
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Descripción general
Este tutorial demuestra el aumento de datos: una técnica para aumentar la diversidad de su conjunto de entrenamiento mediante la aplicación de transformaciones aleatorias (pero realistas), como la rotación de imágenes.
Aprenderá cómo aplicar el aumento de datos de dos maneras:
- Utilice las capas de preprocesamiento de Keras, como
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlipytf.keras.layers.RandomRotation. - Utilice los métodos
tf.image, comotf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_cropytf.image.stateless_random*.
Configuración
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Descargar un conjunto de datos
Este tutorial utiliza el conjunto de datos tf_flowers . Para mayor comodidad, descargue el conjunto de datos mediante TensorFlow Datasets . Si desea conocer otras formas de importar datos, consulte el tutorial de carga de imágenes .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
El conjunto de datos de flores tiene cinco clases.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
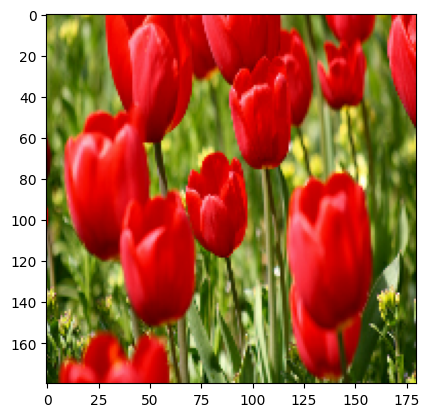
Recuperemos una imagen del conjunto de datos y usémosla para demostrar el aumento de datos.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Usar capas de preprocesamiento de Keras
Redimensionamiento y reescalado
Puede usar las capas de preprocesamiento de Keras para cambiar el tamaño de sus imágenes a una forma consistente (con tf.keras.layers.Resizing ) y para cambiar la escala de los valores de píxeles (con tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
Puedes visualizar el resultado de aplicar estas capas a una imagen.
result = resize_and_rescale(image)
_ = plt.imshow(result)
Verifique que los píxeles estén en el rango [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Aumento de datos
También puede usar las capas de preprocesamiento de Keras para el aumento de datos, como tf.keras.layers.RandomFlip y tf.keras.layers.RandomRotation .
Vamos a crear algunas capas de preprocesamiento y aplicarlas repetidamente a la misma imagen.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Hay una variedad de capas de preprocesamiento que puede usar para el aumento de datos, incluidas tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom y otras.
Dos opciones para usar las capas de preprocesamiento de Keras
Hay dos formas de utilizar estas capas de preprocesamiento, con importantes compensaciones.
Opción 1: haga que las capas de preprocesamiento formen parte de su modelo
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
Hay dos puntos importantes a tener en cuenta en este caso:
El aumento de datos se ejecutará en el dispositivo, de forma sincronizada con el resto de sus capas, y se beneficiará de la aceleración de la GPU.
Cuando exporta su modelo usando
model.save, las capas de preprocesamiento se guardarán junto con el resto de su modelo. Si luego implementa este modelo, automáticamente estandarizará las imágenes (según la configuración de sus capas). Esto puede ahorrarle el esfuerzo de tener que volver a implementar esa lógica del lado del servidor.
Opción 2: aplique las capas de preprocesamiento a su conjunto de datos
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
Con este enfoque, utiliza Dataset.map para crear un conjunto de datos que produce lotes de imágenes aumentadas. En este caso:
- El aumento de datos ocurrirá de forma asíncrona en la CPU y no bloqueará. Puede superponer el entrenamiento de su modelo en la GPU con el preprocesamiento de datos, utilizando
Dataset.prefetch, que se muestra a continuación. - En este caso, las capas de preprocesamiento no se exportarán con el modelo cuando llame a
Model.save. Deberá adjuntarlos a su modelo antes de guardarlo o volver a implementarlos en el lado del servidor. Después del entrenamiento, puede adjuntar las capas de preprocesamiento antes de exportar.
Puede encontrar un ejemplo de la primera opción en el tutorial Clasificación de imágenes . Vamos a demostrar la segunda opción aquí.
Aplicar las capas de preprocesamiento a los conjuntos de datos
Configure los conjuntos de datos de entrenamiento, validación y prueba con las capas de preprocesamiento de Keras que creó anteriormente. También configurará los conjuntos de datos para el rendimiento, utilizando lecturas paralelas y búsqueda previa almacenada en búfer para generar lotes desde el disco sin que la E/S se convierta en un bloqueo. (Obtenga más información sobre el rendimiento del conjunto de datos en la guía Mejor rendimiento con la API tf.data ).
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
entrenar a un modelo
Para completar, ahora entrenará un modelo utilizando los conjuntos de datos que acaba de preparar.
El modelo secuencial consta de tres bloques de convolución ( tf.keras.layers.Conv2D ) con una capa de agrupación máxima ( tf.keras.layers.MaxPooling2D ) en cada uno de ellos. Hay una capa totalmente conectada ( tf.keras.layers.Dense ) con 128 unidades encima que se activa mediante una función de activación de ReLU ( 'relu' ). Este modelo no ha sido ajustado para precisión (el objetivo es mostrarle la mecánica).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Elija el optimizador tf.keras.optimizers.Adam y la función de pérdida tf.keras.losses.SparseCategoricalCrossentropy . Para ver la precisión del entrenamiento y la validación para cada época de entrenamiento, pase el argumento de metrics a Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Entrena por algunas épocas:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Aumento de datos personalizado
También puede crear capas de aumento de datos personalizadas.
Esta sección del tutorial muestra dos formas de hacerlo:
- Primero, creará una capa
tf.keras.layers.Lambda. Esta es una buena manera de escribir código conciso. - A continuación, escribirá una nueva capa a través de subclases , lo que le brinda más control.
Ambas capas invertirán aleatoriamente los colores de una imagen, según alguna probabilidad.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

A continuación, implemente una capa personalizada mediante subclases :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Ambas capas se pueden usar como se describe en las opciones 1 y 2 anteriores.
Usando tf.imagen
Las utilidades de preprocesamiento de Keras anteriores son convenientes. Pero, para un control más preciso, puede escribir sus propias canalizaciones o capas de aumento de datos utilizando tf.data y tf.image . (Es posible que también desee consultar Imagen de complementos de TensorFlow: operaciones y E/S de TensorFlow: conversiones de espacio de color ).
Dado que el conjunto de datos de flores se configuró previamente con el aumento de datos, volvamos a importarlo para comenzar de nuevo:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Recuperar una imagen para trabajar con:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Usemos la siguiente función para visualizar y comparar las imágenes originales y aumentadas una al lado de la otra:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Aumento de datos
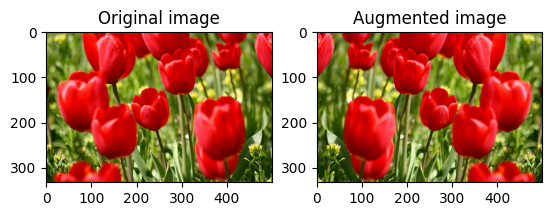
Voltear una imagen
Voltea una imagen ya sea vertical u horizontalmente con tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
escala de grises una imagen
Puede escalar una imagen en escala de grises con tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

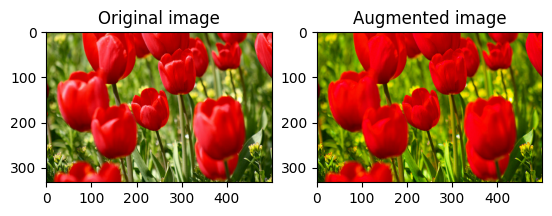
Saturar una imagen
Sature una imagen con tf.image.adjust_saturation proporcionando un factor de saturación:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
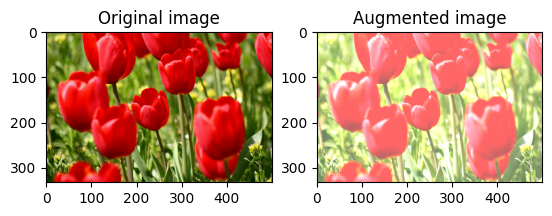
Cambiar el brillo de la imagen
Cambie el brillo de la imagen con tf.image.adjust_brightness proporcionando un factor de brillo:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
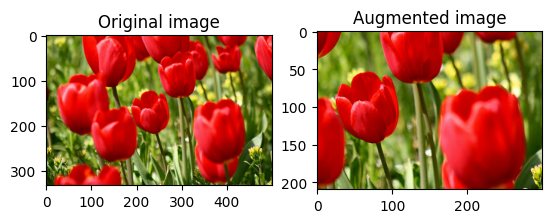
Recortar al centro una imagen
Recorta la imagen desde el centro hasta la parte de la imagen que desees usando tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
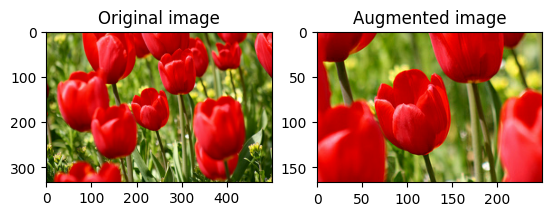
Girar una imagen
Gire una imagen 90 grados con tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

Transformaciones aleatorias
Aplicar transformaciones aleatorias a las imágenes puede ayudar aún más a generalizar y expandir el conjunto de datos. La API tf.image actual proporciona ocho operaciones de imagen aleatorias (ops):
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Estas operaciones de imágenes aleatorias son puramente funcionales: la salida solo depende de la entrada. Esto los hace fáciles de usar en canalizaciones de entrada deterministas de alto rendimiento. Requieren que se ingrese un valor seed en cada paso. Dada la misma seed , devuelven los mismos resultados independientemente de cuántas veces se llamen.
En las siguientes secciones, usted:
- Repase ejemplos del uso de operaciones aleatorias de imágenes para transformar una imagen.
- Demostrar cómo aplicar transformaciones aleatorias a un conjunto de datos de entrenamiento.
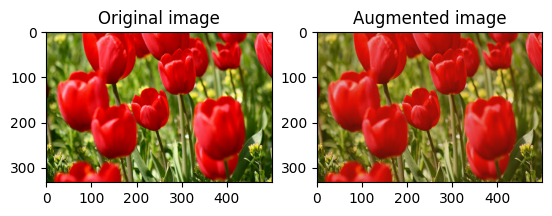
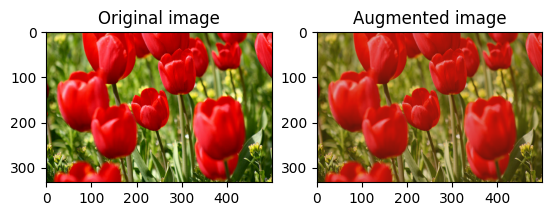
Cambiar aleatoriamente el brillo de la imagen
Cambie aleatoriamente el brillo de la image usando tf.image.stateless_random_brightness al proporcionar un factor de brillo y una seed . El factor de brillo se elige aleatoriamente en el rango [-max_delta, max_delta) y está asociado con la seed dada.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
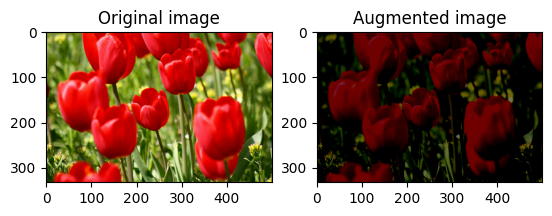
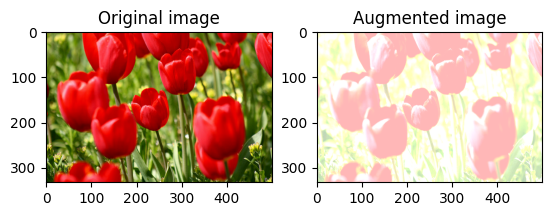
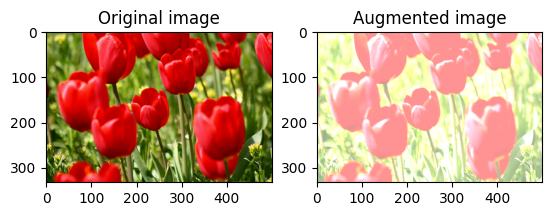
Cambiar aleatoriamente el contraste de la imagen
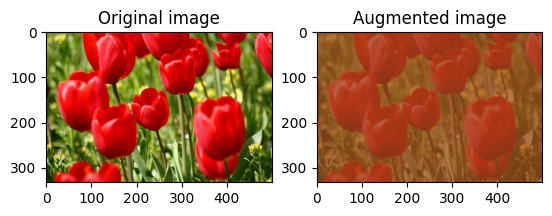
Cambie aleatoriamente el contraste de la image usando tf.image.stateless_random_contrast proporcionando un rango de contraste y seed . El rango de contraste se elige aleatoriamente en el intervalo [lower, upper] y se asocia con la seed dada.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
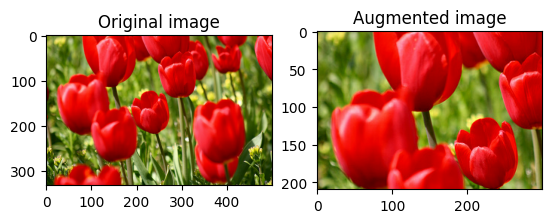
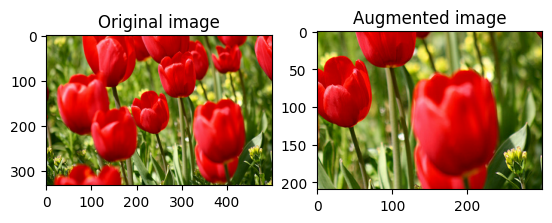
Recortar aleatoriamente una imagen
Recorte aleatoriamente la image usando tf.image.stateless_random_crop al proporcionar el size objetivo y seed . La parte que se recorta de la image se encuentra en un desplazamiento elegido al azar y se asocia con la seed dada.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
Aplicar aumento a un conjunto de datos
Primero descarguemos el conjunto de datos de imágenes nuevamente en caso de que se hayan modificado en las secciones anteriores.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
A continuación, defina una función de utilidad para cambiar el tamaño y la escala de las imágenes. Esta función se utilizará para unificar el tamaño y la escala de las imágenes en el conjunto de datos:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Definamos también la función de augment que puede aplicar las transformaciones aleatorias a las imágenes. Esta función se usará en el conjunto de datos en el siguiente paso.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Opción 1: usar tf.data.experimental.Counter
Cree un objeto tf.data.experimental.Counter (llamémoslo counter ) y Dataset.zip el conjunto de datos con (counter, counter) . Esto asegurará que cada imagen en el conjunto de datos se asocie con un valor único (de forma (2,) ) basado en el counter que luego se puede pasar a la función de augment como valor seed para transformaciones aleatorias.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
augment la función de aumento al conjunto de datos de entrenamiento:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Opción 2: Usar tf.random.Generator
- Cree un objeto
tf.random.Generatorcon un valorseedinicial. Llamar a la funciónmake_seedsen el mismo objeto generador siempre devuelve un nuevo valorseedúnico. - Defina una función contenedora que: 1) llame a la función
make_seeds; y 2) pasa el valorseedrecién generado a la función deaugmentpara transformaciones aleatorias.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
Asigne la función contenedora f al conjunto de datos de entrenamiento y la función resize_and_rescale a los conjuntos de validación y prueba:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Estos conjuntos de datos ahora se pueden usar para entrenar un modelo como se mostró anteriormente.
Próximos pasos
Este tutorial demostró el aumento de datos utilizando capas de preprocesamiento de Keras y tf.image .
- Para aprender a incluir capas de preprocesamiento dentro de su modelo, consulte el tutorial de clasificación de imágenes .
- También puede estar interesado en aprender cómo las capas de preprocesamiento pueden ayudarlo a clasificar el texto, como se muestra en el tutorial de clasificación de texto básico .
- Puede obtener más información sobre
tf.dataen esta guía , y puede aprender cómo configurar sus canalizaciones de entrada para el rendimiento aquí .