
| | |  GitHub에서 보기 GitHub에서 보기 | | |
이 노트북은 TensorFlow Hub의 CropNet 모델을 TFDS의 데이터 세트 또는 자체 작물 질병 감지 데이터 세트에서 미세 조정 하는 방법을 보여줍니다.
당신은:
- TFDS 카사바 데이터 세트 또는 자체 데이터 로드
- 더 강력한 모델을 얻기 위해 알려지지 않은(음수) 예제로 데이터를 보강하십시오.
- 데이터에 이미지 확대 적용
- TF Hub에서 CropNet 모델 로드 및 미세 조정
- Task Library , MLKit 또는 TFLite 를 사용하여 앱에 직접 배포할 준비가 된 TFLite 모델 내보내기
가져오기 및 종속성
시작하기 전에 Model Maker 및 최신 버전의 TensorFlow Datasets와 같이 필요한 일부 종속성을 설치해야 합니다.
pip install --use-deprecated=legacy-resolver tflite-model-makerpip install -U tensorflow-datasets
import matplotlib.pyplot as plt
import os
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.lite.model_maker.core.export_format import ExportFormat
from tensorflow_examples.lite.model_maker.core.task import image_preprocessing
from tflite_model_maker import image_classifier
from tflite_model_maker import ImageClassifierDataLoader
from tflite_model_maker.image_classifier import ModelSpec
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.5.0 and strictly below 2.8.0 (nightly versions are not supported). The versions of TensorFlow you are currently using is 2.8.0-rc1 and is not supported. Some things might work, some things might not. If you were to encounter a bug, do not file an issue. If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version. You can find the compatibility matrix in TensorFlow Addon's readme: https://github.com/tensorflow/addons UserWarning, /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/numba/core/errors.py:154: UserWarning: Insufficiently recent colorama version found. Numba requires colorama >= 0.3.9 warnings.warn(msg)
미세 조정할 TFDS 데이터 세트 로드
TFDS에서 공개적으로 사용 가능한 카사바 잎 질병 데이터 세트 를 사용할 수 있습니다.
tfds_name = 'cassava'
(ds_train, ds_validation, ds_test), ds_info = tfds.load(
name=tfds_name,
split=['train', 'validation', 'test'],
with_info=True,
as_supervised=True)
TFLITE_NAME_PREFIX = tfds_name
또는 자체 데이터를 로드하여 미세 조정할 수 있습니다.
TFDS 데이터 세트를 사용하는 대신 자체 데이터를 학습할 수도 있습니다. 이 코드 스니펫은 사용자 정의 데이터세트를 로드하는 방법을 보여줍니다. 지원되는 데이터 구조는 이 링크를 참조하십시오. 여기에 공개적으로 사용 가능한 카사바 잎 질병 데이터 세트 를 사용하여 예제가 제공됩니다.
# data_root_dir = tf.keras.utils.get_file(
# 'cassavaleafdata.zip',
# 'https://storage.googleapis.com/emcassavadata/cassavaleafdata.zip',
# extract=True)
# data_root_dir = os.path.splitext(data_root_dir)[0] # Remove the .zip extension
# builder = tfds.ImageFolder(data_root_dir)
# ds_info = builder.info
# ds_train = builder.as_dataset(split='train', as_supervised=True)
# ds_validation = builder.as_dataset(split='validation', as_supervised=True)
# ds_test = builder.as_dataset(split='test', as_supervised=True)
기차 분할에서 샘플 시각화
이미지 샘플 및 해당 레이블에 대한 클래스 ID와 클래스 이름을 포함하는 데이터 세트의 몇 가지 예를 살펴보겠습니다.
_ = tfds.show_examples(ds_train, ds_info)

TFDS 데이터 세트에서 알 수 없는 예시로 사용할 이미지 추가
학습 데이터 세트에 알 수 없는(음수) 예제를 추가하고 알 수 없는 클래스 레이블 번호를 새로 할당합니다. 목표는 실제로(예: 현장에서) 사용될 때 예상치 못한 것을 볼 때 "알 수 없음"을 예측하는 옵션이 있는 모델을 갖는 것입니다.
아래에서 알 수 없는 추가 이미지를 샘플링하는 데 사용할 데이터 세트 목록을 볼 수 있습니다. 다양성을 높이기 위해 완전히 다른 3개의 데이터 세트가 포함되어 있습니다. 그 중 하나는 콩 잎 질병 데이터 세트이므로 모델은 카사바 이외의 병든 식물에 노출됩니다.
UNKNOWN_TFDS_DATASETS = [{
'tfds_name': 'imagenet_v2/matched-frequency',
'train_split': 'test[:80%]',
'test_split': 'test[80%:]',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'oxford_flowers102',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}, {
'tfds_name': 'beans',
'train_split': 'train',
'test_split': 'test',
'num_examples_ratio_to_normal': 1.0,
}]
UNKNOWN 데이터세트도 TFDS에서 로드됩니다.
# Load unknown datasets.
weights = [
spec['num_examples_ratio_to_normal'] for spec in UNKNOWN_TFDS_DATASETS
]
num_unknown_train_examples = sum(
int(w * ds_train.cardinality().numpy()) for w in weights)
ds_unknown_train = tf.data.Dataset.sample_from_datasets([
tfds.load(
name=spec['tfds_name'], split=spec['train_split'],
as_supervised=True).repeat(-1) for spec in UNKNOWN_TFDS_DATASETS
], weights).take(num_unknown_train_examples)
ds_unknown_train = ds_unknown_train.apply(
tf.data.experimental.assert_cardinality(num_unknown_train_examples))
ds_unknown_tests = [
tfds.load(
name=spec['tfds_name'], split=spec['test_split'], as_supervised=True)
for spec in UNKNOWN_TFDS_DATASETS
]
ds_unknown_test = ds_unknown_tests[0]
for ds in ds_unknown_tests[1:]:
ds_unknown_test = ds_unknown_test.concatenate(ds)
# All examples from the unknown datasets will get a new class label number.
num_normal_classes = len(ds_info.features['label'].names)
unknown_label_value = tf.convert_to_tensor(num_normal_classes, tf.int64)
ds_unknown_train = ds_unknown_train.map(lambda image, _:
(image, unknown_label_value))
ds_unknown_test = ds_unknown_test.map(lambda image, _:
(image, unknown_label_value))
# Merge the normal train dataset with the unknown train dataset.
weights = [
ds_train.cardinality().numpy(),
ds_unknown_train.cardinality().numpy()
]
ds_train_with_unknown = tf.data.Dataset.sample_from_datasets(
[ds_train, ds_unknown_train], [float(w) for w in weights])
ds_train_with_unknown = ds_train_with_unknown.apply(
tf.data.experimental.assert_cardinality(sum(weights)))
print((f"Added {ds_unknown_train.cardinality().numpy()} negative examples."
f"Training dataset has now {ds_train_with_unknown.cardinality().numpy()}"
' examples in total.'))
Added 16968 negative examples.Training dataset has now 22624 examples in total.
보강 적용
모든 이미지에 대해 더 다양하게 만들기 위해 다음과 같은 변경 사항을 적용합니다.
- 명도
- 차이
- 포화
- 색조
- 수확고
이러한 유형의 증강은 이미지 입력의 변화에 대해 모델을 더욱 강력하게 만드는 데 도움이 됩니다.
def random_crop_and_random_augmentations_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
image = tf.image.random_brightness(image, 0.2)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
return image
def random_crop_fn(image):
# preprocess_for_train does random crop and resize internally.
image = image_preprocessing.preprocess_for_train(image)
return image
def resize_and_center_crop_fn(image):
image = tf.image.resize(image, (256, 256))
image = image[16:240, 16:240]
return image
no_augment_fn = lambda image: image
train_augment_fn = lambda image, label: (
random_crop_and_random_augmentations_fn(image), label)
eval_augment_fn = lambda image, label: (resize_and_center_crop_fn(image), label)
기능 보강을 적용하기 위해 Dataset 클래스의 map 메소드를 사용합니다.
ds_train_with_unknown = ds_train_with_unknown.map(train_augment_fn)
ds_validation = ds_validation.map(eval_augment_fn)
ds_test = ds_test.map(eval_augment_fn)
ds_unknown_test = ds_unknown_test.map(eval_augment_fn)
INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use default resize_bicubic. INFO:tensorflow:Use customized resize method bilinear INFO:tensorflow:Use customized resize method bilinear
데이터를 Model Maker 친화적인 형식으로 래핑
Model Maker와 함께 이러한 데이터 세트를 사용하려면 ImageClassifierDataLoader 클래스에 있어야 합니다.
label_names = ds_info.features['label'].names + ['UNKNOWN']
train_data = ImageClassifierDataLoader(ds_train_with_unknown,
ds_train_with_unknown.cardinality(),
label_names)
validation_data = ImageClassifierDataLoader(ds_validation,
ds_validation.cardinality(),
label_names)
test_data = ImageClassifierDataLoader(ds_test, ds_test.cardinality(),
label_names)
unknown_test_data = ImageClassifierDataLoader(ds_unknown_test,
ds_unknown_test.cardinality(),
label_names)
훈련 실행
TensorFlow Hub 에는 Transfer Learning에 사용할 수 있는 여러 모델이 있습니다.
여기에서 하나를 선택할 수 있으며 더 나은 결과를 얻기 위해 다른 것들을 계속 실험할 수도 있습니다.
더 많은 모델을 시도하고 싶다면 이 컬렉션 에서 추가할 수 있습니다.
기본 모델 선택
model_name = 'mobilenet_v3_large_100_224'
map_model_name = {
'cropnet_cassava':
'https://tfhub.dev/google/cropnet/feature_vector/cassava_disease_V1/1',
'cropnet_concat':
'https://tfhub.dev/google/cropnet/feature_vector/concat/1',
'cropnet_imagenet':
'https://tfhub.dev/google/cropnet/feature_vector/imagenet/1',
'mobilenet_v3_large_100_224':
'https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5',
}
model_handle = map_model_name[model_name]
모델을 미세 조정하려면 Model Maker를 사용합니다. 이렇게 하면 모델을 교육한 후 TFLite로 변환하기 때문에 전체 솔루션이 더 쉬워집니다.
Model Maker는 이 변환을 가능한 한 최상의 변환으로 만들고 나중에 장치에 모델을 쉽게 배포하는 데 필요한 모든 정보를 제공합니다.
모델 사양은 모델 제작자에게 사용하려는 기본 모델을 알려주는 방법입니다.
image_model_spec = ModelSpec(uri=model_handle)
여기서 중요한 세부 사항 중 하나는 훈련 중에 기본 모델을 미세 조정하도록 train_whole_model 을 설정하는 것입니다. 이로 인해 프로세스가 느려지지만 최종 모델의 정확도는 더 높아집니다. shuffle 을 설정하면 모델이 모델 학습을 위한 모범 사례인 무작위 섞인 순서로 데이터를 볼 수 있습니다.
model = image_classifier.create(
train_data,
model_spec=image_model_spec,
batch_size=128,
learning_rate=0.03,
epochs=5,
shuffle=True,
train_whole_model=True,
validation_data=validation_data)
INFO:tensorflow:Retraining the models...
INFO:tensorflow:Retraining the models...
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hub_keras_layer_v1v2 (HubKe (None, 1280) 4226432
rasLayerV1V2)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 6) 7686
=================================================================
Total params: 4,234,118
Trainable params: 4,209,718
Non-trainable params: 24,400
_________________________________________________________________
None
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
176/176 [==============================] - 120s 488ms/step - loss: 0.8874 - accuracy: 0.9148 - val_loss: 1.1721 - val_accuracy: 0.7935
Epoch 2/5
176/176 [==============================] - 84s 444ms/step - loss: 0.7907 - accuracy: 0.9532 - val_loss: 1.0761 - val_accuracy: 0.8100
Epoch 3/5
176/176 [==============================] - 85s 441ms/step - loss: 0.7743 - accuracy: 0.9582 - val_loss: 1.0305 - val_accuracy: 0.8444
Epoch 4/5
176/176 [==============================] - 79s 409ms/step - loss: 0.7653 - accuracy: 0.9611 - val_loss: 1.0166 - val_accuracy: 0.8422
Epoch 5/5
176/176 [==============================] - 75s 402ms/step - loss: 0.7534 - accuracy: 0.9665 - val_loss: 0.9988 - val_accuracy: 0.8555
테스트 분할에서 모델 평가
model.evaluate(test_data)
59/59 [==============================] - 10s 81ms/step - loss: 0.9956 - accuracy: 0.8594 [0.9956456422805786, 0.8594164252281189]
미세 조정된 모델을 더 잘 이해하려면 정오분류표를 분석하는 것이 좋습니다. 이것은 한 클래스가 다른 클래스로 예측되는 빈도를 보여줍니다.
def predict_class_label_number(dataset):
"""Runs inference and returns predictions as class label numbers."""
rev_label_names = {l: i for i, l in enumerate(label_names)}
return [
rev_label_names[o[0][0]]
for o in model.predict_top_k(dataset, batch_size=128)
]
def show_confusion_matrix(cm, labels):
plt.figure(figsize=(10, 8))
sns.heatmap(cm, xticklabels=labels, yticklabels=labels,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
confusion_mtx = tf.math.confusion_matrix(
list(ds_test.map(lambda x, y: y)),
predict_class_label_number(test_data),
num_classes=len(label_names))
show_confusion_matrix(confusion_mtx, label_names)
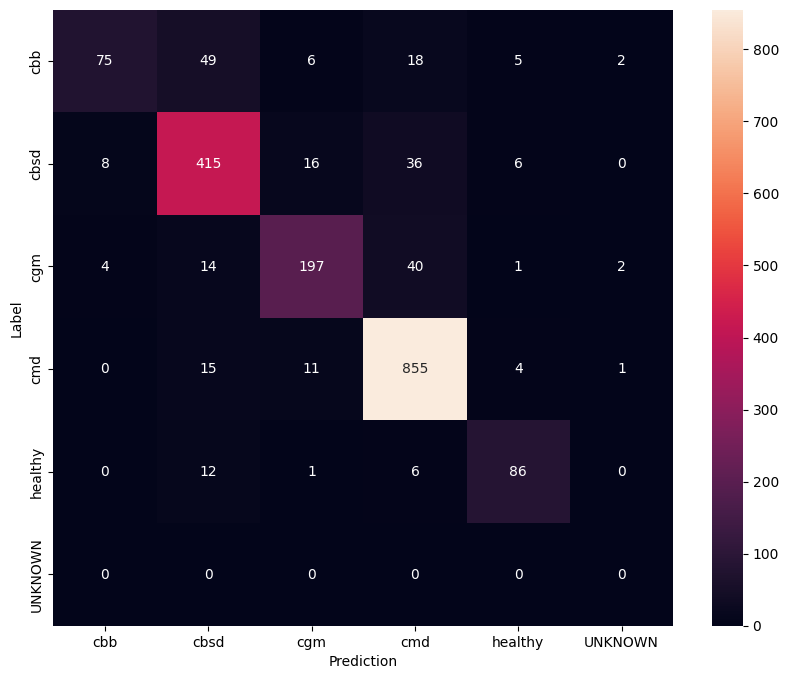
알려지지 않은 테스트 데이터에 대한 모델 평가
이 평가에서 우리는 모델이 거의 1의 정확도를 가질 것으로 예상합니다. 모델이 테스트되는 모든 이미지는 일반 데이터 세트와 관련이 없으므로 모델이 "알 수 없음" 클래스 레이블을 예측할 것으로 예상합니다.
model.evaluate(unknown_test_data)
259/259 [==============================] - 36s 127ms/step - loss: 0.6777 - accuracy: 0.9996 [0.677702784538269, 0.9996375441551208]
정오분류표를 인쇄합니다.
unknown_confusion_mtx = tf.math.confusion_matrix(
list(ds_unknown_test.map(lambda x, y: y)),
predict_class_label_number(unknown_test_data),
num_classes=len(label_names))
show_confusion_matrix(unknown_confusion_mtx, label_names)
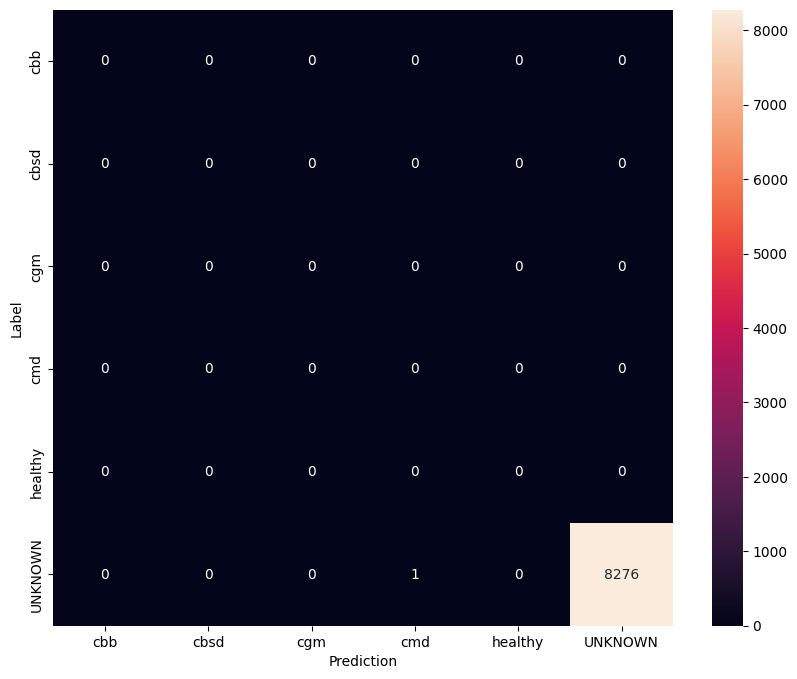
모델을 TFLite 및 SavedModel로 내보내기
이제 기기에 배포하고 TensorFlow에서 추론에 사용하기 위해 훈련된 모델을 TFLite 및 SavedModel 형식으로 내보낼 수 있습니다.
tflite_filename = f'{TFLITE_NAME_PREFIX}_model_{model_name}.tflite'
model.export(export_dir='.', tflite_filename=tflite_filename)
2022-01-26 12:25:57.742415: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
INFO:tensorflow:Assets written to: /tmp/tmppliqmyki/assets
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/lite/python/convert.py:746: UserWarning: Statistics for quantized inputs were expected, but not specified; continuing anyway.
warnings.warn("Statistics for quantized inputs were expected, but not "
2022-01-26 12:26:07.247752: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:357] Ignored output_format.
2022-01-26 12:26:07.247806: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored drop_control_dependency.
INFO:tensorflow:Label file is inside the TFLite model with metadata.
fully_quantize: 0, inference_type: 6, input_inference_type: 3, output_inference_type: 3
INFO:tensorflow:Label file is inside the TFLite model with metadata.
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:Saving labels in /tmp/tmp_k_gr9mu/labels.txt
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
INFO:tensorflow:TensorFlow Lite model exported successfully: ./cassava_model_mobilenet_v3_large_100_224.tflite
# Export saved model version.
model.export(export_dir='.', export_format=ExportFormat.SAVED_MODEL)
INFO:tensorflow:Assets written to: ./saved_model/assets INFO:tensorflow:Assets written to: ./saved_model/assets
다음 단계
방금 훈련한 모델을 모바일 장치에서 사용할 수 있으며 현장에 배포할 수도 있습니다!
모델을 다운로드하려면 colab 왼쪽에 있는 파일 메뉴의 폴더 아이콘을 클릭하고 다운로드 옵션을 선택합니다.
여기에 사용된 동일한 기술을 사용 사례 또는 다른 유형의 이미지 분류 작업에 더 적합할 수 있는 다른 식물 질병 작업에 적용할 수 있습니다. Android 앱에서 후속 작업을 수행하고 배포하려는 경우 이 Android 빠른 시작 가이드 를 계속 진행할 수 있습니다.