
|
|
|
 View source on GitHub
View source on GitHub
|
|
This tutorial demonstrates how to generate images of handwritten digits using a Deep Convolutional Generative Adversarial Network (DCGAN). The code is written using the Keras Sequential API with a tf.GradientTape training loop.
What are GANs?
Generative Adversarial Networks (GANs) are one of the most interesting ideas in computer science today. Two models are trained simultaneously by an adversarial process. A generator ("the artist") learns to create images that look real, while a discriminator ("the art critic") learns to tell real images apart from fakes.
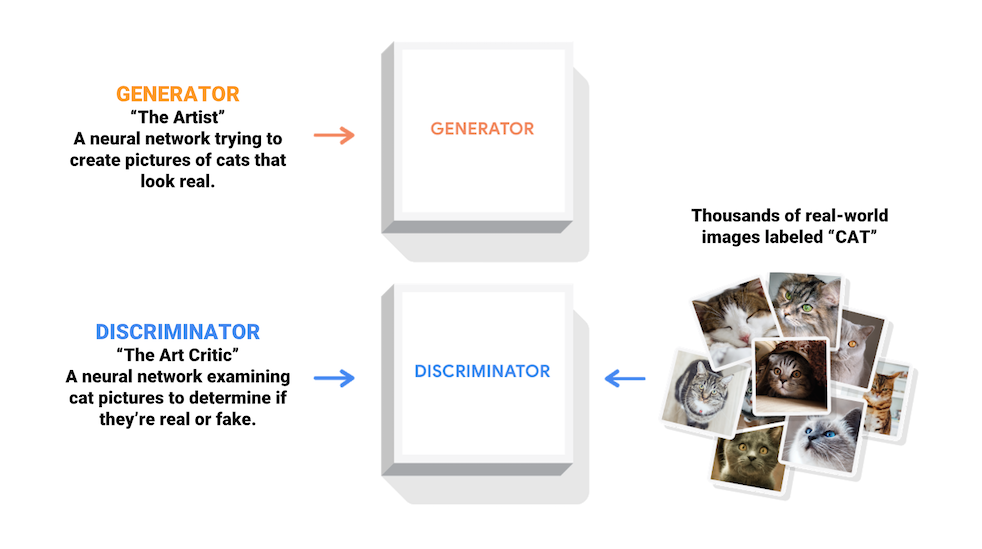
During training, the generator progressively becomes better at creating images that look real, while the discriminator becomes better at telling them apart. The process reaches equilibrium when the discriminator can no longer distinguish real images from fakes.
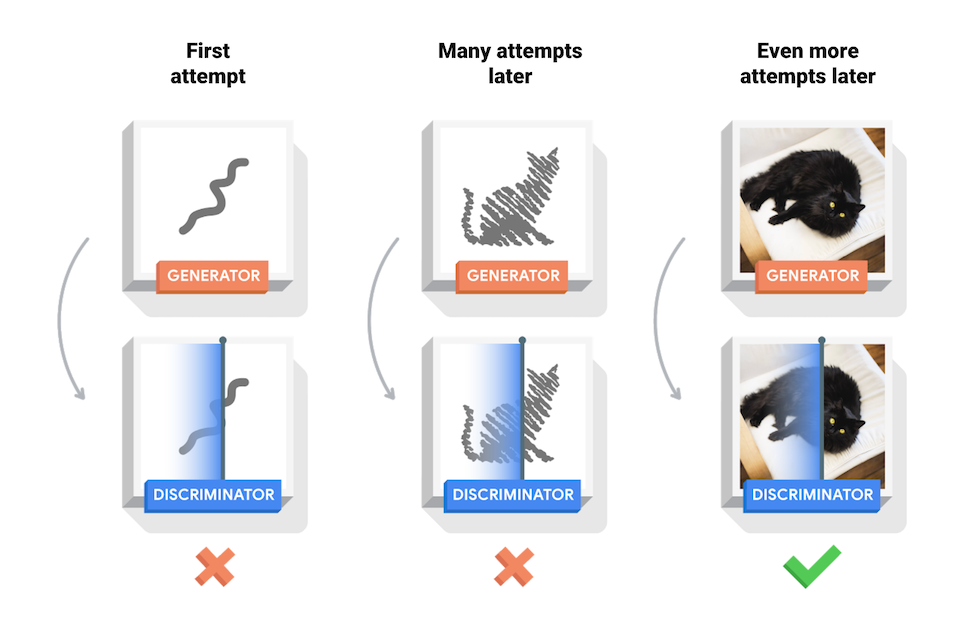
This notebook demonstrates this process on the MNIST dataset. The following animation shows a series of images produced by the generator as it was trained for 50 epochs. The images begin as random noise, and increasingly resemble hand written digits over time.

To learn more about GANs, see MIT's Intro to Deep Learning course.
Setup
import tensorflow as tf
2024-08-16 06:32:45.015549: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-08-16 06:32:45.036284: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-08-16 06:32:45.042482: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
tf.__version__
'2.17.0'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
Load and prepare the dataset
You will use the MNIST dataset to train the generator and the discriminator. The generator will generate handwritten digits resembling the MNIST data.
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1723789973.811300 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.815200 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.818846 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.822539 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.834632 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.838150 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.841574 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.844956 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.848426 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.851903 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.855314 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789973.858808 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.100045 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.102173 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.104239 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.106192 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.108237 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.110183 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.112199 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.114071 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.116009 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.117945 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.120016 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.121872 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.159897 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.161930 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.163934 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.166367 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.168201 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.170159 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.172123 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.174004 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.175870 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.178408 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.180831 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723789975.183150 174689 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
Create the models
Both the generator and discriminator are defined using the Keras Sequential API.
The Generator
The generator uses tf.keras.layers.Conv2DTranspose (upsampling) layers to produce an image from a seed (random noise). Start with a Dense layer that takes this seed as input, then upsample several times until you reach the desired image size of 28x28x1. Notice the tf.keras.layers.LeakyReLU activation for each layer, except the output layer which uses tanh.
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
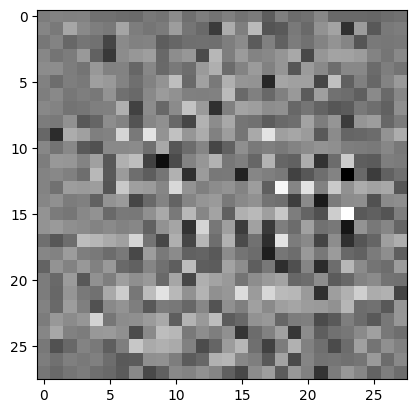
Use the (as yet untrained) generator to create an image.
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/layers/core/dense.py:87: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead. super().__init__(activity_regularizer=activity_regularizer, **kwargs) W0000 00:00:1723789976.899989 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789976.926511 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789976.928496 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789976.929818 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789976.931337 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789976.971816 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789976.980776 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789976.999036 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.003393 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.032526 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.048252 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.049424 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.050581 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.051736 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.052917 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.054531 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.109358 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.112654 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.121306 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.122470 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.123600 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.124762 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.125930 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.127257 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.128571 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.129815 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced <matplotlib.image.AxesImage at 0x7f730c2a83a0>
The Discriminator
The discriminator is a CNN-based image classifier.
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
Use the (as yet untrained) discriminator to classify the generated images as real or fake. The model will be trained to output positive values for real images, and negative values for fake images.
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[0.00357757]], shape=(1, 1), dtype=float32) /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/layers/convolutional/base_conv.py:107: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead. super().__init__(activity_regularizer=activity_regularizer, **kwargs) W0000 00:00:1723789977.415503 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.422830 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.426039 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.427237 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.428359 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.431492 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.432673 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.433841 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.435037 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.436201 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.454917 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.456118 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.457251 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.458415 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.468295 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.469644 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.471012 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.472515 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.474116 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.475706 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.477290 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.478837 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.480442 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.482068 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.483698 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.485061 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.486803 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.488627 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723789977.489960 174689 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
Define the loss and optimizers
Define loss functions and optimizers for both models.
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
Discriminator loss
This method quantifies how well the discriminator is able to distinguish real images from fakes. It compares the discriminator's predictions on real images to an array of 1s, and the discriminator's predictions on fake (generated) images to an array of 0s.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
Generator loss
The generator's loss quantifies how well it was able to trick the discriminator. Intuitively, if the generator is performing well, the discriminator will classify the fake images as real (or 1). Here, compare the discriminators decisions on the generated images to an array of 1s.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
The discriminator and the generator optimizers are different since you will train two networks separately.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
Save checkpoints
This notebook also demonstrates how to save and restore models, which can be helpful in case a long running training task is interrupted.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Define the training loop
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
The training loop begins with generator receiving a random seed as input. That seed is used to produce an image. The discriminator is then used to classify real images (drawn from the training set) and fakes images (produced by the generator). The loss is calculated for each of these models, and the gradients are used to update the generator and discriminator.
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
Generate and save images
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Train the model
Call the train() method defined above to train the generator and discriminator simultaneously. Note, training GANs can be tricky. It's important that the generator and discriminator do not overpower each other (e.g., that they train at a similar rate).
At the beginning of the training, the generated images look like random noise. As training progresses, the generated digits will look increasingly real. After about 50 epochs, they resemble MNIST digits. This may take about one minute / epoch with the default settings on Colab.
train(train_dataset, EPOCHS)

Restore the latest checkpoint.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f730c28dd30>
Create a GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

Use imageio to create an animated gif using the images saved during training.
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
/tmpfs/tmp/ipykernel_174689/1982054950.py:7: DeprecationWarning: Starting with ImageIO v3 the behavior of this function will switch to that of iio.v3.imread. To keep the current behavior (and make this warning disappear) use `import imageio.v2 as imageio` or call `imageio.v2.imread` directly. image = imageio.imread(filename) /tmpfs/tmp/ipykernel_174689/1982054950.py:9: DeprecationWarning: Starting with ImageIO v3 the behavior of this function will switch to that of iio.v3.imread. To keep the current behavior (and make this warning disappear) use `import imageio.v2 as imageio` or call `imageio.v2.imread` directly. image = imageio.imread(filename)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Next steps
This tutorial has shown the complete code necessary to write and train a GAN. As a next step, you might like to experiment with a different dataset, for example the Large-scale Celeb Faces Attributes (CelebA) dataset available on Kaggle. To learn more about GANs see the NIPS 2016 Tutorial: Generative Adversarial Networks.