
เหตุการณ์หายนะที่เกี่ยวข้องกับ NaN บางครั้งสามารถเกิดขึ้นได้ในระหว่างโปรแกรม TensorFlow ซึ่งทำให้กระบวนการฝึกโมเดลพิการ สาเหตุของเหตุการณ์ดังกล่าวมักจะคลุมเครือ โดยเฉพาะโมเดลที่มีขนาดและความซับซ้อนที่ไม่ซับซ้อน เพื่อให้แก้ไขจุดบกพร่องของโมเดลประเภทนี้ได้ง่ายขึ้น TensorBoard 2.3+ (ร่วมกับ TensorFlow 2.3+) จึงจัดให้มีแดชบอร์ดเฉพาะที่เรียกว่า Debugger V2 ที่นี่เราจะสาธิตวิธีใช้เครื่องมือนี้โดยแก้ไขจุดบกพร่องจริงที่เกี่ยวข้องกับ NaN ในโครงข่ายประสาทเทียมที่เขียนด้วย TensorFlow
เทคนิคที่แสดงในบทช่วยสอนนี้สามารถใช้ได้กับกิจกรรมการแก้ไขจุดบกพร่องประเภทอื่นๆ เช่น การตรวจสอบรูปร่างเทนเซอร์รันไทม์ในโปรแกรมที่ซับซ้อน บทช่วยสอนนี้มุ่งเน้นไปที่ NaN เนื่องจากมีความถี่ในการเกิดค่อนข้างสูง
การสังเกตจุดบกพร่อง
ซอร์สโค้ดของโปรแกรม TF2 ที่เราจะดีบัก มีอยู่ใน GitHub โปรแกรมตัวอย่างยังรวมอยู่ในแพ็กเกจ pip tensorflow (เวอร์ชัน 2.3+) และสามารถเรียกใช้ได้โดย:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
โปรแกรม TF2 นี้สร้างการรับรู้แบบหลายชั้น (MLP) และฝึกให้จดจำภาพ MNIST ตัวอย่างนี้จงใจใช้ API ระดับต่ำของ TF2 เพื่อกำหนดโครงสร้างเลเยอร์ที่กำหนดเอง ฟังก์ชันการสูญเสีย และลูปการฝึกอบรม เนื่องจากโอกาสที่จะเกิดข้อบกพร่องของ NaN จะสูงกว่าเมื่อเราใช้ API ที่ยืดหยุ่นกว่าแต่มีแนวโน้มที่จะเกิดข้อผิดพลาดมากกว่าเมื่อเราใช้งานที่ง่ายกว่า -to-use แต่มีความยืดหยุ่นน้อยกว่าเล็กน้อย API ระดับสูงเช่น tf.keras
โปรแกรมจะพิมพ์การทดสอบความแม่นยำหลังจากแต่ละขั้นตอนการฝึกอบรม เราจะเห็นได้ในคอนโซลว่าความแม่นยำในการทดสอบติดอยู่ที่ระดับโอกาสใกล้ (~0.1) หลังจากขั้นตอนแรก นี่ไม่ใช่ลักษณะการทำงานของการฝึกโมเดลอย่างแน่นอน: เราคาดว่าความแม่นยำจะค่อยๆ เข้าใกล้ 1.0 (100%) เมื่อขั้นตอนเพิ่มขึ้น
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
การคาดเดาจากการศึกษาพบว่าปัญหานี้เกิดจากความไม่แน่นอนของตัวเลข เช่น NaN หรือค่าอนันต์ อย่างไรก็ตาม เราจะยืนยันได้อย่างไรว่าเป็นเช่นนั้นจริงๆ และเราจะค้นหาการดำเนินการ TensorFlow (op) ที่รับผิดชอบในการสร้างความไม่เสถียรเชิงตัวเลขได้อย่างไร เพื่อตอบคำถามเหล่านี้ เรามาติดตั้งโปรแกรมบั๊กกี้ด้วย Debugger V2 กันดีกว่า
การติดตั้งโค้ด TensorFlow ด้วย Debugger V2
tf.debugging.experimental.enable_dump_debug_info() คือจุดเริ่มต้น API ของ Debugger V2 มันติดตั้งโปรแกรม TF2 ด้วยโค้ดบรรทัดเดียว ตัวอย่างเช่น การเพิ่มบรรทัดต่อไปนี้ใกล้กับจุดเริ่มต้นของโปรแกรมจะทำให้ข้อมูลการดีบักถูกเขียนลงในไดเร็กทอรีบันทึก (logdir) ที่ /tmp/tfdbg2_logdir ข้อมูลการแก้ไขข้อบกพร่องครอบคลุมแง่มุมต่างๆ ของรันไทม์ TensorFlow ใน TF2 ประกอบด้วยประวัติเต็มรูปแบบของการดำเนินการที่กระตือรือร้น การสร้างกราฟที่ดำเนินการโดย @tf.function การดำเนินการของกราฟ ค่าเทนเซอร์ที่สร้างโดยเหตุการณ์การดำเนินการ รวมถึงตำแหน่งของโค้ด (การติดตามสแต็ก Python) ของเหตุการณ์เหล่านั้น . ข้อมูลการแก้ไขข้อบกพร่องที่สมบูรณ์ทำให้ผู้ใช้สามารถจำกัดข้อบกพร่องที่คลุมเครือให้แคบลงได้
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
อาร์กิวเมนต์ tensor_debug_mode ควบคุมว่าข้อมูลใดที่ Debugger V2 ดึงมาจากเทนเซอร์ที่กระตือรือร้นหรือในกราฟแต่ละตัว “FULL_HEALTH” เป็นโหมดที่รวบรวมข้อมูลต่อไปนี้เกี่ยวกับเทนเซอร์ชนิดลอยตัวแต่ละตัว (เช่น float32 ที่เห็นโดยทั่วไปและ bfloat16 dtype ที่พบน้อยกว่า):
- Dประเภท
- อันดับ
- จำนวนองค์ประกอบทั้งหมด
- การแยกย่อยองค์ประกอบประเภทลอยตัวเป็นหมวดหมู่ต่อไปนี้: ลบจำกัด (
-), ศูนย์ (0), จำกัดบวก (+), ลบอนันต์ (-∞), อนันต์บวก (+∞) และNaN
โหมด "FULL_HEALTH" เหมาะสำหรับการดีบักข้อบกพร่องที่เกี่ยวข้องกับ NaN และอนันต์ ดูด้านล่างสำหรับ tensor_debug_mode อื่นๆ ที่รองรับ
อาร์กิวเมนต์ circular_buffer_size ควบคุมจำนวนเหตุการณ์เทนเซอร์ที่บันทึกไว้ใน logdir โดยค่าเริ่มต้นอยู่ที่ 1,000 ซึ่งทำให้เทนเซอร์ 1,000 ตัวสุดท้ายก่อนสิ้นสุดโปรแกรม TF2 ที่วัดไว้เท่านั้นที่จะบันทึกลงดิสก์ ลักษณะการทำงานเริ่มต้นนี้ช่วยลดค่าใช้จ่ายในการดีบักเกอร์โดยเสียสละความสมบูรณ์ของข้อมูลการดีบัก หากต้องการความสมบูรณ์ ในกรณีนี้ เราสามารถปิดใช้งานบัฟเฟอร์แบบวงกลมได้โดยการตั้งค่าอาร์กิวเมนต์ให้เป็นค่าลบ (เช่น -1 ที่นี่)
ตัวอย่าง debug_mnist_v2 เรียกใช้งาน enable_dump_debug_info() โดยการส่งแฟล็กบรรทัดคำสั่งไป หากต้องการรันโปรแกรม TF2 ที่มีปัญหาอีกครั้งโดยเปิดใช้งานเครื่องมือแก้ไขข้อบกพร่องนี้ ให้ทำดังนี้
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
การเริ่มต้น Debugger V2 GUI ใน TensorBoard
การรันโปรแกรมด้วยเครื่องมือดีบักเกอร์จะสร้าง logdir ที่ /tmp/tfdbg2_logdir เราสามารถเริ่ม TensorBoard และชี้ไปที่ logdir ด้วย:
tensorboard --logdir /tmp/tfdbg2_logdir
ในเว็บเบราว์เซอร์ ให้ไปที่หน้าของ TensorBoard ที่ http://localhost:6006 ปลั๊กอิน “Debugger V2” จะไม่ทำงานตามค่าเริ่มต้น ดังนั้นให้เลือกจากเมนู “ปลั๊กอินที่ไม่ใช้งาน” ที่ด้านบนขวา เมื่อเลือกแล้วควรมีลักษณะดังนี้:
การใช้ Debugger V2 GUI เพื่อค้นหาสาเหตุที่แท้จริงของ NaN
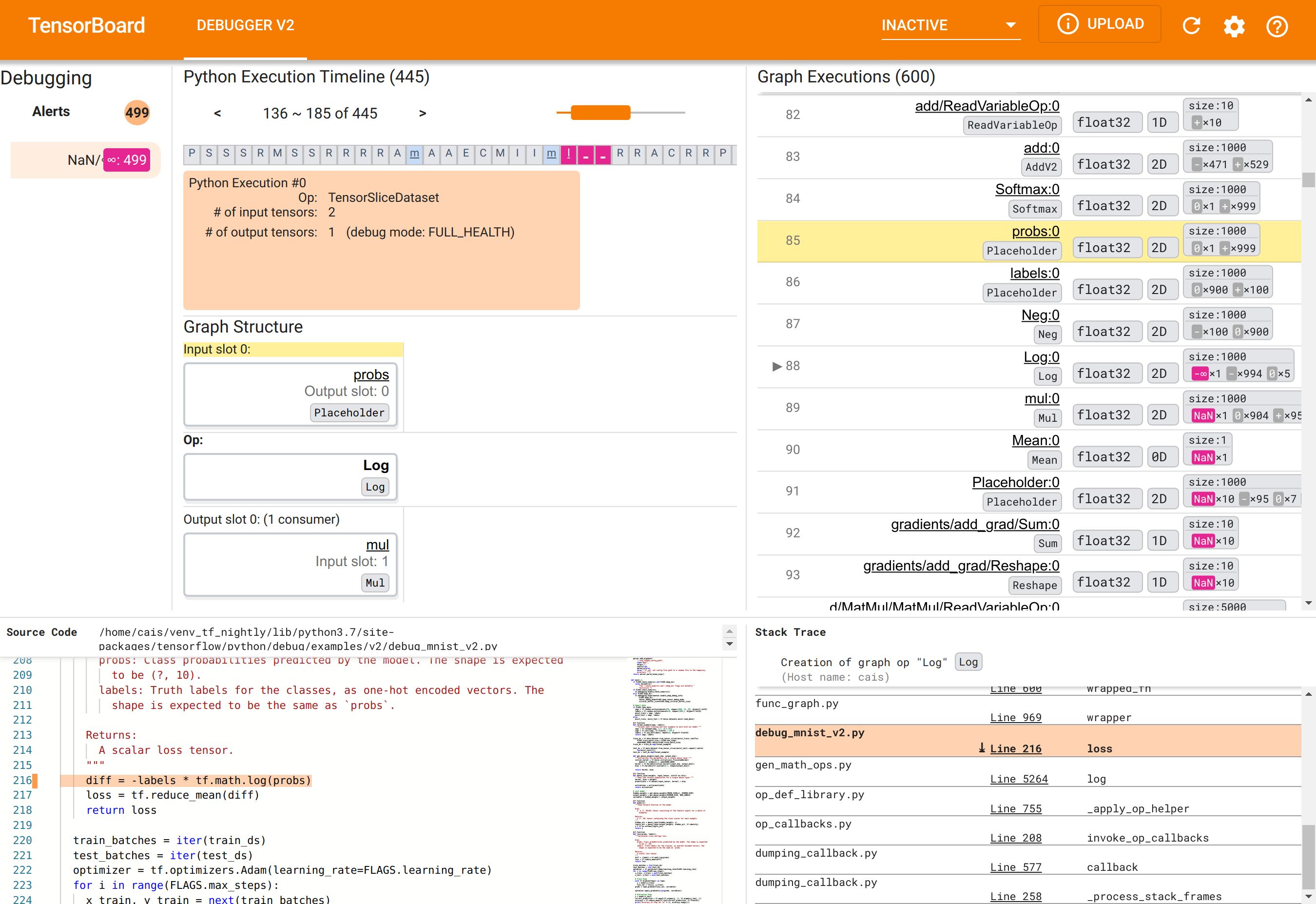
GUI Debugger V2 ใน TensorBoard ได้รับการจัดระเบียบออกเป็นหกส่วน:
- การแจ้งเตือน : ส่วนซ้ายบนนี้ประกอบด้วยรายการเหตุการณ์ "การแจ้งเตือน" ที่ตรวจพบโดยดีบักเกอร์ในข้อมูลดีบักจากโปรแกรม TensorFlow ที่มีเครื่องมือ การแจ้งเตือนแต่ละครั้งจะบ่งบอกถึงความผิดปกติบางอย่างที่ดึงดูดความสนใจ ในกรณีของเรา ส่วนนี้เน้นเหตุการณ์ 499 NaN/∞ โดยมีสีชมพู-แดงเด่นชัด สิ่งนี้เป็นการยืนยันความสงสัยของเราว่าโมเดลไม่สามารถเรียนรู้ได้เนื่องจากการมีอยู่ของ NaN และ/หรือค่าอนันต์ในค่าเทนเซอร์ภายใน เราจะเจาะลึกการแจ้งเตือนเหล่านี้ในไม่ช้า
- Python Execution Timeline : นี่คือครึ่งบนของส่วนบน-กลาง นำเสนอประวัติที่สมบูรณ์ของการดำเนินการ Ops และกราฟอย่างกระตือรือร้น แต่ละช่องของไทม์ไลน์จะถูกทำเครื่องหมายด้วยตัวอักษรเริ่มต้นของ op หรือชื่อของกราฟ (เช่น “T” สำหรับ “TensorSliceDataset” op, “m” สำหรับ “model”
tf.function) เราสามารถนำทางไทม์ไลน์นี้ได้โดยใช้ปุ่มนำทางและแถบเลื่อนเหนือไทม์ไลน์ - การดำเนินการกราฟ : ตั้งอยู่ที่มุมขวาบนของ GUI ส่วนนี้จะเป็นศูนย์กลางของงานแก้ไขจุดบกพร่องของเรา มันมีประวัติของเทนเซอร์ชนิดลอยตัวทั้งหมดที่คำนวณภายในกราฟ (เช่น คอมไพล์โดย
@tf-functions) - โครงสร้างกราฟ (ครึ่งล่างของส่วนตรงกลางบน), ซอร์สโค้ด (ส่วนซ้ายล่าง) และ Stack Trace (ส่วนล่างขวา) ว่างเปล่าในตอนแรก เนื้อหาของพวกเขาจะถูกเติมเมื่อเราโต้ตอบกับ GUI ทั้งสามส่วนนี้จะมีบทบาทสำคัญในงานแก้ไขข้อบกพร่องของเราด้วย
หลังจากมุ่งเน้นไปที่การจัดระบบ UI แล้ว ให้เราทำตามขั้นตอนต่อไปนี้เพื่อดูรายละเอียดสาเหตุที่ NaN ปรากฏ ขั้นแรก คลิกการแจ้งเตือน NaN/∞ ในส่วนการแจ้งเตือน ซึ่งจะเลื่อนรายการเทนเซอร์กราฟ 600 รายการในส่วนการดำเนินการกราฟโดยอัตโนมัติ และมุ่งเน้นไปที่ #88 ซึ่งเป็นเทนเซอร์ชื่อ Log:0 ที่สร้างโดย Log (ลอการิทึมธรรมชาติ) สีชมพู-แดงที่โดดเด่นจะเน้นองค์ประกอบ -∞ ท่ามกลางองค์ประกอบ 1,000 ชิ้นของเทนเซอร์ 2D float32 นี่เป็นเทนเซอร์ตัวแรกในประวัติรันไทม์ของโปรแกรม TF2 ที่มี NaN หรืออนันต์: เทนเซอร์ที่คำนวณก่อนที่จะไม่มี NaN หรือ ∞; เทนเซอร์จำนวนมาก (ในความเป็นจริง ส่วนใหญ่) ที่คำนวณในภายหลังมี NaN เราสามารถยืนยันสิ่งนี้ได้โดยการเลื่อนขึ้นและลงในรายการการดำเนินการกราฟ การสังเกตนี้ให้คำแนะนำที่ชัดเจนว่า Log op เป็นที่มาของความไม่เสถียรเชิงตัวเลขในโปรแกรม TF2 นี้
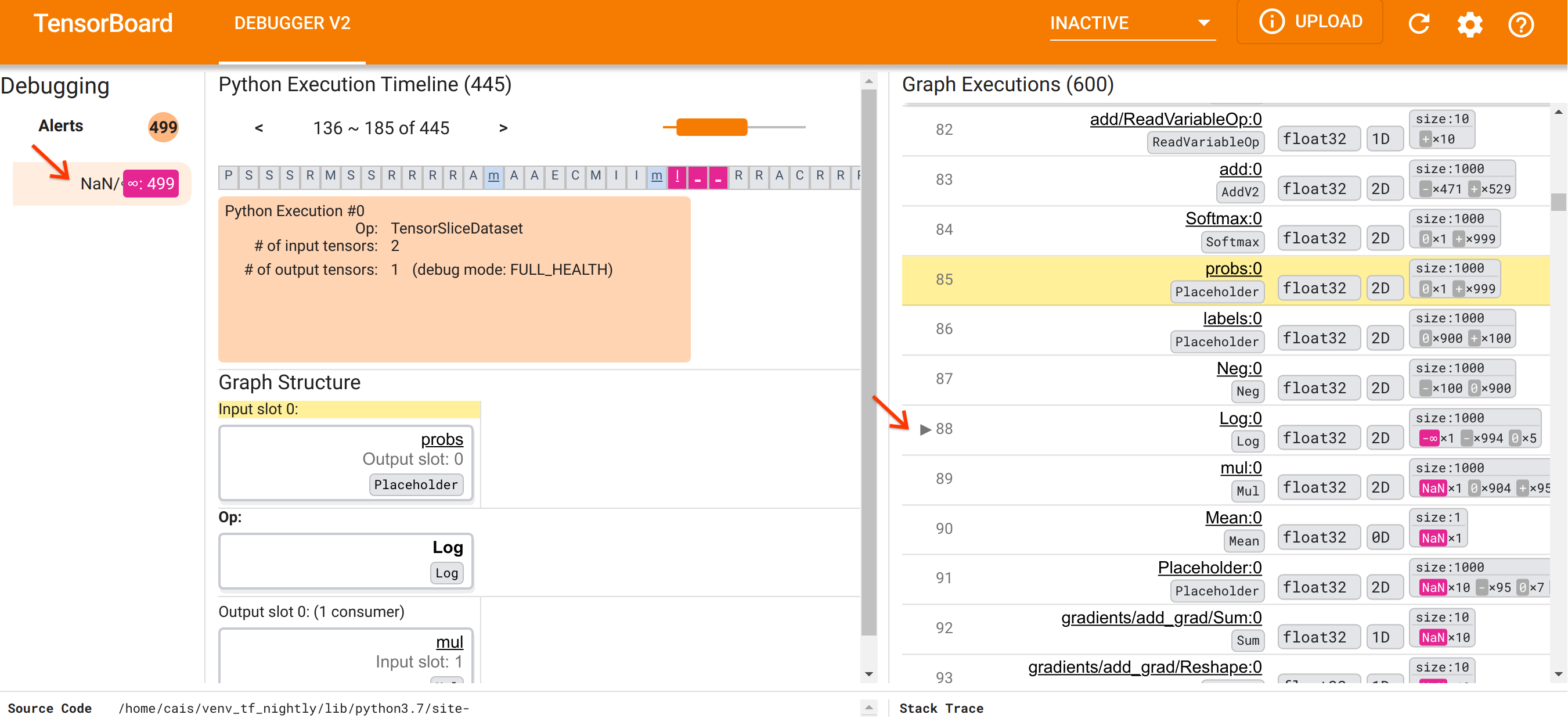
เหตุใด Log นี้จึงคาย-∞ออกมา การตอบคำถามนั้นจำเป็นต้องตรวจสอบข้อมูลของสหกรณ์ การคลิกที่ชื่อของเทนเซอร์ ( Log:0 ) จะแสดงภาพที่เรียบง่ายแต่ให้ข้อมูลของบริเวณใกล้เคียงของ Log op ในกราฟ TensorFlow ในส่วนโครงสร้างกราฟ สังเกตทิศทางการไหลของข้อมูลจากบนลงล่าง op นั้นจะแสดงด้วยตัวหนาตรงกลาง ที่ด้านบนทันที เราจะเห็นว่า Placeholder op ให้ข้อมูลอินพุตเดียวแก่ Log op เทนเซอร์ที่สร้างโดยตัวยึดตำแหน่ง probs นี้อยู่ที่ไหนในรายการการดำเนินการกราฟ ด้วยการใช้สีพื้นหลังสีเหลืองเป็นตัวช่วยในการมองเห็น เราจะเห็นได้ว่า probs:0 เทนเซอร์อยู่เหนือสามแถวเหนือ Log:0 เทนเซอร์ นั่นคือในแถวที่ 85
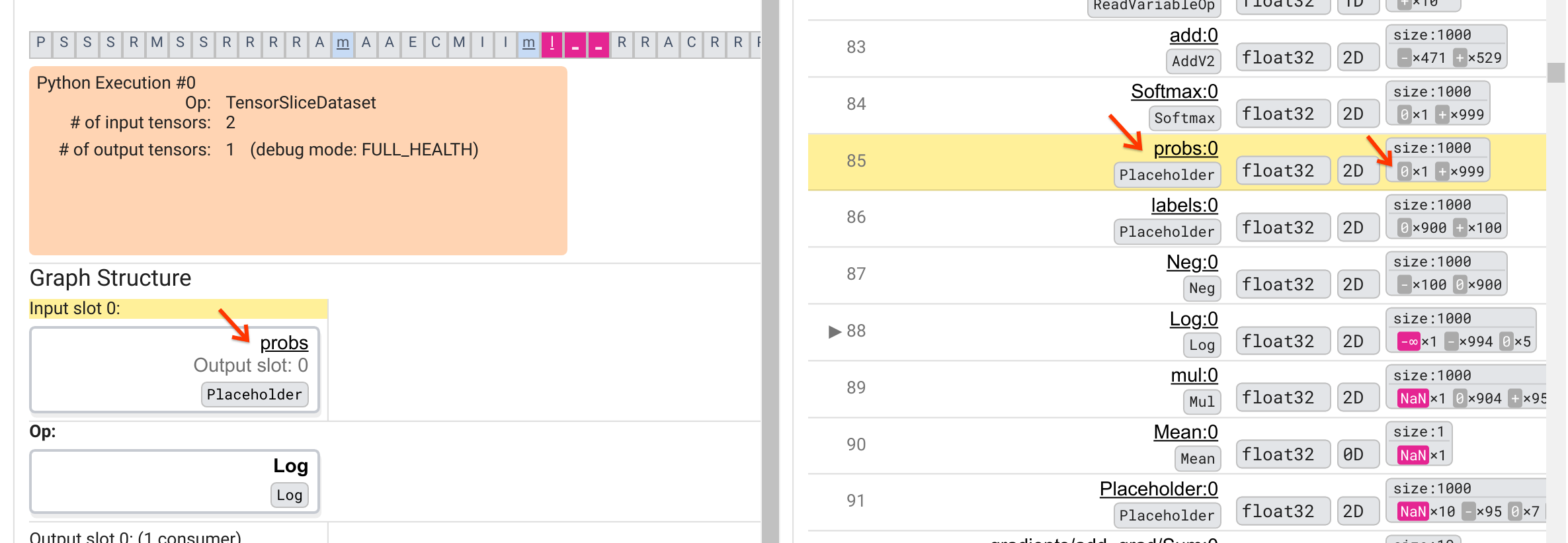
การดูการแยกย่อยตัวเลขของ probs:0 เทนเซอร์ในแถวที่ 85 อย่างละเอียดยิ่งขึ้นเผยให้เห็นว่าทำไม Log:0 ของผู้บริโภคถึงสร้าง -∞: ในบรรดา 1,000 องค์ประกอบของ probs:0 องค์ประกอบหนึ่งมีค่าเป็น 0 -∞ คือ ผลลัพธ์ของการคำนวณลอการิทึมธรรมชาติของ 0! หากเราสามารถแน่ใจได้ว่า Log op ได้รับการเปิดเผยเฉพาะอินพุตที่เป็นบวกเท่านั้น เราจะสามารถป้องกันไม่ให้ NaN/∞ เกิดขึ้นได้ ซึ่งสามารถทำได้โดยการใช้การตัด (เช่นโดยใช้ tf.clip_by_value() ) บนตัวยึดตำแหน่ง probs เทนเซอร์
เรากำลังเข้าใกล้การแก้ไขข้อบกพร่องมากขึ้น แต่ยังไม่ค่อยเสร็จสิ้น ในการใช้การแก้ไข เราจำเป็นต้องทราบว่า Log op และอินพุต Placeholder มาจากที่ใดในซอร์สโค้ด Python Debugger V2 ให้การสนับสนุนชั้นหนึ่งสำหรับการติดตามการดำเนินการด้านกราฟและเหตุการณ์การดำเนินการไปยังแหล่งที่มา เมื่อเราคลิก Log:0 tensor ใน Graph Executions ส่วน Stack Trace จะถูกเติมด้วย Stack Trace ดั้งเดิมของการสร้าง Log op การติดตามสแต็กมีขนาดค่อนข้างใหญ่เนื่องจากมีเฟรมจำนวนมากจากโค้ดภายในของ TensorFlow (เช่น gen_math_ops.py และ dumping_callback.py) ซึ่งเราสามารถเพิกเฉยได้อย่างปลอดภัยสำหรับงานแก้ไขข้อบกพร่องส่วนใหญ่ กรอบที่น่าสนใจคือบรรทัดที่ 216 ของ debug_mnist_v2.py (เช่น ไฟล์ Python ที่เรากำลังพยายามแก้ไขจุดบกพร่อง) การคลิก "บรรทัด 216" จะแสดงมุมมองของบรรทัดโค้ดที่เกี่ยวข้องในส่วนซอร์สโค้ด
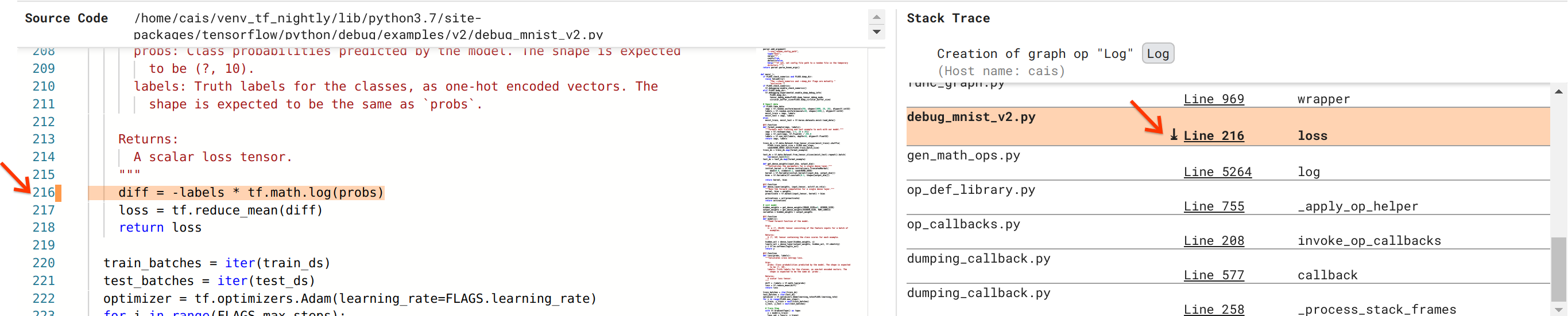
ในที่สุดสิ่งนี้ก็นำเราไปสู่ซอร์สโค้ดที่สร้าง Log op ที่มีปัญหาจากอินพุต probs นี่คือฟังก์ชันการสูญเสียข้ามเอนโทรปีตามหมวดหมู่ที่กำหนดเองของเราซึ่งตกแต่งด้วย @tf.function และด้วยเหตุนี้จึงแปลงเป็นกราฟ TensorFlow Placeholder op probs สอดคล้องกับอาร์กิวเมนต์อินพุตแรกกับฟังก์ชันการสูญเสีย Log op สร้างขึ้นด้วยการเรียก tf.math.log() API
การแก้ไขจุดบกพร่องนี้จะมีลักษณะดังนี้:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
จะแก้ไขความไม่เสถียรเชิงตัวเลขในโปรแกรม TF2 นี้ และทำให้ MLP ฝึกฝนได้สำเร็จ อีกวิธีที่เป็นไปได้ในการแก้ไขความไม่แน่นอนของตัวเลขคือการใช้ tf.keras.losses.CategoricalCrossentropy
นี่เป็นการสรุปการเดินทางของเราจากการสังเกตข้อบกพร่องของโมเดล TF2 ไปสู่การเปลี่ยนแปลงโค้ดที่แก้ไขข้อบกพร่อง ซึ่งได้รับความช่วยเหลือจากเครื่องมือ Debugger V2 ซึ่งช่วยให้มองเห็นประวัติการดำเนินการที่กระตือรือร้นและกราฟของโปรแกรม TF2 ที่ติดตั้งเครื่องมือได้อย่างสมบูรณ์ รวมถึงข้อมูลสรุปเชิงตัวเลข ของค่าเทนเซอร์และการเชื่อมโยงระหว่าง ops, เทนเซอร์ และซอร์สโค้ดดั้งเดิม
ความเข้ากันได้ของฮาร์ดแวร์ของ Debugger V2
Debugger V2 รองรับฮาร์ดแวร์การฝึกอบรมกระแสหลัก รวมถึง CPU และ GPU รองรับการฝึกอบรม Multi-GPU ด้วย tf.distributed.MirroredStrategy การรองรับ TPU ยังอยู่ในช่วงเริ่มต้นและต้องมีการโทรติดต่อ
tf.config.set_soft_device_placement(True)
ก่อนที่จะเรียก enable_dump_debug_info() มันอาจมีข้อจำกัดอื่น ๆ เกี่ยวกับ TPU เช่นกัน หากคุณประสบปัญหาในการใช้ Debugger V2 โปรดรายงานข้อบกพร่องใน หน้าปัญหา GitHub ของเรา
ความเข้ากันได้ของ API ของ Debugger V2
Debugger V2 ได้รับการปรับใช้ในระดับที่ค่อนข้างต่ำของสแต็กซอฟต์แวร์ของ TensorFlow และด้วยเหตุนี้จึงเข้ากันได้กับ tf.keras , tf.data และ API อื่นๆ ที่สร้างขึ้นจากระดับที่ต่ำกว่าของ TensorFlow Debugger V2 ยังเข้ากันได้แบบย้อนหลังกับ TF1 แม้ว่า Eager Execution Timeline จะว่างเปล่าสำหรับ logdirs การดีบักที่สร้างโดยโปรแกรม TF1
เคล็ดลับการใช้ API
คำถามที่พบบ่อยเกี่ยวกับ API การดีบักนี้คือจุดใดในโค้ด TensorFlow ที่เราควรแทรกการเรียกไปที่ enable_dump_debug_info() โดยทั่วไปแล้ว ควรเรียก API โดยเร็วที่สุดในโปรแกรม TF2 ของคุณ โดยเฉพาะอย่างยิ่งหลังจากบรรทัดนำเข้า Python และก่อนที่การสร้างกราฟและการดำเนินการจะเริ่มต้น สิ่งนี้จะช่วยให้มั่นใจได้ถึงความครอบคลุมเต็มรูปแบบของการดำเนินการและกราฟทั้งหมดที่ขับเคลื่อนโมเดลและการฝึกอบรมของคุณ
tensor_debug_modes ที่สนับสนุนในปัจจุบันคือ: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH และ SHAPE โดยจะแตกต่างกันไปตามปริมาณข้อมูลที่ดึงมาจากเทนเซอร์แต่ละตัวและค่าใช้จ่ายด้านประสิทธิภาพการทำงานของโปรแกรมที่ทำการดีบั๊ก โปรดดู ส่วน args ของเอกสารประกอบของ enable_dump_debug_info()
ค่าใช้จ่ายด้านประสิทธิภาพ
API การแก้ไขจุดบกพร่องจะแนะนำโอเวอร์เฮดด้านประสิทธิภาพให้กับโปรแกรม TensorFlow ที่มีเครื่องมือวัด ค่าใช้จ่ายจะแตกต่างกันไปตาม tensor_debug_mode ประเภทฮาร์ดแวร์ และลักษณะของโปรแกรม TensorFlow ที่มีเครื่องมือ เป็นจุดอ้างอิงบน GPU โหมด NO_TENSOR จะเพิ่มค่าใช้จ่าย 15% ในระหว่างการฝึก โมเดล Transformer ภายใต้ขนาดแบทช์ 64 เปอร์เซ็นต์ค่าใช้จ่ายสำหรับ tensor_debug_modes อื่น ๆ จะสูงกว่า: ประมาณ 50% สำหรับ CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH และ SHAPE โหมด บน CPU โอเวอร์เฮดจะลดลงเล็กน้อย บน TPU ค่าใช้จ่ายในปัจจุบันจะสูงกว่า
ความสัมพันธ์กับ API การดีบัก TensorFlow อื่นๆ
โปรดทราบว่า TensorFlow มีเครื่องมือและ API อื่นๆ สำหรับการแก้ไขข้อบกพร่อง คุณสามารถเรียกดู API ดังกล่าวได้ภายใต้ เนม tf.debugging.* ได้ ที่หน้าเอกสาร API ในบรรดา API เหล่านี้ tf.print() ใช้บ่อยที่สุด เมื่อใดที่เราควรใช้ Debugger V2 และเมื่อใดจึงควรใช้ tf.print() แทน tf.print() สะดวกในกรณีที่
- เรารู้แน่ชัดว่าเทนเซอร์ตัวไหนที่จะพิมพ์
- เรารู้ว่าซอร์สโค้ดที่จะแทรกคำสั่ง
tf.print()เหล่านั้นอยู่ที่ไหน - จำนวนเทนเซอร์ดังกล่าวไม่ใหญ่เกินไป
สำหรับกรณีอื่นๆ (เช่น การตรวจสอบค่าเทนเซอร์หลายๆ ค่า การตรวจสอบค่าเทนเซอร์ที่สร้างโดยโค้ดภายในของ TensorFlow และการค้นหาต้นกำเนิดของความไม่เสถียรเชิงตัวเลขดังที่เราแสดงไว้ข้างต้น) Debugger V2 มอบวิธีการดีบักที่รวดเร็วยิ่งขึ้น นอกจากนี้ Debugger V2 ยังมีวิธีการแบบครบวงจรในการตรวจสอบความกระตือรือร้นและกราฟเทนเซอร์ นอกจากนี้ยังให้ข้อมูลเกี่ยวกับโครงสร้างกราฟและตำแหน่งของโค้ด ซึ่งอยู่นอกเหนือความสามารถของ tf.print()
API อื่นที่สามารถใช้เพื่อแก้ไขปัญหาที่เกี่ยวข้องกับ ∞ และ NaN คือ tf.debugging.enable_check_numerics() ต่างจาก enable_dump_debug_info() ตรงที่ enable_check_numerics() จะไม่บันทึกข้อมูลการดีบักลงในดิสก์ แต่จะตรวจสอบ ∞ และ NaN เท่านั้นในระหว่างรันไทม์ TensorFlow และเกิดข้อผิดพลาดกับตำแหน่งโค้ดต้นฉบับทันทีที่ op ใด ๆ สร้างค่าตัวเลขที่ไม่ถูกต้อง มีค่าใช้จ่ายด้านประสิทธิภาพที่ต่ำกว่าเมื่อเปรียบเทียบกับ enable_dump_debug_info() แต่ไม่สามารถติดตามประวัติการทำงานของโปรแกรมได้ทั้งหมด และไม่มีอินเทอร์เฟซผู้ใช้แบบกราฟิกเช่น Debugger V2