
อุปกรณ์ Edge มักจะมีหน่วยความจำหรือพลังในการคำนวณจำกัด สามารถใช้การปรับให้เหมาะสมต่างๆ กับโมเดลเพื่อให้สามารถรันได้ภายในข้อจำกัดเหล่านี้ นอกจากนี้ การปรับปรุงประสิทธิภาพบางอย่างยังทำให้สามารถใช้ฮาร์ดแวร์พิเศษเพื่อการอนุมานแบบเร่งได้อีกด้วย
TensorFlow Lite และ ชุดเครื่องมือเพิ่มประสิทธิภาพโมเดล TensorFlow มอบเครื่องมือในการลดความซับซ้อนของการอนุมานให้เหมาะสมที่สุด
ขอแนะนำให้คุณพิจารณาการปรับโมเดลให้เหมาะสมในระหว่างกระบวนการพัฒนาแอปพลิเคชันของคุณ เอกสารนี้สรุปแนวทางปฏิบัติที่ดีที่สุดในการปรับโมเดล TensorFlow ให้เหมาะสมสำหรับการปรับใช้กับฮาร์ดแวร์ Edge
เหตุใดจึงควรปรับโมเดลให้เหมาะสม
มีหลายวิธีหลักในการเพิ่มประสิทธิภาพโมเดลสามารถช่วยในการพัฒนาแอปพลิเคชันได้
การลดขนาด
การเพิ่มประสิทธิภาพบางรูปแบบสามารถใช้เพื่อลดขนาดของแบบจำลองได้ โมเดลขนาดเล็กมีข้อดีดังต่อไปนี้:
- ขนาดพื้นที่เก็บข้อมูลเล็กลง: รุ่นเล็กใช้พื้นที่เก็บข้อมูลบนอุปกรณ์ของผู้ใช้น้อยลง ตัวอย่างเช่น แอป Android ที่ใช้รุ่นเล็กกว่าจะใช้พื้นที่เก็บข้อมูลบนอุปกรณ์เคลื่อนที่ของผู้ใช้น้อยลง
- ขนาดการดาวน์โหลดที่เล็กลง: โมเดลที่เล็กกว่าต้องใช้เวลาและแบนด์วิธน้อยลงในการดาวน์โหลดลงอุปกรณ์ของผู้ใช้
- การใช้หน่วยความจำน้อยลง: โมเดลที่เล็กกว่าจะใช้ RAM น้อยลงเมื่อทำงาน ซึ่งจะเป็นการเพิ่มหน่วยความจำให้ส่วนอื่นๆ ของแอปพลิเคชันของคุณใช้งานได้ และสามารถแปลประสิทธิภาพและความเสถียรได้ดีขึ้น
การหาปริมาณสามารถลดขนาดของแบบจำลองได้ในทุกกรณี ซึ่งอาจส่งผลให้ต้องสูญเสียความแม่นยำบางประการ การตัดและการจัดกลุ่มสามารถลดขนาดของโมเดลสำหรับการดาวน์โหลดโดยทำให้บีบอัดได้ง่ายขึ้น
การลดความหน่วง
เวลาแฝง คือระยะเวลาที่ใช้ในการอนุมานเดียวกับโมเดลที่กำหนด การปรับให้เหมาะสมบางรูปแบบสามารถลดปริมาณการคำนวณที่จำเป็นในการอนุมานโดยใช้แบบจำลอง ส่งผลให้เวลาแฝงลดลง ค่าหน่วงเวลายังส่งผลต่อการใช้พลังงานอีกด้วย
ในปัจจุบัน การหาปริมาณสามารถนำมาใช้เพื่อลดเวลาในการตอบสนองได้โดยทำให้การคำนวณที่เกิดขึ้นระหว่างการอนุมานง่ายขึ้น ซึ่งอาจต้องสูญเสียความแม่นยำบางประการ
ความเข้ากันได้ของตัวเร่งความเร็ว
ตัวเร่งฮาร์ดแวร์บางตัว เช่น Edge TPU สามารถเรียกใช้การอนุมานได้เร็วมากกับรุ่นที่ได้รับการปรับให้เหมาะสมอย่างถูกต้อง
โดยทั่วไป อุปกรณ์ประเภทนี้ต้องมีการวัดปริมาณโมเดลด้วยวิธีเฉพาะ ดูเอกสารประกอบของตัวเร่งความเร็วฮาร์ดแวร์แต่ละตัวเพื่อเรียนรู้เพิ่มเติมเกี่ยวกับข้อกำหนดของพวกเขา
การแลกเปลี่ยน
การเพิ่มประสิทธิภาพอาจส่งผลให้เกิดการเปลี่ยนแปลงความแม่นยำของโมเดล ซึ่งจะต้องพิจารณาในระหว่างกระบวนการพัฒนาแอปพลิเคชัน
การเปลี่ยนแปลงความแม่นยำขึ้นอยู่กับแต่ละรุ่นที่ได้รับการปรับให้เหมาะสม และยากต่อการคาดการณ์ล่วงหน้า โดยทั่วไป โมเดลที่ได้รับการปรับให้เหมาะสมกับขนาดหรือเวลาแฝงจะสูญเสียความแม่นยำไปเล็กน้อย สิ่งนี้อาจมีหรืออาจไม่ส่งผลกระทบต่อประสบการณ์ผู้ใช้ของคุณ ทั้งนี้ขึ้นอยู่กับแอปพลิเคชันของคุณ ในบางกรณีซึ่งเกิดขึ้นไม่บ่อยนัก บางรุ่นอาจได้รับความแม่นยำอันเป็นผลมาจากกระบวนการปรับให้เหมาะสม
ประเภทของการเพิ่มประสิทธิภาพ
ปัจจุบัน TensorFlow Lite รองรับการปรับให้เหมาะสมผ่านการหาปริมาณ การตัด และการจัดกลุ่ม
สิ่งเหล่านี้เป็นส่วนหนึ่งของ ชุดเครื่องมือเพิ่มประสิทธิภาพโมเดล TensorFlow ซึ่งมีทรัพยากรสำหรับเทคนิคการเพิ่มประสิทธิภาพโมเดลที่เข้ากันได้กับ TensorFlow Lite
การหาปริมาณ
การหาปริมาณ ทำงานโดยการลดความแม่นยำของตัวเลขที่ใช้แทนพารามิเตอร์ของโมเดล ซึ่งโดยค่าเริ่มต้นจะเป็นตัวเลขทศนิยมแบบ 32 บิต ส่งผลให้โมเดลมีขนาดเล็กลงและคำนวณได้เร็วขึ้น
การหาปริมาณประเภทต่อไปนี้มีอยู่ใน TensorFlow Lite:
| เทคนิค | ข้อกำหนดข้อมูล | การลดขนาด | ความแม่นยำ | ฮาร์ดแวร์ที่รองรับ |
|---|---|---|---|---|
| การหาปริมาณหลังการฝึก float16 | ไม่มีข้อมูล | มากถึง 50% | การสูญเสียความแม่นยำเล็กน้อย | ซีพียู, จีพียู |
| การหาปริมาณช่วงไดนามิกหลังการฝึกอบรม | ไม่มีข้อมูล | มากถึง 75% | การสูญเสียความแม่นยำน้อยที่สุด | ซีพียู, GPU (แอนดรอยด์) |
| การหาปริมาณจำนวนเต็มหลังการฝึก | ตัวอย่างตัวแทนที่ไม่มีป้ายกำกับ | มากถึง 75% | การสูญเสียความแม่นยำเล็กน้อย | CPU, GPU (Android), EdgeTPU, หกเหลี่ยม DSP |
| การฝึกอบรมที่คำนึงถึงปริมาณ | ข้อมูลการฝึกอบรมที่มีป้ายกำกับ | มากถึง 75% | การสูญเสียความแม่นยำน้อยที่สุด | CPU, GPU (Android), EdgeTPU, หกเหลี่ยม DSP |
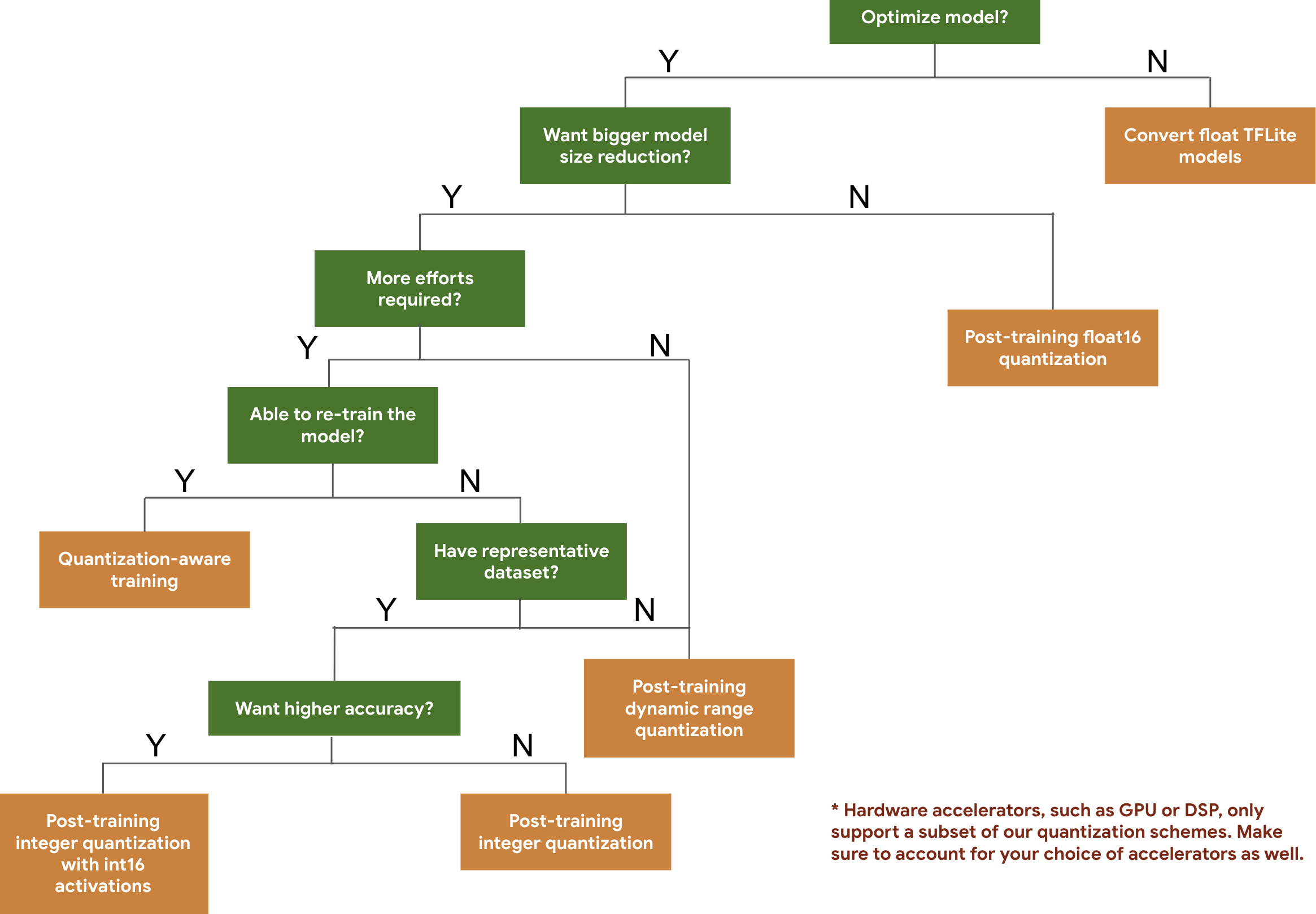
แผนผังการตัดสินใจต่อไปนี้ช่วยให้คุณเลือกแผนการวัดปริมาณที่คุณอาจต้องการใช้สำหรับแบบจำลองของคุณ โดยขึ้นอยู่กับขนาดและความแม่นยำของแบบจำลองที่คาดหวัง
ด้านล่างนี้คือผลลัพธ์ด้านเวลาแฝงและความแม่นยำสำหรับการวัดปริมาณหลังการฝึกอบรมและการฝึกอบรมที่คำนึงถึงการวัดปริมาณในโมเดลบางรุ่น จำนวนเวลาในการตอบสนองทั้งหมดวัดในอุปกรณ์ Pixel 2 โดยใช้ CPU คอร์ขนาดใหญ่ตัวเดียว เมื่อชุดเครื่องมือได้รับการปรับปรุง ตัวเลขที่นี่ก็จะเพิ่มขึ้นเช่นกัน:
| แบบอย่าง | ความแม่นยำอันดับ 1 (ต้นฉบับ) | ความแม่นยำอันดับ 1 (ปริมาณหลังการฝึกอบรม) | ความแม่นยำอันดับ 1 (การฝึกอบรมการรับรู้เชิงปริมาณ) | เวลาแฝง (ดั้งเดิม) (มิลลิวินาที) | เวลาแฝง (หลังการฝึกอบรมเชิงปริมาณ) (มิลลิวินาที) | เวลาแฝง (การฝึกอบรมการรับรู้เชิงปริมาณ) (มิลลิวินาที) | ขนาด (ต้นฉบับ) (MB) | ขนาด (เพิ่มประสิทธิภาพ) (MB) |
|---|---|---|---|---|---|---|---|---|
| โมบายเน็ต-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| โมบายเน็ต-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| การเริ่มต้น_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| เรสเน็ต_v2_101 | 0.770 | 0.768 | ไม่มี | 3973 | 2868 | ไม่มี | 178.3 | 44.9 |
การหาปริมาณจำนวนเต็มด้วยการเปิดใช้งาน int16 และน้ำหนัก int8
การหาปริมาณด้วยการเปิดใช้งาน int16 เป็นรูปแบบการหาปริมาณจำนวนเต็มที่มีการเปิดใช้งานใน int16 และน้ำหนักใน int8 โหมดนี้สามารถปรับปรุงความแม่นยำของแบบจำลองเชิงปริมาณเมื่อเปรียบเทียบกับรูปแบบการหาปริมาณจำนวนเต็มโดยมีทั้งการเปิดใช้งานและน้ำหนักใน int8 ซึ่งรักษาขนาดแบบจำลองที่ใกล้เคียงกัน ขอแนะนำเมื่อการกระตุ้นมีความอ่อนไหวต่อการหาปริมาณ
หมายเหตุ: ปัจจุบันมีเพียงการใช้งานเคอร์เนลอ้างอิงที่ไม่ได้รับการปรับให้เหมาะสมเท่านั้นที่มีอยู่ใน TFLite สำหรับโครงร่างการวัดปริมาณนี้ ดังนั้นโดยค่าเริ่มต้น ประสิทธิภาพจะช้าเมื่อเทียบกับเคอร์เนล int8 คุณสามารถเข้าถึงข้อดีทั้งหมดของโหมดนี้ผ่านทางฮาร์ดแวร์เฉพาะหรือซอฟต์แวร์ที่กำหนดเองได้
ด้านล่างนี้คือผลลัพธ์ความแม่นยำสำหรับบางรุ่นที่ได้รับประโยชน์จากโหมดนี้ แบบอย่าง ประเภทเมตริกความแม่นยำ ความแม่นยำ (การเปิดใช้งาน float32) ความแม่นยำ (การเปิดใช้งาน int8) ความแม่นยำ (การเปิดใช้งาน int16) Wav2letter แวร์ 6.7% 7.7% 7.2% DeepSpeech 0.5.1 (ไม่ได้เปิดใช้งาน) ซีอีอาร์ 6.13% 43.67% 6.52% โยโลV3 เอ็มเอพี(IOU=0.5) 0.577 0.563 0.574 โมบายเน็ตV1 ความแม่นยำอันดับ 1 0.7062 0.694 0.6936 โมบายเน็ทV2 ความแม่นยำอันดับ 1 0.718 0.7126 0.7137 โมบายเบิร์ต F1(ตรงทั้งหมด) 88.81(81.23) 2.08(0) 88.73(81.15)
การตัดแต่งกิ่ง
การตัดแต่งกิ่ง ทำงานโดยการลบพารามิเตอร์ภายในแบบจำลองที่มีผลกระทบเพียงเล็กน้อยต่อการคาดการณ์ โมเดลที่ถูกตัดออกจะมีขนาดเท่ากันบนดิสก์ และมีเวลาแฝงรันไทม์เท่ากัน แต่สามารถบีบอัดได้อย่างมีประสิทธิภาพมากกว่า ทำให้การตัดเป็นเทคนิคที่มีประโยชน์ในการลดขนาดการดาวน์โหลดโมเดล
ในอนาคต TensorFlow Lite จะช่วยลดเวลาในการตอบสนองสำหรับโมเดลที่ถูกตัดออก
การจัดกลุ่ม
การทำคลัสเตอร์ ทำงานโดยการจัดกลุ่มน้ำหนักของแต่ละเลเยอร์ในแบบจำลองให้เป็นจำนวนคลัสเตอร์ที่กำหนดไว้ล่วงหน้า จากนั้นแชร์ค่าเซนทรอยด์สำหรับน้ำหนักที่เป็นของแต่ละคลัสเตอร์ ซึ่งจะช่วยลดจำนวนค่าน้ำหนักที่ไม่ซ้ำกันในแบบจำลอง จึงลดความซับซ้อนลง
เป็นผลให้โมเดลแบบคลัสเตอร์สามารถบีบอัดได้อย่างมีประสิทธิภาพมากขึ้น โดยให้ประโยชน์ในการใช้งานคล้ายกับการตัดออก
ขั้นตอนการพัฒนา
เพื่อเป็นจุดเริ่มต้น ให้ตรวจสอบว่าโมเดลใน โมเดลที่โฮสต์ สามารถทำงานได้กับแอปพลิเคชันของคุณหรือไม่ หากไม่ เราขอแนะนำให้ผู้ใช้เริ่มต้นด้วย เครื่องมือวัดปริมาณหลังการฝึกอบรม เนื่องจากสามารถใช้ได้ในวงกว้างและไม่จำเป็นต้องมีข้อมูลการฝึกอบรม
ในกรณีที่ไม่บรรลุเป้าหมายความแม่นยำและเวลาแฝง หรือการสนับสนุนตัวเร่งฮาร์ดแวร์เป็นสิ่งสำคัญ การฝึกอบรมที่คำนึงถึงปริมาณ เป็นตัวเลือกที่ดีกว่า ดูเทคนิคการเพิ่มประสิทธิภาพเพิ่มเติมภายใต้ ชุดเครื่องมือเพิ่มประสิทธิภาพโมเดล TensorFlow
หากคุณต้องการลดขนาดโมเดลของคุณเพิ่มเติม คุณสามารถลอง ตัด และ/หรือ จัดกลุ่ม ก่อนที่จะหาจำนวนโมเดลของคุณ