
ลิขสิทธิ์ 2020 The TF-Agents Authors.
เริ่ม
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ติดตั้ง
หากคุณไม่ได้ติดตั้งการพึ่งพาต่อไปนี้ ให้เรียกใช้:
pip install tf-agents
นำเข้า
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
บทนำ
ปัญหา Multi-Armed Bandit (MAB) เป็นกรณีพิเศษของ Reinforcement Learning: ตัวแทนรวบรวมรางวัลในสภาพแวดล้อมโดยดำเนินการบางอย่างหลังจากสังเกตสภาพแวดล้อมบางอย่าง ความแตกต่างที่สำคัญระหว่าง RL ทั่วไปและ MAB คือใน MAB เราถือว่าการกระทำที่ดำเนินการโดยตัวแทนไม่ส่งผลต่อสภาวะแวดล้อมถัดไป ดังนั้น ตัวแทนจะไม่จำลองการเปลี่ยนแปลงของรัฐ ให้เครดิตกับการกระทำในอดีต หรือ "วางแผนล่วงหน้า" เพื่อไปยังรัฐที่อุดมด้วยรางวัล
ในฐานะที่เป็นโดเมน RL อื่น ๆ เป้าหมายของการเป็นตัวแทน MAB คือการหานโยบายที่เก็บรวบรวมเป็นรางวัลมากที่สุดเท่าที่เป็นไปได้ มันจะเป็นความผิดพลาด อย่างไรก็ตาม ที่จะพยายามใช้ประโยชน์จากการกระทำที่ให้รางวัลสูงสุดเสมอ เพราะมีโอกาสที่เราจะพลาดการกระทำที่ดีขึ้นหากเราไม่สำรวจเพียงพอ นี่คือปัญหาหลักที่จะแก้ไขได้ใน (MAB) มักจะเรียกว่าภาวะที่กลืนไม่เข้าคายไม่ออกสำรวจการใช้ประโยชน์
สภาพแวดล้อมโจรนโยบายและตัวแทน MAB สามารถพบได้ในไดเรกทอรีย่อยของ tf_agents / โจร
สิ่งแวดล้อม
ในตัวแทน TF, ระดับสภาพแวดล้อมในการทำหน้าที่บทบาทของการให้ข้อมูลเกี่ยวกับสถานะปัจจุบัน (เรียกว่าการสังเกตหรือบริบท) ได้รับการดำเนินการเป็น input ดำเนินการเปลี่ยนแปลงของรัฐและการแสดงผลให้รางวัล ชั้นเรียนนี้ยังดูแลการรีเซ็ตเมื่อตอนสิ้นสุด เพื่อให้สามารถเริ่มตอนใหม่ได้ นี้เป็นตระหนักโดยเรียก reset ฟังก์ชั่นเมื่อรัฐจะมีป้าย "สุดท้าย" ของบท
สำหรับรายละเอียดเพิ่มเติมโปรดดูที่ TF ตัวแทนสภาพแวดล้อมที่กวดวิชา
ดังที่กล่าวไว้ข้างต้น MAB แตกต่างจาก RL ทั่วไปในการกระทำที่ไม่ส่งผลต่อการสังเกตครั้งต่อไป ข้อแตกต่างอีกประการหนึ่งคือใน Bandits ไม่มี "ตอน": ทุกๆ ขั้นตอนเริ่มต้นด้วยการสังเกตใหม่ โดยไม่ขึ้นกับขั้นตอนของเวลาก่อนหน้า
เพื่อให้แน่ใจว่าการสังเกตมีความเป็นอิสระและห่างนามธรรมแนวคิดของ RL ตอนเราแนะนำ subclasses ของ PyEnvironment และ TFEnvironment : BanditPyEnvironment และ BanditTFEnvironment คลาสเหล่านี้แสดงฟังก์ชันสมาชิกไพรเวตสองฟังก์ชันที่ผู้ใช้ยังคงใช้งาน:
@abc.abstractmethod
def _observe(self):
และ
@abc.abstractmethod
def _apply_action(self, action):
_observe ฟังก์ชันส่งกลับสังเกต จากนั้นนโยบายจะเลือกการดำเนินการตามข้อสังเกตนี้ _apply_action ได้รับการดำเนินการที่เป็น input และผลตอบแทนผลตอบแทนที่สอดคล้องกัน เหล่านี้ฟังก์ชั่นสมาชิกส่วนตัวเขาเรียกด้วยฟังก์ชั่น reset และ step ตามลำดับ
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
ระหว่างกาลดังกล่าวข้างต้นการดำเนินการระดับนามธรรม PyEnvironment 's _reset และ _step ฟังก์ชั่นและจะแสดงฟังก์ชั่นที่เป็นนามธรรม _observe และ _apply_action ที่จะดำเนินการโดย subclasses
คลาสสภาพแวดล้อมตัวอย่างอย่างง่าย
คลาสต่อไปนี้ให้สภาพแวดล้อมที่เรียบง่าย ซึ่งการสังเกตเป็นจำนวนเต็มสุ่มระหว่าง -2 ถึง 2 มี 3 การกระทำที่เป็นไปได้ (0, 1, 2) และรางวัลเป็นผลจากการกระทำและการสังเกต
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
ตอนนี้ เราสามารถใช้สภาพแวดล้อมนี้เพื่อรับการสังเกต และรับรางวัลสำหรับการกระทำของเรา
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
สภาพแวดล้อม TF
หนึ่งสามารถกำหนดสภาพแวดล้อมโจรโดย subclassing BanditTFEnvironment หรือคล้าย ๆ กับสภาพแวดล้อม RL หนึ่งสามารถกำหนด BanditPyEnvironment และห่อมันด้วย TFPyEnvironment เพื่อความเรียบง่าย เราใช้ตัวเลือกหลังในบทช่วยสอนนี้
tf_environment = tf_py_environment.TFPyEnvironment(environment)
นโยบาย
นโยบายในปัญหาโจรทำงานในลักษณะเดียวกันในขณะที่ปัญหา RL: การที่จะให้การดำเนินการ (หรือการกระจายของการกระทำ) ที่ได้รับการสังเกตเป็น input
สำหรับรายละเอียดเพิ่มเติมโปรดดูที่ TF-ตัวแทนนโยบายการกวดวิชา
เช่นเดียวกับสภาพแวดล้อมที่มีสองวิธีในการสร้างนโยบาย: หนึ่งสามารถสร้าง PyPolicy และห่อมันด้วย TFPyPolicy หรือโดยตรงสร้าง TFPolicy ที่นี่เราเลือกที่จะไปกับวิธีการโดยตรง
เนื่องจากตัวอย่างนี้ค่อนข้างง่าย เราจึงสามารถกำหนดนโยบายที่เหมาะสมได้ด้วยตนเอง การกระทำขึ้นอยู่กับเครื่องหมายของการสังเกตเท่านั้น 0 เมื่อเป็นลบและ 2 เมื่อเป็นบวก
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
ตอนนี้เราสามารถขอการสังเกตจากสิ่งแวดล้อม เรียกนโยบายเพื่อเลือกการกระทำ จากนั้นสภาพแวดล้อมจะให้รางวัล:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
วิธีการใช้งานสภาพแวดล้อมของโจรทำให้มั่นใจได้ว่าทุกครั้งที่เราก้าว เราไม่เพียงได้รับรางวัลสำหรับการกระทำที่เราทำ แต่ยังได้รับการสังเกตในครั้งต่อไปด้วย
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
ตัวแทน
ตอนนี้เรามีสภาพแวดล้อมของโจรและนโยบายของโจรแล้ว ก็ถึงเวลากำหนดตัวแทนโจรที่ดูแลการเปลี่ยนแปลงนโยบายตามตัวอย่างการฝึกอบรม
API ที่สำหรับตัวแทนโจรไม่แตกต่างจากที่ของตัวแทน RL: ตัวแทนเพียงแค่ต้องการที่จะใช้ _initialize และ _train วิธีการและกำหนด policy และ collect_policy
สภาพแวดล้อมที่ซับซ้อนมากขึ้น
ก่อนที่เราจะเขียนตัวแทนโจร เราจำเป็นต้องมีสภาพแวดล้อมที่เข้าใจยากขึ้นเล็กน้อย เพื่อเครื่องเทศขึ้นสิ่งเพียงนิด ๆ หน่อย ๆ สภาพแวดล้อมต่อไปอย่างใดอย่างหนึ่งมักจะให้ reward = observation * action หรือ reward = -observation * action สิ่งนี้จะถูกตัดสินเมื่อสภาพแวดล้อมเริ่มต้น
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
นโยบายที่ซับซ้อนยิ่งขึ้น
สภาพแวดล้อมที่ซับซ้อนมากขึ้นเรียกร้องให้มีนโยบายที่ซับซ้อนมากขึ้น เราต้องการนโยบายที่ตรวจจับพฤติกรรมของสภาพแวดล้อมพื้นฐาน มีสามสถานการณ์ที่นโยบายต้องจัดการ:
- เอเจนต์ยังไม่ตรวจพบว่ายังรู้ว่าสภาพแวดล้อมเวอร์ชันใดกำลังทำงานอยู่
- เอเจนต์ตรวจพบว่าเวอร์ชันดั้งเดิมของสภาพแวดล้อมกำลังทำงานอยู่
- เอเจนต์ตรวจพบว่าเวอร์ชันพลิกของสภาพแวดล้อมกำลังทำงานอยู่
เรากำหนด tf_variable ชื่อ _situation เพื่อเก็บข้อมูลนี้เข้ารหัสเป็นค่าใน [0, 2] แล้วให้ประพฤติตามนโยบาย
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
ตัวแทน
ถึงเวลากำหนดตัวแทนที่ตรวจจับสัญญาณของสภาพแวดล้อมและกำหนดนโยบายอย่างเหมาะสม
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
ในโค้ดข้างต้นตัวแทนกำหนดนโยบายและตัวแปร situation ร่วมกันโดยตัวแทนและนโยบาย
นอกจากนี้พารามิเตอร์ experience ของ _train ฟังก์ชั่นเป็นวิถี:
วิถี
ในตัวแทน TF, trajectories มีชื่ออันดับที่มีตัวอย่างจากขั้นตอนก่อนหน้านี้ จากนั้นตัวแทนจะใช้ตัวอย่างเหล่านี้ในการฝึกอบรมและปรับปรุงนโยบาย ใน RL เส้นทางวิถีต้องมีข้อมูลเกี่ยวกับสถานะปัจจุบัน สถานะถัดไป และตอนปัจจุบันสิ้นสุดหรือไม่ เนื่องจากในโลกของโจร เราไม่ต้องการสิ่งเหล่านี้ เราจึงตั้งค่าฟังก์ชันตัวช่วยเพื่อสร้างวิถี:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
การฝึกอบรมตัวแทน
ตอนนี้ชิ้นส่วนทั้งหมดพร้อมสำหรับการฝึกตัวแทนโจรของเราแล้ว
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
จากผลลัพธ์จะเห็นได้ว่าหลังจากขั้นตอนที่สอง (เว้นแต่การสังเกตเป็น 0 ในขั้นตอนแรก) นโยบายจะเลือกการดำเนินการในทางที่ถูกต้อง ดังนั้นรางวัลที่รวบรวมได้จะไม่เป็นลบเสมอ
ตัวอย่างโจรตามบริบทที่แท้จริง
ในส่วนที่เหลือของการกวดวิชานี้เราจะใช้ก่อนการใช้งาน สภาพแวดล้อม และ ตัวแทน ของ TF-ตัวแทนห้องสมุดโจร
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
สภาพแวดล้อม Stochastic แบบคงที่พร้อมฟังก์ชัน Linear Payoff
สภาพแวดล้อมที่ใช้ในตัวอย่างนี้เป็น StationaryStochasticPyEnvironment สภาพแวดล้อมนี้ใช้เป็นพารามิเตอร์ a (มักจะมีสัญญาณรบกวน) สำหรับการสังเกตการณ์ (บริบท) และสำหรับทุกแขนจะมีฟังก์ชัน (ที่มีเสียงรบกวน) ที่คำนวณรางวัลตามการสังเกตที่ได้รับ ในตัวอย่างของเรา เราสุ่มตัวอย่างบริบทอย่างสม่ำเสมอจากลูกบาศก์มิติ d และฟังก์ชันการให้รางวัลเป็นฟังก์ชันเชิงเส้นของบริบท บวกกับสัญญาณรบกวนแบบเกาส์เซียนบางส่วน
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
ตัวแทน LinUCB
ตัวแทนดำเนินการดังต่อไปนี้ LinUCB อัลกอริทึม
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
เมตริกเสียใจ
โจรตัวชี้วัดที่สำคัญที่สุดคือความเสียใจคำนวณเป็นความแตกต่างระหว่างผลตอบแทนที่เก็บรวบรวมโดยตัวแทนและผลตอบแทนที่คาดหวังของนโยบายการพยากรณ์ที่มีการเข้าถึงฟังก์ชั่นรางวัลของสภาพแวดล้อม RegretMetric จึงจำเป็นต้องมีฟังก์ชั่น baseline_reward_fn ที่คำนวณที่ดีที่สุดรางวัลที่คาดว่าจะประสบความสำเร็จได้รับการสังเกต สำหรับตัวอย่างของเรา เราต้องใช้ฟังก์ชันการให้รางวัลที่เทียบเท่ากับเสียงที่ไม่มีเสียงรบกวนมากที่สุดที่เรากำหนดไว้สำหรับสภาพแวดล้อมแล้ว
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
การฝึกอบรม
ตอนนี้ เราได้รวบรวมองค์ประกอบทั้งหมดที่เราแนะนำไว้ข้างต้น: สภาพแวดล้อม นโยบาย และตัวแทน เราทำงานนโยบายเกี่ยวกับสภาพแวดล้อมและการฝึกอบรมการส่งออกข้อมูลด้วยความช่วยเหลือของคนขับรถและการฝึกอบรมตัวแทนในข้อมูล
โปรดทราบว่ามีสองพารามิเตอร์ที่ระบุจำนวนขั้นตอนที่ดำเนินการร่วมกัน num_iterations ระบุว่าหลายครั้งที่เราทำงานห่วงฝึกสอนในขณะที่คนขับรถที่จะนำ steps_per_loop ขั้นตอนต่อซ้ำ เหตุผลหลักที่อยู่เบื้องหลังการรักษาพารามิเตอร์ทั้งสองนี้ก็คือ การดำเนินการบางอย่างจะดำเนินการต่อการวนซ้ำ ในขณะที่บางรายการดำเนินการโดยไดรเวอร์ในทุกขั้นตอน ยกตัวอย่างเช่นตัวแทนของ train ฟังก์ชั่นที่เรียกว่าเป็นเพียงหนึ่งครั้งต่อการทำซ้ำ ข้อแลกเปลี่ยนคือถ้าเราฝึกบ่อยขึ้น นโยบายของเราก็ "สดกว่า" ในทางกลับกัน การฝึกอบรมเป็นกลุ่มใหญ่อาจใช้เวลาอย่างมีประสิทธิภาพมากขึ้น
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
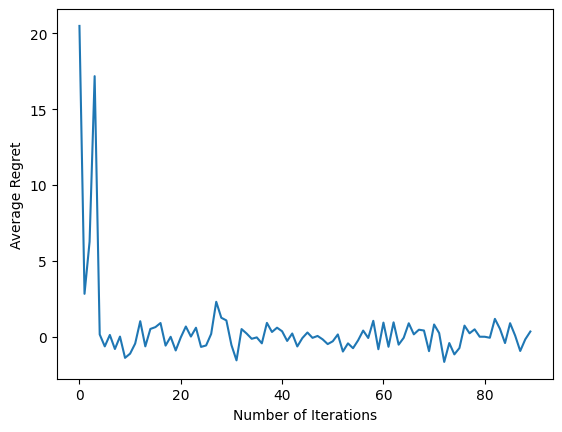
หลังจากรันข้อมูลโค้ดล่าสุด แผนภาพผลลัพธ์ (หวังว่า) แสดงว่าความเสียใจโดยเฉลี่ยกำลังลดลงเมื่อตัวแทนได้รับการฝึกอบรม และนโยบายจะดีขึ้นในการค้นหาว่าการดำเนินการที่ถูกต้องคืออะไร เมื่อพิจารณาจากการสังเกต
อะไรต่อไป?
หากต้องการดูตัวอย่างการใช้งานเพิ่มเติมโปรดดู โจร / ตัวแทน / ตัวอย่าง ไดเรกทอรีที่มีตัวอย่างพร้อมต่อการทำงานที่แตกต่างกันสำหรับตัวแทนและสภาพแวดล้อม
ไลบรารี TF-Agents ยังสามารถจัดการกับ Multi-Armed Bandits ด้วยคุณสมบัติต่อแขน ไปสิ้นสุดที่เราจะเรียกผู้อ่านที่จะต่อแขนโจร กวดวิชา