
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش طبقه بندی متن را از فایل های متنی ساده ذخیره شده روی دیسک نشان می دهد. شما یک طبقه بندی کننده باینری را برای انجام تجزیه و تحلیل احساسات بر روی مجموعه داده های IMDB آموزش خواهید داد. در انتهای دفترچه، تمرینی برای شما وجود دارد که می توانید آن را امتحان کنید، که در آن یک طبقه بندی کننده چند کلاسه را آموزش می دهید تا برچسب یک سوال برنامه نویسی را در Stack Overflow پیش بینی کند.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
تحلیل احساسات
این نوت بوک یک مدل تحلیل احساسات را آموزش می دهد تا نقدهای فیلم را بر اساس متن نقد به عنوان مثبت یا منفی طبقه بندی کند. این نمونهای از طبقهبندی باینری یا دو کلاسه است، یک نوع مهم و بهطور گسترده از مشکل یادگیری ماشین.
شما از مجموعه دادههای مرور فیلم بزرگ استفاده خواهید کرد که حاوی متن 50000 نقد فیلم از پایگاه داده اینترنتی فیلم است. اینها به 25000 بررسی برای آموزش و 25000 بررسی برای آزمایش تقسیم می شوند. مجموعه های آموزشی و آزمایشی متعادل هستند، به این معنی که شامل تعداد مساوی نظرات مثبت و منفی هستند.
مجموعه داده های IMDB را دانلود و کاوش کنید
بیایید مجموعه داده را دانلود و استخراج کنیم، سپس ساختار دایرکتوری را بررسی کنیم.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
aclImdb/train/pos و aclImdb/train/neg حاوی فایلهای متنی زیادی هستند که هر کدام یک بررسی فیلم هستند. بیایید نگاهی به یکی از آنها بیندازیم.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
مجموعه داده را بارگیری کنید
در مرحله بعد، داده ها را از روی دیسک بارگذاری کرده و آن را در قالبی مناسب برای آموزش آماده می کنید. برای انجام این کار، از ابزار مفید text_dataset_from_directory استفاده خواهید کرد که ساختار دایرکتوری را به صورت زیر انتظار دارد.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
برای تهیه یک مجموعه داده برای طبقه بندی باینری، به دو پوشه روی دیسک نیاز دارید که مربوط به class_a و class_b هستند. اینها نقدهای مثبت و منفی فیلم هستند که در aclImdb/train/pos و aclImdb/train/neg یافت می شوند. از آنجایی که مجموعه داده های IMDB حاوی پوشه های اضافی است، قبل از استفاده از این ابزار، آنها را حذف خواهید کرد.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
در مرحله بعد، از ابزار text_dataset_from_directory برای ایجاد یک tf.data.Dataset با برچسب استفاده خواهید کرد. tf.data مجموعه ای قدرتمند از ابزارها برای کار با داده ها است.
هنگام اجرای یک آزمایش یادگیری ماشینی، بهترین روش این است که مجموعه داده خود را به سه بخش تقسیم کنید: قطار ، اعتبارسنجی و آزمایش .
مجموعه داده های IMDB قبلاً به دو دسته آموزش و آزمایش تقسیم شده است، اما فاقد مجموعه اعتبارسنجی است. بیایید یک مجموعه اعتبار سنجی با استفاده از تقسیم 80:20 از داده های آموزشی با استفاده از آرگومان validation_split زیر ایجاد کنیم.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
همانطور که در بالا مشاهده می کنید، 25000 نمونه در پوشه آموزشی وجود دارد که از 80% (یا 20000) آن برای آموزش استفاده خواهید کرد. همانطور که در یک لحظه خواهید دید، می توانید یک مدل را با ارسال مستقیم یک مجموعه داده به model.fit . اگر با tf.data تازه کار هستید، میتوانید روی مجموعه داده نیز تکرار کنید و چند نمونه را به شرح زیر چاپ کنید.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
توجه داشته باشید که بررسی ها حاوی متن خام هستند (با علائم نگارشی و گاه به گاه برچسب های HTML مانند <br/> ). نحوه رسیدگی به این موارد را در بخش زیر نشان خواهید داد.
برچسبها 0 یا 1 هستند. برای اینکه ببینید کدام یک از اینها با نقدهای مثبت و منفی فیلم مطابقت دارد، میتوانید ویژگی class_names را در مجموعه داده بررسی کنید.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
در مرحله بعد، یک مجموعه داده اعتبارسنجی و آزمایشی ایجاد خواهید کرد. شما از 5000 بررسی باقی مانده از مجموعه آموزشی برای اعتبارسنجی استفاده خواهید کرد.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
مجموعه داده را برای آموزش آماده کنید
در مرحله بعد، داده ها را با استفاده از لایه مفید tf.keras.layers.TextVectorization استاندارد، نشانه گذاری و بردار می کنید.
استانداردسازی به پیش پردازش متن اشاره دارد، معمولاً برای حذف علائم نگارشی یا عناصر HTML برای ساده کردن مجموعه داده. Tokenization به تقسیم رشته ها به نشانه ها اشاره دارد (به عنوان مثال، تقسیم یک جمله به کلمات جداگانه، با تقسیم در فضای خالی). بردارسازی به تبدیل نشانه ها به اعداد اشاره دارد تا بتوان آنها را به یک شبکه عصبی تغذیه کرد. تمام این وظایف را می توان با این لایه انجام داد.
همانطور که در بالا دیدید، بررسی ها حاوی تگ های مختلف HTML مانند <br /> هستند. این تگها توسط استانداردساز پیشفرض در لایه TextVectorization (که متن را به حروف کوچک تبدیل میکند و به طور پیشفرض علائم نگارشی را حذف میکند، اما HTML را حذف نمیکند) حذف نمیشوند. شما یک تابع استانداردسازی سفارشی برای حذف HTML خواهید نوشت.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
بعد، یک لایه TextVectorization ایجاد خواهید کرد. شما از این لایه برای استانداردسازی، نشانه گذاری و برداری داده های ما استفاده خواهید کرد. شما output_mode را روی int قرار می دهید تا برای هر توکن شاخص های عدد صحیح منحصر به فرد ایجاد کنید.
توجه داشته باشید که از تابع تقسیم پیشفرض و تابع استانداردسازی سفارشی که در بالا تعریف کردید استفاده میکنید. شما همچنین برخی از ثابتها را برای مدل تعریف میکنید، مانند حداکثر sequence_length ، که باعث میشود لایه لایهها را اضافه کند یا توالیها را دقیقاً به مقادیر sequence_length کوتاه کند.
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
در مرحله بعد، adapt را فراخوانی میکنید تا وضعیت لایه پیشپردازش با مجموعه داده مطابقت داشته باشد. این باعث می شود که مدل یک فهرست از رشته ها به اعداد صحیح بسازد.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
بیایید یک تابع ایجاد کنیم تا نتیجه استفاده از این لایه برای پیش پردازش برخی از داده ها را ببینیم.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
همانطور که در بالا می بینید، هر نشانه با یک عدد صحیح جایگزین شده است. شما می توانید با فراخوانی .get_vocabulary() در لایه، توکن (رشته) را که هر عدد صحیح مربوط به آن است جستجو کنید.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
شما تقریباً آماده آموزش مدل خود هستید. به عنوان آخرین مرحله پیش پردازش، لایه TextVectorization را که قبلاً ایجاد کردهاید، روی مجموعه دادههای قطار، اعتبارسنجی و آزمایش اعمال میکنید.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
مجموعه داده را برای عملکرد پیکربندی کنید
این دو روش مهم هستند که باید هنگام بارگیری داده ها استفاده کنید تا مطمئن شوید که I/O مسدود نمی شود.
.cache() داده ها را پس از بارگیری از دیسک در حافظه نگه می دارد. این اطمینان حاصل می کند که مجموعه داده در حین آموزش مدل شما به یک گلوگاه تبدیل نمی شود. اگر مجموعه داده شما بیش از حد بزرگ است که نمی تواند در حافظه جا شود، می توانید از این روش برای ایجاد یک حافظه پنهان روی دیسک کارآمد استفاده کنید که خواندن آن از بسیاری از فایل های کوچک کارآمدتر است.
.prefetch() با پیش پردازش داده ها و اجرای مدل در حین آموزش همپوشانی دارد.
در راهنمای عملکرد داده میتوانید درباره هر دو روش و همچنین نحوه ذخیره اطلاعات روی دیسک اطلاعات بیشتری کسب کنید.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
مدل را ایجاد کنید
وقت آن است که شبکه عصبی خود را ایجاد کنید:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
لایه ها برای ساخت طبقه بندی کننده به صورت متوالی روی هم چیده می شوند:
- لایه اول یک لایه
Embeddingاست. این لایه بررسی های رمزگذاری شده با اعداد صحیح را می گیرد و یک بردار تعبیه شده را برای هر فهرست واژه جستجو می کند. این بردارها به عنوان آموزش مدل یاد می شوند. بردارها یک بعد به آرایه خروجی اضافه می کنند. ابعاد به دست آمده عبارتند از:(batch, sequence, embedding). برای کسب اطلاعات بیشتر در مورد جاسازی، به آموزش تعبیه کلمه مراجعه کنید. - در مرحله بعد، یک لایه
GlobalAveragePooling1Dیک بردار خروجی با طول ثابت را برای هر مثال با میانگینگیری از بعد دنباله برمیگرداند. این به مدل اجازه می دهد تا ورودی با طول متغیر را به ساده ترین شکل ممکن مدیریت کند. - این بردار خروجی با طول ثابت از طریق یک لایه کاملاً متصل (
Dense) با 16 واحد پنهان لوله می شود. - آخرین لایه به طور متراکم با یک گره خروجی متصل است.
عملکرد از دست دادن و بهینه ساز
یک مدل برای آموزش به یک تابع ضرر و یک بهینه ساز نیاز دارد. از آنجایی که این یک مشکل طبقهبندی باینری است و مدل یک احتمال (یک لایه تک واحدی با فعالسازی سیگموئید) را خروجی میدهد، شما از تابع losses.BinaryCrossentropy استفاده خواهید کرد.
اکنون، مدل را طوری پیکربندی کنید که از یک بهینه ساز و یک تابع ضرر استفاده کند:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
مدل را آموزش دهید
شما مدل را با ارسال شی dataset به متد fit آموزش خواهید داد.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
مدل را ارزیابی کنید
بیایید ببینیم مدل چگونه عمل می کند. دو مقدار برگردانده خواهد شد. ضرر (عددی که نشان دهنده خطای ما است، مقادیر کمتر بهتر است) و دقت.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
این رویکرد نسبتا ساده لوحانه به دقت حدود 86 درصد دست می یابد.
طرحی از دقت و ضرر در طول زمان ایجاد کنید
model.fit() یک شی History را برمیگرداند که حاوی یک فرهنگ لغت با همه چیزهایی است که در طول آموزش اتفاق افتاده است:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
چهار ورودی وجود دارد: یکی برای هر معیار نظارت شده در طول آموزش و اعتبارسنجی. میتوانید از این موارد برای ترسیم از دست دادن آموزش و اعتبارسنجی برای مقایسه، و همچنین دقت آموزش و اعتبارسنجی استفاده کنید:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
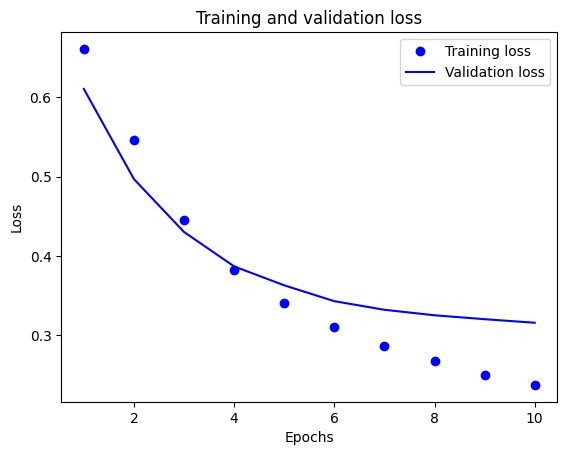
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
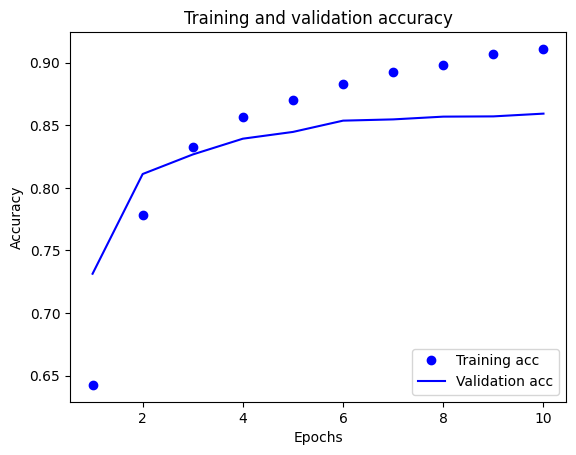
در این نمودار، نقاط نشان دهنده فقدان تمرین و دقت و خطوط ثابت، از دست دادن اعتبار و دقت هستند.
توجه داشته باشید که از دست دادن تمرین با هر دوره کاهش می یابد و دقت تمرین با هر دوره افزایش می یابد. هنگام استفاده از بهینهسازی نزولی گرادیان، این مورد انتظار میرود - باید مقدار مورد نظر را در هر تکرار به حداقل برساند.
این مورد در مورد از دست دادن اعتبار و دقت صدق نمی کند - به نظر می رسد آنها قبل از دقت آموزش به اوج خود می رسند. این مثالی از برازش بیش از حد است: این مدل در دادههای آموزشی بهتر از دادههایی که قبلاً ندیده بود، عمل میکند. پس از این مرحله، مدل بیش از حد بهینهسازی میکند و نمایشهایی خاص برای دادههای آموزشی را میآموزد که به دادههای آزمایش تعمیم نمییابند .
برای این مورد خاص، زمانی که دقت اعتبارسنجی دیگر افزایش نمییابد، میتوانید به سادگی با متوقف کردن آموزش از بیشبرازش جلوگیری کنید. یک راه برای انجام این کار استفاده از tf.keras.callbacks.EarlyStopping callback است.
مدل را صادر کنید
در کد بالا، قبل از تغذیه متن به مدل، لایه TextVectorization را روی مجموعه داده اعمال کردید. اگر میخواهید مدل خود را قادر به پردازش رشتههای خام (مثلاً برای ساده کردن استقرار آن) کنید، میتوانید لایه TextVectorization را در مدل خود قرار دهید. برای انجام این کار، می توانید با استفاده از وزنه هایی که به تازگی تمرین کرده اید، یک مدل جدید ایجاد کنید.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
استنباط در مورد داده های جدید
برای دریافت پیشبینی برای مثالهای جدید، میتوانید به سادگی model.predict() را فراخوانی کنید.
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
گنجاندن منطق پیشپردازش متن در داخل مدل شما را قادر میسازد مدلی را برای تولید صادر کنید که استقرار را ساده میکند و پتانسیل انحراف قطار/آزمایش را کاهش میدهد.
هنگام انتخاب محل اعمال لایه TextVectorization خود باید به یک تفاوت عملکرد توجه داشت. استفاده از آن در خارج از مدل شما را قادر می سازد تا هنگام آموزش بر روی GPU، پردازش ناهمزمان CPU و بافر داده های خود را انجام دهید. بنابراین، اگر مدل خود را بر روی GPU آموزش می دهید، احتمالاً می خواهید از این گزینه استفاده کنید تا بهترین عملکرد را در حین توسعه مدل خود داشته باشید، سپس هنگامی که برای استقرار آماده شدید، به اضافه کردن لایه TextVectorization در داخل مدل خود بروید. .
برای کسب اطلاعات بیشتر در مورد ذخیره مدل ها، از این آموزش دیدن کنید.
تمرین: طبقه بندی چند کلاسه در مورد سوالات Stack Overflow
این آموزش نحوه آموزش یک طبقه بندی کننده باینری را از ابتدا در مجموعه داده های IMDB نشان می دهد. به عنوان یک تمرین، می توانید این نوت بوک را برای آموزش یک طبقه بندی کننده چند کلاسه برای پیش بینی برچسب یک سوال برنامه نویسی در Stack Overflow تغییر دهید.
مجموعه داده ای برای استفاده شما آماده شده است که شامل چندین هزار سوال برنامه نویسی است (به عنوان مثال، "چگونه می توانم یک فرهنگ لغت را بر اساس مقدار در پایتون مرتب کنم؟") که در Stack Overflow ارسال شده است. هر یک از اینها دقیقاً با یک برچسب (یا پایتون، CSharp، جاوا اسکریپت یا جاوا) برچسب گذاری شده اند. وظیفه شما این است که یک سوال را به عنوان ورودی بگیرید و تگ مناسب را پیش بینی کنید، در این مورد پایتون.
مجموعه داده ای که با آن کار خواهید کرد حاوی چندین هزار سؤال است که از مجموعه داده عمومی بسیار بزرگتر Stack Overflow در BigQuery استخراج شده است که شامل بیش از 17 میلیون پست است.
پس از دانلود مجموعه داده، متوجه خواهید شد که ساختار دایرکتوری مشابهی با مجموعه داده IMDB دارد که قبلاً با آن کار می کردید:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
برای تکمیل این تمرین، باید این نوت بوک را برای کار با مجموعه داده های Stack Overflow با انجام تغییرات زیر تغییر دهید:
در بالای نوت بوک خود، کدی را که مجموعه داده های IMDB را دانلود می کند با کد به روز کنید تا مجموعه داده های Stack Overflow را که از قبل آماده شده است دانلود کنید. از آنجایی که مجموعه داده Stack Overflow دارای ساختار دایرکتوری مشابهی است، نیازی به ایجاد تغییرات زیادی نخواهید داشت.
آخرین لایه مدل خود را به
Dense(4)تغییر دهید، زیرا اکنون چهار کلاس خروجی وجود دارد.هنگام کامپایل کردن مدل، ضرر را به
tf.keras.losses.SparseCategoricalCrossentropyتغییر دهید. این تابع از دست دادن صحیح برای یک مسئله طبقه بندی چند کلاسه است، زمانی که برچسب های هر کلاس اعداد صحیح هستند (در این مورد، آنها می توانند 0، 1 ، 2 یا 3 باشند). علاوه بر این، معیارها را بهmetrics=['accuracy']تغییر دهید، زیرا این یک مشکل طبقهبندی چند کلاسه است (tf.metrics.BinaryAccuracyفقط برای طبقهبندیکنندههای باینری استفاده میشود).هنگام ترسیم دقت در طول زمان،
binary_accuracyوval_binary_accuracyرا به ترتیب بهaccuracyوval_accuracyتغییر دهید.پس از تکمیل این تغییرات، می توانید یک طبقه بندی کننده چند کلاسه را آموزش دهید.
بیشتر بیاموزید
این آموزش طبقه بندی متن را از ابتدا معرفی می کند. برای کسب اطلاعات بیشتر در مورد گردش کار طبقه بندی متن به طور کلی، راهنمای طبقه بندی متن از Google Developers را بررسی کنید.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.