
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial demonstra como implementar o método Actor-Critic usando o TensorFlow para treinar um agente no ambiente Open AI Gym CartPole-V0. Presume-se que o leitor tenha alguma familiaridade com métodos de gradiente de política de aprendizado por reforço.
Métodos Ator-Crítico
Os métodos Actor-Critic são métodos de aprendizado de diferença temporal (TD) que representam a função de política independente da função de valor.
Uma função de política (ou política) retorna uma distribuição de probabilidade sobre as ações que o agente pode realizar com base no estado fornecido. Uma função de valor determina o retorno esperado para um agente começando em um determinado estado e agindo de acordo com uma política específica para sempre.
No método Ator-Crítico, a política é referida como o ator que propõe um conjunto de ações possíveis dado um estado, e a função de valor estimado é referida como crítica , que avalia as ações tomadas pelo ator com base na política dada. .
Neste tutorial, tanto o Ator quanto o Crítico serão representados usando uma rede neural com duas saídas.
CartPole-v0
No ambiente CartPole-v0 , um poste é preso a um carrinho que se move ao longo de um trilho sem atrito. O poste começa na vertical e o objetivo do agente é evitar que ele caia aplicando uma força de -1 ou +1 no carrinho. Uma recompensa de +1 é dada para cada passo de tempo em que o poste permanece na posição vertical. Um episódio termina quando (1) o poste está a mais de 15 graus da vertical ou (2) o carrinho se move mais de 2,4 unidades do centro.
O problema é considerado "resolvido" quando a recompensa total média do episódio atinge 195 em 100 tentativas consecutivas.
Configurar
Importe os pacotes necessários e defina as configurações globais.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
Modelo
O Ator e o Crítico serão modelados usando uma rede neural que gera as probabilidades de ação e o valor crítico respectivamente. Este tutorial usa subclasses de modelo para definir o modelo.
Durante a passagem para frente, o modelo receberá o estado como entrada e produzirá as probabilidades de ação e o valor crítico \(V\), que modela a função de valor dependente do estado . O objetivo é treinar um modelo que escolha ações com base em uma política \(\pi\) que maximize o retorno esperado .
Para Cartpole-v0, existem quatro valores que representam o estado: posição do carrinho, velocidade do carrinho, ângulo do pólo e velocidade do pólo, respectivamente. O agente pode realizar duas ações para empurrar o carrinho para a esquerda (0) e para a direita (1), respectivamente.
Consulte a página wiki CartPole-v0 do OpenAI Gym para obter mais informações.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
Treinamento
Para treinar o agente, você seguirá estas etapas:
- Execute o agente no ambiente para coletar dados de treinamento por episódio.
- Calcule o retorno esperado em cada passo de tempo.
- Calcule a perda para o modelo combinado ator-crítico.
- Calcule gradientes e atualize os parâmetros de rede.
- Repita 1-4 até que o critério de sucesso ou o máximo de episódios tenham sido alcançados.
1. Coletando dados de treinamento
Assim como no aprendizado supervisionado, para treinar o modelo ator-crítico, você precisa ter dados de treinamento. No entanto, para coletar esses dados, o modelo precisaria ser "executado" no ambiente.
Os dados de treinamento são coletados para cada episódio. Então, a cada passo de tempo, o forward pass do modelo será executado no estado do ambiente para gerar probabilidades de ação e o valor crítico com base na política atual parametrizada pelos pesos do modelo.
A próxima ação será amostrada a partir das probabilidades de ação geradas pelo modelo, que então seriam aplicadas ao ambiente, fazendo com que o próximo estado e recompensa fossem gerados.
Esse processo é implementado na função run_episode , que usa operações do TensorFlow para que possa ser compilado posteriormente em um gráfico do TensorFlow para um treinamento mais rápido. Observe que tf.TensorArray s foram usados para dar suporte à iteração do Tensor em matrizes de comprimento variável.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. Calculando os retornos esperados
A sequência de recompensas para cada timestep \(t\), \(\{r_{t}\}^{T}_{t=1}\) coletada durante um episódio é convertida em uma sequência de retornos esperados \(\{G_{t}\}^{T}_{t=1}\) na qual a soma das recompensas é tirada do timestep atual \(t\) para \(T\) e cada a recompensa é multiplicada por um fator de desconto exponencialmente decrescente \(\gamma\):
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
Desde \(\gamma\in(0,1)\), as recompensas mais distantes do passo de tempo atual recebem menos peso.
Intuitivamente, o retorno esperado simplesmente implica que as recompensas agora são melhores do que as recompensas posteriores. Em um sentido matemático, é garantir que a soma das recompensas converge.
Para estabilizar o treinamento, a sequência de retornos resultante também é padronizada (ou seja, ter média zero e desvio padrão unitário).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. A perda do ator-crítico
Como é utilizado um modelo híbrido ator-crítico, a função de perda escolhida é uma combinação de perdas de ator e crítica para treinamento, conforme mostrado abaixo:
\[L = L_{actor} + L_{critic}\]
Perda do ator
A perda do ator é baseada em gradientes de política com o crítico como uma linha de base dependente do estado e calculada com estimativas de amostra única (por episódio).
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
Onde:
- \(T\): o número de timesteps por episódio, que pode variar por episódio
- \(s_{t}\): o estado no \(t\)
- \(a_{t}\): ação escolhida no \(t\) dado o estado \(s\)
- \(\pi_{\theta}\): é a política (ator) parametrizada por \(\theta\)
- \(V^{\pi}_{\theta}\): é a função valor (crítica) também parametrizada por \(\theta\)
- \(G = G_{t}\): o retorno esperado para um determinado estado, par de ações no timestep \(t\)
Um termo negativo é adicionado à soma, uma vez que a ideia é maximizar as probabilidades das ações renderem maiores recompensas, minimizando a perda combinada.
Vantagem
O termo \(G - V\) em nossa formulação \(L_{actor}\) é chamado de vantagem , que indica o quanto melhor uma ação recebe um determinado estado em relação a uma ação aleatória selecionada de acordo com a política \(\pi\) para esse estado.
Embora seja possível excluir uma linha de base, isso pode resultar em alta variação durante o treinamento. E o bom de escolher o crítico \(V\) como linha de base é que ele foi treinado para estar o mais próximo possível de \(G\), levando a uma variância menor.
Além disso, sem o crítico, o algoritmo tentaria aumentar as probabilidades de ações realizadas em um determinado estado com base no retorno esperado, o que pode não fazer muita diferença se as probabilidades relativas entre as ações permanecerem as mesmas.
Por exemplo, suponha que duas ações para um determinado estado produziriam o mesmo retorno esperado. Sem a crítica, o algoritmo tentaria aumentar a probabilidade dessas ações com base no objetivo \(J\). Com a crítica, pode acontecer que não haja vantagem (\(G - V = 0\)) e, portanto, nenhum benefício ganho em aumentar as probabilidades das ações e o algoritmo definiria os gradientes para zero.
Perda crítica
Treinar \(V\) para ficar o mais próximo possível de \(G\) pode ser configurado como um problema de regressão com a seguinte função de perda:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
onde \(L_{\delta}\) é a perda de Huber , que é menos sensível a valores discrepantes nos dados do que a perda de erro quadrado.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. Definindo a etapa de treinamento para atualizar os parâmetros
Todas as etapas acima são combinadas em uma etapa de treinamento que é executada a cada episódio. Todas as etapas que levam à função de perda são executadas com o contexto tf.GradientTape para habilitar a diferenciação automática.
Este tutorial usa o otimizador Adam para aplicar os gradientes aos parâmetros do modelo.
A soma das recompensas não descontadas, episode_reward , também é calculada nesta etapa. Esse valor será usado posteriormente para avaliar se o critério de sucesso foi atendido.
O contexto tf.function é aplicado à função train_step para que possa ser compilado em um gráfico TensorFlow que pode ser chamado, o que pode levar a uma aceleração de 10 vezes no treinamento.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. Execute o loop de treinamento
O treinamento é executado executando a etapa de treinamento até que o critério de sucesso ou o número máximo de episódios seja atingido.
Um registro contínuo de recompensas de episódios é mantido em uma fila. Uma vez que 100 tentativas são alcançadas, a recompensa mais antiga é removida na extremidade esquerda (cauda) da fila e a mais nova é adicionada na frente (direita). Uma soma corrente das recompensas também é mantida para eficiência computacional.
Dependendo do seu tempo de execução, o treinamento pode terminar em menos de um minuto.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
Visualização
Após o treinamento, seria bom visualizar como o modelo se comporta no ambiente. Você pode executar as células abaixo para gerar uma animação GIF de um episódio executado do modelo. Observe que pacotes adicionais precisam ser instalados para que o OpenAI Gym renderize as imagens do ambiente corretamente no Colab.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
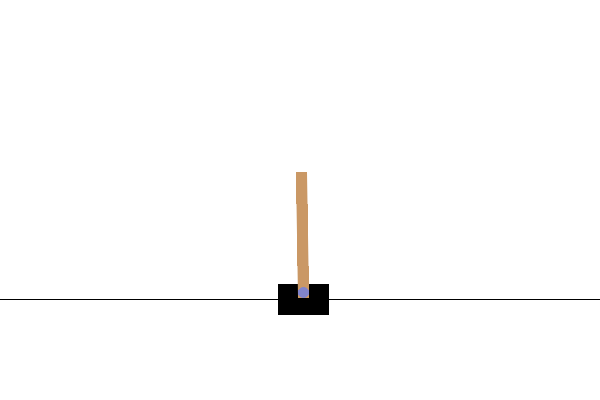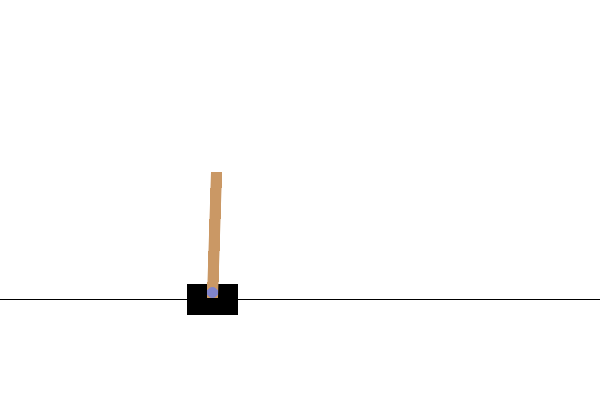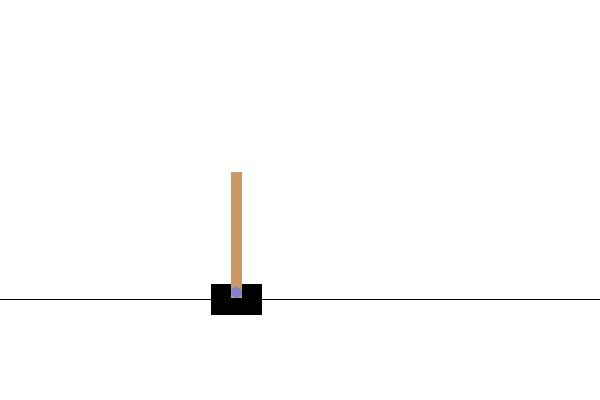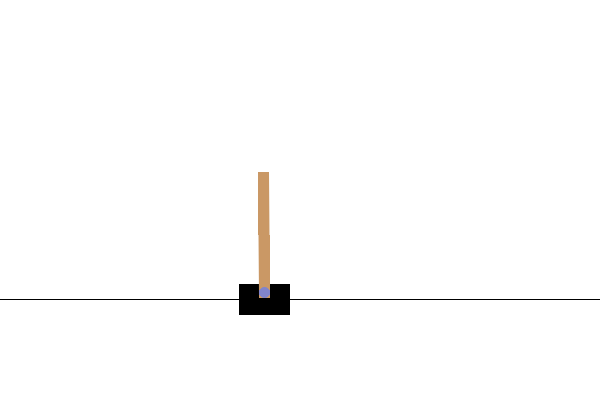
Próximos passos
Este tutorial demonstrou como implementar o método ator-crítico usando o Tensorflow.
Como próximo passo, você pode tentar treinar um modelo em um ambiente diferente no OpenAI Gym.
Para obter informações adicionais sobre métodos críticos de atores e o problema Cartpole-v0, você pode consultar os seguintes recursos:
- Método Ator Crítico
- Palestra Ator Crítico (CAL)
- Problema de controle de aprendizagem cartpole [Barto, et al. 1983]
Para obter mais exemplos de aprendizado por reforço no TensorFlow, você pode verificar os seguintes recursos: