
| | |  Ver en GitHub Ver en GitHub | |
En aplicaciones de IA que son críticas para la seguridad (p. ej., toma de decisiones médicas y conducción autónoma) o donde los datos son inherentemente ruidosos (p. ej., comprensión del lenguaje natural), es importante que un clasificador profundo cuantifique de manera confiable su incertidumbre. El clasificador profundo debe ser capaz de ser consciente de sus propias limitaciones y cuándo debe ceder el control a los expertos humanos. Este tutorial muestra cómo mejorar la capacidad de un clasificador profundo para cuantificar la incertidumbre utilizando una técnica llamada Proceso gaussiano neuronal normalizado espectral ( SNGP ) .
La idea central de SNGP es mejorar el conocimiento de la distancia de un clasificador profundo mediante la aplicación de modificaciones simples a la red. La conciencia de distancia de un modelo es una medida de cómo su probabilidad predictiva refleja la distancia entre el ejemplo de prueba y los datos de entrenamiento. Esta es una propiedad deseable que es común para los modelos probabilísticos estándar de oro (por ejemplo, el proceso gaussiano con núcleos RBF) pero que falta en los modelos con redes neuronales profundas. SNGP proporciona una forma sencilla de inyectar este comportamiento de proceso gaussiano en un clasificador profundo mientras mantiene su precisión predictiva.
Este tutorial implementa un modelo SNGP basado en una red residual profunda (ResNet) en el conjunto de datos de dos lunas y compara su superficie de incertidumbre con la de otros dos enfoques de incertidumbre populares: la deserción de Monte Carlo y el conjunto profundo ).
Este tutorial ilustra el modelo SNGP en un conjunto de datos 2D de juguete. Para ver un ejemplo de la aplicación de SNGP a una tarea de comprensión del lenguaje natural del mundo real utilizando la base BERT, consulte el tutorial de SNGP-BERT . Para implementaciones de alta calidad del modelo SNGP (y muchos otros métodos de incertidumbre) en una amplia variedad de conjuntos de datos de referencia (p. ej., CIFAR-100 , ImageNet , detección de toxicidad de Jigsaw , etc.), consulte la referencia de referencia de incertidumbre .
Acerca de SNGP
El proceso gaussiano neuronal normalizado espectralmente (SNGP) es un enfoque simple para mejorar la calidad de incertidumbre de un clasificador profundo mientras se mantiene un nivel similar de precisión y latencia. Dada una red residual profunda, SNGP realiza dos cambios simples en el modelo:
- Aplica normalización espectral a las capas residuales ocultas.
- Reemplaza la capa de salida densa con una capa de proceso gaussiana.
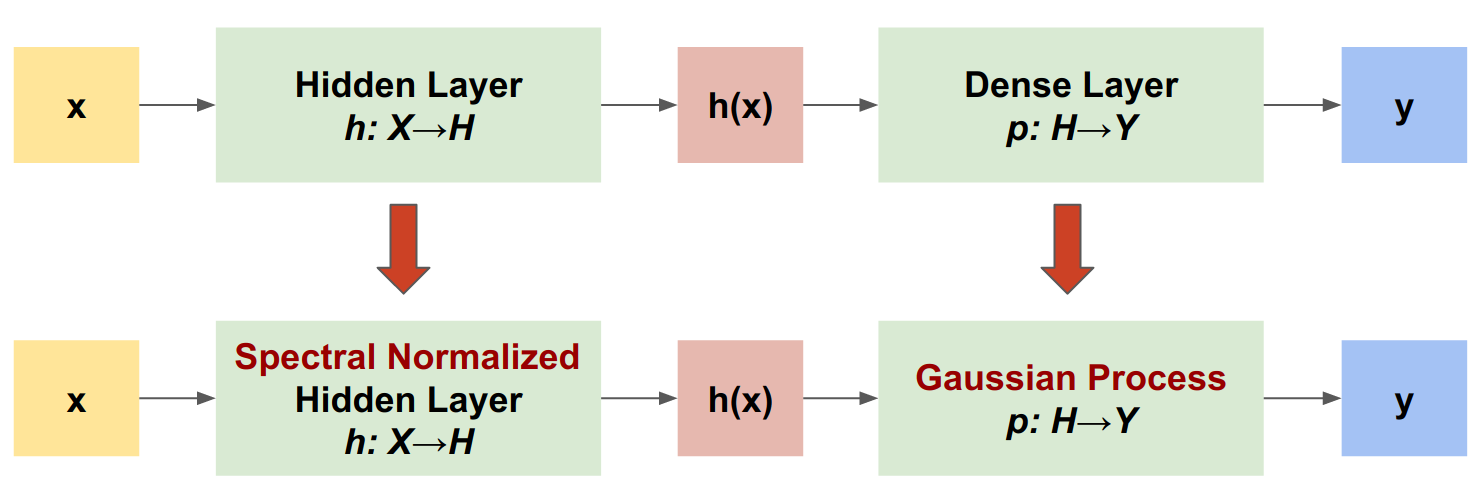
En comparación con otros enfoques de incertidumbre (por ejemplo, abandono de Monte Carlo o conjunto profundo), SNGP tiene varias ventajas:
- Funciona para una amplia gama de arquitecturas basadas en residuos de última generación (p. ej., (Wide) ResNet, DenseNet, BERT, etc.).
- Es un método de modelo único (es decir, no se basa en el promedio de conjunto). Por lo tanto, SNGP tiene un nivel de latencia similar al de una única red determinista y se puede escalar fácilmente a grandes conjuntos de datos como ImageNet y la clasificación de comentarios tóxicos de Jigsaw .
- Tiene un fuerte rendimiento de detección fuera de dominio debido a la propiedad de reconocimiento de distancia .
Las desventajas de este método son:
La incertidumbre predictiva de un SNGP se calcula utilizando la aproximación de Laplace . Por lo tanto, teóricamente, la incertidumbre posterior de SNGP es diferente de la de un proceso gaussiano exacto.
El entrenamiento de SNGP necesita un paso de reinicio de covarianza al comienzo de una nueva época. Esto puede agregar una pequeña cantidad de complejidad adicional a una canalización de capacitación. Este tutorial muestra una forma sencilla de implementar esto mediante las devoluciones de llamada de Keras.
Configuración
pip install --use-deprecated=legacy-resolver tf-models-official
# refresh pkg_resources so it takes the changes into account.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
import matplotlib.pyplot as plt
import matplotlib.colors as colors
import sklearn.datasets
import numpy as np
import tensorflow as tf
import official.nlp.modeling.layers as nlp_layers
Definir macros de visualización
plt.rcParams['figure.dpi'] = 140
DEFAULT_X_RANGE = (-3.5, 3.5)
DEFAULT_Y_RANGE = (-2.5, 2.5)
DEFAULT_CMAP = colors.ListedColormap(["#377eb8", "#ff7f00"])
DEFAULT_NORM = colors.Normalize(vmin=0, vmax=1,)
DEFAULT_N_GRID = 100
El conjunto de datos de dos lunas
Cree los conjuntos de datos de capacitación y evaluación a partir del conjunto de datos de dos lunas .
def make_training_data(sample_size=500):
"""Create two moon training dataset."""
train_examples, train_labels = sklearn.datasets.make_moons(
n_samples=2 * sample_size, noise=0.1)
# Adjust data position slightly.
train_examples[train_labels == 0] += [-0.1, 0.2]
train_examples[train_labels == 1] += [0.1, -0.2]
return train_examples, train_labels
Evalúe el comportamiento predictivo del modelo en todo el espacio de entrada 2D.
def make_testing_data(x_range=DEFAULT_X_RANGE, y_range=DEFAULT_Y_RANGE, n_grid=DEFAULT_N_GRID):
"""Create a mesh grid in 2D space."""
# testing data (mesh grid over data space)
x = np.linspace(x_range[0], x_range[1], n_grid)
y = np.linspace(y_range[0], y_range[1], n_grid)
xv, yv = np.meshgrid(x, y)
return np.stack([xv.flatten(), yv.flatten()], axis=-1)
Para evaluar la incertidumbre del modelo, agregue un conjunto de datos fuera del dominio (OOD) que pertenezca a una tercera clase. El modelo nunca ve estos ejemplos OOD durante el entrenamiento.
def make_ood_data(sample_size=500, means=(2.5, -1.75), vars=(0.01, 0.01)):
return np.random.multivariate_normal(
means, cov=np.diag(vars), size=sample_size)
# Load the train, test and OOD datasets.
train_examples, train_labels = make_training_data(
sample_size=500)
test_examples = make_testing_data()
ood_examples = make_ood_data(sample_size=500)
# Visualize
pos_examples = train_examples[train_labels == 0]
neg_examples = train_examples[train_labels == 1]
plt.figure(figsize=(7, 5.5))
plt.scatter(pos_examples[:, 0], pos_examples[:, 1], c="#377eb8", alpha=0.5)
plt.scatter(neg_examples[:, 0], neg_examples[:, 1], c="#ff7f00", alpha=0.5)
plt.scatter(ood_examples[:, 0], ood_examples[:, 1], c="red", alpha=0.1)
plt.legend(["Postive", "Negative", "Out-of-Domain"])
plt.ylim(DEFAULT_Y_RANGE)
plt.xlim(DEFAULT_X_RANGE)
plt.show()

Aquí, el azul y el naranja representan las clases positivas y negativas, y el rojo representa los datos OOD. Se espera que un modelo que cuantifique bien la incertidumbre sea seguro cuando esté cerca de los datos de entrenamiento (es decir, \(p(x_{test})\) cerca de 0 o 1), y que sea incierto cuando esté lejos de las regiones de datos de entrenamiento (es decir, \(p(x_{test})\) cerca de 0,5 ).
El modelo determinista
Definir modelo
Comience desde el modelo determinista (línea de base): una red residual de múltiples capas (ResNet) con regularización de abandono.
class DeepResNet(tf.keras.Model):
"""Defines a multi-layer residual network."""
def __init__(self, num_classes, num_layers=3, num_hidden=128,
dropout_rate=0.1, **classifier_kwargs):
super().__init__()
# Defines class meta data.
self.num_hidden = num_hidden
self.num_layers = num_layers
self.dropout_rate = dropout_rate
self.classifier_kwargs = classifier_kwargs
# Defines the hidden layers.
self.input_layer = tf.keras.layers.Dense(self.num_hidden, trainable=False)
self.dense_layers = [self.make_dense_layer() for _ in range(num_layers)]
# Defines the output layer.
self.classifier = self.make_output_layer(num_classes)
def call(self, inputs):
# Projects the 2d input data to high dimension.
hidden = self.input_layer(inputs)
# Computes the resnet hidden representations.
for i in range(self.num_layers):
resid = self.dense_layers[i](hidden)
resid = tf.keras.layers.Dropout(self.dropout_rate)(resid)
hidden += resid
return self.classifier(hidden)
def make_dense_layer(self):
"""Uses the Dense layer as the hidden layer."""
return tf.keras.layers.Dense(self.num_hidden, activation="relu")
def make_output_layer(self, num_classes):
"""Uses the Dense layer as the output layer."""
return tf.keras.layers.Dense(
num_classes, **self.classifier_kwargs)
Este tutorial utiliza una ResNet de 6 capas con 128 unidades ocultas.
resnet_config = dict(num_classes=2, num_layers=6, num_hidden=128)
resnet_model = DeepResNet(**resnet_config)
resnet_model.build((None, 2))
resnet_model.summary()
Model: "deep_res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 384
dense_1 (Dense) multiple 16512
dense_2 (Dense) multiple 16512
dense_3 (Dense) multiple 16512
dense_4 (Dense) multiple 16512
dense_5 (Dense) multiple 16512
dense_6 (Dense) multiple 16512
dense_7 (Dense) multiple 258
=================================================================
Total params: 99,714
Trainable params: 99,330
Non-trainable params: 384
_________________________________________________________________
modelo de tren
Configure los parámetros de entrenamiento para usar SparseCategoricalCrossentropy como la función de pérdida y el optimizador de Adam.
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metrics = tf.keras.metrics.SparseCategoricalAccuracy(),
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
train_config = dict(loss=loss, metrics=metrics, optimizer=optimizer)
Entrene el modelo para 100 épocas con tamaño de lote 128.
fit_config = dict(batch_size=128, epochs=100)
resnet_model.compile(**train_config)
resnet_model.fit(train_examples, train_labels, **fit_config)
Epoch 1/100 8/8 [==============================] - 1s 4ms/step - loss: 1.1251 - sparse_categorical_accuracy: 0.5050 Epoch 2/100 8/8 [==============================] - 0s 3ms/step - loss: 0.5538 - sparse_categorical_accuracy: 0.6920 Epoch 3/100 8/8 [==============================] - 0s 3ms/step - loss: 0.2881 - sparse_categorical_accuracy: 0.9160 Epoch 4/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1923 - sparse_categorical_accuracy: 0.9370 Epoch 5/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1550 - sparse_categorical_accuracy: 0.9420 Epoch 6/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1403 - sparse_categorical_accuracy: 0.9450 Epoch 7/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1269 - sparse_categorical_accuracy: 0.9430 Epoch 8/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1208 - sparse_categorical_accuracy: 0.9460 Epoch 9/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1158 - sparse_categorical_accuracy: 0.9510 Epoch 10/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1103 - sparse_categorical_accuracy: 0.9490 Epoch 11/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1051 - sparse_categorical_accuracy: 0.9510 Epoch 12/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1053 - sparse_categorical_accuracy: 0.9510 Epoch 13/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1013 - sparse_categorical_accuracy: 0.9450 Epoch 14/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0967 - sparse_categorical_accuracy: 0.9500 Epoch 15/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0991 - sparse_categorical_accuracy: 0.9530 Epoch 16/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0984 - sparse_categorical_accuracy: 0.9500 Epoch 17/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0982 - sparse_categorical_accuracy: 0.9480 Epoch 18/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0918 - sparse_categorical_accuracy: 0.9510 Epoch 19/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0903 - sparse_categorical_accuracy: 0.9500 Epoch 20/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0883 - sparse_categorical_accuracy: 0.9510 Epoch 21/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0870 - sparse_categorical_accuracy: 0.9530 Epoch 22/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0884 - sparse_categorical_accuracy: 0.9560 Epoch 23/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0850 - sparse_categorical_accuracy: 0.9540 Epoch 24/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0808 - sparse_categorical_accuracy: 0.9580 Epoch 25/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0773 - sparse_categorical_accuracy: 0.9560 Epoch 26/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0801 - sparse_categorical_accuracy: 0.9590 Epoch 27/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0779 - sparse_categorical_accuracy: 0.9580 Epoch 28/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0807 - sparse_categorical_accuracy: 0.9580 Epoch 29/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0820 - sparse_categorical_accuracy: 0.9570 Epoch 30/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0730 - sparse_categorical_accuracy: 0.9600 Epoch 31/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0782 - sparse_categorical_accuracy: 0.9590 Epoch 32/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0704 - sparse_categorical_accuracy: 0.9600 Epoch 33/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0709 - sparse_categorical_accuracy: 0.9610 Epoch 34/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0758 - sparse_categorical_accuracy: 0.9580 Epoch 35/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0702 - sparse_categorical_accuracy: 0.9610 Epoch 36/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0688 - sparse_categorical_accuracy: 0.9600 Epoch 37/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0675 - sparse_categorical_accuracy: 0.9630 Epoch 38/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0636 - sparse_categorical_accuracy: 0.9690 Epoch 39/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0677 - sparse_categorical_accuracy: 0.9610 Epoch 40/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0702 - sparse_categorical_accuracy: 0.9650 Epoch 41/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0614 - sparse_categorical_accuracy: 0.9690 Epoch 42/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0663 - sparse_categorical_accuracy: 0.9680 Epoch 43/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0626 - sparse_categorical_accuracy: 0.9740 Epoch 44/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0590 - sparse_categorical_accuracy: 0.9760 Epoch 45/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0573 - sparse_categorical_accuracy: 0.9780 Epoch 46/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0568 - sparse_categorical_accuracy: 0.9770 Epoch 47/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0595 - sparse_categorical_accuracy: 0.9780 Epoch 48/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0482 - sparse_categorical_accuracy: 0.9840 Epoch 49/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0515 - sparse_categorical_accuracy: 0.9820 Epoch 50/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0525 - sparse_categorical_accuracy: 0.9830 Epoch 51/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0507 - sparse_categorical_accuracy: 0.9790 Epoch 52/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0433 - sparse_categorical_accuracy: 0.9850 Epoch 53/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0511 - sparse_categorical_accuracy: 0.9820 Epoch 54/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0501 - sparse_categorical_accuracy: 0.9820 Epoch 55/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0440 - sparse_categorical_accuracy: 0.9890 Epoch 56/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0438 - sparse_categorical_accuracy: 0.9850 Epoch 57/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0438 - sparse_categorical_accuracy: 0.9880 Epoch 58/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0416 - sparse_categorical_accuracy: 0.9860 Epoch 59/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0479 - sparse_categorical_accuracy: 0.9860 Epoch 60/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0434 - sparse_categorical_accuracy: 0.9860 Epoch 61/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0414 - sparse_categorical_accuracy: 0.9880 Epoch 62/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0402 - sparse_categorical_accuracy: 0.9870 Epoch 63/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0376 - sparse_categorical_accuracy: 0.9890 Epoch 64/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0337 - sparse_categorical_accuracy: 0.9900 Epoch 65/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0309 - sparse_categorical_accuracy: 0.9910 Epoch 66/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0336 - sparse_categorical_accuracy: 0.9910 Epoch 67/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0389 - sparse_categorical_accuracy: 0.9870 Epoch 68/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0333 - sparse_categorical_accuracy: 0.9920 Epoch 69/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0331 - sparse_categorical_accuracy: 0.9890 Epoch 70/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0346 - sparse_categorical_accuracy: 0.9900 Epoch 71/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0367 - sparse_categorical_accuracy: 0.9880 Epoch 72/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0283 - sparse_categorical_accuracy: 0.9920 Epoch 73/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0315 - sparse_categorical_accuracy: 0.9930 Epoch 74/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0271 - sparse_categorical_accuracy: 0.9900 Epoch 75/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0257 - sparse_categorical_accuracy: 0.9920 Epoch 76/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0289 - sparse_categorical_accuracy: 0.9900 Epoch 77/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0264 - sparse_categorical_accuracy: 0.9900 Epoch 78/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0272 - sparse_categorical_accuracy: 0.9910 Epoch 79/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0336 - sparse_categorical_accuracy: 0.9880 Epoch 80/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0249 - sparse_categorical_accuracy: 0.9900 Epoch 81/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0216 - sparse_categorical_accuracy: 0.9930 Epoch 82/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0279 - sparse_categorical_accuracy: 0.9890 Epoch 83/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0261 - sparse_categorical_accuracy: 0.9920 Epoch 84/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0235 - sparse_categorical_accuracy: 0.9920 Epoch 85/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0236 - sparse_categorical_accuracy: 0.9930 Epoch 86/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0219 - sparse_categorical_accuracy: 0.9920 Epoch 87/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0196 - sparse_categorical_accuracy: 0.9920 Epoch 88/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0215 - sparse_categorical_accuracy: 0.9900 Epoch 89/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0223 - sparse_categorical_accuracy: 0.9900 Epoch 90/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0200 - sparse_categorical_accuracy: 0.9950 Epoch 91/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0250 - sparse_categorical_accuracy: 0.9900 Epoch 92/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0160 - sparse_categorical_accuracy: 0.9940 Epoch 93/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0203 - sparse_categorical_accuracy: 0.9930 Epoch 94/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0203 - sparse_categorical_accuracy: 0.9930 Epoch 95/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0172 - sparse_categorical_accuracy: 0.9960 Epoch 96/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0209 - sparse_categorical_accuracy: 0.9940 Epoch 97/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0179 - sparse_categorical_accuracy: 0.9920 Epoch 98/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0195 - sparse_categorical_accuracy: 0.9940 Epoch 99/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0165 - sparse_categorical_accuracy: 0.9930 Epoch 100/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0170 - sparse_categorical_accuracy: 0.9950 <keras.callbacks.History at 0x7ff7ac5c8fd0>
Visualiza la incertidumbre
def plot_uncertainty_surface(test_uncertainty, ax, cmap=None):
"""Visualizes the 2D uncertainty surface.
For simplicity, assume these objects already exist in the memory:
test_examples: Array of test examples, shape (num_test, 2).
train_labels: Array of train labels, shape (num_train, ).
train_examples: Array of train examples, shape (num_train, 2).
Arguments:
test_uncertainty: Array of uncertainty scores, shape (num_test,).
ax: A matplotlib Axes object that specifies a matplotlib figure.
cmap: A matplotlib colormap object specifying the palette of the
predictive surface.
Returns:
pcm: A matplotlib PathCollection object that contains the palette
information of the uncertainty plot.
"""
# Normalize uncertainty for better visualization.
test_uncertainty = test_uncertainty / np.max(test_uncertainty)
# Set view limits.
ax.set_ylim(DEFAULT_Y_RANGE)
ax.set_xlim(DEFAULT_X_RANGE)
# Plot normalized uncertainty surface.
pcm = ax.imshow(
np.reshape(test_uncertainty, [DEFAULT_N_GRID, DEFAULT_N_GRID]),
cmap=cmap,
origin="lower",
extent=DEFAULT_X_RANGE + DEFAULT_Y_RANGE,
vmin=DEFAULT_NORM.vmin,
vmax=DEFAULT_NORM.vmax,
interpolation='bicubic',
aspect='auto')
# Plot training data.
ax.scatter(train_examples[:, 0], train_examples[:, 1],
c=train_labels, cmap=DEFAULT_CMAP, alpha=0.5)
ax.scatter(ood_examples[:, 0], ood_examples[:, 1], c="red", alpha=0.1)
return pcm
Ahora visualiza las predicciones del modelo determinista. Primero traza la probabilidad de clase:
\[p(x) = softmax(logit(x))\]
resnet_logits = resnet_model(test_examples)
resnet_probs = tf.nn.softmax(resnet_logits, axis=-1)[:, 0] # Take the probability for class 0.
_, ax = plt.subplots(figsize=(7, 5.5))
pcm = plot_uncertainty_surface(resnet_probs, ax=ax)
plt.colorbar(pcm, ax=ax)
plt.title("Class Probability, Deterministic Model")
plt.show()

En este gráfico, el amarillo y el violeta son las probabilidades predictivas de las dos clases. El modelo determinista hizo un buen trabajo al clasificar las dos clases conocidas (azul y naranja) con un límite de decisión no lineal. Sin embargo, no tiene en cuenta la distancia y clasificó los ejemplos rojos fuera del dominio (OOD) nunca vistos con confianza como la clase naranja.
Visualice la incertidumbre del modelo calculando la varianza predictiva :
\[var(x) = p(x) * (1 - p(x))\]
resnet_uncertainty = resnet_probs * (1 - resnet_probs)
_, ax = plt.subplots(figsize=(7, 5.5))
pcm = plot_uncertainty_surface(resnet_uncertainty, ax=ax)
plt.colorbar(pcm, ax=ax)
plt.title("Predictive Uncertainty, Deterministic Model")
plt.show()

En este gráfico, el amarillo indica una incertidumbre alta y el violeta indica una incertidumbre baja. La incertidumbre de una ResNet determinista depende únicamente de la distancia de los ejemplos de prueba desde el límite de decisión. Esto lleva al modelo a tener un exceso de confianza cuando está fuera del dominio de entrenamiento. La siguiente sección muestra cómo SNGP se comporta de manera diferente en este conjunto de datos.
El modelo SNGP
Definir modelo SNGP
Ahora implementemos el modelo SNGP. Ambos componentes de SNGP, SpectralNormalization y RandomFeatureGaussianProcess , están disponibles en las capas integradas de tensorflow_model.
Veamos estos dos componentes con más detalle. (También puede saltar a la sección El modelo SNGP para ver cómo se implementa el modelo completo).
Envoltura de normalización espectral
SpectralNormalization es un contenedor de capas de Keras. Se puede aplicar a una capa densa existente como esta:
dense = tf.keras.layers.Dense(units=10)
dense = nlp_layers.SpectralNormalization(dense, norm_multiplier=0.9)
La normalización espectral regulariza el peso oculto \(W\) al guiar gradualmente su norma espectral (es decir, el valor propio más grande de \(W\)) hacia el valor objetivo norm_multiplier .
La capa del Proceso Gaussiano (GP)
RandomFeatureGaussianProcess implementa una aproximación basada en características aleatorias a un modelo de proceso gaussiano que se puede entrenar de extremo a extremo con una red neuronal profunda. Debajo del capó, la capa de proceso gaussiano implementa una red de dos capas:
\[logits(x) = \Phi(x) \beta, \quad \Phi(x)=\sqrt{\frac{2}{M} } * cos(Wx + b)\]
Aquí \(x\) es la entrada, y \(W\) y \(b\) son pesos congelados inicializados aleatoriamente a partir de distribuciones gaussianas y uniformes, respectivamente. (Por lo tanto \(\Phi(x)\) se denominan "características aleatorias"). \(\beta\) es el peso del núcleo aprendible similar al de una capa densa.
batch_size = 32
input_dim = 1024
num_classes = 10
gp_layer = nlp_layers.RandomFeatureGaussianProcess(units=num_classes,
num_inducing=1024,
normalize_input=False,
scale_random_features=True,
gp_cov_momentum=-1)
Los principales parámetros de las capas GP son:
-
units: La dimensión de los logits de salida. -
num_inducing: La dimensión \(M\) del peso oculto \(W\). Por defecto a 1024. -
normalize_input: si aplicar la normalización de capa a la entrada \(x\). -
scale_random_features: si aplicar la escala \(\sqrt{2/M}\) a la salida oculta.
-
gp_cov_momentumcontrola cómo se calcula la covarianza del modelo. Si se establece en un valor positivo (p. ej., 0,999), la matriz de covarianza se calcula utilizando la actualización del promedio móvil basada en el impulso (similar a la normalización por lotes). Si se establece en -1, la matriz de covarianza se actualiza sin impulso.
Dada una entrada por lotes con forma (batch_size, input_dim) , la capa GP devuelve un tensor logits (forma (batch_size, num_classes) ) para la predicción, y también un tensor covmat (forma (batch_size, batch_size) ) que es la matriz de covarianza posterior de la logaritmos por lotes.
embedding = tf.random.normal(shape=(batch_size, input_dim))
logits, covmat = gp_layer(embedding)
Teóricamente, es posible extender el algoritmo para calcular diferentes valores de varianza para diferentes clases (como se introdujo en el artículo original de SNGP ). Sin embargo, esto es difícil de escalar a problemas con grandes espacios de salida (por ejemplo, ImageNet o modelado de lenguaje).
El modelo SNGP completo
Dada la clase base DeepResNet , el modelo SNGP se puede implementar fácilmente modificando las capas ocultas y de salida de la red residual. Para compatibilidad con la API model.fit() de Keras, modifique también el método call() del modelo para que solo logits durante el entrenamiento.
class DeepResNetSNGP(DeepResNet):
def __init__(self, spec_norm_bound=0.9, **kwargs):
self.spec_norm_bound = spec_norm_bound
super().__init__(**kwargs)
def make_dense_layer(self):
"""Applies spectral normalization to the hidden layer."""
dense_layer = super().make_dense_layer()
return nlp_layers.SpectralNormalization(
dense_layer, norm_multiplier=self.spec_norm_bound)
def make_output_layer(self, num_classes):
"""Uses Gaussian process as the output layer."""
return nlp_layers.RandomFeatureGaussianProcess(
num_classes,
gp_cov_momentum=-1,
**self.classifier_kwargs)
def call(self, inputs, training=False, return_covmat=False):
# Gets logits and covariance matrix from GP layer.
logits, covmat = super().call(inputs)
# Returns only logits during training.
if not training and return_covmat:
return logits, covmat
return logits
Utilice la misma arquitectura que el modelo determinista.
resnet_config
{'num_classes': 2, 'num_layers': 6, 'num_hidden': 128}
sngp_model = DeepResNetSNGP(**resnet_config)
sngp_model.build((None, 2))
sngp_model.summary()
Model: "deep_res_net_sngp"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) multiple 384
spectral_normalization_1 (S multiple 16768
pectralNormalization)
spectral_normalization_2 (S multiple 16768
pectralNormalization)
spectral_normalization_3 (S multiple 16768
pectralNormalization)
spectral_normalization_4 (S multiple 16768
pectralNormalization)
spectral_normalization_5 (S multiple 16768
pectralNormalization)
spectral_normalization_6 (S multiple 16768
pectralNormalization)
random_feature_gaussian_pro multiple 1182722
cess (RandomFeatureGaussian
Process)
=================================================================
Total params: 1,283,714
Trainable params: 101,120
Non-trainable params: 1,182,594
_________________________________________________________________
Implemente una devolución de llamada de Keras para restablecer la matriz de covarianza al comienzo de una nueva época.
class ResetCovarianceCallback(tf.keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs=None):
"""Resets covariance matrix at the begining of the epoch."""
if epoch > 0:
self.model.classifier.reset_covariance_matrix()
Agregue esta devolución de llamada a la clase de modelo DeepResNetSNGP .
class DeepResNetSNGPWithCovReset(DeepResNetSNGP):
def fit(self, *args, **kwargs):
"""Adds ResetCovarianceCallback to model callbacks."""
kwargs["callbacks"] = list(kwargs.get("callbacks", []))
kwargs["callbacks"].append(ResetCovarianceCallback())
return super().fit(*args, **kwargs)
modelo de tren
Utilice tf.keras.model.fit para entrenar el modelo.
sngp_model = DeepResNetSNGPWithCovReset(**resnet_config)
sngp_model.compile(**train_config)
sngp_model.fit(train_examples, train_labels, **fit_config)
Epoch 1/100 8/8 [==============================] - 2s 5ms/step - loss: 0.6223 - sparse_categorical_accuracy: 0.9570 Epoch 2/100 8/8 [==============================] - 0s 4ms/step - loss: 0.5310 - sparse_categorical_accuracy: 0.9980 Epoch 3/100 8/8 [==============================] - 0s 4ms/step - loss: 0.4766 - sparse_categorical_accuracy: 0.9990 Epoch 4/100 8/8 [==============================] - 0s 5ms/step - loss: 0.4346 - sparse_categorical_accuracy: 0.9980 Epoch 5/100 8/8 [==============================] - 0s 5ms/step - loss: 0.4015 - sparse_categorical_accuracy: 0.9980 Epoch 6/100 8/8 [==============================] - 0s 5ms/step - loss: 0.3757 - sparse_categorical_accuracy: 0.9990 Epoch 7/100 8/8 [==============================] - 0s 4ms/step - loss: 0.3525 - sparse_categorical_accuracy: 0.9990 Epoch 8/100 8/8 [==============================] - 0s 4ms/step - loss: 0.3305 - sparse_categorical_accuracy: 0.9990 Epoch 9/100 8/8 [==============================] - 0s 5ms/step - loss: 0.3144 - sparse_categorical_accuracy: 0.9980 Epoch 10/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2975 - sparse_categorical_accuracy: 0.9990 Epoch 11/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2832 - sparse_categorical_accuracy: 0.9990 Epoch 12/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2707 - sparse_categorical_accuracy: 0.9990 Epoch 13/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2568 - sparse_categorical_accuracy: 0.9990 Epoch 14/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2470 - sparse_categorical_accuracy: 0.9970 Epoch 15/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2361 - sparse_categorical_accuracy: 0.9990 Epoch 16/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2271 - sparse_categorical_accuracy: 0.9990 Epoch 17/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2182 - sparse_categorical_accuracy: 0.9990 Epoch 18/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2097 - sparse_categorical_accuracy: 0.9990 Epoch 19/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2018 - sparse_categorical_accuracy: 0.9990 Epoch 20/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1940 - sparse_categorical_accuracy: 0.9980 Epoch 21/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1892 - sparse_categorical_accuracy: 0.9990 Epoch 22/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1821 - sparse_categorical_accuracy: 0.9980 Epoch 23/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1768 - sparse_categorical_accuracy: 0.9990 Epoch 24/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1702 - sparse_categorical_accuracy: 0.9980 Epoch 25/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1664 - sparse_categorical_accuracy: 0.9990 Epoch 26/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1604 - sparse_categorical_accuracy: 0.9990 Epoch 27/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1565 - sparse_categorical_accuracy: 0.9990 Epoch 28/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1517 - sparse_categorical_accuracy: 0.9990 Epoch 29/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1469 - sparse_categorical_accuracy: 0.9990 Epoch 30/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1431 - sparse_categorical_accuracy: 0.9980 Epoch 31/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1385 - sparse_categorical_accuracy: 0.9980 Epoch 32/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1351 - sparse_categorical_accuracy: 0.9990 Epoch 33/100 8/8 [==============================] - 0s 5ms/step - loss: 0.1312 - sparse_categorical_accuracy: 0.9980 Epoch 34/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1289 - sparse_categorical_accuracy: 0.9990 Epoch 35/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1254 - sparse_categorical_accuracy: 0.9980 Epoch 36/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1223 - sparse_categorical_accuracy: 0.9980 Epoch 37/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1180 - sparse_categorical_accuracy: 0.9990 Epoch 38/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1167 - sparse_categorical_accuracy: 0.9990 Epoch 39/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1132 - sparse_categorical_accuracy: 0.9980 Epoch 40/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1110 - sparse_categorical_accuracy: 0.9990 Epoch 41/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1075 - sparse_categorical_accuracy: 0.9990 Epoch 42/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1067 - sparse_categorical_accuracy: 0.9990 Epoch 43/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1034 - sparse_categorical_accuracy: 0.9990 Epoch 44/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1006 - sparse_categorical_accuracy: 0.9990 Epoch 45/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0991 - sparse_categorical_accuracy: 0.9990 Epoch 46/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0963 - sparse_categorical_accuracy: 0.9990 Epoch 47/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0943 - sparse_categorical_accuracy: 0.9980 Epoch 48/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0925 - sparse_categorical_accuracy: 0.9990 Epoch 49/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0905 - sparse_categorical_accuracy: 0.9990 Epoch 50/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0889 - sparse_categorical_accuracy: 0.9990 Epoch 51/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0863 - sparse_categorical_accuracy: 0.9980 Epoch 52/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0847 - sparse_categorical_accuracy: 0.9990 Epoch 53/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0831 - sparse_categorical_accuracy: 0.9980 Epoch 54/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0818 - sparse_categorical_accuracy: 0.9990 Epoch 55/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0799 - sparse_categorical_accuracy: 0.9990 Epoch 56/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0780 - sparse_categorical_accuracy: 0.9990 Epoch 57/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0768 - sparse_categorical_accuracy: 0.9990 Epoch 58/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0751 - sparse_categorical_accuracy: 0.9990 Epoch 59/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0748 - sparse_categorical_accuracy: 0.9990 Epoch 60/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0723 - sparse_categorical_accuracy: 0.9990 Epoch 61/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0712 - sparse_categorical_accuracy: 0.9990 Epoch 62/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0701 - sparse_categorical_accuracy: 0.9990 Epoch 63/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0701 - sparse_categorical_accuracy: 0.9990 Epoch 64/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0683 - sparse_categorical_accuracy: 0.9990 Epoch 65/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0665 - sparse_categorical_accuracy: 0.9990 Epoch 66/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0661 - sparse_categorical_accuracy: 0.9990 Epoch 67/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0636 - sparse_categorical_accuracy: 0.9990 Epoch 68/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0631 - sparse_categorical_accuracy: 0.9990 Epoch 69/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0620 - sparse_categorical_accuracy: 0.9990 Epoch 70/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0606 - sparse_categorical_accuracy: 0.9990 Epoch 71/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0601 - sparse_categorical_accuracy: 0.9980 Epoch 72/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0590 - sparse_categorical_accuracy: 0.9990 Epoch 73/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0586 - sparse_categorical_accuracy: 0.9990 Epoch 74/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0574 - sparse_categorical_accuracy: 0.9990 Epoch 75/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0565 - sparse_categorical_accuracy: 1.0000 Epoch 76/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0559 - sparse_categorical_accuracy: 0.9990 Epoch 77/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0549 - sparse_categorical_accuracy: 0.9990 Epoch 78/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0534 - sparse_categorical_accuracy: 1.0000 Epoch 79/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0532 - sparse_categorical_accuracy: 0.9990 Epoch 80/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0519 - sparse_categorical_accuracy: 1.0000 Epoch 81/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0511 - sparse_categorical_accuracy: 1.0000 Epoch 82/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0508 - sparse_categorical_accuracy: 0.9990 Epoch 83/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0499 - sparse_categorical_accuracy: 1.0000 Epoch 84/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0490 - sparse_categorical_accuracy: 1.0000 Epoch 85/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0490 - sparse_categorical_accuracy: 0.9990 Epoch 86/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0470 - sparse_categorical_accuracy: 1.0000 Epoch 87/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0468 - sparse_categorical_accuracy: 1.0000 Epoch 88/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0468 - sparse_categorical_accuracy: 1.0000 Epoch 89/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0453 - sparse_categorical_accuracy: 1.0000 Epoch 90/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0448 - sparse_categorical_accuracy: 1.0000 Epoch 91/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0441 - sparse_categorical_accuracy: 1.0000 Epoch 92/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0434 - sparse_categorical_accuracy: 1.0000 Epoch 93/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0431 - sparse_categorical_accuracy: 1.0000 Epoch 94/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0424 - sparse_categorical_accuracy: 1.0000 Epoch 95/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0420 - sparse_categorical_accuracy: 1.0000 Epoch 96/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0415 - sparse_categorical_accuracy: 1.0000 Epoch 97/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0409 - sparse_categorical_accuracy: 1.0000 Epoch 98/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0401 - sparse_categorical_accuracy: 1.0000 Epoch 99/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0396 - sparse_categorical_accuracy: 1.0000 Epoch 100/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0392 - sparse_categorical_accuracy: 1.0000 <keras.callbacks.History at 0x7ff7ac0f83d0>
Visualiza la incertidumbre
Primero calcule los logits predictivos y las varianzas.
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_variance = tf.linalg.diag_part(sngp_covmat)[:, None]
Ahora calcule la probabilidad predictiva posterior. El método clásico para calcular la probabilidad predictiva de un modelo probabilístico es utilizar el muestreo Monte Carlo, es decir,
\[E(p(x)) = \frac{1}{M} \sum_{m=1}^M logit_m(x), \]
donde \(M\) es el tamaño de la muestra y \(logit_m(x)\) son muestras aleatorias del SNGP posterior \(MultivariateNormal\)( sngp_logits , sngp_covmat ). Sin embargo, este enfoque puede ser lento para aplicaciones sensibles a la latencia, como la conducción autónoma o las ofertas en tiempo real. En cambio, puede aproximar \(E(p(x))\) usando el método de campo medio :
\[E(p(x)) \approx softmax(\frac{logit(x)}{\sqrt{1+ \lambda * \sigma^2(x)} })\]
donde \(\sigma^2(x)\) es la varianza de SNGP, y \(\lambda\) a menudo se elige como \(\pi/8\) o \(3/\pi^2\).
sngp_logits_adjusted = sngp_logits / tf.sqrt(1. + (np.pi / 8.) * sngp_variance)
sngp_probs = tf.nn.softmax(sngp_logits_adjusted, axis=-1)[:, 0]
Este método de campo medio se implementa como una función layers.gaussian_process.mean_field_logits :
def compute_posterior_mean_probability(logits, covmat, lambda_param=np.pi / 8.):
# Computes uncertainty-adjusted logits using the built-in method.
logits_adjusted = nlp_layers.gaussian_process.mean_field_logits(
logits, covmat, mean_field_factor=lambda_param)
return tf.nn.softmax(logits_adjusted, axis=-1)[:, 0]
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_probs = compute_posterior_mean_probability(sngp_logits, sngp_covmat)
Resumen de SNGP
def plot_predictions(pred_probs, model_name=""):
"""Plot normalized class probabilities and predictive uncertainties."""
# Compute predictive uncertainty.
uncertainty = pred_probs * (1. - pred_probs)
# Initialize the plot axes.
fig, axs = plt.subplots(1, 2, figsize=(14, 5))
# Plots the class probability.
pcm_0 = plot_uncertainty_surface(pred_probs, ax=axs[0])
# Plots the predictive uncertainty.
pcm_1 = plot_uncertainty_surface(uncertainty, ax=axs[1])
# Adds color bars and titles.
fig.colorbar(pcm_0, ax=axs[0])
fig.colorbar(pcm_1, ax=axs[1])
axs[0].set_title(f"Class Probability, {model_name}")
axs[1].set_title(f"(Normalized) Predictive Uncertainty, {model_name}")
plt.show()
Pon todo junto. Todo el procedimiento (entrenamiento, evaluación y cálculo de incertidumbre) se puede realizar en tan solo cinco líneas:
def train_and_test_sngp(train_examples, test_examples):
sngp_model = DeepResNetSNGPWithCovReset(**resnet_config)
sngp_model.compile(**train_config)
sngp_model.fit(train_examples, train_labels, verbose=0, **fit_config)
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_probs = compute_posterior_mean_probability(sngp_logits, sngp_covmat)
return sngp_probs
sngp_probs = train_and_test_sngp(train_examples, test_examples)
Visualice la probabilidad de clase (izquierda) y la incertidumbre predictiva (derecha) del modelo SNGP.
plot_predictions(sngp_probs, model_name="SNGP")

Recuerde que en la gráfica de probabilidad de clase (izquierda), el amarillo y el morado son probabilidades de clase. Cuando está cerca del dominio de datos de entrenamiento, SNGP clasifica correctamente los ejemplos con alta confianza (es decir, asignando una probabilidad cercana a 0 o 1). Cuando está lejos de los datos de entrenamiento, SNGP gradualmente pierde confianza y su probabilidad predictiva se acerca a 0,5 mientras que la incertidumbre del modelo (normalizado) aumenta a 1.
Compare esto con la superficie de incertidumbre del modelo determinista:
plot_predictions(resnet_probs, model_name="Deterministic")

Como se mencionó anteriormente, un modelo determinista no tiene en cuenta la distancia . Su incertidumbre se define por la distancia del ejemplo de prueba desde el límite de decisión. Esto lleva al modelo a producir predicciones demasiado seguras para los ejemplos fuera del dominio (rojo).
Comparación con otros enfoques de incertidumbre
Esta sección compara la incertidumbre de SNGP con la deserción de Monte Carlo y el conjunto profundo .
Ambos métodos se basan en el promedio de Monte Carlo de múltiples pases hacia adelante de modelos deterministas. Primero establezca el tamaño del conjunto \(M\).
num_ensemble = 10
Abandono de Montecarlo
Dada una red neuronal entrenada con capas de abandono, el abandono de Monte Carlo calcula la probabilidad predictiva media
\[E(p(x)) = \frac{1}{M}\sum_{m=1}^M softmax(logit_m(x))\]
promediando varios pases hacia adelante habilitados para abandono \(\{logit_m(x)\}_{m=1}^M\).
def mc_dropout_sampling(test_examples):
# Enable dropout during inference.
return resnet_model(test_examples, training=True)
# Monte Carlo dropout inference.
dropout_logit_samples = [mc_dropout_sampling(test_examples) for _ in range(num_ensemble)]
dropout_prob_samples = [tf.nn.softmax(dropout_logits, axis=-1)[:, 0] for dropout_logits in dropout_logit_samples]
dropout_probs = tf.reduce_mean(dropout_prob_samples, axis=0)
dropout_probs = tf.reduce_mean(dropout_prob_samples, axis=0)
plot_predictions(dropout_probs, model_name="MC Dropout")

conjunto profundo
El conjunto profundo es un método de última generación (pero costoso) para la incertidumbre del aprendizaje profundo. Para entrenar un conjunto profundo, primero entrene a los miembros del conjunto \(M\) .
# Deep ensemble training
resnet_ensemble = []
for _ in range(num_ensemble):
resnet_model = DeepResNet(**resnet_config)
resnet_model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
resnet_model.fit(train_examples, train_labels, verbose=0, **fit_config)
resnet_ensemble.append(resnet_model)
Recopile logits y calcule la probabilidad predictiva media \(E(p(x)) = \frac{1}{M}\sum_{m=1}^M softmax(logit_m(x))\).
# Deep ensemble inference
ensemble_logit_samples = [model(test_examples) for model in resnet_ensemble]
ensemble_prob_samples = [tf.nn.softmax(logits, axis=-1)[:, 0] for logits in ensemble_logit_samples]
ensemble_probs = tf.reduce_mean(ensemble_prob_samples, axis=0)
plot_predictions(ensemble_probs, model_name="Deep ensemble")

Tanto MC Dropout como Deep ensemble mejoran la capacidad de incertidumbre de un modelo al hacer que el límite de decisión sea menos seguro. Sin embargo, ambos heredan la limitación de la red profunda determinista al carecer de conciencia de la distancia.
Resumen
En este tutorial, usted tiene:
- Implementó un modelo SNGP en un clasificador profundo para mejorar su conocimiento de la distancia.
- Entrenó el modelo SNGP de extremo a extremo utilizando la API de Keras
model.fit(). - Visualizó el comportamiento de incertidumbre de SNGP.
- Comparó el comportamiento de la incertidumbre entre SNGP, la caída de Monte Carlo y los modelos de conjuntos profundos.
Recursos y lecturas adicionales
- Consulte el tutorial de SNGP-BERT para ver un ejemplo de aplicación de SNGP en un modelo BERT para la comprensión del lenguaje natural consciente de la incertidumbre.
- Consulte las líneas de base de incertidumbre para la implementación del modelo SNGP (y muchos otros métodos de incertidumbre) en una amplia variedad de conjuntos de datos de referencia (p. ej., CIFAR , ImageNet , detección de toxicidad de rompecabezas, etc.).
- Para una comprensión más profunda del método SNGP, consulte el documento Estimación de incertidumbre simple y basada en principios con aprendizaje profundo determinista a través de la conciencia de la distancia .