
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial demuestra cómo generar imágenes de dígitos escritos a mano utilizando una red antagónica generativa convolucional profunda (DCGAN). El código está escrito utilizando la API secuencial de Keras con un bucle de entrenamiento tf.GradientTape .
¿Qué son las GAN?
Las redes generativas antagónicas (GAN) son una de las ideas más interesantes de la informática actual. Dos modelos son entrenados simultáneamente por un proceso contradictorio. Un generador ("el artista") aprende a crear imágenes que parecen reales, mientras que un discriminador ("el crítico de arte") aprende a diferenciar las imágenes reales de las falsificaciones.
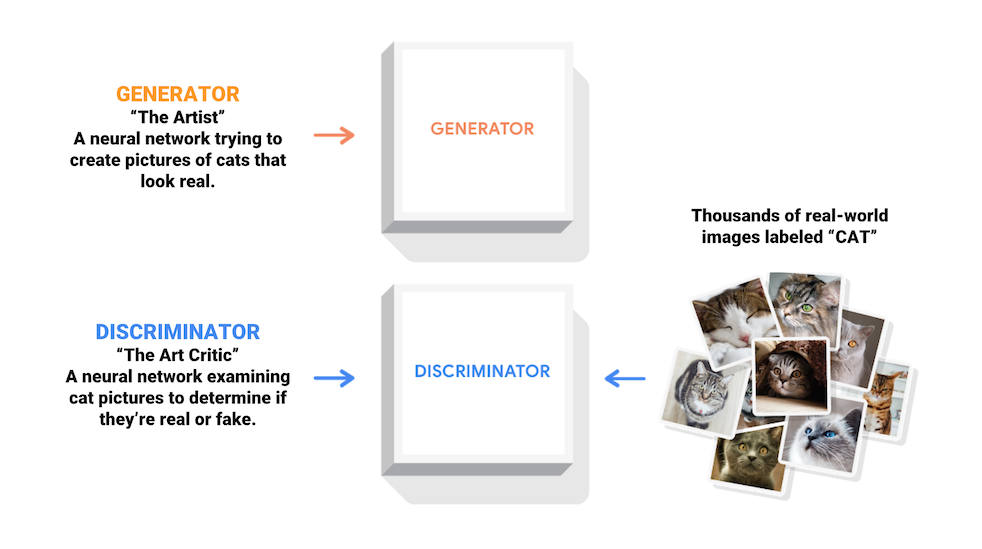
Durante el entrenamiento, el generador mejora progresivamente en la creación de imágenes que parecen reales, mientras que el discriminador mejora en diferenciarlas. El proceso alcanza el equilibrio cuando el discriminador ya no puede distinguir las imágenes reales de las falsificaciones.
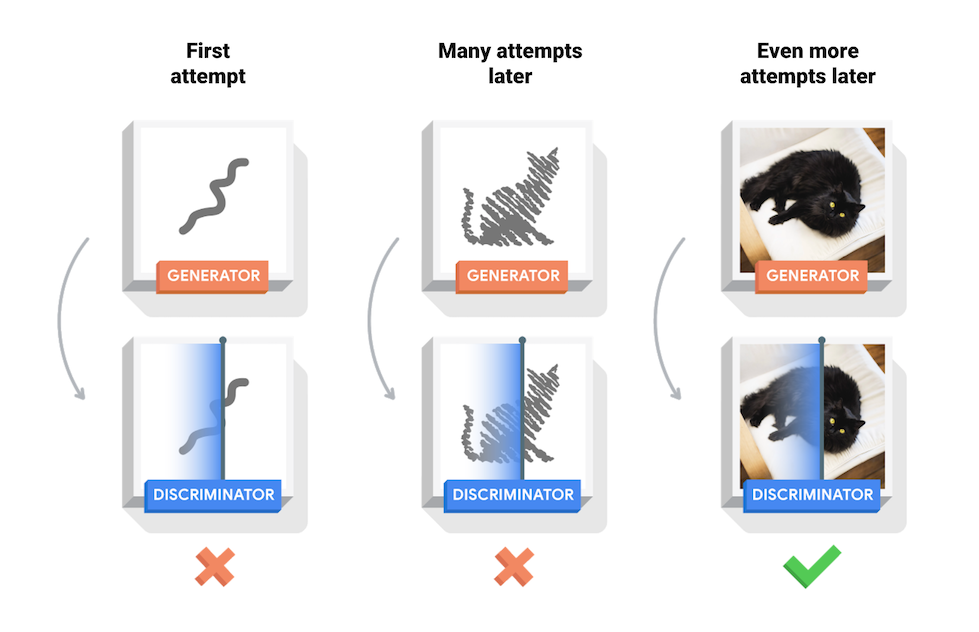
Este cuaderno demuestra este proceso en el conjunto de datos MNIST. La siguiente animación muestra una serie de imágenes producidas por el generador a medida que fue entrenado durante 50 épocas. Las imágenes comienzan como un ruido aleatorio y, con el tiempo, se parecen cada vez más a dígitos escritos a mano.

Para obtener más información sobre las GAN, consulte el curso Introducción al aprendizaje profundo del MIT.
Configuración
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
Cargue y prepare el conjunto de datos
Utilizará el conjunto de datos MNIST para entrenar el generador y el discriminador. El generador generará dígitos escritos a mano que se asemejan a los datos MNIST.
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
Crear los modelos
Tanto el generador como el discriminador se definen mediante la API secuencial de Keras .
El generador
El generador utiliza tf.keras.layers.Conv2DTranspose (sobremuestreo) para producir una imagen a partir de una semilla (ruido aleatorio). Comience con una capa Dense que tome esta semilla como entrada, luego aumente la muestra varias veces hasta alcanzar el tamaño de imagen deseado de 28x28x1. Observe la activación de tf.keras.layers.LeakyReLU para cada capa, excepto la capa de salida que usa tanh.
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
Use el generador (todavía no entrenado) para crear una imagen.
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

el discriminador
El discriminador es un clasificador de imágenes basado en CNN.
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
Utilice el discriminador (todavía no entrenado) para clasificar las imágenes generadas como reales o falsas. El modelo se entrenará para generar valores positivos para imágenes reales y valores negativos para imágenes falsas.
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
Definir la pérdida y los optimizadores.
Definir funciones de pérdida y optimizadores para ambos modelos.
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
Pérdida de discriminador
Este método cuantifica qué tan bien el discriminador es capaz de distinguir las imágenes reales de las falsificaciones. Compara las predicciones del discriminador sobre imágenes reales con una matriz de 1 y las predicciones del discriminador sobre imágenes falsas (generadas) con una matriz de 0.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
Pérdida del generador
La pérdida del generador cuantifica qué tan bien pudo engañar al discriminador. Intuitivamente, si el generador funciona bien, el discriminador clasificará las imágenes falsas como reales (o 1). Aquí, compare las decisiones de los discriminadores en las imágenes generadas con una matriz de 1.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
Los optimizadores discriminador y generador son diferentes ya que entrenará dos redes por separado.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
Guardar puntos de control
Este cuaderno también demuestra cómo guardar y restaurar modelos, lo que puede ser útil en caso de que se interrumpa una tarea de entrenamiento de larga duración.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Definir el ciclo de entrenamiento
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
El ciclo de entrenamiento comienza cuando el generador recibe una semilla aleatoria como entrada. Esa semilla se usa para producir una imagen. Luego, el discriminador se usa para clasificar imágenes reales (extraídas del conjunto de entrenamiento) e imágenes falsas (producidas por el generador). La pérdida se calcula para cada uno de estos modelos y los gradientes se utilizan para actualizar el generador y el discriminador.
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
Generar y guardar imágenes
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
entrenar al modelo
Llame al método train() definido anteriormente para entrenar el generador y el discriminador simultáneamente. Tenga en cuenta que entrenar GAN puede ser complicado. Es importante que el generador y el discriminador no se dominen entre sí (p. ej., que entrenen a un ritmo similar).
Al comienzo del entrenamiento, las imágenes generadas parecen ruido aleatorio. A medida que avanza el entrenamiento, los dígitos generados se verán cada vez más reales. Después de unas 50 épocas, se asemejan a los dígitos MNIST. Esto puede demorar aproximadamente un minuto por época con la configuración predeterminada en Colab.
train(train_dataset, EPOCHS)

Restaurar el último punto de control.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
crear un GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

Usa imageio para crear un gif animado usando las imágenes guardadas durante el entrenamiento.
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Próximos pasos
Este tutorial ha mostrado el código completo necesario para escribir y entrenar una GAN. Como siguiente paso, es posible que desee experimentar con un conjunto de datos diferente, por ejemplo, el conjunto de datos de atributos de rostros de celebridades a gran escala (CelebA) disponible en Kaggle . Para obtener más información sobre las GAN, consulte el Tutorial de NIPS 2016: Redes antagónicas generativas .