
|
|
|
 Veja código fonte em GitHub Veja código fonte em GitHub
|
|
Este tutorial treina um modelo de rede neural para classificação de imagens de roupas, como tênis e camisetas. Tudo bem se você não entender todos os detalhes; este é um visão geral de um programa do TensorFlow com detalhes explicados enquanto progredimos.
O guia usa tf.keras, uma API alto-nível para construir e treinar modelos no TensorFlow.
# TensorFlow e tf.keras
import tensorflow as tf
from tensorflow import keras
# Bibliotecas Auxiliares
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.4.1
Importe a base de dados Fashion MNIST
Esse tutorial usa a base de dados Fashion MNIST que contém 70,000 imagens em tons de cinza em 10 categorias. As imagens mostram artigos individuais de roupas com baixa resolução (28 por 28 pixels), como vemos aqui:
|
|
|
Figure 1. Amostras de Fashion-MNIST (por Zalando, MIT License). |
Fashion MNIST tem como intenção substituir a clássica base de dados MNIST— frequentemente usada como "Hello, World" de programas de aprendizado de máquina (machine learning) para visão computacional. A base de dados MNIST contém imagens de dígitos escritos à mão (0, 1, 2, etc.) em um formato idêntico ao dos artigos de roupas que usaremos aqui.
Esse tutorial usa a Fashion MNIST para variar, e porque é um problema um pouco mais desafiador que o regular MNIST. Ambas bases são relativamente pequenas e são usadas para verificar se um algoritmo funciona como esperado. Elas são bons pontos de partida para testar e debugar código.
Usaremos 60,000 imagens para treinar nossa rede e 10,000 imagens para avaliar quão precisamente nossa rede aprendeu a classificar as imagens. Você pode acessar a Fashion MNIST diretamente do TensorFlow. Importe e carregue a base Fashion MNIST diretamente do TensorFlow:
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
Carregando a base de dados que retorna quatro NumPy arrays:
- Os arrays
train_imagesetrain_labelssão o conjunto de treinamento— os dados do modelo usados para aprender. - O modelo é testado com o conjunto de teste, os arrays
test_imagesetest_labels.
As imagens são arrays NumPy de 28x28, com os valores de pixels entre 0 to 255. As labels (alvo da classificação) são um array de inteiros, no intervalo de 0 a 9. Esse corresponde com a classe de roupa que cada imagem representa:
| Label | Classe |
|---|---|
| 0 | Camisetas/Top (T-shirt/top) |
| 1 | Calça (Trouser) |
| 2 | Suéter (Pullover) |
| 3 | Vestidos (Dress) |
| 4 | Casaco (Coat) |
| 5 | Sandálias (Sandal) |
| 6 | Camisas (Shirt) |
| 7 | Tênis (Sneaker) |
| 8 | Bolsa (Bag) |
| 9 | Botas (Ankle boot) |
Cada imagem é mapeada com um só label. Já que o nome das classes não são incluídas na base de dados, armazene os dados aqui para usá-los mais tarde quando plotarmos as imagens:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Explore os dados
Vamos explorar o formato da base de dados antes de treinar o modelo. O próximo comando mostra que existem 60000 imagens no conjunto de treinamento, e cada imagem é representada em 28 x 28 pixels:
train_images.shape
(60000, 28, 28)
Do mesmo modo, existem 60000 labels no conjunto de treinamento:
len(train_labels)
60000
Cada label é um inteiro entre 0 e 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
Existem 10000 imagens no conjunto de teste. Novamente, cada imagem é representada por 28 x 28 pixels:
test_images.shape
(10000, 28, 28)
E um conjunto de teste contendo 10000 labels das imagens :
len(test_labels)
10000
Pré-processe os dados
Os dados precisam ser pré-processados antes de treinar a rede. Se você inspecionar a primeira imagem do conjunto de treinamento, você verá que os valores dos pixels estão entre 0 e 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
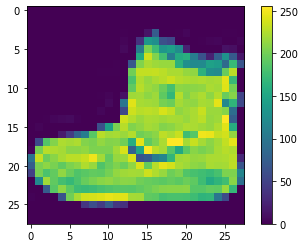
Escalaremos esses valores no intervalo de 0 e 1 antes de alimentar o modelo da rede neural. Para fazer isso, dividimos os valores por 255. É importante que o conjunto de treinamento e o conjunto de teste podem ser pré-processados do mesmo modo:
train_images = train_images / 255.0
test_images = test_images / 255.0
Para verificar que os dados estão no formato correto e que estamos prontos para construir e treinar a rede, vamos mostrar as primeiras 25 imagens do conjunto de treinamento e mostrar o nome das classes de cada imagem abaixo.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Construindo o modelo
Construir a rede neural requer configurar as camadas do modelo, e depois, compilar o modelo.
Montar as camadas
O principal bloco de construção da rede neural é a camada (layer). As camadas (layers) extraem representações dos dados inseridos na rede. Com sorte, essas representações são significativas para o problema à mão.
Muito do deep learning consiste em encadear simples camadas. Muitas camadas, como tf.keras.layers.Dense, tem parâmetros que são aprendidos durante o treinamento.
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
A primeira camada da rede, tf.keras.layers.Flatten, transforma o formato da imagem de um array de imagens de duas dimensões (of 28 by 28 pixels) para um array de uma dimensão (de 28 * 28 = 784 pixels). Pense nessa camada como camadas não empilhadas de pixels de uma imagem e os enfilere. Essa camada não tem parâmetros para aprender; ela só reformata os dados.
Depois dos pixels serem achatados, a rede consiste de uma sequência de duas camadas tf.keras.layers.Dense. Essas são camadas neurais densely connected, ou fully connected. A primeira camada Dense tem 128 nós (ou neurônios). A segunda (e última) camada é uma softmax de 10 nós que retorna um array de 10 probabilidades, cuja soma resulta em 1. Cada nó contém um valor que indica a probabilidade de que aquela imagem pertence a uma das 10 classes.
Compile o modelo
Antes do modelo estar pronto para o treinamento, é necessário algumas configurações a mais. Essas serão adicionadas no passo de compilação:
- Função Loss —Essa mede quão precisa o modelo é durante o treinamento. Queremos minimizar a função para guiar o modelo para a direção certa.
- Optimizer —Isso é como o modelo se atualiza com base no dado que ele vê e sua função loss.
- Métricas —usadas para monitorar os passos de treinamento e teste. O exemplo abaixo usa a acurácia, a fração das imagens que foram classificadas corretamente.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Treine o modelo
Treinar a rede neural requer os seguintes passos:
- Alimente com os dados de treinamento, o modelo. Neste exemplo, os dados de treinamento são os arrays
train_imagesetrain_labels. - O modelo aprende como associar as imagens as labels.
- Perguntamos ao modelo para fazer previsões sobre o conjunto de teste — nesse exemplo, o array
test_images. Verificamos se as previsões combinaram com as labels do arraytest_labels.
Para começar a treinar, chame o método model.fit— assim chamado, porque ele "encaixa" o modelo no conjunto de treinamento:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.6237 - accuracy: 0.7844 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3802 - accuracy: 0.8626 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3358 - accuracy: 0.8765 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3052 - accuracy: 0.8880 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2961 - accuracy: 0.8897 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2775 - accuracy: 0.8972 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2666 - accuracy: 0.9010 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2593 - accuracy: 0.9046 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2418 - accuracy: 0.9101 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2347 - accuracy: 0.9124 <tensorflow.python.keras.callbacks.History at 0x7ff238ad37b8>
À medida que o modelo treina, as métricas loss e acurácia são mostradas. O modelo atinge uma acurácia de 0.88 (ou 88%) com o conjunto de treinamento.
Avalie a acurácia
Depois, compare como o modelo performou com o conjunto de teste:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3342 - accuracy: 0.8823 Test accuracy: 0.8823000192642212
Acabou que o a acurácia com o conjunto de teste é um pouco menor do que a acurácia de treinamento. Essa diferença entre as duas acurácias representa um overfitting. Overfitting é modelo de aprendizado de máquina performou de maneira pior em um conjunto de entradas novas, e não usadas anteriormente, que usando o conjunto de treinamento.
Faça predições
Com o modelo treinado, o usaremos para predições de algumas imagens.
predictions = model.predict(test_images)
Aqui, o modelo previu que a label de cada imagem no conjunto de treinamento. Vamos olhar na primeira predição:
predictions[0]
array([3.2807145e-07, 1.0875438e-09, 4.7872772e-10, 1.3293636e-10,
4.8750839e-09, 6.3827081e-04, 1.3278054e-04, 2.0520254e-03,
3.5905177e-08, 9.9717653e-01], dtype=float32)
A predição é um array de 10 números. Eles representam um a confiança do modelo que a imagem corresponde a cada um dos diferentes artigos de roupa. Podemos ver cada label tem um maior valor de confiança:
np.argmax(predictions[0])
9
Então, o modelo é confiante de que esse imagem é uma bota (ankle boot) ou class_names[9]. Examinando a label do teste, vemos que essa classificação é correta:
test_labels[0]
9
Podemos mostrar graficamente como se parece em um conjunto total de previsão de 10 classes.
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Vamos olhar a previsão imagem na posição 0, do array de predição.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()

i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()

Vamos plotar algumas da previsão do modelo. Labels preditas corretamente são azuis e as predições erradas são vermelhas. O número dá a porcentagem (de 100) das labels preditas. Note que o modelo pode errar mesmo estando confiante.
# Plota o primeiro X test images, e as labels preditas, e as labels verdadeiras.
# Colore as predições corretas de azul e as incorretas de vermelho.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()

Finamente, use o modelo treinado para fazer a predição de uma única imagem.
# Grab an image from the test dataset.
img = test_images[0]
print(img.shape)
(28, 28)
Modelos tf.keras são otimizados para fazer predições em um batch, ou coleções, de exemplos de uma vez. De acordo, mesmo que usemos uma única imagem, precisamos adicionar em uma lista:
# Adiciona a imagem em um batch que possui um só membro.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Agora prediremos a label correta para essa imagem:
predictions_single = model.predict(img)
print(predictions_single)
[[3.2807174e-07 1.0875438e-09 4.7872772e-10 1.3293584e-10 4.8750932e-09 6.3827110e-04 1.3278067e-04 2.0520263e-03 3.5905177e-08 9.9717653e-01]]
plot_value_array(0, predictions_single, test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)

model.predict retorna a lista de listas — uma lista para cada imagem em um batch de dados. Pegue a predição de nossa (única) imagem no batch:
np.argmax(predictions_single[0])
9
E, como antes, o modelo previu a label como 9.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.