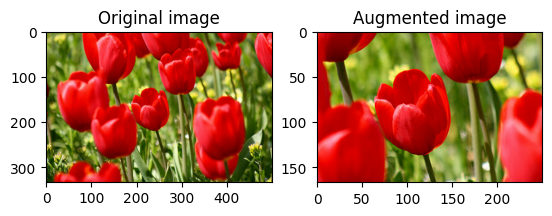
Putar gambar
Putar gambar sebesar 90 derajat dengan tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

Transformasi acak
Menerapkan transformasi acak ke gambar selanjutnya dapat membantu menggeneralisasi dan memperluas kumpulan data. tf.image API saat ini menyediakan delapan operasi gambar acak (ops):
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Operasi gambar acak ini murni fungsional: output hanya bergantung pada input. Ini membuatnya mudah digunakan dalam saluran input deterministik berkinerja tinggi. Mereka membutuhkan nilai seed menjadi masukan setiap langkah. Diberikan seed yang sama , mereka mengembalikan hasil yang sama terlepas dari berapa kali mereka dipanggil.
Di bagian berikut, Anda akan:
- Lihat contoh penggunaan operasi gambar acak untuk mengubah gambar.
- Mendemonstrasikan cara menerapkan transformasi acak ke set data pelatihan.
Ubah kecerahan gambar secara acak
Ubah kecerahan image secara acak menggunakan tf.image.stateless_random_brightness dengan memberikan faktor kecerahan dan seed . Faktor kecerahan dipilih secara acak dalam rentang [-max_delta, max_delta) dan dikaitkan dengan seed yang diberikan.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
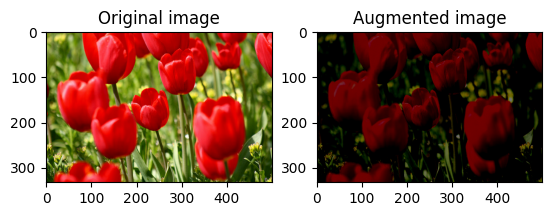
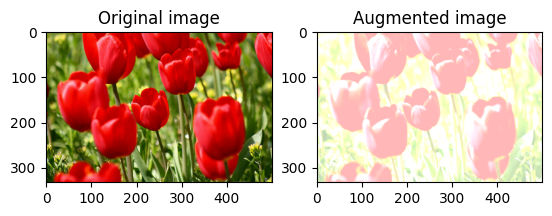
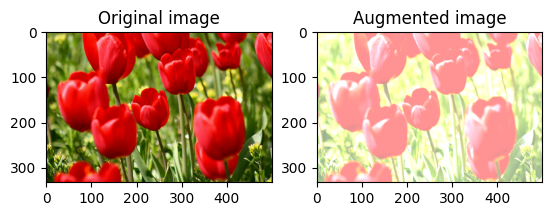
Ubah kontras gambar secara acak
Ubah kontras image secara acak menggunakan tf.image.stateless_random_contrast dengan memberikan rentang kontras dan seed . Rentang kontras dipilih secara acak dalam interval [lower, upper] dan dikaitkan dengan seed yang diberikan .
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
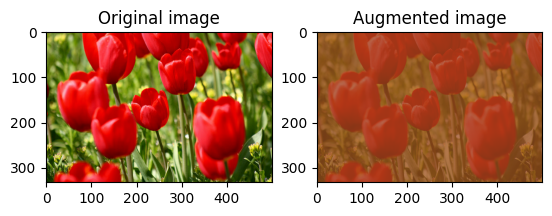
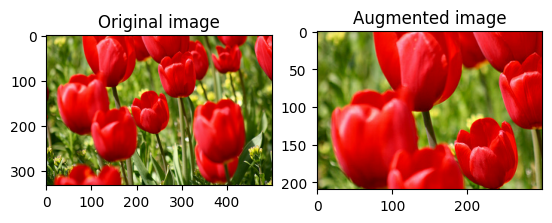
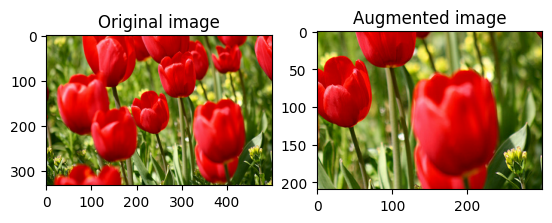
Pangkas gambar secara acak
Pangkas image secara acak menggunakan tf.image.stateless_random_crop dengan memberikan size target dan seed . Bagian yang terpotong dari image berada pada offset yang dipilih secara acak dan dikaitkan dengan seed yang diberikan .
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
Terapkan augmentasi ke kumpulan data
Pertama-tama, unduh dataset gambar lagi jika diubah di bagian sebelumnya.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Selanjutnya, tentukan fungsi utilitas untuk mengubah ukuran dan mengubah skala gambar. Fungsi ini akan digunakan dalam menyatukan ukuran dan skala gambar dalam dataset:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Mari kita juga mendefinisikan fungsi augment yang dapat menerapkan transformasi acak ke gambar. Fungsi ini akan digunakan pada dataset pada langkah berikutnya.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Opsi 1: Menggunakan tf.data.experimental.Counter
Buat objek tf.data.experimental.Counter (sebut saja counter ) dan Dataset.zip dataset dengan (counter, counter) . Ini akan memastikan bahwa setiap gambar dalam kumpulan data dikaitkan dengan nilai unik (berbentuk (2,) ) berdasarkan counter yang nantinya dapat diteruskan ke fungsi augment sebagai nilai seed untuk transformasi acak.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
Memetakan fungsi augment ke set data pelatihan:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Opsi 2: Menggunakan tf.random.Generator
- Buat objek
tf.random.Generatordengan nilaiseedawal. Memanggil fungsimake_seedspada objek generator yang sama selalu mengembalikan nilaiseedbaru yang unik. - Tentukan fungsi pembungkus yang: 1) memanggil fungsi
make_seeds; dan 2) meneruskan nilaiseedyang baru dibuat ke dalam fungsiaugmentuntuk transformasi acak.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
Petakan fungsi wrapper f ke set data pelatihan, dan fungsi resize_and_rescale —ke set validasi dan pengujian:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Kumpulan data ini sekarang dapat digunakan untuk melatih model seperti yang ditunjukkan sebelumnya.
Langkah selanjutnya
Tutorial ini mendemonstrasikan augmentasi data menggunakan lapisan preprocessing Keras dan tf.image .
- Untuk mempelajari cara menyertakan lapisan prapemrosesan di dalam model Anda, lihat tutorial Klasifikasi gambar .
- Anda mungkin juga tertarik untuk mempelajari bagaimana lapisan prapemrosesan dapat membantu Anda mengklasifikasikan teks, seperti yang ditunjukkan dalam tutorial klasifikasi teks Dasar .
- Anda dapat mempelajari lebih lanjut tentang
tf.datadalam panduan ini , dan Anda dapat mempelajari cara mengkonfigurasi saluran input Anda untuk kinerja di sini .