
เล่นเกมกระดานกับตัวแทน ซึ่งได้รับการฝึกฝนโดยใช้การเรียนรู้แบบเสริมกำลังและปรับใช้กับ TensorFlow Lite
เริ่ม
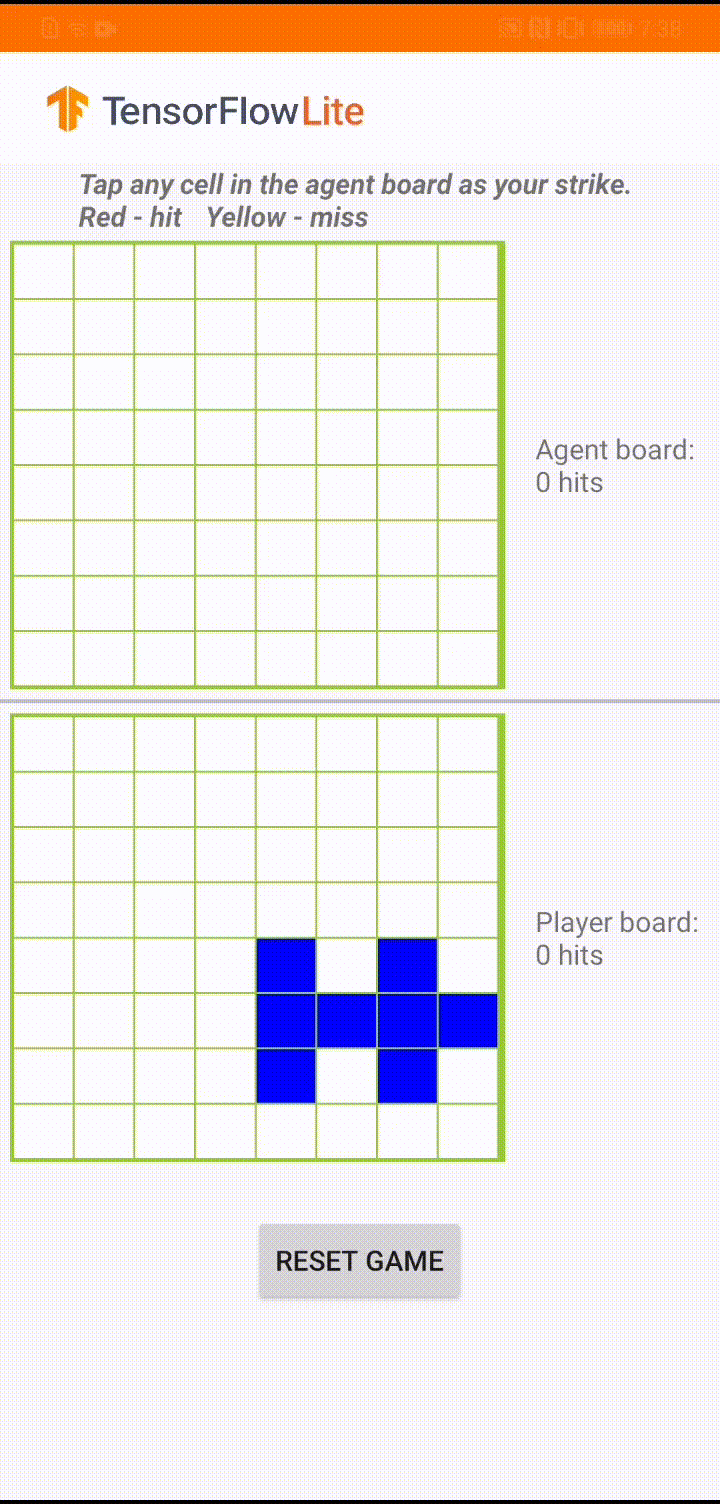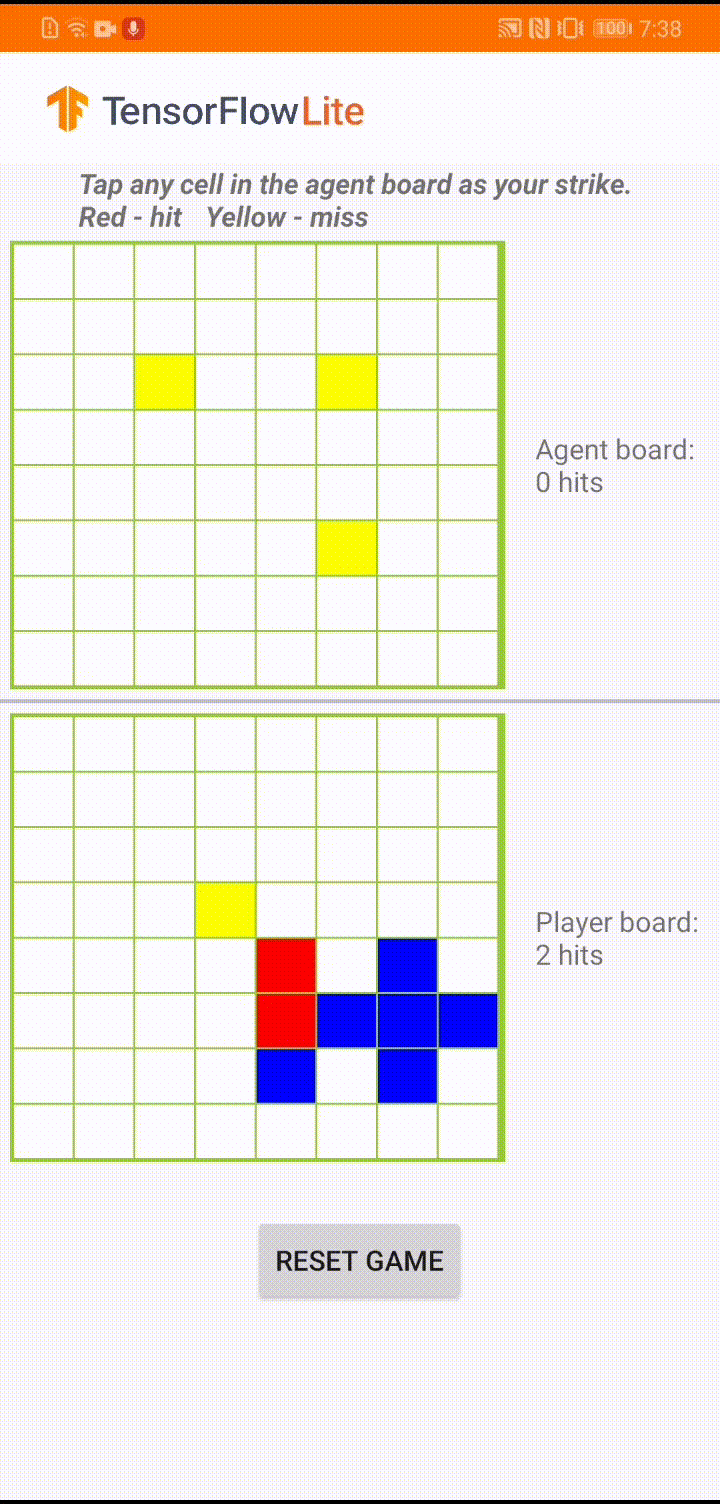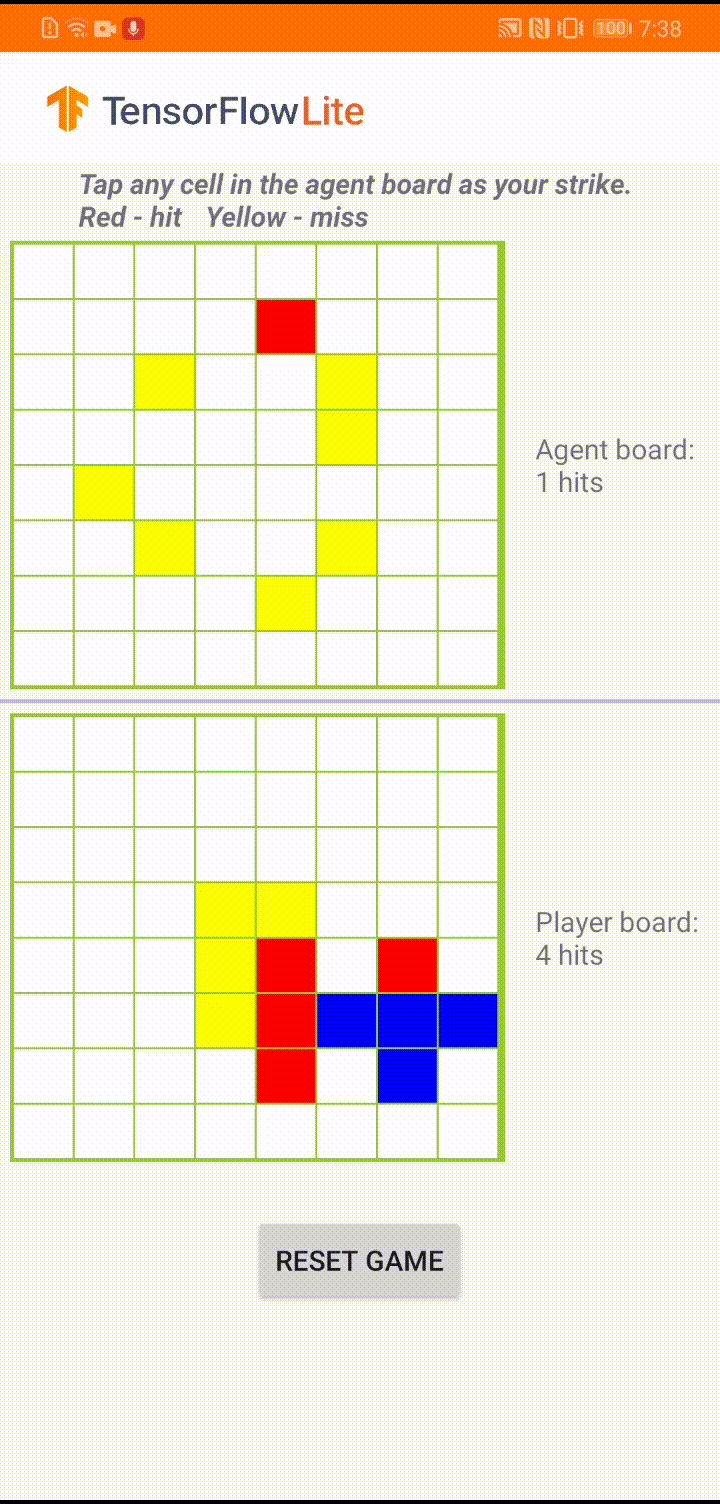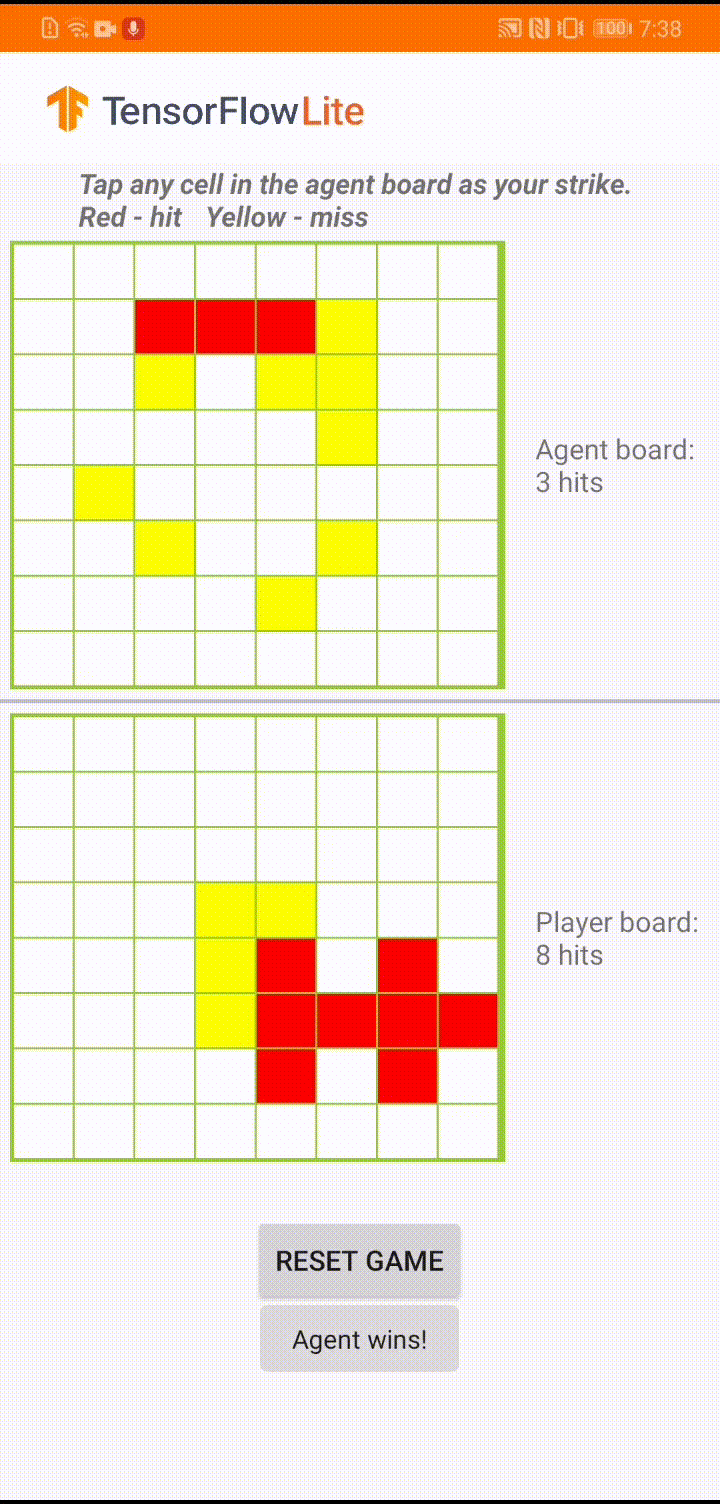
หากคุณยังใหม่กับ TensorFlow Lite และกำลังใช้งาน Android เราขอแนะนำให้สำรวจแอปพลิเคชันตัวอย่างต่อไปนี้ที่สามารถช่วยคุณเริ่มต้นได้
หากคุณใช้แพลตฟอร์มอื่นที่ไม่ใช่ Android หรือคุณคุ้นเคยกับ TensorFlow Lite API อยู่แล้ว คุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมของเราได้
มันทำงานอย่างไร
โมเดลนี้สร้างขึ้นเพื่อให้ตัวแทนเกมเล่นเกมกระดานขนาดเล็กที่เรียกว่า 'Plane Strike' สำหรับการแนะนำเกมนี้และกฎกติกาโดยย่อ โปรดดูที่ README นี้
ใต้ UI ของแอป เราได้สร้างตัวแทนที่เล่นกับผู้เล่นที่เป็นมนุษย์ เอเจนต์คือ MLP 3 เลเยอร์ที่ใช้สถานะของบอร์ดเป็นอินพุตและเอาต์พุตคะแนนที่คาดการณ์ไว้สำหรับแต่ละเซลล์ของบอร์ดที่เป็นไปได้ 64 เซลล์ โมเดลนี้ได้รับการฝึกฝนโดยใช้การไล่ระดับนโยบาย (REINFORCE) และคุณสามารถค้นหารหัสการฝึก ได้ที่นี่ หลังจากฝึกอบรมตัวแทนแล้ว เราจะแปลงโมเดลเป็น TFLite และปรับใช้ในแอป Android
ในระหว่างการเล่นเกมจริงในแอป Android เมื่อถึงตาของตัวแทนที่จะดำเนินการ ตัวแทนจะดูสถานะกระดานของผู้เล่นที่เป็นมนุษย์ (กระดานที่ด้านล่าง) ซึ่งมีข้อมูลเกี่ยวกับการโจมตีที่สำเร็จและไม่สำเร็จก่อนหน้านี้ (ตีและพลาด) และใช้โมเดลที่ได้รับการฝึกมาเพื่อคาดเดาว่าจะโจมตีจุดไหนต่อไป เพื่อให้สามารถจบเกมได้ก่อนที่ผู้เล่นจะทำ
เกณฑ์มาตรฐานประสิทธิภาพ
หมายเลขเกณฑ์มาตรฐานประสิทธิภาพสร้างขึ้นด้วยเครื่องมือที่อธิบายไว้ ที่นี่
| ชื่อรุ่น | ขนาดโมเดล | อุปกรณ์ | ซีพียู |
|---|---|---|---|
| การไล่ระดับนโยบาย | 84 กิโลไบต์ | พิกเซล 3 (Android 10) | 0.01ms* |
| พิกเซล 4 (Android 10) | 0.01ms* |
* ใช้ไปแล้ว 1 เส้น
อินพุต
โมเดลยอมรับ 3-D float32 Tensor ของ (1, 8, 8) เป็นสถานะของบอร์ด
เอาท์พุต
แบบจำลองส่งคืนเทนเซอร์รูปร่าง 2 มิติ float32 (1,64) เป็นคะแนนที่คาดการณ์ไว้สำหรับแต่ละตำแหน่งการโจมตีที่เป็นไปได้ 64 ตำแหน่ง
ฝึกโมเดลของคุณเอง
คุณสามารถฝึกโมเดลของคุณเองสำหรับบอร์ดที่ใหญ่ขึ้น/เล็กลงได้โดยเปลี่ยนพารามิเตอร์ BOARD_SIZE ใน โค้ดการฝึก