
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial demonstra como gerar imagens de dígitos manuscritos usando uma Deep Convolutional Generative Adversarial Network (DCGAN). O código é escrito usando a API Keras Sequential com um loop de treinamento tf.GradientTape .
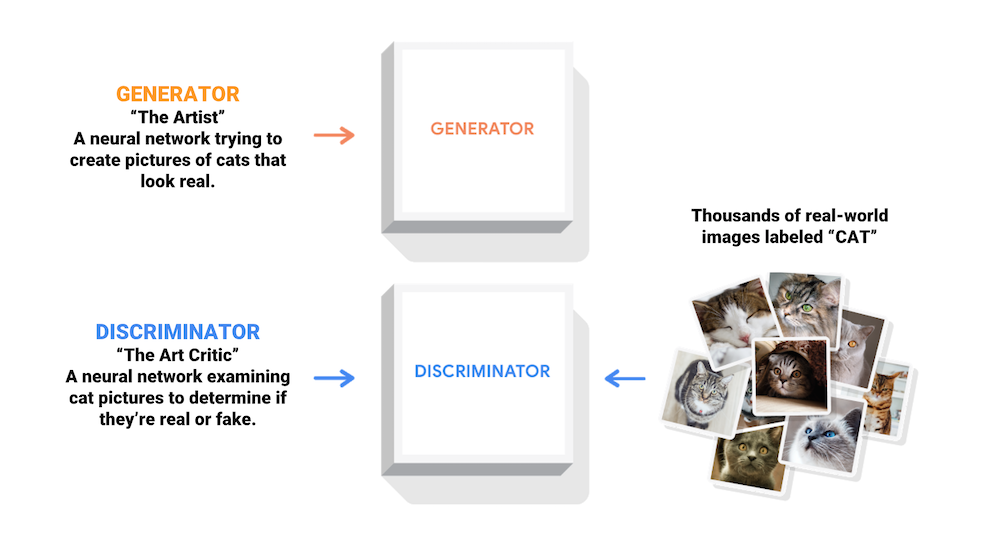
O que são GANs?
Generative Adversarial Networks (GANs) são uma das ideias mais interessantes da ciência da computação atualmente. Dois modelos são treinados simultaneamente por um processo adversário. Um gerador ("o artista") aprende a criar imagens que parecem reais, enquanto um discriminador ("o crítico de arte") aprende a distinguir imagens reais de falsificações.
Durante o treinamento, o gerador se torna progressivamente melhor em criar imagens que parecem reais, enquanto o discriminador se torna melhor em diferenciá-las. O processo atinge o equilíbrio quando o discriminador não consegue mais distinguir imagens reais de falsificações.
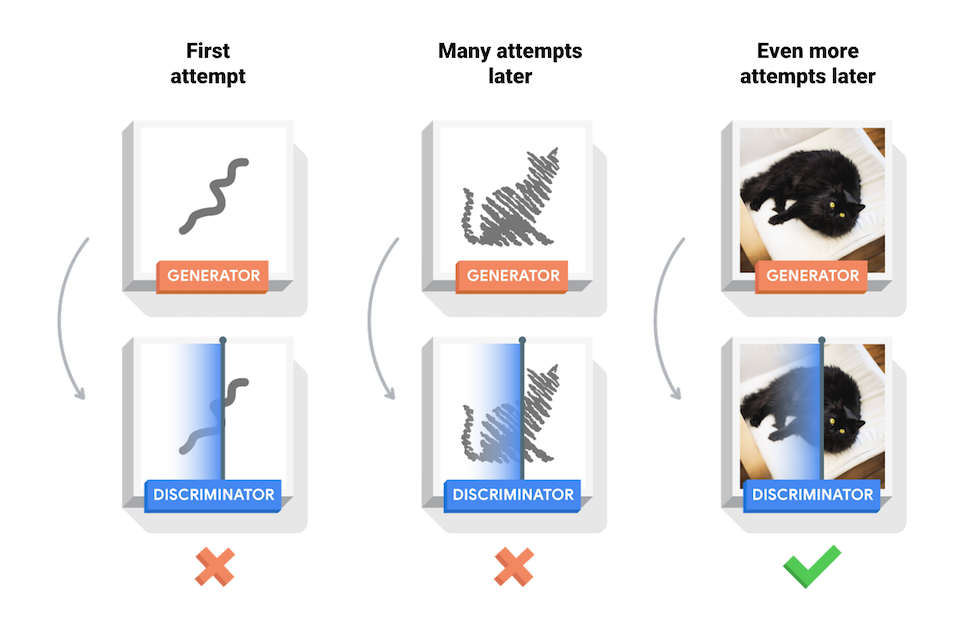
Este notebook demonstra esse processo no conjunto de dados MNIST. A animação a seguir mostra uma série de imagens produzidas pelo gerador conforme ele foi treinado por 50 épocas. As imagens começam como ruído aleatório, e cada vez mais se assemelham a dígitos escritos à mão ao longo do tempo.

Para saber mais sobre GANs, consulte o curso Intro to Deep Learning do MIT.
Configurar
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
Carregar e preparar o conjunto de dados
Você usará o conjunto de dados MNIST para treinar o gerador e o discriminador. O gerador irá gerar dígitos manuscritos semelhantes aos dados MNIST.
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
Crie os modelos
Tanto o gerador quanto o discriminador são definidos usando a API Keras Sequential .
O Gerador
O gerador usa camadas tf.keras.layers.Conv2DTranspose (upsampling) para produzir uma imagem a partir de uma semente (ruído aleatório). Comece com uma camada Dense que recebe essa semente como entrada e, em seguida, faça o upsample várias vezes até atingir o tamanho de imagem desejado de 28x28x1. Observe a ativação de tf.keras.layers.LeakyReLU para cada camada, exceto a camada de saída que usa tanh.
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
Use o gerador (ainda não treinado) para criar uma imagem.
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

O discriminador
O discriminador é um classificador de imagens baseado em CNN.
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
Use o discriminador (ainda não treinado) para classificar as imagens geradas como reais ou falsas. O modelo será treinado para gerar valores positivos para imagens reais e valores negativos para imagens falsas.
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
Defina a perda e os otimizadores
Defina funções de perda e otimizadores para ambos os modelos.
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
Perda do discriminador
Este método quantifica quão bem o discriminador é capaz de distinguir imagens reais de falsificações. Ele compara as previsões do discriminador em imagens reais com uma matriz de 1s e as previsões do discriminador em imagens falsas (geradas) com uma matriz de 0s.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
Perda do gerador
A perda do gerador quantifica quão bem ele foi capaz de enganar o discriminador. Intuitivamente, se o gerador estiver funcionando bem, o discriminador classificará as imagens falsas como reais (ou 1). Aqui, compare as decisões dos discriminadores nas imagens geradas com uma matriz de 1s.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
O discriminador e os otimizadores do gerador são diferentes, pois você treinará duas redes separadamente.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
Salvar pontos de verificação
Este notebook também demonstra como salvar e restaurar modelos, o que pode ser útil caso uma tarefa de treinamento de longa duração seja interrompida.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Definir o loop de treinamento
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
O loop de treinamento começa com o gerador recebendo uma semente aleatória como entrada. Essa semente é usada para produzir uma imagem. O discriminador é então usado para classificar imagens reais (retiradas do conjunto de treinamento) e imagens falsas (produzidas pelo gerador). A perda é calculada para cada um desses modelos e os gradientes são usados para atualizar o gerador e o discriminador.
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
Gerar e salvar imagens
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Treine o modelo
Chame o método train() definido acima para treinar o gerador e o discriminador simultaneamente. Observe que treinar GANs pode ser complicado. É importante que o gerador e o discriminador não se sobreponham (por exemplo, que eles treinem em uma taxa semelhante).
No início do treinamento, as imagens geradas parecem ruídos aleatórios. À medida que o treinamento avança, os dígitos gerados parecerão cada vez mais reais. Após cerca de 50 épocas, eles se assemelham a dígitos MNIST. Isso pode levar cerca de um minuto/época com as configurações padrão no Colab.
train(train_dataset, EPOCHS)

Restaure o último ponto de verificação.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
Criar um GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

Use imageio para criar um gif animado usando as imagens salvas durante o treino.
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Próximos passos
Este tutorial mostrou o código completo necessário para escrever e treinar um GAN. Como próxima etapa, você pode experimentar um conjunto de dados diferente, por exemplo, o conjunto de dados de atributos de rostos de celebridades em grande escala (CelebA) disponível no Kaggle . Para saber mais sobre GANs, consulte o Tutorial NIPS 2016: Generative Adversarial Networks .