
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub |
Tài liệu API: tf.RaggedTensor tf.ragged
Thành lập
import math
import tensorflow as tf
Tổng quat
Dữ liệu của bạn có nhiều hình dạng; căng thẳng của bạn cũng nên. Ragged tensors là TensorFlow tương đương với các danh sách có độ dài thay đổi được lồng vào nhau. Chúng giúp dễ dàng lưu trữ và xử lý dữ liệu có hình dạng không đồng nhất, bao gồm:
- Các tính năng có độ dài thay đổi, chẳng hạn như tập hợp các diễn viên trong phim.
- Hàng loạt đầu vào tuần tự có độ dài thay đổi, chẳng hạn như câu hoặc video clip.
- Đầu vào phân cấp, chẳng hạn như tài liệu văn bản được chia nhỏ thành các phần, đoạn văn, câu và từ.
- Các trường riêng lẻ trong đầu vào có cấu trúc, chẳng hạn như bộ đệm giao thức.
Bạn có thể làm gì với một cái máy căng rách
Các tensor có Ragged được hỗ trợ bởi hơn một trăm hoạt động TensorFlow, bao gồm các phép toán (chẳng hạn như tf.add và tf.reduce_mean ), các hoạt động mảng (chẳng hạn như tf.concat và tf.tile ), các hoạt động thao tác chuỗi (chẳng hạn như tf.substr ), kiểm soát các hoạt động luồng (chẳng hạn như tf.while_loop và tf.map_fn ), và nhiều hoạt động khác:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Ngoài ra còn có một số phương pháp và hoạt động dành riêng cho tensors rách nát, bao gồm phương pháp nhà máy, phương pháp chuyển đổi và hoạt động lập bản đồ giá trị. Để biết danh sách các hoạt động được hỗ trợ, hãy xem tài liệu gói tf.ragged .
Ragged tensors được hỗ trợ bởi nhiều API TensorFlow, bao gồm Keras , Datasets , tf. functions, SavedModels và tf.Example . Để biết thêm thông tin, hãy xem phần về API TensorFlow bên dưới.
Như với các tensor bình thường, bạn có thể sử dụng lập chỉ mục kiểu Python để truy cập các lát cụ thể của tensor bị rách. Để biết thêm thông tin, hãy tham khảo phần Lập chỉ mục bên dưới.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
Và cũng giống như các tensor thông thường, bạn có thể sử dụng toán tử so sánh và số học Python để thực hiện các phép toán theo từng phần tử. Để biết thêm thông tin, hãy kiểm tra phần Toán tử bị quá tải bên dưới.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Nếu bạn cần thực hiện chuyển đổi theo từng phần tử đối với các giá trị của RaggedTensor , bạn có thể sử dụng tf.ragged.map_flat_values , hàm này nhận một hàm cộng với một hoặc nhiều đối số và áp dụng hàm để biến đổi các giá trị của RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Có thể chuyển đổi các tensors Ragged thành các list Python lồng nhau và array NumPy:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Cấu tạo một tensor rách nát
Cách đơn giản nhất để tạo một tensor rách rưới là sử dụng tf.ragged.constant , tạo RaggedTensor tương ứng với một list Python lồng nhau nhất định hoặc array NumPy:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Các tensor có răng cưa cũng có thể được xây dựng bằng cách ghép nối các tensor giá trị phẳng với các tensor phân vùng hàng cho biết cách các giá trị đó nên được chia thành các hàng, sử dụng các phương pháp phân loại của nhà máy như tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths và tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
Nếu bạn biết mỗi giá trị thuộc về hàng nào, thì bạn có thể tạo RaggedTensor bằng cách sử dụng tensor phân vùng hàng value_rowids :
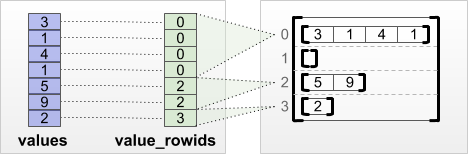
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Nếu bạn biết mỗi hàng dài bao nhiêu thì bạn có thể sử dụng tensor phân vùng hàng row_lengths :
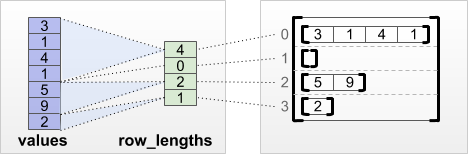
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Nếu bạn biết chỉ mục nơi mỗi hàng bắt đầu và kết thúc, thì bạn có thể sử dụng row_splits phân vùng hàng:
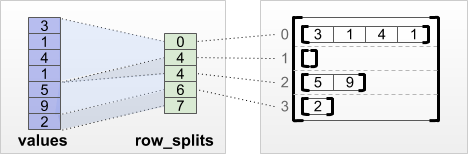
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Xem tài liệu lớp tf.RaggedTensor để biết danh sách đầy đủ các phương thức gốc.
Những gì bạn có thể lưu trữ trong một chiếc máy kéo rách nát
Như với các Tensor thông thường, tất cả các giá trị trong RaggedTensor phải có cùng kiểu; và tất cả các giá trị phải ở cùng độ sâu lồng nhau ( thứ hạng của tensor):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
Trường hợp sử dụng ví dụ
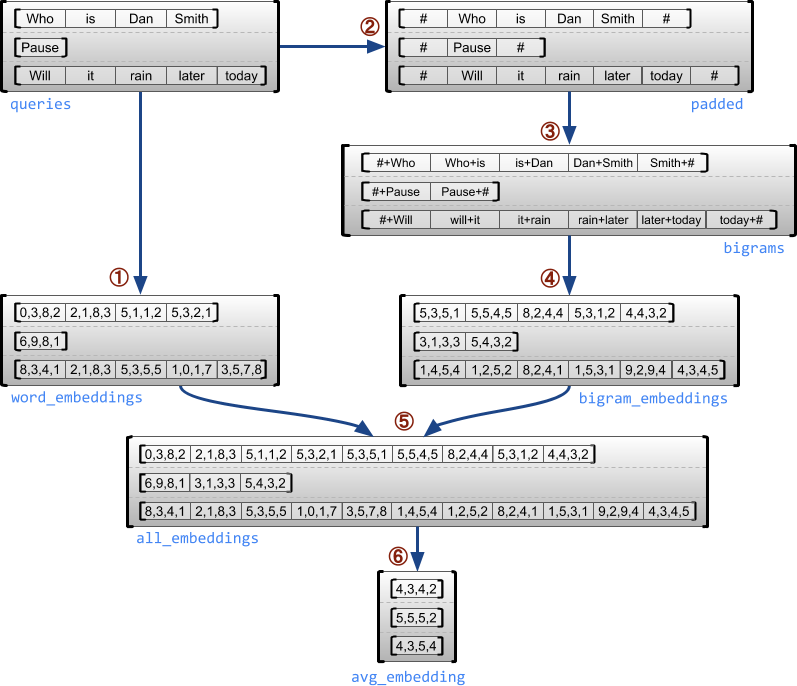
Ví dụ sau minh họa cách sử dụng RaggedTensor s để xây dựng và kết hợp nhúng unigram và bigram cho một loạt các truy vấn có độ dài thay đổi, sử dụng các dấu đặc biệt cho đầu và cuối mỗi câu. Để biết thêm chi tiết về các hoạt động được sử dụng trong ví dụ này, hãy kiểm tra tài liệu gói tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Kích thước có răng cưa và đồng nhất
Kích thước rách rưới là thứ nguyên mà các lát cắt có thể có độ dài khác nhau. Ví dụ: kích thước bên trong (cột) của rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] bị lệch, vì cột cắt ( rt[0, :] , ..., rt[4, :] ) có độ dài khác nhau. Kích thước mà các lát cắt có cùng chiều dài được gọi là kích thước đồng nhất .
Kích thước ngoài cùng của một tensor rách nát luôn đồng nhất, vì nó bao gồm một lát duy nhất (và do đó, không có khả năng xảy ra các chiều dài lát cắt khác nhau). Các kích thước còn lại có thể bị rách hoặc đồng nhất. Ví dụ: bạn có thể lưu trữ các nhúng từ cho mỗi từ trong một loạt câu bằng cách sử dụng một tensor rách có hình dạng [num_sentences, (num_words), embedding_size] , trong đó các dấu ngoặc đơn xung quanh (num_words) cho biết rằng thứ nguyên bị rách.
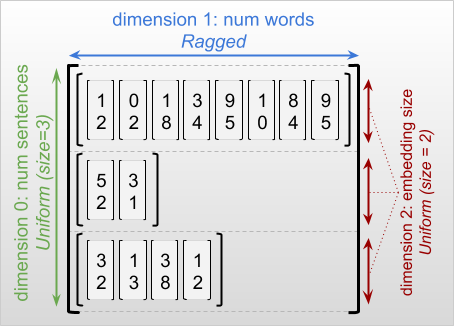
Các thanh căng răng cưa có thể có nhiều kích thước rách. Ví dụ: bạn có thể lưu trữ một loạt tài liệu văn bản có cấu trúc bằng cách sử dụng một tensor có hình dạng [num_documents, (num_paragraphs), (num_sentences), (num_words)] (trong đó dấu ngoặc đơn lại được sử dụng để biểu thị các kích thước bị rách).
Như với tf.Tensor , thứ hạng của một tensor rách rưới là tổng số kích thước của nó (bao gồm cả kích thước rách rưới và đồng nhất). Một tensor bị rách tiềm ẩn là một giá trị có thể là tf.Tensor hoặc tf.RaggedTensor .
Khi mô tả hình dạng của RaggedTensor, các kích thước rách rưới được chỉ ra theo quy ước bằng cách đặt chúng trong dấu ngoặc đơn. Ví dụ: như bạn đã thấy ở trên, hình dạng của 3D RaggedTensor lưu trữ các nhúng từ cho mỗi từ trong một loạt câu có thể được viết dưới dạng [num_sentences, (num_words), embedding_size] .
Thuộc tính RaggedTensor.shape trả về một tf.TensorShape cho một tensor rách nát trong đó kích thước rách rưới có kích thước None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
Phương thức tf.RaggedTensor.bounding_shape có thể được sử dụng để tìm một hình dạng giới hạn chặt chẽ cho một RaggedTensor nhất định:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Ragged vs thưa thớt
Một tenxơ rách rưới không nên được coi là một loại tenxơ thưa. Đặc biệt, tenxơ thưa thớt là mã hóa hiệu quả cho tf.Tensor mô hình hóa cùng một dữ liệu ở định dạng nhỏ gọn; nhưng tensor rách rưới là một phần mở rộng của tf.Tensor mô hình hóa một lớp dữ liệu mở rộng. Sự khác biệt này là rất quan trọng khi xác định các hoạt động:
- Áp dụng op cho tensor thưa thớt hoặc dày đặc phải luôn cho kết quả giống nhau.
- Áp dụng op cho một tensor bị rách hoặc thưa thớt có thể cho các kết quả khác nhau.
Như một ví dụ minh họa, hãy xem xét cách các phép toán mảng như concat , stack và tile được xác định cho các tensors rách rưới và thưa thớt. Nối các hàng căng đứt nối với mỗi hàng để tạo thành một hàng duy nhất với chiều dài kết hợp:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Tuy nhiên, việc nối các tenxơ thưa thớt tương đương với việc nối các tenxơ dày đặc tương ứng, như được minh họa trong ví dụ sau (trong đó Ø chỉ ra các giá trị bị thiếu):
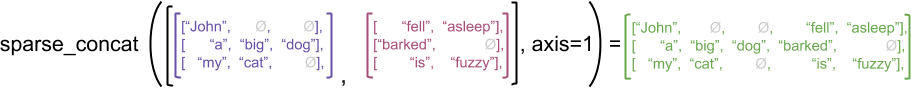
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Đối với một ví dụ khác về lý do tại sao sự khác biệt này lại quan trọng, hãy xem xét định nghĩa “giá trị trung bình của mỗi hàng” cho một op chẳng hạn như tf.reduce_mean . Đối với một tensor rách rưới, giá trị trung bình cho một hàng là tổng các giá trị của hàng chia cho chiều rộng của hàng. Nhưng đối với tensor thưa thớt, giá trị trung bình cho một hàng là tổng giá trị của hàng chia cho chiều rộng tổng thể của tensor thưa thớt (lớn hơn hoặc bằng chiều rộng của hàng dài nhất).
API TensorFlow
Keras
tf.keras là API cấp cao của TensorFlow để xây dựng và đào tạo các mô hình học sâu. Ragged tensors có thể được chuyển làm đầu vào cho mô hình Keras bằng cách đặt ragged=True trên tf.keras.Input hoặc tf.keras.layers.InputLayer . Các bộ căng răng cưa cũng có thể được truyền qua giữa các lớp Keras và được các mô hình Keras trả lại. Ví dụ sau đây cho thấy một mô hình LSTM đồ chơi được huấn luyện bằng cách sử dụng các dây căng rách.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Example
tf.Example là một mã hóa protobuf tiêu chuẩn cho dữ liệu TensorFlow. Dữ liệu được mã hóa bằng tf.Example . Ví dụ s thường bao gồm các tính năng có độ dài thay đổi. Ví dụ: đoạn mã sau xác định một lô gồm bốn thông báo tf.Example Ví dụ: với các độ dài tính năng khác nhau:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Bạn có thể phân tích cú pháp dữ liệu được mã hóa này bằng cách sử dụng tf.io.parse_example , lấy một tensor các chuỗi được tuần tự hoá và một từ điển đặc tả tính năng và trả về tên tính năng ánh xạ từ điển cho tensor. Để đọc các đối tượng có độ dài thay đổi thành các hàm căng đứt, bạn chỉ cần sử dụng tf.io.RaggedFeature trong từ điển đặc điểm kỹ thuật:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature cũng có thể được sử dụng để đọc các đối tượng địa lý có nhiều kích thước khác nhau. Để biết chi tiết, hãy tham khảo tài liệu API .
Bộ dữ liệu
tf.data là một API cho phép bạn xây dựng các đường ống đầu vào phức tạp từ các mảnh đơn giản, có thể tái sử dụng. Cấu trúc dữ liệu cốt lõi của nó là tf.data.Dataset , đại diện cho một chuỗi các phần tử, trong đó mỗi phần tử bao gồm một hoặc nhiều thành phần.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Xây dựng tập dữ liệu với bộ căng cứng
Các tập dữ liệu có thể được xây dựng từ các tensor rách nát bằng cách sử dụng các phương pháp tương tự được sử dụng để xây dựng chúng từ các array tf.Tensor hoặc NumPy, chẳng hạn như Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Ghép và hủy ghép các Tập dữ liệu với các bộ căng cứng
Các tập dữ liệu với các tensors rách rưới có thể được phân lô (kết hợp n phần tử liên tiếp thành một phần tử duy nhất) bằng cách sử dụng phương thức Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Ngược lại, tập dữ liệu theo lô có thể được chuyển đổi thành tập dữ liệu phẳng bằng Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Lô tập dữ liệu với bộ căng thẳng có độ dài thay đổi được
Nếu bạn có Tập dữ liệu chứa các tensor không bị rách và độ dài của tensor khác nhau giữa các phần tử, thì bạn có thể gộp các tensor không bị rách đó thành các tensor bị rách bằng cách áp dụng biến đổi dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Biến đổi tập dữ liệu với bộ căng đứt
Bạn cũng có thể tạo hoặc chuyển đổi các tensor bị rách trong Datasets bằng Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf. chức năng
tf. functions là một trình trang trí tính toán trước các đồ thị TensorFlow cho các hàm Python, có thể cải thiện đáng kể hiệu suất của mã TensorFlow của bạn. Máy căng có răng cưa có thể được sử dụng trong suốt với các chức năng được trang trí theo @tf.function . Chức năng. Ví dụ: hàm sau hoạt động với cả bộ căng có rãnh và không rách:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Nếu bạn muốn chỉ định rõ ràng input_signature cho tf. tf.function , thì bạn có thể làm như vậy bằng cách sử dụng tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Chức năng bê tông
Các hàm cụ thể đóng gói các đồ thị theo dấu vết riêng lẻ được xây dựng bởi tf.function . function. Máy căng răng cưa có thể được sử dụng trong suốt với các chức năng cụ thể.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Đã lưu
SavedModel là một chương trình TensorFlow được tuần tự hóa, bao gồm cả trọng số và tính toán. Nó có thể được xây dựng từ một mô hình Keras hoặc từ một mô hình tùy chỉnh. Trong cả hai trường hợp, các tensors rách nát có thể được sử dụng một cách minh bạch với các chức năng và phương pháp được xác định bởi SavedModel.
Ví dụ: lưu một mô hình Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Ví dụ: lưu một mô hình tùy chỉnh
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Các nhà khai thác quá tải
Lớp RaggedTensor nạp chồng các toán tử so sánh và số học Python chuẩn, giúp dễ dàng thực hiện phép toán theo từng phần tử cơ bản:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Vì các toán tử được nạp chồng thực hiện các phép tính theo từng phần tử, các đầu vào cho tất cả các phép toán nhị phân phải có cùng hình dạng hoặc có thể quảng bá cho cùng một hình dạng. Trong trường hợp phát sóng đơn giản nhất, một đại lượng vô hướng đơn được kết hợp theo từng phần tử với mỗi giá trị trong một tensor rách rưới:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Để thảo luận về các trường hợp nâng cao hơn, hãy kiểm tra phần Phát sóng .
Các tenxơ có răng cưa làm quá tải cùng một tập hợp các toán tử như các Tensor thông thường: các toán tử một ngôi - , ~ , và abs() ; và các toán tử nhị phân + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > và >= .
Lập chỉ mục
Ragged tensors hỗ trợ lập chỉ mục kiểu Python, bao gồm lập chỉ mục đa chiều và cắt. Các ví dụ sau đây cho thấy lập chỉ mục tensor rách bằng 2D và 3D.
Các ví dụ về lập chỉ mục: tensor rách nát 2D
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Các ví dụ về lập chỉ mục: tensor rách nát 3D
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor s hỗ trợ lập chỉ mục và cắt lát nhiều chiều với một hạn chế: không được phép lập chỉ mục vào một thứ nguyên rách nát. Trường hợp này có vấn đề vì giá trị được chỉ định có thể tồn tại trong một số hàng nhưng không tồn tại trong các hàng khác. Trong những trường hợp như vậy, không rõ bạn có nên (1) tăng IndexError ; (2) sử dụng giá trị mặc định; hoặc (3) bỏ qua giá trị đó và trả về một tensor có ít hàng hơn bạn bắt đầu. Tuân theo các nguyên tắc hướng dẫn của Python ("Đối mặt với sự mơ hồ, từ chối sự cám dỗ để đoán"), thao tác này hiện không được phép.
Chuyển đổi kiểu căng
Lớp RaggedTensor định nghĩa các phương thức có thể được sử dụng để chuyển đổi giữa RaggedTensor s và tf.Tensor s hoặc tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Đánh giá bộ căng bị rách
Để truy cập các giá trị trong một tensor rách rưới, bạn có thể:
- Sử dụng
tf.RaggedTensor.to_listđể chuyển đổi tensor rách rưới thành một danh sách Python lồng nhau. - Sử dụng
tf.RaggedTensor.numpyđể chuyển đổi tensor bị rách thành mảng NumPy có các giá trị là các mảng NumPy lồng nhau. - Phân rã tensor bị rách thành các thành phần của nó, sử dụng các thuộc tính
tf.RaggedTensor.valuesvàtf.RaggedTensor.row_splitshoặc các phương thức phân chia hàng nhưtf.RaggedTensor.row_lengthsvàtf.RaggedTensor.value_rowids. - Sử dụng lập chỉ mục Python để chọn các giá trị từ tensor bị rách.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Phát thanh truyền hình
Phát sóng là quá trình làm cho các tenxơ với các hình dạng khác nhau có hình dạng tương thích cho các hoạt động của từng phần tử. Để biết thêm thông tin cơ bản về phát sóng, hãy tham khảo:
Các bước cơ bản để phát hai đầu vào x và y để có hình dạng tương thích là:
Nếu
xvàykhông có cùng số kích thước, thì hãy thêm các kích thước bên ngoài (với kích thước 1) cho đến khi chúng giống nhau.Đối với mỗi kích thước trong đó
xvàycó các kích thước khác nhau:
- Nếu
xhoặcycó kích thước1trong kích thướcd, thì hãy lặp lại các giá trị của nó trên kích thướcdđể khớp với kích thước của đầu vào khác. - Nếu không, hãy nêu ra một ngoại lệ (
xvàykhông tương thích với quảng bá).
Trong đó kích thước của tenxơ theo một chiều thống nhất là một số đơn (kích thước của các lát cắt trên chiều đó); và kích thước của tensor trong một kích thước rách là một danh sách các chiều dài lát cắt (cho tất cả các lát cắt trên kích thước đó).
Các ví dụ về phát thanh truyền hình
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Dưới đây là một số ví dụ về hình dạng không phát sóng:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Mã hóa RaggedTensor
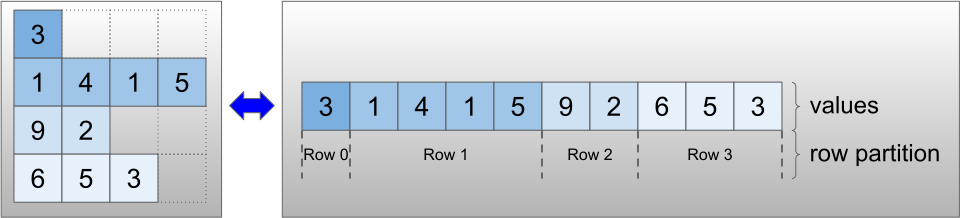
Ragged tensors được mã hóa bằng cách sử dụng lớp RaggedTensor . Bên trong, mỗi RaggedTensor bao gồm:
- Một
valuestensor, nối các hàng có độ dài thay đổi thành một danh sách phẳng. - Phân
row_partition, cho biết cách các giá trị được làm phẳng đó được chia thành các hàng.
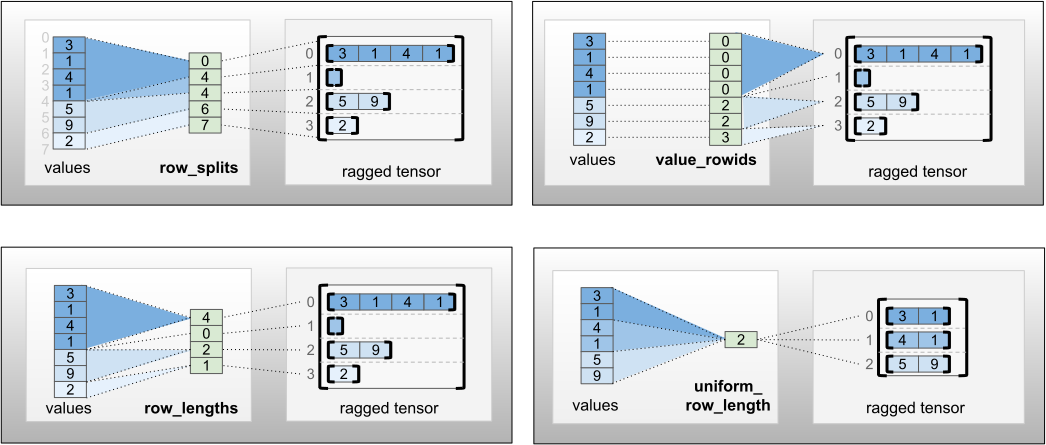
Phân row_partition có thể được lưu trữ bằng cách sử dụng bốn bảng mã khác nhau:
-
row_splitslà một vectơ số nguyên xác định các điểm phân tách giữa các hàng. -
value_rowidslà một vectơ số nguyên xác định chỉ số hàng cho mỗi giá trị. -
row_lengthslà một vectơ số nguyên xác định độ dài của mỗi hàng. -
uniform_row_lengthlà một đại lượng vô hướng số nguyên xác định một độ dài duy nhất cho tất cả các hàng.
Một nrows vô hướng số nguyên cũng có thể được bao gồm trong mã hóa row_partition để giải thích cho các hàng trống ở cuối với value_rowids hoặc các hàng trống với uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Việc lựa chọn mã hóa nào để sử dụng cho các phân vùng hàng được quản lý nội bộ bởi các bộ căng thẳng để cải thiện hiệu quả trong một số ngữ cảnh. Đặc biệt, một số ưu điểm và nhược điểm của các sơ đồ phân vùng theo hàng khác nhau là:
- Lập chỉ mục hiệu quả : Mã hóa
row_splitscho phép lập chỉ mục theo thời gian không đổi và cắt thành các phần tử căng thẳng. - Nối hiệu quả : Mã hóa
row_lengthshiệu quả hơn khi nối các tensor bị xé nhỏ, vì độ dài hàng không thay đổi khi hai tensor được nối với nhau. - Kích thước mã hóa nhỏ : Mã hóa
value_rowidshiệu quả hơn khi lưu trữ các tensor bị xé nhỏ có số lượng lớn các hàng trống, vì kích thước của tensor chỉ phụ thuộc vào tổng số giá trị. Mặt khác, các mã hóarow_splitsvàrow_lengthshiệu quả hơn khi lưu trữ các tensor bị xé nhỏ với các hàng dài hơn, vì chúng chỉ yêu cầu một giá trị vô hướng cho mỗi hàng. - Khả năng tương thích : Lược đồ
value_rowidskhớp với định dạng phân đoạn được sử dụng bởi các phép toán, chẳng hạn nhưtf.segment_sum. Lược đồrow_limitskhớp với định dạng được sử dụng bởi các hoạt động nhưtf.sequence_mask. - Kích thước đồng nhất : Như đã thảo luận bên dưới, mã hóa
uniform_row_lengthđược sử dụng để mã hóa các tenxơ có kích thước đồng nhất.
Nhiều kích thước rách rưới
Một tensor rách rưới với nhiều kích thước rách rưới được mã hóa bằng cách sử dụng RaggedTensor lồng nhau cho các values tensor. Mỗi RaggedTensor lồng vào nhau thêm một thứ nguyên rách nát.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
Hàm tf.RaggedTensor.from_nested_row_splits có thể được sử dụng để tạo RaggedTensor với nhiều kích thước bị rách trực tiếp bằng cách cung cấp danh sách các tensors row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Xếp hạng được đánh dấu và các giá trị cố định
Xếp hạng bị rách nát của tensor ragged là số lần các values cơ bản tensor đã được phân vùng (tức là độ sâu lồng nhau của các đối tượng RaggedTensor ). Các values trong cùng tensor được gọi là giá trị phẳng của nó. Trong ví dụ sau, các conversations có ragged_rank = 3 và flat_values của nó là Tensor 1D với 24 chuỗi:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Kích thước bên trong đồng nhất
Các tenxơ có răng cưa với kích thước bên trong đồng nhất được mã hóa bằng cách sử dụng tf.Tensor đa chiều cho các giá trị phẳng (tức là các values trong cùng).
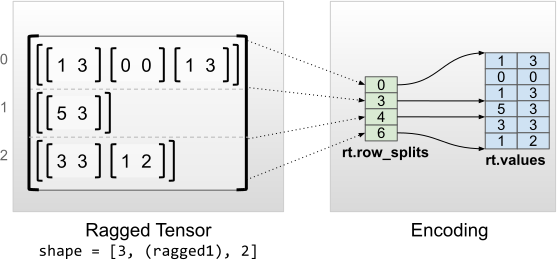
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Kích thước không bên trong đồng nhất
Các căng có răng cưa với các kích thước không bên trong đồng nhất được mã hóa bằng cách phân vùng các hàng với uniform_row_length .
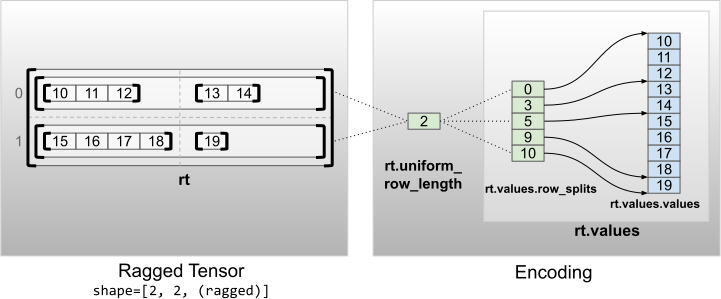
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2