
| | |  Ver no GitHub Ver no GitHub | | |
Este tutorial usa aprendizado profundo para compor uma imagem no estilo de outra imagem (já desejou poder pintar como Picasso ou Van Gogh?). Isso é conhecido como transferência de estilo neural e a técnica é descrita em A Neural Algorithm of Artistic Style (Gatys et al.).
Para uma aplicação simples de transferência de estilo, confira este tutorial para saber mais sobre como usar o modelo de estilização de imagem arbitrária pré-treinado do TensorFlow Hub ou como usar um modelo de transferência de estilo com o TensorFlow Lite .
A transferência de estilo neural é uma técnica de otimização usada para pegar duas imagens - uma imagem de conteúdo e uma imagem de referência de estilo (como uma obra de arte de um pintor famoso) - e misturá-las para que a imagem de saída se pareça com a imagem de conteúdo, mas "pintada" no estilo da imagem de referência de estilo.
Isso é implementado otimizando a imagem de saída para corresponder às estatísticas de conteúdo da imagem de conteúdo e às estatísticas de estilo da imagem de referência de estilo. Essas estatísticas são extraídas das imagens usando uma rede convolucional.
Por exemplo, vamos tirar uma imagem deste cachorro e a Composição 7 de Wassily Kandinsky:

Olhar do Labrador Amarelo , do Wikimedia Commons por Elf . Licença CC BY-SA 3.0
{kind=link}

Agora, como seria se Kandinsky decidisse pintar a imagem desse Cão exclusivamente com esse estilo? Algo assim?

Configurar
Importar e configurar módulos
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Baixe imagens e escolha uma imagem de estilo e uma imagem de conteúdo:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Visualize a entrada
Defina uma função para carregar uma imagem e limite sua dimensão máxima a 512 pixels.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Crie uma função simples para exibir uma imagem:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Transferência rápida de estilo usando o TF-Hub
Este tutorial demonstra o algoritmo de transferência de estilo original, que otimiza o conteúdo da imagem para um estilo específico. Antes de entrar em detalhes, vamos ver como o modelo do TensorFlow Hub faz isso:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
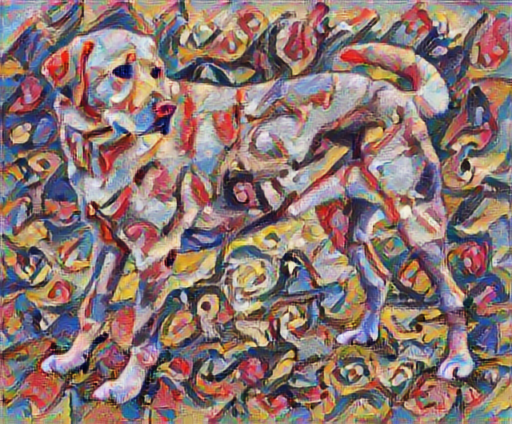
Definir representações de conteúdo e estilo
Use as camadas intermediárias do modelo para obter as representações de conteúdo e estilo da imagem. A partir da camada de entrada da rede, as primeiras ativações de camada representam recursos de baixo nível, como bordas e texturas. À medida que você percorre a rede, as camadas finais representam recursos de nível superior - partes de objetos como rodas ou olhos . Nesse caso, você está usando a arquitetura de rede VGG19, uma rede de classificação de imagem pré-treinada. Essas camadas intermediárias são necessárias para definir a representação de conteúdo e estilo das imagens. Para uma imagem de entrada, tente corresponder o estilo correspondente e as representações de destino de conteúdo nessas camadas intermediárias.
Carregue um VGG19 e teste-o em nossa imagem para garantir que seja usado corretamente:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Agora carregue um VGG19 sem o cabeçalho de classificação e liste os nomes das camadas
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Escolha camadas intermediárias da rede para representar o estilo e o conteúdo da imagem:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Camadas intermediárias para estilo e conteúdo
Então, por que essas saídas intermediárias dentro de nossa rede de classificação de imagens pré-treinadas nos permitem definir representações de estilo e conteúdo?
Em um nível alto, para que uma rede execute a classificação de imagens (para a qual essa rede foi treinada), ela deve entender a imagem. Isso requer tomar a imagem bruta como pixels de entrada e construir uma representação interna que converta os pixels da imagem bruta em uma compreensão complexa dos recursos presentes na imagem.
Essa também é uma razão pela qual as redes neurais convolucionais são capazes de generalizar bem: elas são capazes de capturar as invariâncias e características definidoras dentro de classes (por exemplo, gatos vs. cães) que são agnósticas ao ruído de fundo e outros incômodos. Assim, em algum lugar entre onde a imagem bruta é alimentada no modelo e o rótulo de classificação de saída, o modelo serve como um extrator de recursos complexos. Ao acessar as camadas intermediárias do modelo, você pode descrever o conteúdo e o estilo das imagens de entrada.
Construir o modelo
As redes em tf.keras.applications são projetadas para que você possa extrair facilmente os valores da camada intermediária usando a API funcional Keras.
Para definir um modelo usando a API funcional, especifique as entradas e saídas:
model = Model(inputs, outputs)
Esta função a seguir cria um modelo VGG19 que retorna uma lista de saídas da camada intermediária:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
E para criar o modelo:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Calcular estilo
O conteúdo de uma imagem é representado pelos valores dos mapas de recursos intermediários.
Acontece que o estilo de uma imagem pode ser descrito pelos meios e correlações entre os diferentes mapas de recursos. Calcule uma matriz Gram que inclua essa informação tomando o produto externo do vetor de características consigo mesmo em cada local e calculando a média desse produto externo em todos os locais. Esta matriz Gram pode ser calculada para uma camada particular como:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Isso pode ser implementado de forma concisa usando a função tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Extrair estilo e conteúdo
Construa um modelo que retorne os tensores de estilo e conteúdo.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Quando chamado em uma imagem, este modelo retorna a matriz grama (estilo) do style_layers e o conteúdo do content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Executar descida de gradiente
Com este extrator de estilo e conteúdo, agora você pode implementar o algoritmo de transferência de estilo. Faça isso calculando o erro quadrático médio para a saída da sua imagem em relação a cada alvo e, em seguida, faça a soma ponderada dessas perdas.
Defina seus valores de destino de estilo e conteúdo:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Defina uma tf.Variable para conter a imagem a ser otimizada. Para agilizar, inicialize-o com a imagem do conteúdo (a tf.Variable deve ter a mesma forma que a imagem do conteúdo):
image = tf.Variable(content_image)
Como esta é uma imagem flutuante, defina uma função para manter os valores de pixel entre 0 e 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Crie um otimizador. O jornal recomenda o LBFGS, mas Adam também funciona bem:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Para otimizar isso, use uma combinação ponderada das duas perdas para obter a perda total:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Use tf.GradientTape para atualizar a imagem.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Agora execute alguns passos para testar:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Como está funcionando, faça uma otimização mais longa:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Perda de variação total
Uma desvantagem dessa implementação básica é que ela produz muitos artefatos de alta frequência. Diminua-os usando um termo de regularização explícito nos componentes de alta frequência da imagem. Na transferência de estilo, isso geralmente é chamado de perda total de variação :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
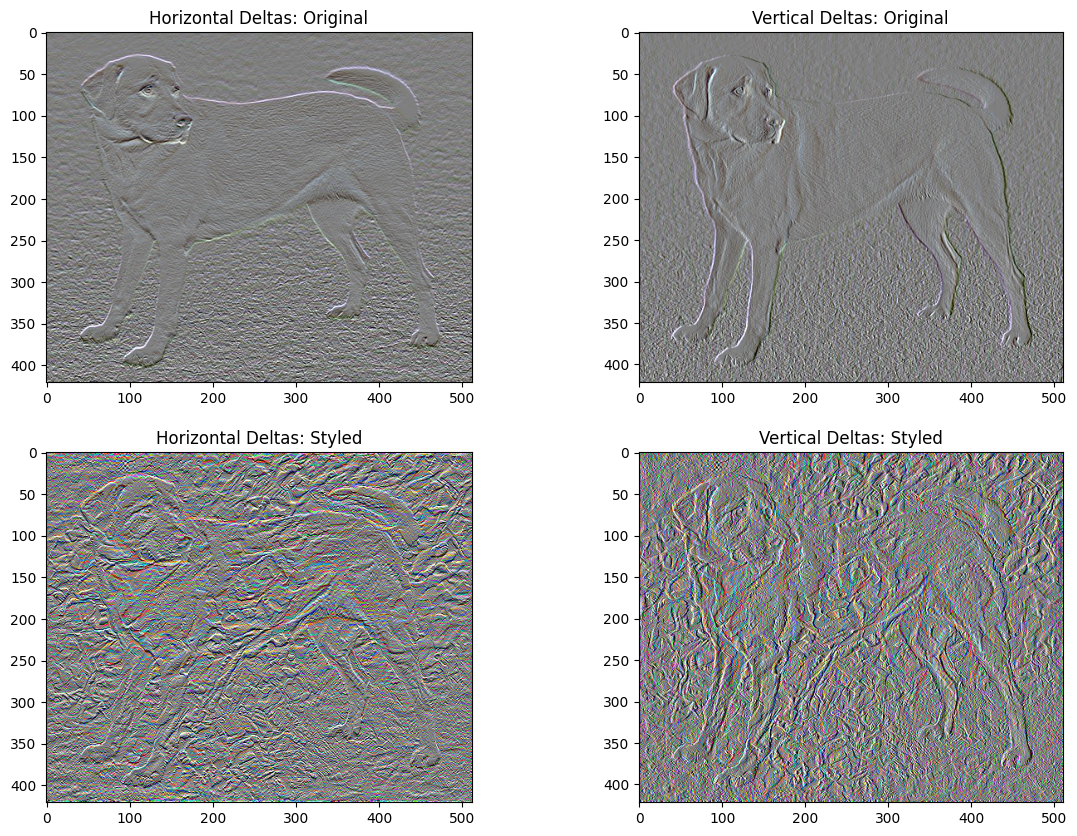
Isso mostra como os componentes de alta frequência aumentaram.
Além disso, este componente de alta frequência é basicamente um detector de borda. Você pode obter uma saída semelhante do detector de borda Sobel, por exemplo:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
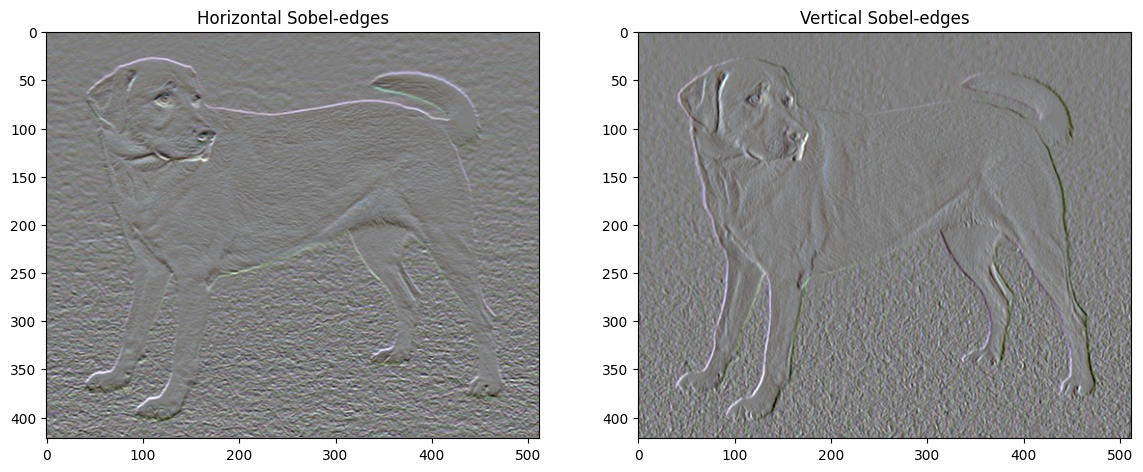
A perda de regularização associada a isso é a soma dos quadrados dos valores:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Isso demonstrou o que faz. Mas não há necessidade de implementar você mesmo, o TensorFlow inclui uma implementação padrão:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Execute novamente a otimização
Escolha um peso para total_variation_loss :
total_variation_weight=30
Agora inclua-o na função train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Reinicie a variável de otimização:
image = tf.Variable(content_image)
E execute a otimização:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Por fim, salve o resultado:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Saber mais
Este tutorial demonstra o algoritmo de transferência de estilo original. Para uma aplicação simples de transferência de estilo, confira este tutorial para saber mais sobre como usar o modelo de transferência de estilo de imagem arbitrário do TensorFlow Hub .