
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel montre comment prétraiter des fichiers audio au format WAV et créer et former un modèle de base de reconnaissance vocale automatique (ASR) pour reconnaître dix mots différents. Vous utiliserez une partie de l'ensemble de données Speech Commands ( Warden, 2018 ), qui contient de courts clips audio (d'une seconde ou moins) de commandes, telles que "bas", "aller", "gauche", "non", " droite", "stop", "haut" et "oui".
Les systèmes de reconnaissance vocale et audio du monde réel sont complexes. Mais, comme la classification d'images avec le jeu de données MNIST , ce didacticiel devrait vous donner une compréhension de base des techniques impliquées.
Installer
Importez les modules et les dépendances nécessaires. Notez que vous utiliserez seaborn pour la visualisation dans ce didacticiel.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Importer le mini jeu de données Speech Commands
Pour gagner du temps lors du chargement des données, vous travaillerez avec une version réduite du jeu de données Speech Commands. L'ensemble de données original se compose de plus de 105 000 fichiers audio au format de fichier audio WAV (Waveform) de personnes prononçant 35 mots différents. Ces données ont été collectées par Google et publiées sous une licence CC BY.
Téléchargez et extrayez le fichier mini_speech_commands.zip contenant les plus petits jeux de données Speech Commands avec tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Les clips audio du jeu de données sont stockés dans huit dossiers correspondant à chaque commande vocale : no , yes , down , go , left , up , right et stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Extrayez les clips audio dans une liste appelée filenames et mélangez-la :
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
Divisez les noms de filenames en ensembles d'entraînement, de validation et de test en utilisant un ratio de 80:10:10, respectivement :
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Lire les fichiers audio et leurs étiquettes
Dans cette section, vous allez prétraiter l'ensemble de données, en créant des tenseurs décodés pour les formes d'onde et les étiquettes correspondantes. Noter que:
- Chaque fichier WAV contient des données de séries chronologiques avec un nombre défini d'échantillons par seconde.
- Chaque échantillon représente l' amplitude du signal audio à ce moment précis.
- Dans un système 16 bits , comme les fichiers WAV du jeu de données Mini Speech Commands, les valeurs d'amplitude vont de -32 768 à 32 767.
- Le taux d'échantillonnage pour cet ensemble de données est de 16 kHz.
La forme du tenseur renvoyé par tf.audio.decode_wav est [samples, channels] , où channels est 1 pour mono ou 2 pour stéréo. Le jeu de données mini Speech Commands ne contient que des enregistrements mono.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Définissons maintenant une fonction qui prétraite les fichiers audio WAV bruts de l'ensemble de données en tenseurs audio :
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Définissez une fonction qui crée des étiquettes à l'aide des répertoires parents pour chaque fichier :
- Divisez les chemins de fichiers en
tf.RaggedTensors (tenseurs aux dimensions irrégulières, avec des tranches pouvant avoir des longueurs différentes).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Définissez une autre fonction d'assistance — get_waveform_and_label — qui rassemble le tout :
- L'entrée est le nom du fichier audio WAV.
- La sortie est un tuple contenant l'audio et les tenseurs d'étiquettes prêts pour l'apprentissage supervisé.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Créez l'ensemble d'entraînement pour extraire les paires d'étiquettes audio :
- Créez un
tf.data.DatasetavecDataset.from_tensor_slicesetDataset.map, en utilisantget_waveform_and_labeldéfini précédemment.
Vous créerez les ensembles de validation et de test à l'aide d'une procédure similaire ultérieurement.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
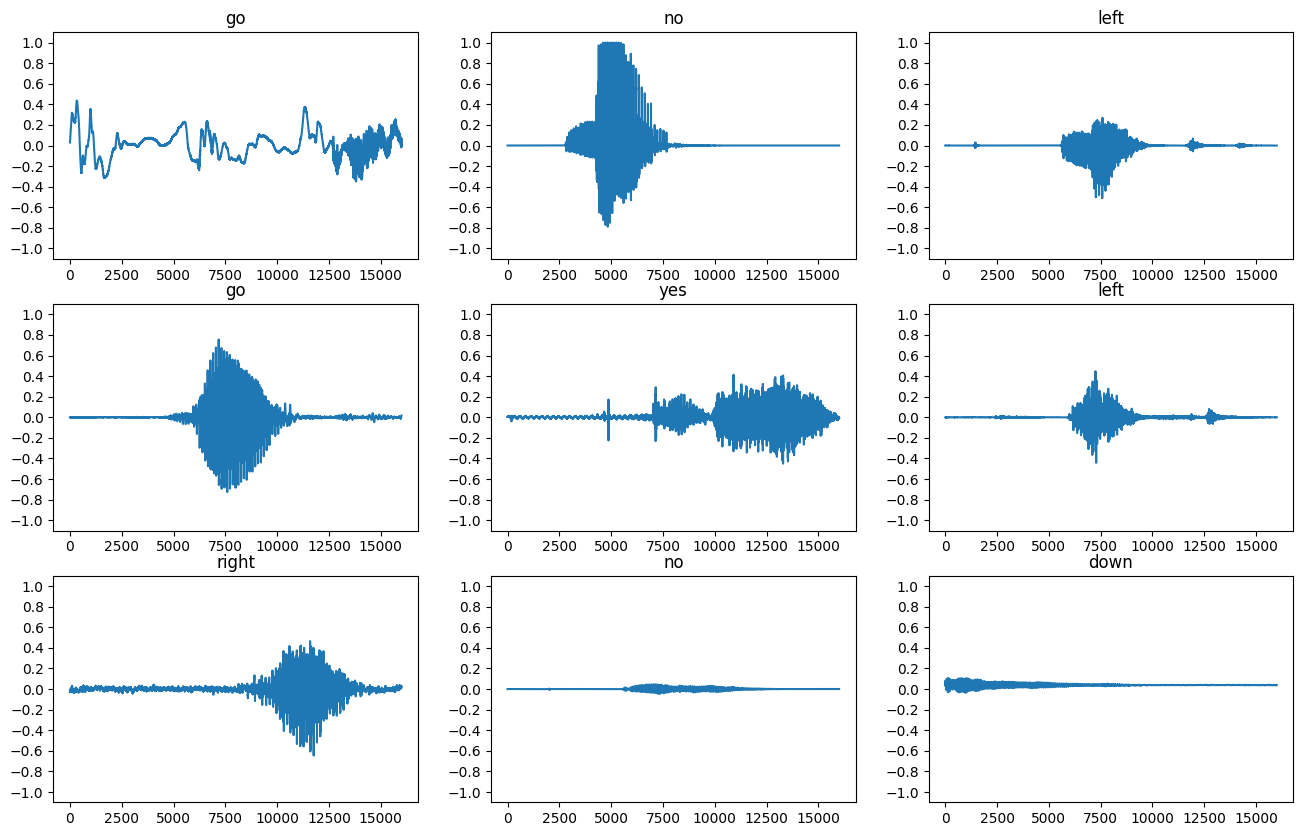
Traçons quelques formes d'onde audio :
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
Convertir des formes d'onde en spectrogrammes
Les formes d'onde du jeu de données sont représentées dans le domaine temporel. Ensuite, vous transformerez les formes d'onde des signaux du domaine temporel en signaux du domaine temps-fréquence en calculant la transformée de Fourier à court terme (STFT) pour convertir les formes d'onde en spectrogrammes , qui montrent les changements de fréquence au fil du temps et peuvent être représentés sous forme d'images 2D. Vous alimenterez les images du spectrogramme dans votre réseau de neurones pour entraîner le modèle.
Une transformée de Fourier ( tf.signal.fft ) convertit un signal en ses fréquences composantes, mais perd toutes les informations temporelles. En comparaison, STFT ( tf.signal.stft ) divise le signal en fenêtres de temps et exécute une transformée de Fourier sur chaque fenêtre, en préservant certaines informations temporelles et en renvoyant un tenseur 2D sur lequel vous pouvez exécuter des convolutions standard.
Créez une fonction utilitaire pour convertir les formes d'onde en spectrogrammes :
- Les formes d'onde doivent avoir la même longueur, de sorte que lorsque vous les convertissez en spectrogrammes, les résultats aient des dimensions similaires. Cela peut être fait en remplissant simplement de zéro les clips audio qui durent moins d'une seconde (en utilisant
tf.zeros). - Lors de l'appel
tf.signal.stft, choisissez les paramètresframe_lengthetframe_stepsorte que "l'image" du spectrogramme généré soit presque carrée. Pour plus d'informations sur le choix des paramètres STFT, reportez-vous à cette vidéo Coursera sur le traitement du signal audio et STFT. - Le STFT produit un tableau de nombres complexes représentant l'amplitude et la phase. Cependant, dans ce didacticiel, vous n'utiliserez que la magnitude, que vous pouvez dériver en appliquant
tf.abssur la sortie detf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
Ensuite, commencez à explorer les données. Imprimez les formes de la forme d'onde tensorilée d'un exemple et le spectrogramme correspondant, et lisez l'audio d'origine :
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Maintenant, définissez une fonction pour afficher un spectrogramme :
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
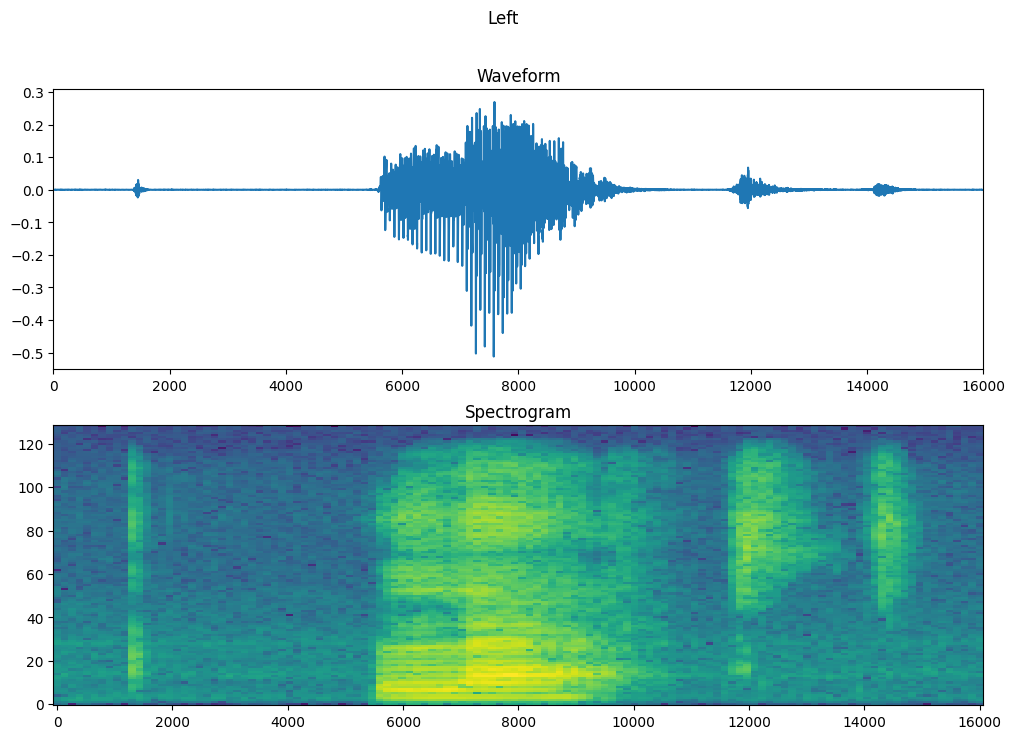
Tracez la forme d'onde de l'exemple dans le temps et le spectrogramme correspondant (fréquences dans le temps) :
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
Maintenant, définissez une fonction qui transforme l'ensemble de données de forme d'onde en spectrogrammes et leurs étiquettes correspondantes en identifiants entiers :
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
get_spectrogram_and_label_id sur les éléments de l'ensemble de données avec Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
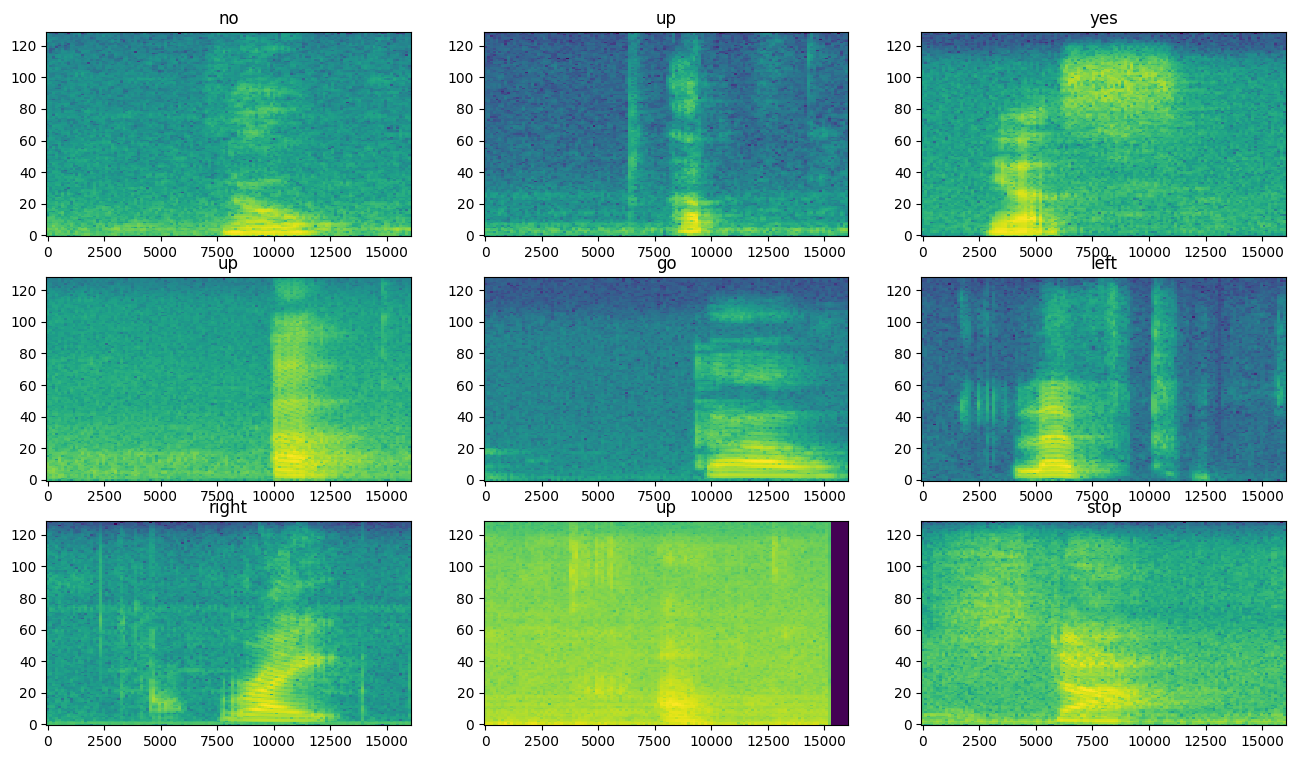
Examinez les spectrogrammes pour différents exemples de l'ensemble de données :
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
Construire et entraîner le modèle
Répétez le prétraitement de l'ensemble d'entraînement sur les ensembles de validation et de test :
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Regroupez les ensembles d'entraînement et de validation pour l'entraînement du modèle :
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Ajoutez les opérations Dataset.cache et Dataset.prefetch pour réduire la latence de lecture lors de l'entraînement du modèle :
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
Pour le modèle, vous utiliserez un simple réseau de neurones à convolution (CNN), puisque vous avez transformé les fichiers audio en images de spectrogramme.
Votre modèle tf.keras.Sequential utilisera les couches de prétraitement Keras suivantes :
-
tf.keras.layers.Resizing: pour sous-échantillonner l'entrée afin de permettre au modèle de s'entraîner plus rapidement. -
tf.keras.layers.Normalization: pour normaliser chaque pixel de l'image en fonction de sa moyenne et de son écart type.
Pour la couche de Normalization , sa méthode adapt devrait d'abord être appelée sur les données d'apprentissage afin de calculer des statistiques agrégées (c'est-à-dire la moyenne et l'écart type).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Configurez le modèle Keras avec l'optimiseur Adam et la perte d'entropie croisée :
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Entraînez le modèle sur 10 époques à des fins de démonstration :
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Traçons les courbes de perte d'entraînement et de validation pour vérifier comment votre modèle s'est amélioré pendant l'entraînement :
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Évaluer les performances du modèle
Exécutez le modèle sur l'ensemble de test et vérifiez les performances du modèle :
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
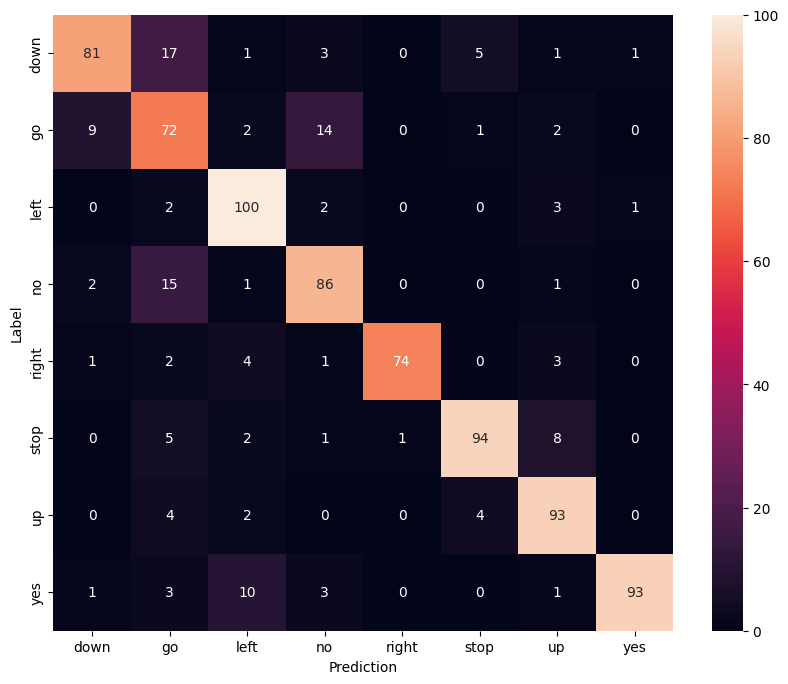
Afficher une matrice de confusion
Utilisez une matrice de confusion pour vérifier dans quelle mesure le modèle a classé chacune des commandes dans l'ensemble de test :
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
Exécuter l'inférence sur un fichier audio
Enfin, vérifiez la sortie de prédiction du modèle à l'aide d'un fichier audio d'entrée de quelqu'un qui dit "non". Quelle est la performance de votre modèle ?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
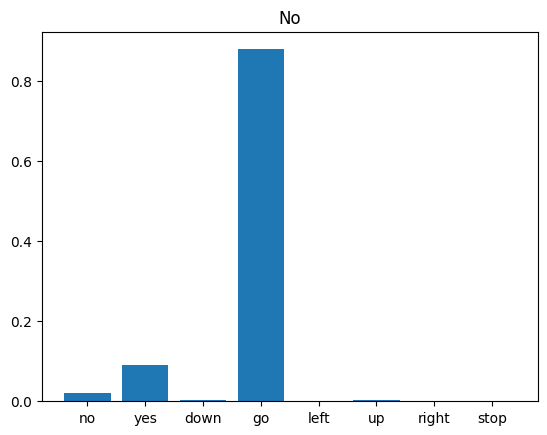
Comme le suggère la sortie, votre modèle devrait avoir reconnu la commande audio comme "non".
Prochaines étapes
Ce didacticiel a montré comment effectuer une simple classification audio/reconnaissance automatique de la parole à l'aide d'un réseau de neurones convolutifs avec TensorFlow et Python. Pour en savoir plus, consultez les ressources suivantes :
- Le didacticiel Classification du son avec YAMNet montre comment utiliser l'apprentissage par transfert pour la classification audio.
- Les cahiers du défi de reconnaissance vocale TensorFlow de Kaggle .
- L'atelier de programmation TensorFlow.js - Reconnaissance audio à l'aide de l'apprentissage par transfert explique comment créer votre propre application Web interactive pour la classification audio.
- Un tutoriel sur le deep learning pour la recherche d'informations musicales (Choi et al., 2017) sur arXiv.
- TensorFlow offre également une prise en charge supplémentaire de la préparation et de l'augmentation des données audio pour vous aider dans vos propres projets audio.
- Envisagez d'utiliser la bibliothèque librosa , un package Python pour l'analyse musicale et audio.