
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ใน featurization กวดวิชา ที่เรารวมคุณสมบัติหลายในรูปแบบของเรา แต่รุ่นประกอบด้วยเพียงชั้นฝัง เราสามารถเพิ่มเลเยอร์ที่มีความหนาแน่นมากขึ้นให้กับโมเดลของเราเพื่อเพิ่มพลังในการแสดงออก
โดยทั่วไป แบบจำลองที่ลึกกว่าสามารถเรียนรู้รูปแบบที่ซับซ้อนกว่าแบบจำลองที่ตื้นกว่า ตัวอย่างเช่นเรา รูปแบบการใช้ ประกอบด้วยรหัสผู้ใช้และการประทับเวลาในการตั้งค่าการใช้รูปแบบที่จุดในเวลา โมเดลแบบตื้น (เช่น เลเยอร์การฝังชั้นเดียว) อาจสามารถเรียนรู้ความสัมพันธ์ที่ง่ายที่สุดระหว่างคุณลักษณะและภาพยนตร์เหล่านั้น: ภาพยนตร์ที่กำหนดจะได้รับความนิยมมากที่สุดในช่วงเวลาที่ออกฉาย และผู้ใช้รายหนึ่งมักชอบภาพยนตร์สยองขวัญมากกว่าเรื่องตลก ในการจับภาพความสัมพันธ์ที่ซับซ้อนมากขึ้น เช่น ความชอบของผู้ใช้ที่เปลี่ยนแปลงไปตามเวลา เราอาจต้องใช้แบบจำลองที่ลึกกว่าซึ่งมีเลเยอร์หนาแน่นซ้อนกันหลายชั้น
แน่นอนว่าโมเดลที่ซับซ้อนก็มีข้อเสียเช่นกัน อย่างแรกคือต้นทุนในการคำนวณ เนื่องจากรุ่นที่มีขนาดใหญ่กว่าต้องการทั้งหน่วยความจำที่มากขึ้นและการคำนวณที่มากขึ้นเพื่อให้พอดีและให้บริการ ประการที่สองคือข้อกำหนดสำหรับข้อมูลเพิ่มเติม: โดยทั่วไป จำเป็นต้องมีข้อมูลการฝึกอบรมเพิ่มเติมเพื่อใช้ประโยชน์จากแบบจำลองที่ลึกกว่า ด้วยพารามิเตอร์ที่มากขึ้น แบบจำลองเชิงลึกอาจไม่เหมาะสมหรือเพียงแค่จดจำตัวอย่างการฝึก แทนที่จะเรียนรู้ฟังก์ชันที่สามารถสรุปได้ สุดท้าย การฝึกโมเดลเชิงลึกอาจยากขึ้น และต้องใช้ความระมัดระวังมากขึ้นในการเลือกการตั้งค่า เช่น การทำให้เป็นมาตรฐานและอัตราการเรียนรู้
หาสถาปัตยกรรมที่ดีสำหรับระบบ recommender โลกแห่งความจริงเป็นศิลปะที่ซับซ้อนต้องใช้สัญชาตญาณที่ดีและระมัดระวังใน การปรับจูน hyperparameter ตัวอย่างเช่น ปัจจัยต่างๆ เช่น ความลึกและความกว้างของโมเดล ฟังก์ชันการเปิดใช้งาน อัตราการเรียนรู้ และตัวเพิ่มประสิทธิภาพสามารถเปลี่ยนแปลงประสิทธิภาพของโมเดลได้อย่างสิ้นเชิง ตัวเลือกการสร้างแบบจำลองนั้นซับซ้อนยิ่งขึ้นด้วยข้อเท็จจริงที่ว่าตัวชี้วัดการประเมินออฟไลน์ที่ดีอาจไม่สอดคล้องกับประสิทธิภาพออนไลน์ที่ดี และการเลือกสิ่งที่จะปรับให้เหมาะสมนั้นมักจะมีความสำคัญมากกว่าการเลือกตัวแบบเอง
อย่างไรก็ตาม ความพยายามในการสร้างและปรับแต่งโมเดลขนาดใหญ่ขึ้นอย่างละเอียดมักจะได้ผลดี ในบทช่วยสอนนี้ เราจะอธิบายวิธีสร้างแบบจำลองการดึงข้อมูลเชิงลึกโดยใช้ตัวแนะนำ TensorFlow เราจะทำเช่นนี้โดยการสร้างแบบจำลองที่ซับซ้อนมากขึ้นเรื่อยๆ เพื่อดูว่าสิ่งนี้ส่งผลต่อประสิทธิภาพของแบบจำลองอย่างไร
เบื้องต้น
ก่อนอื่นเรานำเข้าแพ็คเกจที่จำเป็น
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
ในการกวดวิชานี้เราจะใช้รูปแบบจาก featurization กวดวิชา เพื่อสร้าง embeddings ดังนั้น เราจะใช้เฉพาะคุณสมบัติ ID ผู้ใช้ เวลาประทับ และชื่อภาพยนตร์เท่านั้น
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
เรายังดูแลทำความสะอาดเพื่อเตรียมคำศัพท์เกี่ยวกับคุณลักษณะอีกด้วย
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
คำจำกัดความของโมเดล
แบบสอบถามรุ่น
เราเริ่มต้นด้วยรูปแบบที่ผู้ใช้กำหนดไว้ใน featurization กวดวิชา เป็นชั้นแรกของรูปแบบของเรามอบหมายกับการแปลงตัวอย่างการป้อนข้อมูลดิบให้เป็น embeddings คุณลักษณะ
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
การกำหนดโมเดลที่ลึกขึ้นจะทำให้เราต้องซ้อนเลเยอร์โหมดที่ด้านบนของอินพุตแรกนี้ สแต็กเลเยอร์ที่แคบลงเรื่อยๆ คั่นด้วยฟังก์ชันการเปิดใช้งาน เป็นรูปแบบทั่วไป:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
เนื่องจากพลังการแสดงออกของแบบจำลองเชิงเส้นลึกไม่ได้ยิ่งใหญ่ไปกว่าแบบจำลองเชิงเส้นตรงตื้น เราจึงใช้การเปิดใช้งาน ReLU สำหรับทุกคนยกเว้นเลเยอร์ที่ซ่อนอยู่สุดท้าย เลเยอร์ที่ซ่อนอยู่สุดท้ายไม่ได้ใช้ฟังก์ชันการเปิดใช้งานใดๆ การใช้ฟังก์ชันการเปิดใช้งานจะจำกัดพื้นที่เอาต์พุตของการฝังขั้นสุดท้าย และอาจส่งผลเสียต่อประสิทธิภาพของโมเดล ตัวอย่างเช่น หากใช้ ReLU ในเลเยอร์การฉายภาพ ส่วนประกอบทั้งหมดในการฝังเอาต์พุตจะไม่เป็นค่าลบ
เราจะลองทำสิ่งที่คล้ายกันที่นี่ เพื่อให้การทดลองกับความลึกต่างๆ เป็นเรื่องง่าย ให้กำหนดแบบจำลองที่มีการกำหนดความลึก (และความกว้าง) โดยชุดของพารามิเตอร์ตัวสร้าง
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizes พารามิเตอร์ช่วยให้เรามีความลึกและความกว้างของรูปแบบ เราสามารถเปลี่ยนแปลงได้เพื่อทดลองกับแบบจำลองที่ตื้นขึ้นหรือลึกขึ้น
รูปแบบผู้สมัคร
เราสามารถนำแนวทางเดียวกันนี้มาใช้กับโมเดลภาพยนตร์ได้ อีกครั้งที่เราเริ่มต้นด้วย MovieModel จาก featurization กวดวิชา:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
และขยายด้วยเลเยอร์ที่ซ่อนอยู่:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
รุ่นรวม
กับทั้ง QueryModel และ CandidateModel กำหนดเราสามารถใส่กันรูปแบบการทำงานร่วมกันและดำเนินการสูญเสียและการวัดตรรกะของเรา เพื่อให้ง่ายขึ้น เราจะบังคับใช้ว่าโครงสร้างแบบจำลองจะเหมือนกันในแบบสอบถามและแบบจำลองตัวเลือก
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
ฝึกโมเดล
เตรียมข้อมูล
ก่อนอื่นเราแบ่งข้อมูลออกเป็นชุดฝึกอบรมและชุดทดสอบ
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
แบบตื้น
เราพร้อมแล้วที่จะลองใช้โมเดลแรก แบบตื้น!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
สิ่งนี้ทำให้เรามีความแม่นยำสูงสุด 100 อันดับแรกที่ประมาณ 0.27 เราสามารถใช้สิ่งนี้เป็นจุดอ้างอิงในการประเมินแบบจำลองเชิงลึกได้
โมเดลที่ลึกกว่า
แล้วโมเดลลึกที่มีสองชั้นล่ะ?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
ความแม่นยำที่นี่คือ 0.29 ค่อนข้างดีกว่ารุ่นตื้นเล็กน้อย
เราสามารถพลอตเส้นโค้งความแม่นยำในการตรวจสอบเพื่อแสดงให้เห็นสิ่งนี้:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
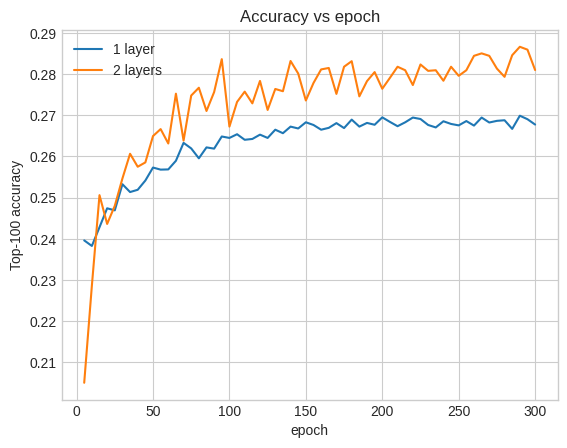
แม้แต่ในช่วงเริ่มต้นของการฝึกอบรม โมเดลที่ใหญ่กว่าก็มีลีดที่ชัดเจนและมั่นคงเหนือโมเดลตื้น ซึ่งแนะนำว่าการเพิ่มความลึกจะช่วยให้โมเดลสามารถจับความสัมพันธ์ที่ละเอียดยิ่งขึ้นในข้อมูลได้
อย่างไรก็ตาม แบบจำลองที่ลึกกว่านั้นไม่จำเป็นต้องดีกว่าเสมอไป โมเดลต่อไปนี้ขยายความลึกเป็นสามชั้น:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
ที่จริงแล้ว เราไม่เห็นการปรับปรุงเหนือแบบจำลองตื้น:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
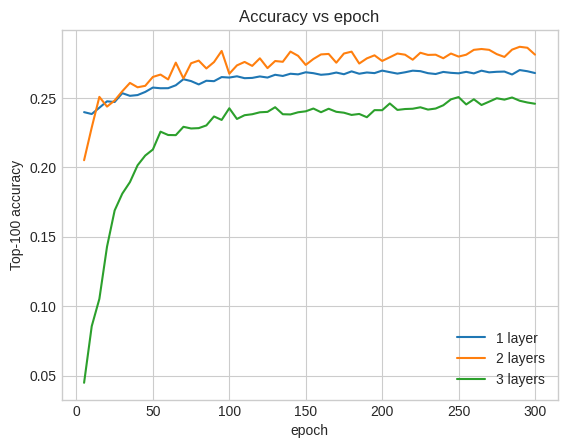
นี่เป็นภาพประกอบที่ดีของข้อเท็จจริงที่ว่ารุ่นที่ลึกและใหญ่ขึ้น ในขณะที่สามารถแสดงประสิทธิภาพที่เหนือกว่า มักจะต้องมีการปรับแต่งอย่างระมัดระวัง ตัวอย่างเช่น ตลอดบทช่วยสอนนี้ เราใช้อัตราการเรียนรู้คงที่เพียงอัตราเดียว ทางเลือกอื่นอาจให้ผลลัพธ์ที่แตกต่างกันมากและควรค่าแก่การสำรวจ
ด้วยการปรับแต่งที่เหมาะสมและข้อมูลที่เพียงพอ ความพยายามในการสร้างแบบจำลองที่ใหญ่ขึ้นและลึกขึ้นนั้นคุ้มค่าในหลายกรณี: โมเดลขนาดใหญ่สามารถนำไปสู่การปรับปรุงอย่างมากในความแม่นยำในการทำนาย
ขั้นตอนถัดไป
ในบทช่วยสอนนี้ เราได้ขยายโมเดลการดึงข้อมูลของเราด้วยเลเยอร์ที่หนาแน่นและฟังก์ชันการเปิดใช้งาน เพื่อดูวิธีการสร้างรูปแบบที่สามารถดำเนินการไม่เพียง แต่งาน แต่ยังดึงงานการจัดอันดับให้ดูที่ มัลติทาสก์กวดวิชา