
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش شامل مقدمه ای بر جاسازی کلمات است. شما تعبیههای کلمه خود را با استفاده از یک مدل ساده Keras برای یک کار طبقهبندی احساسات آموزش میدهید و سپس آنها را در پروژکتور جاسازی (در تصویر زیر نشان داده شده است) تجسم میکنید.

نمایش متن به صورت اعداد
مدل های یادگیری ماشین بردارها (آرایه های اعداد) را به عنوان ورودی می گیرند. هنگام کار با متن، اولین کاری که باید انجام دهید این است که یک استراتژی برای تبدیل رشته ها به اعداد (یا "بردار کردن" متن) قبل از تغذیه آن به مدل ارائه دهید. در این بخش، سه راهکار برای انجام این کار را مشاهده خواهید کرد.
رمزگذاری های تک داغ
به عنوان اولین ایده، ممکن است هر کلمه را در واژگان خود به صورت "یک داغ" رمزگذاری کنید. جمله «گربه روی حصیر نشست» را در نظر بگیرید. واژگان (یا کلمات منحصر به فرد) در این جمله (cat, mat, on, sat, the) است. برای نشان دادن هر کلمه، یک بردار صفر با طول معادل واژگان ایجاد می کنید، سپس یک بردار را در فهرست مربوط به کلمه قرار می دهید. این رویکرد در نمودار زیر نشان داده شده است.
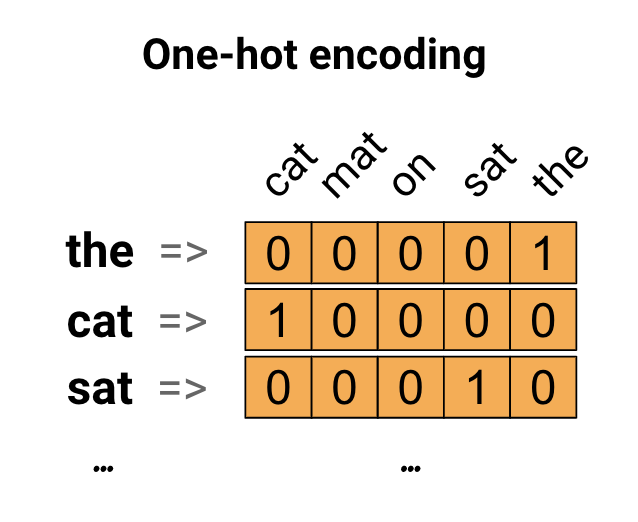
برای ایجاد یک برداری که حاوی رمزگذاری جمله باشد، می توانید بردارهای یک داغ را برای هر کلمه به هم متصل کنید.
هر کلمه را با یک عدد منحصر به فرد رمزگذاری کنید
روش دومی که ممکن است امتحان کنید این است که هر کلمه را با استفاده از یک عدد منحصر به فرد رمزگذاری کنید. در ادامه مثال بالا، می توانید 1 را به "cat"، 2 را به "mat" و غیره اختصاص دهید. سپس می توانید جمله "گربه روی تشک نشست" را به عنوان یک بردار متراکم مانند [5، 1، 4، 3، 5، 2] رمزگذاری کنید. این رویکرد کارآمد است. به جای یک بردار پراکنده، اکنون یک بردار متراکم دارید (که در آن همه عناصر پر هستند).
با این حال، این رویکرد دو جنبه منفی دارد:
رمزگذاری عدد صحیح دلخواه است (هیچ رابطه ای بین کلمات را نشان نمی دهد).
رمزگذاری عدد صحیح می تواند برای یک مدل چالش برانگیز باشد. به عنوان مثال، یک طبقهبندی خطی، یک وزن واحد را برای هر ویژگی میآموزد. از آنجا که هیچ رابطه ای بین شباهت هر دو کلمه و شباهت رمزگذاری آنها وجود ندارد، این ترکیب ویژگی-وزن معنی ندارد.
جاسازی کلمات
جاسازی کلمات راهی را به ما می دهد تا از یک نمایش کارآمد و متراکم استفاده کنیم که در آن کلمات مشابه رمزگذاری مشابهی دارند. نکته مهم این است که لازم نیست این رمزگذاری را با دست مشخص کنید. تعبیه یک بردار متراکم از مقادیر ممیز شناور است (طول بردار پارامتری است که شما تعیین می کنید). به جای تعیین مقادیر برای جاسازی به صورت دستی، آنها پارامترهای قابل آموزش هستند (وزن هایی که مدل در طول آموزش یاد می گیرد، به همان روشی که یک مدل وزن ها را برای یک لایه متراکم یاد می گیرد). معمولاً هنگام کار با مجموعه دادههای بزرگ، جاسازیهای کلمهای 8 بعدی (برای مجموعه دادههای کوچک)، تا 1024 بعد دیده میشود. تعبیه ابعادی بالاتر میتواند روابط دقیق بین کلمات را ثبت کند، اما برای یادگیری به دادههای بیشتری نیاز دارد.
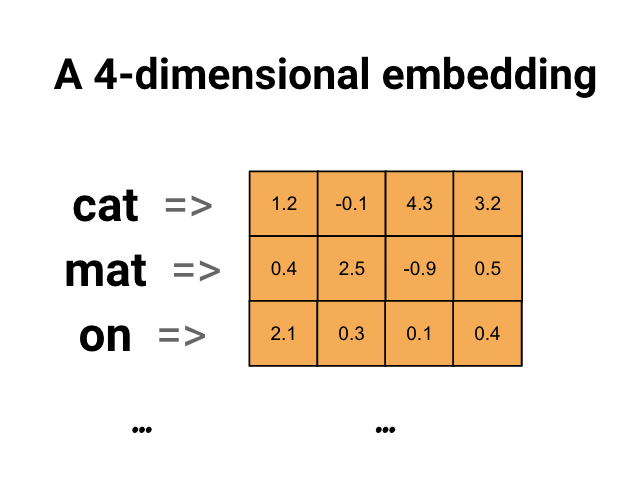
در بالا نموداری برای جاسازی کلمه آمده است. هر کلمه به عنوان یک بردار 4 بعدی از مقادیر ممیز شناور نشان داده می شود. راه دیگری برای در نظر گرفتن یک جاسازی به عنوان "جدول جستجو" است. پس از یادگیری این وزن ها، می توانید هر کلمه را با جستجوی بردار متراکم مربوط به آن در جدول رمزگذاری کنید.
برپایی
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
مجموعه داده های IMDb را دانلود کنید
شما از مجموعه داده های بررسی فیلم بزرگ از طریق آموزش استفاده خواهید کرد. شما یک مدل طبقهبندیکننده احساسات را روی این مجموعه داده آموزش خواهید داد و در این فرآیند جاسازیها را از ابتدا یاد خواهید گرفت. برای مطالعه بیشتر درباره بارگیری مجموعه داده از ابتدا، به آموزش بارگیری متن مراجعه کنید.
مجموعه داده را با استفاده از ابزار فایل Keras دانلود کنید و نگاهی به دایرکتوری ها بیندازید.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
به دایرکتوری train/ نگاهی بیندازید. دارای پوشههای pos و neg با نقدهای فیلم که به ترتیب به عنوان مثبت و منفی برچسبگذاری شدهاند. برای آموزش یک مدل طبقه بندی باینری از بررسی های پوشه های pos و neg استفاده خواهید کرد.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
فهرست راهنمای train همچنین دارای پوشه های اضافی است که باید قبل از ایجاد مجموعه داده آموزشی حذف شوند.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
سپس، یک tf.data.Dataset با استفاده از tf.keras.utils.text_dataset_from_directory ایجاد کنید. میتوانید در این آموزش طبقهبندی متن درباره استفاده از این ابزار بیشتر بخوانید.
از دایرکتوری train برای ایجاد مجموعه داده های قطار و اعتبارسنجی با تقسیم 20٪ برای اعتبار سنجی استفاده کنید.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
به چند نقد فیلم و برچسب آنها (1: positive, 0: negative) از مجموعه داده قطار نگاهی بیندازید.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
مجموعه داده را برای عملکرد پیکربندی کنید
این دو روش مهم هستند که باید هنگام بارگیری داده ها استفاده کنید تا مطمئن شوید که I/O مسدود نمی شود.
.cache() داده ها را پس از بارگیری از دیسک در حافظه نگه می دارد. این اطمینان حاصل می کند که مجموعه داده در حین آموزش مدل شما به یک گلوگاه تبدیل نمی شود. اگر مجموعه داده شما بیش از حد بزرگ است که نمی تواند در حافظه جا شود، می توانید از این روش برای ایجاد یک حافظه پنهان روی دیسک کارآمد استفاده کنید که خواندن آن از بسیاری از فایل های کوچک کارآمدتر است.
.prefetch() با پیش پردازش داده ها و اجرای مدل در حین آموزش همپوشانی دارد.
در راهنمای عملکرد داده میتوانید درباره هر دو روش و همچنین نحوه ذخیره اطلاعات روی دیسک اطلاعات بیشتری کسب کنید.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
با استفاده از لایه Embedding
Keras استفاده از جاسازی کلمات را آسان می کند. به لایه Embedding نگاهی بیندازید.
لایه Embedding را می توان به عنوان یک جدول جستجو درک کرد که از شاخص های اعداد صحیح (که مخفف کلمات خاص هستند) به بردارهای متراکم (جاسازی های آنها) نگاشت می شود. ابعاد (یا عرض) تعبیه پارامتری است که می توانید با آن آزمایش کنید تا ببینید چه چیزی برای مشکل شما خوب است، دقیقاً به همان روشی که با تعداد نورون ها در یک لایه متراکم آزمایش می کنید.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
هنگامی که یک لایه Embedding ایجاد می کنید، وزن های مربوط به embedding به طور تصادفی مقداردهی اولیه می شوند (دقیقاً مانند هر لایه دیگر). در طول تمرین، آنها به تدریج از طریق پس انتشار تنظیم می شوند. پس از آموزش، تعبیههای کلمات آموخته شده تقریباً شباهتهای بین کلمات را رمزگذاری میکنند (همانطور که برای مشکل خاصی که مدل شما آموزش داده شده است).
اگر یک عدد صحیح را به یک لایه جاسازی ارسال کنید، نتیجه هر عدد صحیح را با بردار جدول جاسازی جایگزین می کند:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
برای مشکلات متن یا دنباله، لایه Embedding یک تانسور دوبعدی از اعداد صحیح، شکل (samples, sequence_length) ، که در آن هر ورودی دنباله ای از اعداد صحیح است. می تواند دنباله هایی با طول های متغیر را جاسازی کند. می توانید به لایه جاسازی در بالای دسته ها با اشکال (32, 10) (دسته ای از 32 دنباله به طول 10) یا (64, 15) (دسته ای از 64 دنباله به طول 15) وارد کنید.
تانسور برگشتی یک محور بیشتر از ورودی دارد، بردارهای تعبیه شده در امتداد آخرین محور جدید تراز شده اند. یک دسته ورودی (2, 3) ارسال کنید و خروجی (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
هنگامی که یک دسته از دنباله ها به عنوان ورودی داده می شود، یک لایه جاسازی یک تانسور ممیز شناور سه بعدی با شکل (samples, sequence_length, embedding_dimensionality) را برمی گرداند. برای تبدیل این دنباله از طول متغیر به یک نمایش ثابت، رویکردهای استاندارد مختلفی وجود دارد. می توانید از یک لایه RNN، Attention یا Pooling استفاده کنید قبل از اینکه آن را به یک لایه متراکم منتقل کنید. این آموزش از ادغام استفاده می کند زیرا ساده ترین است. طبقه بندی متن با آموزش RNN گام بعدی خوب است.
پیش پردازش متن
در مرحله بعد، مراحل پیش پردازش داده مورد نیاز برای مدل طبقه بندی احساسات خود را تعریف کنید. یک لایه TextVectorization با پارامترهای مورد نظر برای برداری بردار بررسی فیلم ها راه اندازی کنید. در آموزش طبقه بندی متن می توانید با استفاده از این لایه بیشتر آشنا شوید.
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
یک مدل طبقه بندی ایجاد کنید
از Keras Sequential API برای تعریف مدل طبقه بندی احساسات استفاده کنید. در این مورد یک مدل سبک "Continuous bag of words" است.
- لایه
TextVectorizationرشته ها را به شاخص های واژگانی تبدیل می کند. شما قبلاvectorize_layerرا به عنوان یک لایه TextVectorization مقداردهی اولیه کرده اید و واژگان آن را با فراخوانیadaptدرtext_ds. اکنون vectorize_layer می تواند به عنوان اولین لایه از مدل طبقه بندی end-to-end شما استفاده شود و رشته های تبدیل شده را به لایه Embedding تغذیه کند. لایه
Embeddingواژگان رمزگذاری شده با اعداد صحیح را می گیرد و بردار جاسازی را برای هر کلمه-شاخص جستجو می کند. این بردارها به عنوان آموزش مدل یاد می شوند. بردارها یک بعد به آرایه خروجی اضافه می کنند. ابعاد به دست آمده عبارتند از:(batch, sequence, embedding).لایه
GlobalAveragePooling1Dیک بردار خروجی با طول ثابت را برای هر مثال با میانگینگیری از بعد دنباله برمیگرداند. این به مدل اجازه می دهد تا ورودی با طول متغیر را به ساده ترین شکل ممکن مدیریت کند.بردار خروجی با طول ثابت از طریق یک لایه کاملاً متصل (
Dense) با 16 واحد پنهان لوله می شود.آخرین لایه به طور متراکم با یک گره خروجی متصل است.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
کامپایل و آموزش مدل
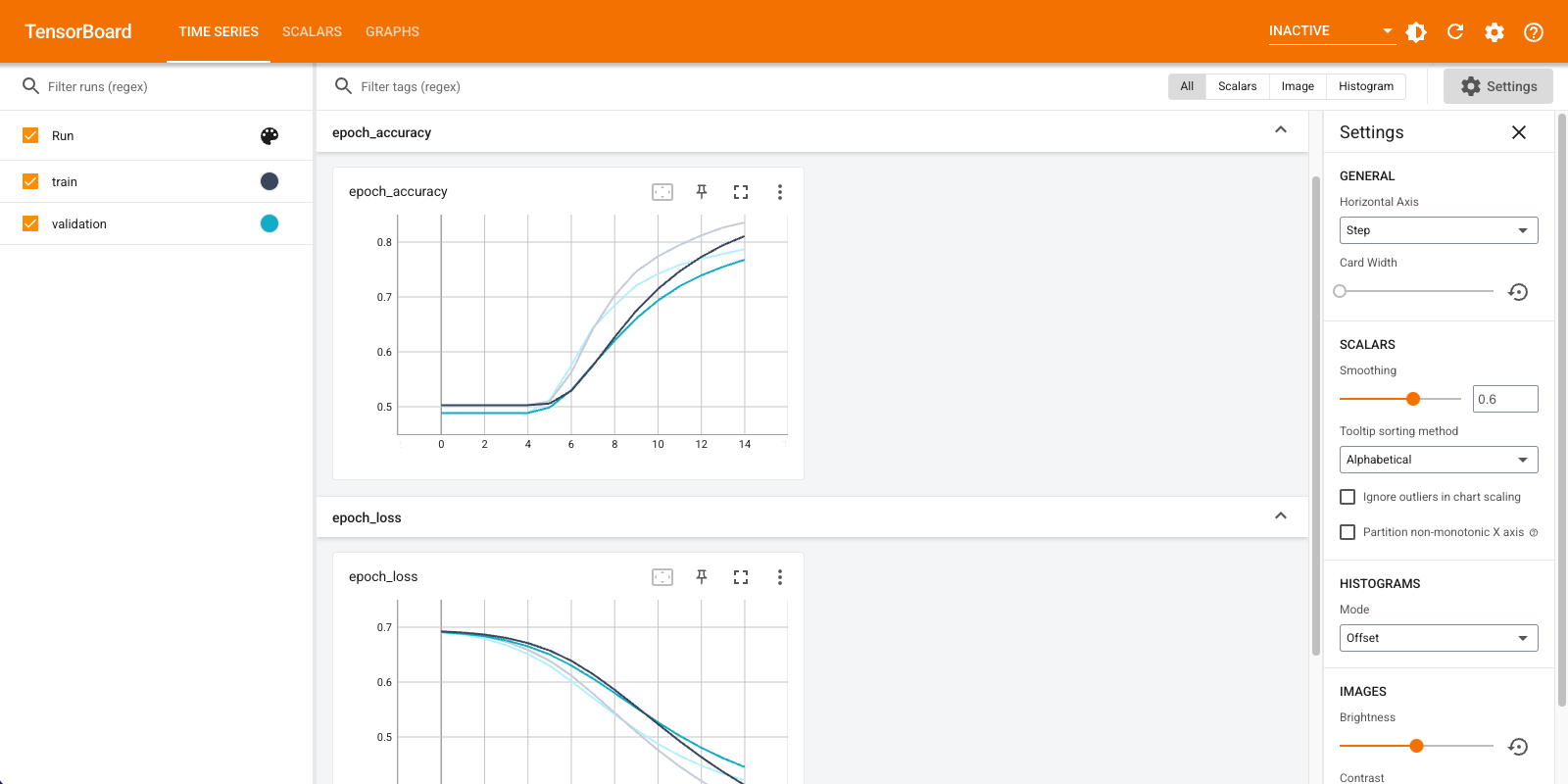
شما از TensorBoard برای تجسم معیارها از جمله ضرر و دقت استفاده خواهید کرد. یک tf.keras.callbacks.TensorBoard ایجاد کنید.
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
مدل را با استفاده از بهینه ساز Adam و از دست دادن BinaryCrossentropy کامپایل و آموزش دهید.
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
با این رویکرد، مدل به دقت اعتبارسنجی حدود 78٪ می رسد (توجه داشته باشید که مدل بیش از حد برازش دارد زیرا دقت آموزش بالاتر است).
برای کسب اطلاعات بیشتر در مورد هر لایه از مدل می توانید به خلاصه مدل نگاه کنید.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
معیارهای مدل را در TensorBoard تجسم کنید.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
جاسازی های کلمه آموزش دیده را بازیابی کنید و آنها را در دیسک ذخیره کنید
در مرحله بعد، کلمه embeddings آموخته شده در طول آموزش را بازیابی کنید. تعبیهها وزنهای لایه Embedding در مدل هستند. ماتریس اوزان به شکل (vocab_size, embedding_dimension) است.
با استفاده از get_layer() و get_weights() وزن ها را از مدل بدست آورید. تابع get_vocabulary() واژگانی را برای ساخت یک فایل فراداده با یک نشانه در هر خط فراهم می کند.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
وزن ها را روی دیسک بنویسید. برای استفاده از پروژکتور جاسازی ، دو فایل را با فرمت جداشده از برگه ها آپلود خواهید کرد: یک فایل بردار (شامل جاسازی) و یک فایل متا داده (حاوی کلمات).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
اگر این آموزش را در Colaboratory اجرا می کنید، می توانید از قطعه زیر برای دانلود این فایل ها در دستگاه محلی خود استفاده کنید (یا از مرورگر فایل، View -> Table of contents -> File browser استفاده کنید).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
جاسازی ها را تجسم کنید
برای تجسم جاسازی ها، آنها را در پروژکتور جاسازی آپلود کنید.
پروژکتور Embedding را باز کنید (این پروژکتور می تواند در یک نمونه محلی TensorBoard نیز اجرا شود).
روی "بارگیری داده ها" کلیک کنید.
دو فایلی را که در بالا ایجاد کردید آپلود کنید:
vecs.tsvوmeta.tsv.
جاسازی هایی که آموزش داده اید اکنون نمایش داده می شوند. می توانید کلمات را جستجو کنید تا نزدیک ترین همسایگان آنها را بیابید. به عنوان مثال، سعی کنید "زیبا" را جستجو کنید. ممکن است همسایه هایی مانند "شگفت انگیز" را ببینید.
مراحل بعدی
این آموزش به شما نشان داده است که چگونه جاسازی کلمات را از ابتدا در یک مجموعه داده کوچک آموزش دهید و تجسم کنید.
برای آموزش جاسازی کلمات با استفاده از الگوریتم Word2Vec، آموزش Word2Vec را امتحان کنید.
برای کسب اطلاعات بیشتر در مورد پردازش متن پیشرفته، مدل Transformer برای درک زبان را بخوانید.