
| | |  Lihat di GitHub Lihat di GitHub | | |
Buku catatan ini mengilustrasikan cara mengakses Encoder Kalimat Universal dan menggunakannya untuk tugas-tugas kesamaan kalimat dan klasifikasi kalimat.
Universal Sentence Encoder membuat mendapatkan penyematan tingkat kalimat semudah mencari penyematan untuk kata-kata individual secara historis. Penyematan kalimat kemudian dapat digunakan secara sepele untuk menghitung kesamaan makna tingkat kalimat serta untuk memungkinkan kinerja yang lebih baik pada tugas klasifikasi hilir menggunakan data pelatihan yang kurang diawasi.
Mempersiapkan
Bagian ini mengatur lingkungan untuk akses ke Universal Sentence Encoder di TF Hub dan memberikan contoh penerapan encoder ke kata, kalimat, dan paragraf.
%%capture
!pip3 install seaborn
Informasi lebih lanjut tentang menginstal Tensorflow dapat ditemukan di https://www.tensorflow.org/install/ .
Muat modul TF Hub Universal Sentence Encoder
from absl import logging
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import re
import seaborn as sns
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
print ("module %s loaded" % module_url)
def embed(input):
return model(input)
module https://tfhub.dev/google/universal-sentence-encoder/4 loaded
Hitung representasi untuk setiap pesan, yang menunjukkan berbagai panjang yang didukung.
word = "Elephant"
sentence = "I am a sentence for which I would like to get its embedding."
paragraph = (
"Universal Sentence Encoder embeddings also support short paragraphs. "
"There is no hard limit on how long the paragraph is. Roughly, the longer "
"the more 'diluted' the embedding will be.")
messages = [word, sentence, paragraph]
# Reduce logging output.
logging.set_verbosity(logging.ERROR)
message_embeddings = embed(messages)
for i, message_embedding in enumerate(np.array(message_embeddings).tolist()):
print("Message: {}".format(messages[i]))
print("Embedding size: {}".format(len(message_embedding)))
message_embedding_snippet = ", ".join(
(str(x) for x in message_embedding[:3]))
print("Embedding: [{}, ...]\n".format(message_embedding_snippet))
Message: Elephant Embedding size: 512 Embedding: [0.008344474248588085, 0.00048079612315632403, 0.06595245748758316, ...] Message: I am a sentence for which I would like to get its embedding. Embedding size: 512 Embedding: [0.05080860108137131, -0.016524313017725945, 0.015737781301140785, ...] Message: Universal Sentence Encoder embeddings also support short paragraphs. There is no hard limit on how long the paragraph is. Roughly, the longer the more 'diluted' the embedding will be. Embedding size: 512 Embedding: [-0.028332678601145744, -0.05586216226220131, -0.012941479682922363, ...]
Contoh Tugas Kesamaan Tekstual Semantik
Embeddings yang dihasilkan oleh Universal Sentence Encoder kira-kira dinormalisasi. Kesamaan semantik dari dua kalimat dapat dihitung secara sepele sebagai produk dalam dari pengkodean.
def plot_similarity(labels, features, rotation):
corr = np.inner(features, features)
sns.set(font_scale=1.2)
g = sns.heatmap(
corr,
xticklabels=labels,
yticklabels=labels,
vmin=0,
vmax=1,
cmap="YlOrRd")
g.set_xticklabels(labels, rotation=rotation)
g.set_title("Semantic Textual Similarity")
def run_and_plot(messages_):
message_embeddings_ = embed(messages_)
plot_similarity(messages_, message_embeddings_, 90)
Kesamaan Divisualisasikan
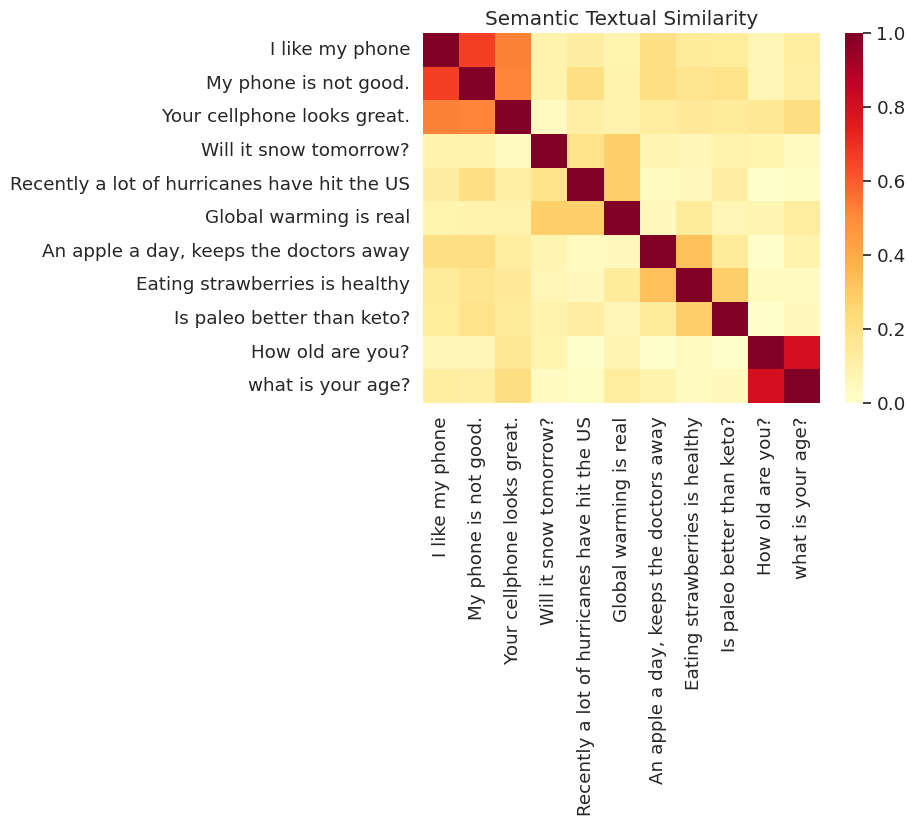
Di sini kami menunjukkan kesamaan dalam peta panas. Grafik akhir adalah matriks 9x9 di mana setiap entri [i, j] berwarna berdasarkan produk dalam dari pengkodean untuk kalimat i dan j .
messages = [
# Smartphones
"I like my phone",
"My phone is not good.",
"Your cellphone looks great.",
# Weather
"Will it snow tomorrow?",
"Recently a lot of hurricanes have hit the US",
"Global warming is real",
# Food and health
"An apple a day, keeps the doctors away",
"Eating strawberries is healthy",
"Is paleo better than keto?",
# Asking about age
"How old are you?",
"what is your age?",
]
run_and_plot(messages)
Evaluasi: Tolok Ukur STS (Semantic Textual Similarity)
The STS benchmark memberikan evaluasi intrinsik dari sejauh mana skor kesamaan dihitung kalimat embeddings menyelaraskan dengan penilaian manusia. Patokan membutuhkan sistem untuk mengembalikan skor kesamaan untuk beragam pilihan pasangan kalimat. Korelasi Pearson kemudian digunakan untuk mengevaluasi kualitas dari nilai mesin kesamaan terhadap penilaian manusia.
Unduh data
import pandas
import scipy
import math
import csv
sts_dataset = tf.keras.utils.get_file(
fname="Stsbenchmark.tar.gz",
origin="http://ixa2.si.ehu.es/stswiki/images/4/48/Stsbenchmark.tar.gz",
extract=True)
sts_dev = pandas.read_table(
os.path.join(os.path.dirname(sts_dataset), "stsbenchmark", "sts-dev.csv"),
error_bad_lines=False,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
sts_test = pandas.read_table(
os.path.join(
os.path.dirname(sts_dataset), "stsbenchmark", "sts-test.csv"),
error_bad_lines=False,
quoting=csv.QUOTE_NONE,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
# cleanup some NaN values in sts_dev
sts_dev = sts_dev[[isinstance(s, str) for s in sts_dev['sent_2']]]
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/IPython/core/interactiveshell.py:3444: FutureWarning: The error_bad_lines argument has been deprecated and will be removed in a future version. exec(code_obj, self.user_global_ns, self.user_ns)
Evaluasi Penyematan Kalimat
sts_data = sts_dev
def run_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_1'].tolist())), axis=1)
sts_encode2 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_2'].tolist())), axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1, sts_encode2), axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities, -1.0, 1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
"""Returns the similarity scores"""
return scores
dev_scores = sts_data['sim'].tolist()
scores = []
for batch in np.array_split(sts_data, 10):
scores.extend(run_sts_benchmark(batch))
pearson_correlation = scipy.stats.pearsonr(scores, dev_scores)
print('Pearson correlation coefficient = {0}\np-value = {1}'.format(
pearson_correlation[0], pearson_correlation[1]))
Pearson correlation coefficient = 0.8036394630692778 p-value = 0.0