
|
|
|
 View source on GitHub View source on GitHub
|
|
This tutorial provides examples of how to use CSV data with TensorFlow.
There are two main parts to this:
- Loading the data off disk
- Pre-processing it into a form suitable for training.
This tutorial focuses on the loading, and gives some quick examples of preprocessing. To learn more about the preprocessing aspect, check out the Working with preprocessing layers guide and the Classify structured data using Keras preprocessing layers tutorial.
Setup
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
2024-08-16 07:14:23.551186: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-08-16 07:14:23.572583: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-08-16 07:14:23.579075: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
In memory data
For any small CSV dataset the simplest way to train a TensorFlow model on it is to load it into memory as a pandas DataFrame or a NumPy array.
A relatively simple example is the abalone dataset.
- The dataset is small.
- All the input features are limited-range floating point values.
Here is how to download the data into a DataFrame:
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
The dataset contains a set of measurements of abalone, a type of sea snail.

“Abalone shell” (by Nicki Dugan Pogue, CC BY-SA 2.0)
The nominal task for this dataset is to predict the age from the other measurements, so separate the features and labels for training:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
For this dataset you will treat all features identically. Pack the features into a single NumPy array.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Next make a regression model predict the age. Since there is only a single input tensor, a tf.keras.Sequential model is sufficient here.
abalone_model = tf.keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
abalone_model.compile(loss = tf.keras.losses.MeanSquaredError(),
optimizer = tf.keras.optimizers.Adam())
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1723792465.996743 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.000553 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.003815 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.007504 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.019051 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.022520 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.025442 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.028861 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.032242 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.035760 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.038693 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792466.042130 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.267390 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.269524 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.271597 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.273646 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.275655 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.277618 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.279574 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.281561 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.283463 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.285432 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.287397 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.289455 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.328726 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.330789 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.332799 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.334808 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.336761 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.338745 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.340723 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.342691 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.344638 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.347233 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.349687 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723792467.352112 222190 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
To train that model, pass the features and labels to Model.fit:
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1723792468.428118 222359 service.cc:146] XLA service 0x7f100c01c790 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices: I0000 00:00:1723792468.428162 222359 service.cc:154] StreamExecutor device (0): Tesla T4, Compute Capability 7.5 I0000 00:00:1723792468.428167 222359 service.cc:154] StreamExecutor device (1): Tesla T4, Compute Capability 7.5 I0000 00:00:1723792468.428169 222359 service.cc:154] StreamExecutor device (2): Tesla T4, Compute Capability 7.5 I0000 00:00:1723792468.428172 222359 service.cc:154] StreamExecutor device (3): Tesla T4, Compute Capability 7.5 92/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 96.5295 I0000 00:00:1723792468.891864 222359 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 104/104 ━━━━━━━━━━━━━━━━━━━━ 2s 4ms/step - loss: 94.6642 Epoch 2/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 37.7894 Epoch 3/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 9.5372 Epoch 4/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 7.8776 Epoch 5/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 7.6655 Epoch 6/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 7.3812 Epoch 7/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 7.1331 Epoch 8/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 6.9013 Epoch 9/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 6.9626 Epoch 10/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 7.0985 <keras.src.callbacks.history.History at 0x7f11c4145370>
You have just seen the most basic way to train a model using CSV data. Next, you will learn how to apply preprocessing to normalize numeric columns.
Basic preprocessing
It's good practice to normalize the inputs to your model. The Keras preprocessing layers provide a convenient way to build this normalization into your model.
The tf.keras.layers.Normalization layer precomputes the mean and variance of each column, and uses these to normalize the data.
First, create the layer:
normalize = layers.Normalization()
Then, use the Normalization.adapt method to adapt the normalization layer to your data.
normalize.adapt(abalone_features)
Then, use the normalization layer in your model:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.keras.losses.MeanSquaredError(),
optimizer = tf.keras.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - loss: 86.0107 Epoch 2/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 41.7985 Epoch 3/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 30.1734 Epoch 4/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 22.2187 Epoch 5/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 13.0996 Epoch 6/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 7.8169 Epoch 7/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 7.1509 Epoch 8/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 6.4672 Epoch 9/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 5.9506 Epoch 10/10 104/104 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 5.8023 <keras.src.callbacks.history.History at 0x7f11b00c7eb0>
Mixed data types
In the previous sections, you worked with a dataset where all the features were limited-range floating point values. But not all datasets are limited to a single data type.
The "Titanic" dataset contains information about the passengers on the Titanic. The nominal task on this dataset is to predict who survived.

Image from Wikimedia
{kind=link}
The raw data can easily be loaded as a Pandas DataFrame, but is not immediately usable as input to a TensorFlow model.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
Because of the different data types and ranges, you can't simply stack the features into a NumPy array and pass it to a tf.keras.Sequential model. Each column needs to be handled individually.
As one option, you could preprocess your data offline (using any tool you like) to convert categorical columns to numeric columns, then pass the processed output to your TensorFlow model. The disadvantage to that approach is that if you save and export your model the preprocessing is not saved with it. The Keras preprocessing layers avoid this problem because they're part of the model.
In this example, you'll build a model that implements the preprocessing logic using Keras functional API. You could also do it by subclassing.
The functional API operates on "symbolic" tensors. Normal "eager" tensors have a value. In contrast these "symbolic" tensors do not. Instead they keep track of which operations are run on them, and build a representation of the calculation, that you can run later. Here's a quick example:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor shape=(None,), dtype=float32, sparse=False, name=keras_tensor_9>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(np.array([1])).numpy())
print(calc(np.array([2])).numpy())
[3.] [5.]
To build the preprocessing model, start by building a set of symbolic tf.keras.Input objects, matching the names and data-types of the CSV columns.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor shape=(None, 1), dtype=string, sparse=False, name=sex>,
'age': <KerasTensor shape=(None, 1), dtype=float32, sparse=False, name=age>,
'n_siblings_spouses': <KerasTensor shape=(None, 1), dtype=float32, sparse=False, name=n_siblings_spouses>,
'parch': <KerasTensor shape=(None, 1), dtype=float32, sparse=False, name=parch>,
'fare': <KerasTensor shape=(None, 1), dtype=float32, sparse=False, name=fare>,
'class': <KerasTensor shape=(None, 1), dtype=string, sparse=False, name=class>,
'deck': <KerasTensor shape=(None, 1), dtype=string, sparse=False, name=deck>,
'embark_town': <KerasTensor shape=(None, 1), dtype=string, sparse=False, name=embark_town>,
'alone': <KerasTensor shape=(None, 1), dtype=string, sparse=False, name=alone>}
The first step in your preprocessing logic is to concatenate the numeric inputs together, and run them through a normalization layer:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor shape=(None, 4), dtype=float32, sparse=False, name=keras_tensor_11>
Collect all the symbolic preprocessing results, to concatenate them later:
preprocessed_inputs = [all_numeric_inputs]
For the string inputs use the tf.keras.layers.StringLookup function to map from strings to integer indices in a vocabulary. Next, use tf.keras.layers.CategoryEncoding to convert the indexes into float32 data appropriate for the model.
The default settings for the tf.keras.layers.CategoryEncoding layer create a one-hot vector for each input. A tf.keras.layers.Embedding would also work. Check out the Working with preprocessing layers guide and the Classify structured data using Keras preprocessing layers tutorial for more on this topic.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(num_tokens=lookup.vocabulary_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
With the collection of inputs and preprocessed_inputs, you can concatenate all the preprocessed inputs together, and build a model that handles the preprocessing:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
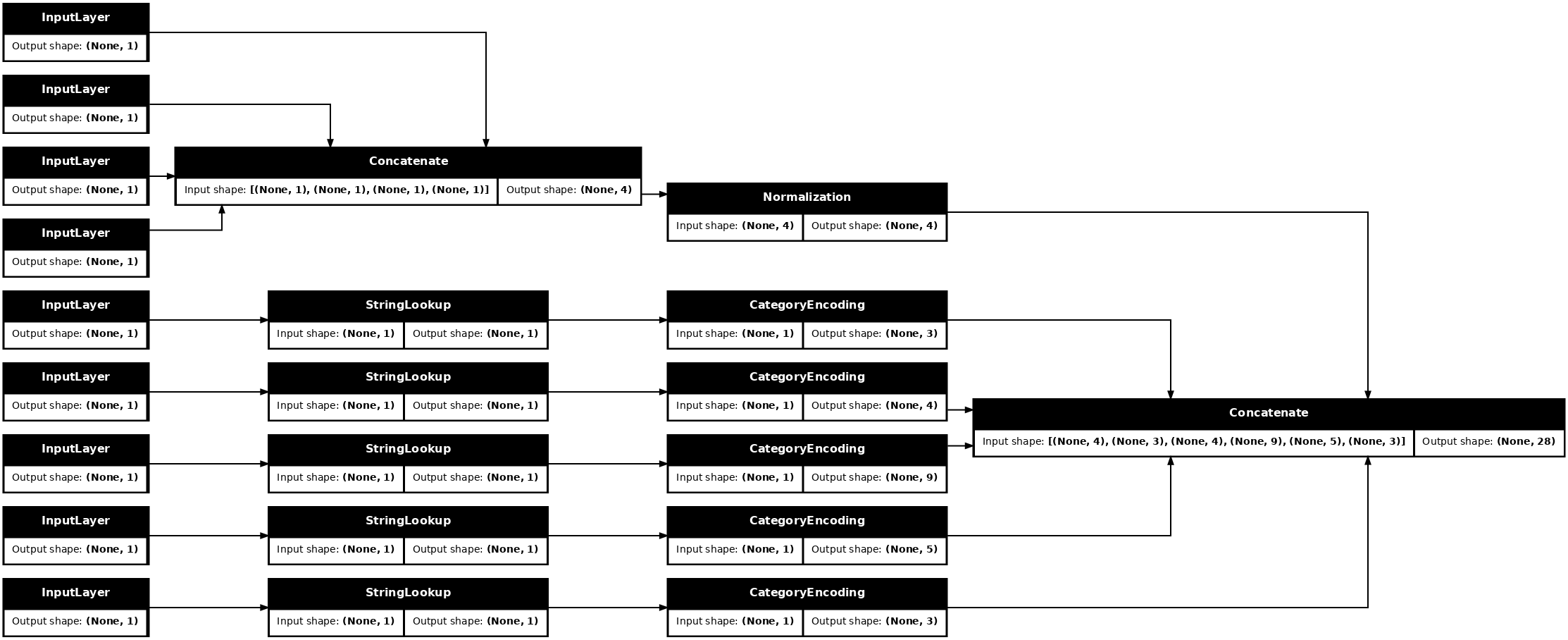
This model just contains the input preprocessing. You can run it to see what it does to your data. Keras models don't automatically convert pandas DataFrames because it's not clear if it should be converted to one tensor or to a dictionary of tensors. So, convert it to a dictionary of tensors:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Slice out the first training example and pass it to this preprocessing model, you see the numeric features and string one-hots all concatenated together:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Now, build the model on top of this:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
When you train the model, pass the dictionary of features as x, and the label as y.
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 2s 3ms/step - loss: 0.6818 Epoch 2/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.5930 Epoch 3/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.5349 Epoch 4/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4976 Epoch 5/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4973 Epoch 6/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4514 Epoch 7/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4692 Epoch 8/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4024 Epoch 9/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4243 Epoch 10/10 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.3980 <keras.src.callbacks.history.History at 0x7f12f1f79a00>
Since the preprocessing is part of the model, you can save the model and reload it somewhere else and get identical results:
titanic_model.save('test.keras')
reloaded = tf.keras.models.load_model('test.keras')
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.882]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.882]], shape=(1, 1), dtype=float32)
Using tf.data
In the previous section you relied on the model's built-in data shuffling and batching while training the model.
If you need more control over the input data pipeline or need to use data that doesn't easily fit into memory: use tf.data.
For more examples, refer to the tf.data: Build TensorFlow input pipelines guide.
On in memory data
As a first example of applying tf.data to CSV data, consider the following code to manually slice up the dictionary of features from the previous section. For each index, it takes that index for each feature:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Run this and print the first example:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
The most basic tf.data.Dataset in memory data loader is the Dataset.from_tensor_slices constructor. This returns a tf.data.Dataset that implements a generalized version of the above slices function, in TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
You can iterate over a tf.data.Dataset like any other python iterable:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
The from_tensor_slices function can handle any structure of nested dictionaries or tuples. The following code makes a dataset of (features_dict, labels) pairs:
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
To train a model using this Dataset, you'll need to at least shuffle and batch the data.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Instead of passing features and labels to Model.fit, you pass the dataset:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.3885 Epoch 2/5 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4162 Epoch 3/5 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.4269 Epoch 4/5 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.3933 Epoch 5/5 20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 0.3703 <keras.src.callbacks.history.History at 0x7f12f1e26f70>
From a single file
So far this tutorial has worked with in-memory data. tf.data is a highly scalable toolkit for building data pipelines, and provides a few functions for loading CSV files.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 30874/30874 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Now read the CSV data from the file and create a tf.data.Dataset.
(For the full documentation, see tf.data.experimental.make_csv_dataset)
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/data/experimental/ops/readers.py:572: ignore_errors (from tensorflow.python.data.experimental.ops.error_ops) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.ignore_errors` instead.
This function includes many convenient features, so the data is easy to work with. This includes:
- Using the column headers as dictionary keys.
- Automatically determining the type of each column.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'male' b'male' b'female'] age : [28. 28. 48. 61. 28.] n_siblings_spouses : [0 0 0 0 1] parch : [0 0 0 0 0] fare : [ 7.75 7.896 26.55 32.321 51.862] class : [b'Third' b'Third' b'First' b'First' b'First'] deck : [b'unknown' b'unknown' b'E' b'D' b'D'] embark_town : [b'Queenstown' b'Southampton' b'Southampton' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'y' b'n'] label : [0 0 1 0 1]
It can also decompress the data on the fly. Here's a gzipped CSV file containing the metro interstate traffic dataset.

Image from Wikimedia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 401408/Unknown 2s 5us/step
Set the compression_type argument to read directly from the compressed file:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [249.51 288.47 254.48 275.54 274.24] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [88 44 1 90 20] weather_main : [b'Clouds' b'Clouds' b'Clear' b'Mist' b'Clouds'] weather_description : [b'overcast clouds' b'scattered clouds' b'sky is clear' b'mist' b'few clouds'] date_time : [b'2013-02-03 03:00:00' b'2013-08-07 08:00:00' b'2013-01-01 23:00:00' b'2013-01-12 11:00:00' b'2012-10-30 01:00:00'] label : [ 338 5990 845 4017 393]
Caching
There is some overhead to parsing the CSV data. For small models this can be the bottleneck in training.
Depending on your use case, it may be a good idea to use Dataset.cache or tf.data.Dataset.snapshot, so that the CSV data is only parsed on the first epoch.
The main difference between the cache and snapshot methods is that cache files can only be used by the TensorFlow process that created them, but snapshot files can be read by other processes.
For example, iterating over the traffic_volume_csv_gz_ds 20 times may take around 15 seconds without caching, or about two seconds with caching.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 12.9 s, sys: 2.09 s, total: 15 s Wall time: 9.41 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.83 s, sys: 197 ms, total: 2.03 s Wall time: 1.73 s
%%time
snapshotting = traffic_volume_csv_gz_ds.snapshot('titanic.tfsnap').shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 2.71 s, sys: 686 ms, total: 3.39 s Wall time: 2.08 s
If your data loading is slowed by loading CSV files, and Dataset.cache and tf.data.Dataset.snapshot are insufficient for your use case, consider re-encoding your data into a more streamlined format.
Multiple files
All the examples so far in this section could easily be done without tf.data. One place where tf.data can really simplify things is when dealing with collections of files.
For example, the character font images dataset is distributed as a collection of csv files, one per font.

Image by Willi Heidelbach from Pixabay
Download the dataset, and review the files inside:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160301056/Unknown 1096s 7us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
When dealing with a bunch of files, you can pass a glob-style file_pattern to the tf.data.experimental.make_csv_dataset function. The order of the files is shuffled each iteration.
Use the num_parallel_reads argument to set how many files are read in parallel and interleaved together.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
These CSV files have the images flattened out into a single row. The column names are formatted r{row}c{column}. Here's the first batch:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'CONSOLAS' b'BITSTREAMVERA' b'CORBEL' b'BRUSH' b'ROMAN' b'KUNSTLER' b'OCRA' b'BITSTREAMVERA' b'BITSTREAMVERA' b'TW'] fontVariant : [b'CONSOLAS' b'scanned' b'CORBEL' b'BRUSH SCRIPT MT' b'ROMANT' b'KUNSTLER SCRIPT' b'scanned' b'scanned' b'scanned' b'TW CEN MT CONDENSED EXTRA BOLD'] m_label : [9520 57 733 305 88 173 84 79 82 8212] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 0 0 0 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [57 0 35 57 40 67 0 0 0 60] m_left : [20 0 22 20 23 21 0 0 0 20] originalH : [42 20 11 23 50 1 14 21 20 8] originalW : [37 69 19 16 42 9 8 55 32 67] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [255 1 1 1 107 255 255 1 1 255] r0c1 : [255 1 1 1 209 255 255 1 1 255] r0c2 : [255 1 1 1 255 255 255 1 1 255] r0c3 : [255 1 1 1 255 255 255 5 1 255] ... [total: 412 features]
Optional: Packing fields
You probably don't want to work with each pixel in separate columns like this. Before trying to use this dataset be sure to pack the pixels into an image-tensor.
Here is code that parses the column names to build images for each example:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Apply that function to each batch in the dataset:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Plot the resulting images:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/IPython/core/events.py:82: UserWarning: Glyph 65045 (\N{PRESENTATION FORM FOR VERTICAL EXCLAMATION MARK}) missing from font(s) DejaVu Sans.
func(*args, **kwargs)
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/IPython/core/pylabtools.py:152: UserWarning: Glyph 65045 (\N{PRESENTATION FORM FOR VERTICAL EXCLAMATION MARK}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)

Lower level functions
So far this tutorial has focused on the highest-level utilities for reading csv data. There are two other APIs that may be helpful for advanced users if your use-case doesn't fit the basic patterns.
tf.io.decode_csv: a function for parsing lines of text into a list of CSV column tensors.tf.data.experimental.CsvDataset: a lower-level CSV dataset constructor.
This section recreates functionality provided by tf.data.experimental.make_csv_dataset, to demonstrate how this lower-level functionality can be used.
tf.io.decode_csv
This function decodes a string, or list of strings into a list of columns.
Unlike tf.data.experimental.make_csv_dataset this function does not try to guess column data-types. You specify the column types by providing a list of record_defaults containing a value of the correct type, for each column.
To read the Titanic data as strings using tf.io.decode_csv you would say:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
To parse them with their actual types, create a list of record_defaults of the corresponding types:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
The tf.data.experimental.CsvDataset class provides a minimal CSV Dataset interface without the convenience features of the tf.data.experimental.make_csv_dataset function: column header parsing, column type-inference, automatic shuffling, file interleaving.
This constructor uses record_defaults the same way as tf.io.decode_csv:
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
The above code is basically equivalent to:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Multiple files
To parse the fonts dataset using tf.data.experimental.CsvDataset, you first need to determine the column types for the record_defaults. Start by inspecting the first row of one file:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Only the first two fields are strings, the rest are integers or floats, and you can get the total number of features by counting the commas:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
The tf.data.experimental.CsvDataset constructor can take a list of input files, but reads them sequentially. The first file in the list of CSVs is AGENCY.csv:
font_csvs[0]
'fonts/AGENCY.csv'
So, when you pass the list of files to CsvDataset, the records from AGENCY.csv are read first:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
To interleave multiple files, use Dataset.interleave.
Here's an initial dataset that contains the CSV file names:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
This shuffles the file names each epoch:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/YI BAITI.csv'
b'fonts/HAETTENSCHWEILER.csv'
b'fonts/SKETCHFLOW.csv'
b'fonts/JUICE.csv'
b'fonts/CONSOLAS.csv'
...
Epoch 2:
b'fonts/PHAGSPA.csv'
b'fonts/GILL.csv'
b'fonts/ROCKWELL.csv'
b'fonts/JUICE.csv'
b'fonts/SUPERFRENCH.csv'
...
The interleave method takes a map_func that creates a child-Dataset for each element of the parent-Dataset.
Here, you want to create a tf.data.experimental.CsvDataset from each element of the dataset of files:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
The Dataset returned by interleave returns elements by cycling over a number of the child-Datasets. Note, below, how the dataset cycles over cycle_length=3 three font files:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(int(row[2].numpy())))
pd.DataFrame(fonts_dict)
Performance
Earlier, it was noted that tf.io.decode_csv is more efficient when run on a batch of strings.
It is possible to take advantage of this fact, when using large batch sizes, to improve CSV loading performance (but try caching first).
With the built-in loader 20, 2048-example batches take about 17s.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 48.7 s, sys: 3.96 s, total: 52.7 s Wall time: 20.4 s
Passing batches of text lines todecode_csv runs faster, in about 5s:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 3.93 s, sys: 125 ms, total: 4.06 s Wall time: 931 ms
For another example of increasing CSV performance by using large batches, refer to the Overfit and underfit tutorial.
This sort of approach may work, but consider other options like Dataset.cache and tf.data.Dataset.snapshot, or re-encoding your data into a more streamlined format.