
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel montre comment classer des données structurées, telles que des données tabulaires, à l'aide d'une version simplifiée de l' ensemble de données PetFinder d'un concours Kaggle stocké dans un fichier CSV.
Vous utiliserez Keras pour définir le modèle et les couches de prétraitement Keras comme pont pour mapper les colonnes d'un fichier CSV aux fonctionnalités utilisées pour former le modèle. Le but est de prédire si un animal de compagnie sera adopté.
Ce tutoriel contient le code complet pour :
- Chargement d'un fichier CSV dans un DataFrame à l'aide de pandas .
- Construire un pipeline d'entrée pour regrouper et mélanger les lignes à l'aide
tf.data. (Consultez tf.data : Build TensorFlow input pipelines pour plus de détails.) - Mappage des colonnes du fichier CSV aux fonctionnalités utilisées pour entraîner le modèle avec les couches de prétraitement Keras.
- Construire, entraîner et évaluer un modèle à l'aide des méthodes intégrées de Keras.
Le mini jeu de données PetFinder.my
Il y a plusieurs milliers de lignes dans le fichier CSV de PetFinder.my mini, où chaque ligne décrit un animal de compagnie (un chien ou un chat) et chaque colonne décrit un attribut, tel que l'âge, la race, la couleur, etc.
Dans le résumé de l'ensemble de données ci-dessous, notez qu'il y a principalement des colonnes numériques et catégorielles. Dans ce didacticiel, vous ne traiterez que de ces deux types de fonctionnalités, en supprimant Description (une fonctionnalité de texte libre) et AdoptionSpeed (une fonctionnalité de classification) lors du prétraitement des données.
| Colonne | Description de l'animal | Type de fonctionnalité | Type de données |
|---|---|---|---|
Type | Type d'animal ( Dog , Cat ) | Catégorique | Chaîne de caractères |
Age | Âge | Numérique | Entier |
Breed1 | Race primaire | Catégorique | Chaîne de caractères |
Color1 | Couleur 1 | Catégorique | Chaîne de caractères |
Color2 | Couleur 2 | Catégorique | Chaîne de caractères |
MaturitySize | Taille à maturité | Catégorique | Chaîne de caractères |
FurLength | Longueur de la fourrure | Catégorique | Chaîne de caractères |
Vaccinated | L'animal a été vacciné | Catégorique | Chaîne de caractères |
Sterilized | L'animal a été stérilisé | Catégorique | Chaîne de caractères |
Health | État de santé | Catégorique | Chaîne de caractères |
Fee | Frais d'adoption | Numérique | Entier |
Description | Rédaction de profil | Texte | Chaîne de caractères |
PhotoAmt | Total de photos téléchargées | Numérique | Entier |
AdoptionSpeed | Rapidité d'adoption catégorielle | Classification | Entier |
Importer TensorFlow et d'autres bibliothèques
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__
'2.8.0-rc1'
Chargez le jeu de données et lisez-le dans un pandas DataFrame
pandas est une bibliothèque Python avec de nombreux utilitaires utiles pour charger et travailler avec des données structurées. Utilisez tf.keras.utils.get_file pour télécharger et extraire le fichier CSV avec le mini jeu de données PetFinder.my, et chargez-le dans un DataFrame avec pandas.read_csv :
dataset_url = 'http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip'
csv_file = 'datasets/petfinder-mini/petfinder-mini.csv'
tf.keras.utils.get_file('petfinder_mini.zip', dataset_url,
extract=True, cache_dir='.')
dataframe = pd.read_csv(csv_file)
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip 1671168/1668792 [==============================] - 0s 0us/step 1679360/1668792 [==============================] - 0s 0us/step
Inspectez l'ensemble de données en vérifiant les cinq premières lignes du DataFrame :
dataframe.head()
Créer une variable cible
La tâche initiale du concours PetFinder.my Adoption Prediction de Kaggle était de prédire la vitesse à laquelle un animal sera adopté (par exemple, la première semaine, le premier mois, les trois premiers mois, etc.).
Dans ce tutoriel, vous simplifierez la tâche en la transformant en un problème de classification binaire, où vous n'aurez qu'à prédire si un animal a été adopté ou non.
Après avoir modifié la colonne AdoptionSpeed , 0 indiquera que l'animal n'a pas été adopté et 1 indiquera qu'il l'a été.
# In the original dataset, `'AdoptionSpeed'` of `4` indicates
# a pet was not adopted.
dataframe['target'] = np.where(dataframe['AdoptionSpeed']==4, 0, 1)
# Drop unused features.
dataframe = dataframe.drop(columns=['AdoptionSpeed', 'Description'])
Diviser le DataFrame en ensembles d'entraînement, de validation et de test
L'ensemble de données se trouve dans un seul pandas DataFrame. Divisez-le en ensembles d'entraînement, de validation et de test en utilisant, par exemple, un rapport de 80:10:10, respectivement :
train, val, test = np.split(dataframe.sample(frac=1), [int(0.8*len(dataframe)), int(0.9*len(dataframe))])
print(len(train), 'training examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
9229 training examples 1154 validation examples 1154 test examples
Créer un pipeline d'entrée à l'aide de tf.data
Ensuite, créez une fonction utilitaire qui convertit chaque DataFrame d'entraînement, de validation et de test en un tf.data.Dataset , puis mélange et regroupe les données.
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop('target')
df = {key: value[:,tf.newaxis] for key, value in dataframe.items()}
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
Maintenant, utilisez la fonction nouvellement créée ( df_to_dataset ) pour vérifier le format des données renvoyées par la fonction d'assistance du pipeline d'entrée en l'appelant sur les données d'apprentissage, et utilisez une petite taille de lot pour que la sortie reste lisible :
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
[(train_features, label_batch)] = train_ds.take(1)
print('Every feature:', list(train_features.keys()))
print('A batch of ages:', train_features['Age'])
print('A batch of targets:', label_batch )
Every feature: ['Type', 'Age', 'Breed1', 'Gender', 'Color1', 'Color2', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Fee', 'PhotoAmt', 'target'] A batch of ages: tf.Tensor( [[84] [ 1] [ 5] [ 1] [12]], shape=(5, 1), dtype=int64) A batch of targets: tf.Tensor([1 1 0 1 0], shape=(5,), dtype=int64)
Comme le montre la sortie, l'ensemble d'apprentissage renvoie un dictionnaire de noms de colonnes (du DataFrame) qui correspondent aux valeurs de colonne des lignes.
Appliquer les couches de prétraitement Keras
Les couches de prétraitement Keras vous permettent de créer des pipelines de traitement d'entrée natifs Keras, qui peuvent être utilisés comme code de prétraitement indépendant dans des flux de travail non-Keras, combinés directement avec des modèles Keras et exportés dans le cadre d'un Keras SavedModel.
Dans ce didacticiel, vous utiliserez les quatre couches de prétraitement suivantes pour montrer comment effectuer le prétraitement, l'encodage des données structurées et l'ingénierie des fonctionnalités :
-
tf.keras.layers.Normalization: Effectue une normalisation par fonctionnalité des fonctionnalités d'entrée. -
tf.keras.layers.CategoryEncoding: transforme les caractéristiques catégorielles entières en représentations denses one-hot, multi-hot ou tf-idf . -
tf.keras.layers.StringLookup: transforme les valeurs catégorielles de chaîne en indices entiers. -
tf.keras.layers.IntegerLookup: transforme les valeurs catégorielles entières en indices entiers.
Vous pouvez en savoir plus sur les couches disponibles dans le guide Utilisation des couches de prétraitement .
- Pour les caractéristiques numériques du mini jeu de données PetFinder.my, vous utiliserez une couche
tf.keras.layers.Normalizationpour standardiser la distribution des données. - Pour les caractéristiques catégorielles , telles que les
Typed'animaux (chaînesDogetCat), vous les transformerez en tenseurs codés multi-chauds avectf.keras.layers.CategoryEncoding.
Colonnes numériques
Pour chaque entité numérique du mini-ensemble de données PetFinder.my, vous utiliserez une couche tf.keras.layers.Normalization pour normaliser la distribution des données.
Définissez une nouvelle fonction utilitaire qui renvoie une couche qui applique la normalisation par fonctionnalité aux entités numériques à l'aide de cette couche de prétraitement Keras :
def get_normalization_layer(name, dataset):
# Create a Normalization layer for the feature.
normalizer = layers.Normalization(axis=None)
# Prepare a Dataset that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
Ensuite, testez la nouvelle fonction en l'appelant sur le nombre total de fonctionnalités de photos d'animaux téléchargées pour normaliser 'PhotoAmt' :
photo_count_col = train_features['PhotoAmt']
layer = get_normalization_layer('PhotoAmt', train_ds)
layer(photo_count_col)
<tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[-0.8272058 ],
[-0.19125296],
[ 1.3986291 ],
[-0.19125296],
[-0.50922936]], dtype=float32)>
Colonnes catégorielles
Type d'animaux de compagnie dans l'ensemble de données sont représentés sous forme de chaînes ( Dog et Cat ) qui doivent être encodées à chaud avant d'être introduites dans le modèle. La fonction Age
Définissez une autre nouvelle fonction utilitaire qui renvoie une couche qui mappe les valeurs d'un vocabulaire à des indices entiers et encode à chaud les fonctionnalités à l'aide du tf.keras.layers.StringLookup , tf.keras.layers.IntegerLookup et tf.keras.CategoryEncoding couches:
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))
Testez la fonction get_category_encoding_layer en l'appelant sur les fonctionnalités 'Type' d'animal familier pour les transformer en tenseurs codés multi-hot :
test_type_col = train_features['Type']
test_type_layer = get_category_encoding_layer(name='Type',
dataset=train_ds,
dtype='string')
test_type_layer(test_type_col)
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=float32)>
Répétez le processus sur les fonctionnalités 'Age' de l'animal :
test_age_col = train_features['Age']
test_age_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
test_age_layer(test_age_col)
<tf.Tensor: shape=(5, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.]], dtype=float32)>
Prétraiter les fonctionnalités sélectionnées pour former le modèle sur
Vous avez appris à utiliser plusieurs types de couches de prétraitement Keras. Ensuite, vous allez :
- Appliquez les fonctions utilitaires de prétraitement définies précédemment sur 13 caractéristiques numériques et catégorielles du mini jeu de données PetFinder.my.
- Ajoutez toutes les entrées de fonctionnalité à une liste.
Comme mentionné au début, pour former le modèle, vous utiliserez le mini jeu de données PetFinder.my numérique ( 'PhotoAmt' , 'Fee' ) et catégorique ( 'Age' , 'Type' , 'Color1' , 'Color2' , 'Gender' , 'MaturitySize' , 'FurLength' , 'Vaccinated' , 'Sterilized' , 'Health' , 'Breed1' ).
Précédemment, vous avez utilisé une petite taille de lot pour illustrer le pipeline d'entrée. Créons maintenant un nouveau pipeline d'entrée avec une taille de lot plus grande de 256 :
batch_size = 256
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
Normalisez les caractéristiques numériques (le nombre de photos d'animaux et les frais d'adoption) et ajoutez-les à une liste d'entrées appelée encoded_features :
all_inputs = []
encoded_features = []
# Numerical features.
for header in ['PhotoAmt', 'Fee']:
numeric_col = tf.keras.Input(shape=(1,), name=header)
normalization_layer = get_normalization_layer(header, train_ds)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
Transformez les valeurs catégorielles entières du jeu de données (l'âge de l'animal) en indices entiers, effectuez un encodage multi-chaud et ajoutez les entrées d'entités résultantes à encoded_features :
age_col = tf.keras.Input(shape=(1,), name='Age', dtype='int64')
encoding_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
encoded_age_col = encoding_layer(age_col)
all_inputs.append(age_col)
encoded_features.append(encoded_age_col)
Répétez la même étape pour les valeurs catégorielles de chaîne :
categorical_cols = ['Type', 'Color1', 'Color2', 'Gender', 'MaturitySize',
'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1']
for header in categorical_cols:
categorical_col = tf.keras.Input(shape=(1,), name=header, dtype='string')
encoding_layer = get_category_encoding_layer(name=header,
dataset=train_ds,
dtype='string',
max_tokens=5)
encoded_categorical_col = encoding_layer(categorical_col)
all_inputs.append(categorical_col)
encoded_features.append(encoded_categorical_col)
Créer, compiler et entraîner le modèle
L'étape suivante consiste à créer un modèle à l'aide de l' API fonctionnelle Keras . Pour la première couche de votre modèle, fusionnez la liste des entrées d'entités encoded_features ) en un seul vecteur via la concaténation avec tf.keras.layers.concatenate .
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(32, activation="relu")(all_features)
x = tf.keras.layers.Dropout(0.5)(x)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
Configurez le modèle avec Keras Model.compile :
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"])
Visualisons le graphe de connectivité :
# Use `rankdir='LR'` to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")
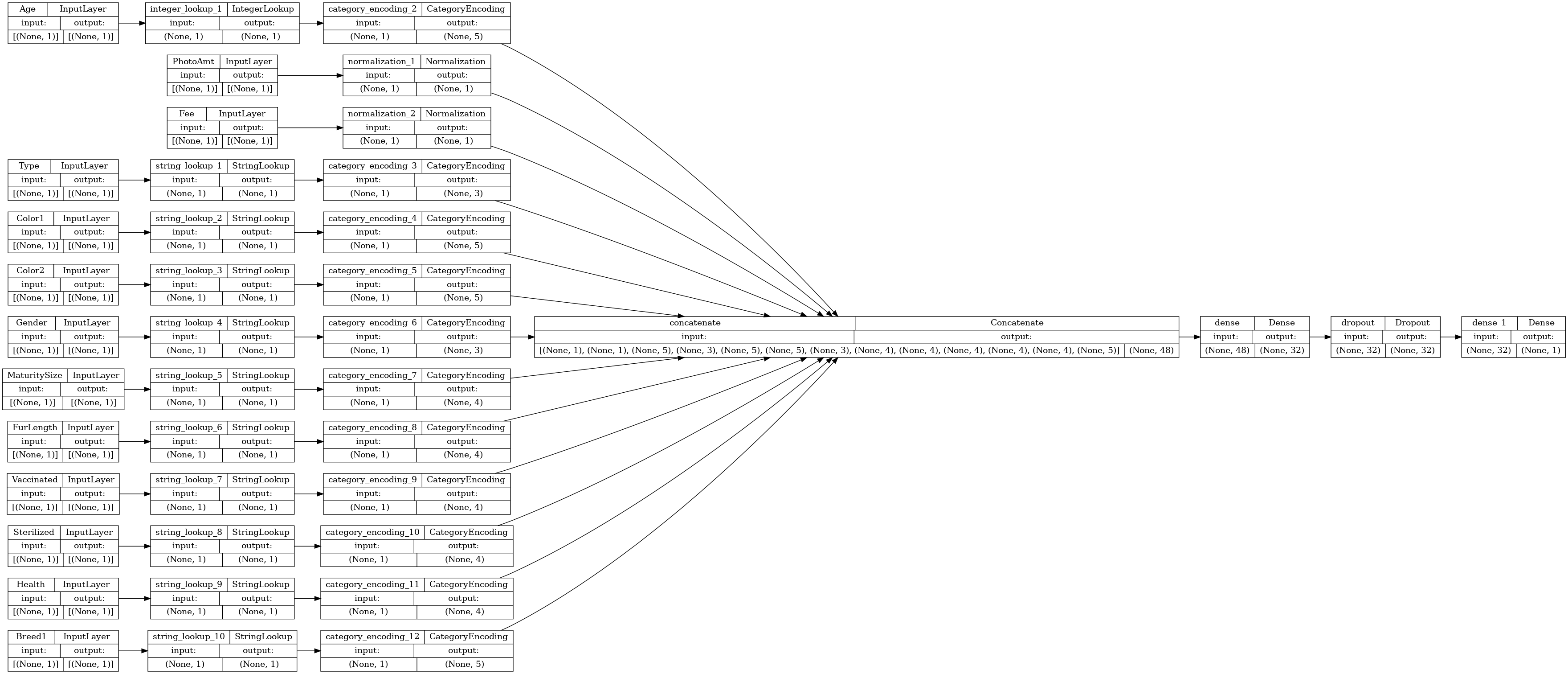
Ensuite, entraînez et testez le modèle :
model.fit(train_ds, epochs=10, validation_data=val_ds)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['target'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 37/37 [==============================] - 2s 19ms/step - loss: 0.6524 - accuracy: 0.5034 - val_loss: 0.5887 - val_accuracy: 0.6941 Epoch 2/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5906 - accuracy: 0.6648 - val_loss: 0.5627 - val_accuracy: 0.7218 Epoch 3/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5697 - accuracy: 0.6924 - val_loss: 0.5463 - val_accuracy: 0.7504 Epoch 4/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5558 - accuracy: 0.6978 - val_loss: 0.5346 - val_accuracy: 0.7504 Epoch 5/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5502 - accuracy: 0.7105 - val_loss: 0.5272 - val_accuracy: 0.7487 Epoch 6/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5415 - accuracy: 0.7123 - val_loss: 0.5210 - val_accuracy: 0.7608 Epoch 7/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5354 - accuracy: 0.7171 - val_loss: 0.5152 - val_accuracy: 0.7435 Epoch 8/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5301 - accuracy: 0.7214 - val_loss: 0.5113 - val_accuracy: 0.7513 Epoch 9/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5286 - accuracy: 0.7189 - val_loss: 0.5087 - val_accuracy: 0.7574 Epoch 10/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5252 - accuracy: 0.7260 - val_loss: 0.5058 - val_accuracy: 0.7539 <keras.callbacks.History at 0x7f5f9fa91c50>
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
5/5 [==============================] - 0s 6ms/step - loss: 0.5012 - accuracy: 0.7626 Accuracy 0.762565016746521
Effectuer une inférence
Le modèle que vous avez développé peut désormais classer une ligne à partir d'un fichier CSV directement après avoir inclus les couches de prétraitement dans le modèle lui-même.
Vous pouvez désormais enregistrer et recharger le modèle Keras avec Model.save et Model.load_model avant d'effectuer l'inférence sur de nouvelles données :
model.save('my_pet_classifier')
reloaded_model = tf.keras.models.load_model('my_pet_classifier')
2022-01-26 06:20:08.013613: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Function `_wrapped_model` contains input name(s) PhotoAmt, Fee, Age, Type, Color1, Color2, Gender, MaturitySize, FurLength, Vaccinated, Sterilized, Health, Breed1 with unsupported characters which will be renamed to photoamt, fee, age, type, color1, color2, gender, maturitysize, furlength, vaccinated, sterilized, health, breed1 in the SavedModel. INFO:tensorflow:Assets written to: my_pet_classifier/assets INFO:tensorflow:Assets written to: my_pet_classifier/assets
Pour obtenir une prédiction pour un nouvel échantillon, vous pouvez simplement appeler la méthode Keras Model.predict . Il n'y a que deux choses que vous devez faire :
- Enveloppez les scalaires dans une liste afin d'avoir une dimension de lot (les
Modelne traitent que des lots de données, pas des échantillons uniques). - Appelez
tf.convert_to_tensorsur chaque fonctionnalité.
sample = {
'Type': 'Cat',
'Age': 3,
'Breed1': 'Tabby',
'Gender': 'Male',
'Color1': 'Black',
'Color2': 'White',
'MaturitySize': 'Small',
'FurLength': 'Short',
'Vaccinated': 'No',
'Sterilized': 'No',
'Health': 'Healthy',
'Fee': 100,
'PhotoAmt': 2,
}
input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}
predictions = reloaded_model.predict(input_dict)
prob = tf.nn.sigmoid(predictions[0])
print(
"This particular pet had a %.1f percent probability "
"of getting adopted." % (100 * prob)
)
This particular pet had a 77.7 percent probability of getting adopted.
Prochaines étapes
Pour en savoir plus sur la classification des données structurées, essayez de travailler avec d'autres ensembles de données. Pour améliorer la précision lors de la formation et du test de vos modèles, réfléchissez bien aux fonctionnalités à inclure dans votre modèle et à la manière dont elles doivent être représentées.
Voici quelques suggestions d'ensembles de données :
- Ensembles de données TensorFlow : MovieLens : un ensemble de classements de films provenant d'un service de recommandation de films.
- Ensembles de données TensorFlow : Qualité du vin : deux ensembles de données liés aux variantes rouges et blanches du vin portugais "Vinho Verde". Vous pouvez également trouver l'ensemble de données sur la qualité du vin rouge sur Kaggle .
- Kaggle : arXiv Dataset : un corpus de 1,7 million d'articles scientifiques d'arXiv, couvrant la physique, l'informatique, les mathématiques, les statistiques, l'ingénierie électrique, la biologie quantitative et l'économie.