
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
ใช้ TensorBoard ฝัง Projector, คุณสามารถแสดงกราฟิก embeddings มิติสูง ซึ่งจะเป็นประโยชน์ในการแสดงภาพ ตรวจสอบ และทำความเข้าใจเลเยอร์การฝังของคุณ

ในบทช่วยสอนนี้ คุณจะได้เรียนรู้ว่าการแสดงภาพเลเยอร์ที่ได้รับการฝึกฝนประเภทนี้เป็นอย่างไร
ติดตั้ง
สำหรับบทช่วยสอนนี้ เราจะใช้ TensorBoard เพื่อแสดงภาพเลเยอร์การฝังที่สร้างขึ้นเพื่อจัดประเภทข้อมูลบทวิจารณ์ภาพยนตร์
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
ข้อมูล IMDB
เราจะใช้ชุดข้อมูลบทวิจารณ์ภาพยนตร์ IMDB 25,000 เรื่อง ซึ่งแต่ละรายการมีป้ายกำกับความรู้สึก (บวก/ลบ) การตรวจสอบแต่ละครั้งจะได้รับการประมวลผลล่วงหน้าและเข้ารหัสเป็นลำดับของดัชนีคำ (จำนวนเต็ม) เพื่อความง่าย คำจะถูกสร้างดัชนีตามความถี่โดยรวมในชุดข้อมูล เช่น จำนวนเต็ม "3" จะเข้ารหัสคำที่ใช้บ่อยที่สุดอันดับ 3 ที่ปรากฏในบทวิจารณ์ทั้งหมด ซึ่งช่วยให้ดำเนินการกรองได้อย่างรวดเร็ว เช่น: "พิจารณาเฉพาะคำที่พบบ่อยที่สุด 10,000 คำ แต่ตัดคำที่พบบ่อยที่สุด 20 อันดับแรก"
ตามแบบแผน "0" ไม่ได้ยืนสำหรับคำใดคำหนึ่ง แต่จะใช้เพื่อเข้ารหัสคำที่ไม่รู้จักแทน ภายหลังในบทช่วยสอน เราจะลบแถวสำหรับ "0" ในการแสดงภาพ
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Keras Embedding Layer
ชั้น Keras ฝัง สามารถนำมาใช้ในการฝึกอบรมการฝังสำหรับแต่ละคำในคำศัพท์ของคุณ แต่ละคำ (หรือคำย่อยในกรณีนี้) จะเชื่อมโยงกับเวกเตอร์ 16 มิติ (หรือการฝัง) ที่จะฝึกโดยโมเดล
ดู การกวดวิชานี้ จะเรียนรู้เพิ่มเติมเกี่ยวกับคำ embeddings
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
บันทึกข้อมูลสำหรับ TensorBoard
TensorBoard อ่านเทนเซอร์และข้อมูลเมตาจากบันทึกของโปรเจ็กต์เทนเซอร์โฟลว์ของคุณ เส้นทางไปยังไดเรกทอรีล็อกจะถูกระบุด้วย log_dir ด้านล่าง สำหรับการกวดวิชานี้เราจะใช้ /logs/imdb-example/ /
ในการโหลดข้อมูลลงใน Tensorboard เราจำเป็นต้องบันทึกจุดตรวจสอบการฝึกอบรมลงในไดเร็กทอรีนั้น พร้อมด้วยข้อมูลเมตาที่ช่วยให้มองเห็นเลเยอร์เฉพาะที่น่าสนใจในโมเดลได้
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
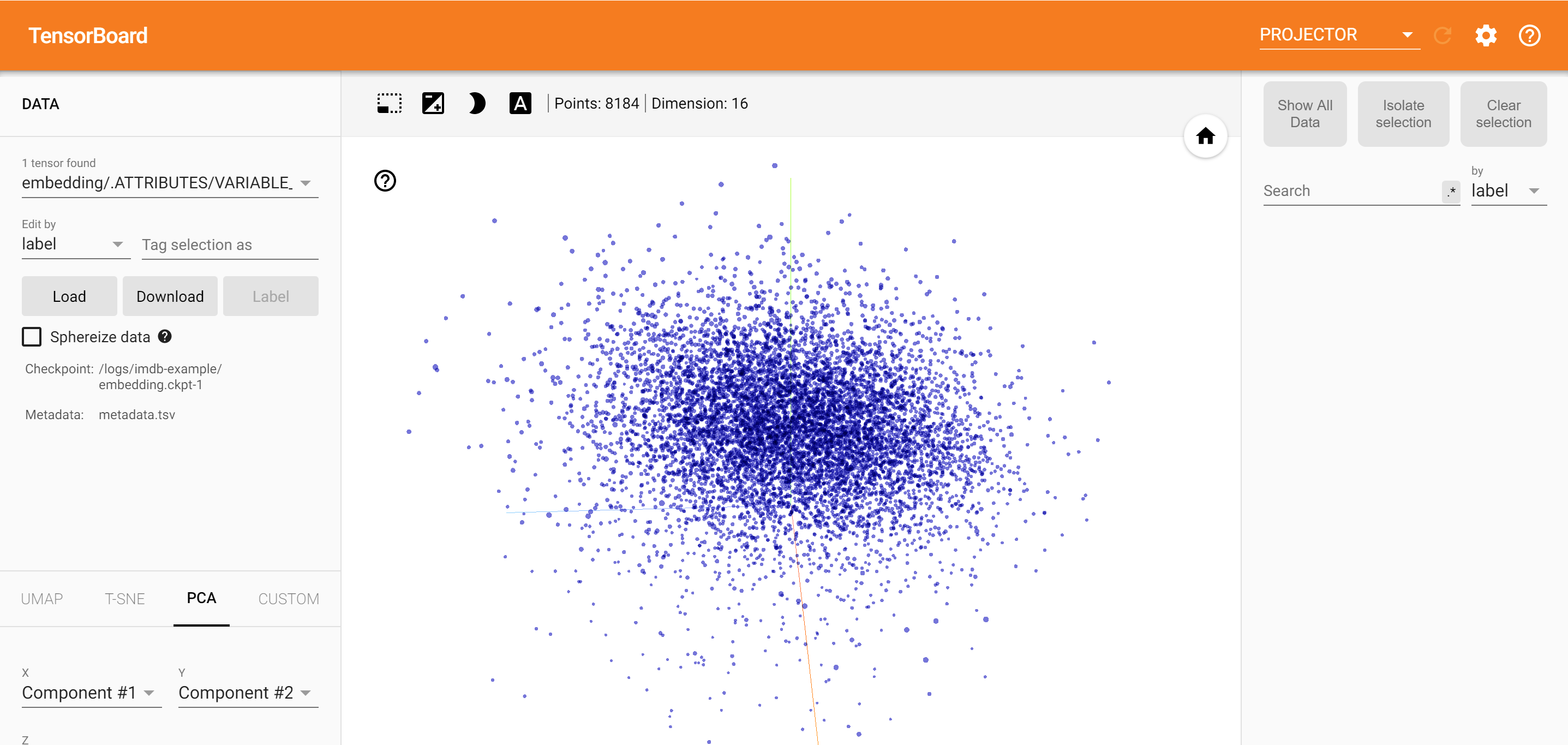
การวิเคราะห์
TensorBoard Projector เป็นเครื่องมือที่ยอดเยี่ยมสำหรับการตีความและการแสดงภาพการฝัง แดชบอร์ดอนุญาตให้ผู้ใช้ค้นหาคำที่เฉพาะเจาะจง และเน้นคำที่อยู่ติดกันในพื้นที่ฝัง (มิติต่ำ) จากตัวอย่างนี้เราจะเห็นว่าเวสแอนเดอร์สันและอัลเฟรดฮิตช์ค็อกมีทั้งแง่ค่อนข้างเป็นกลาง แต่ที่พวกเขามีการอ้างอิงในบริบทที่แตกต่าง
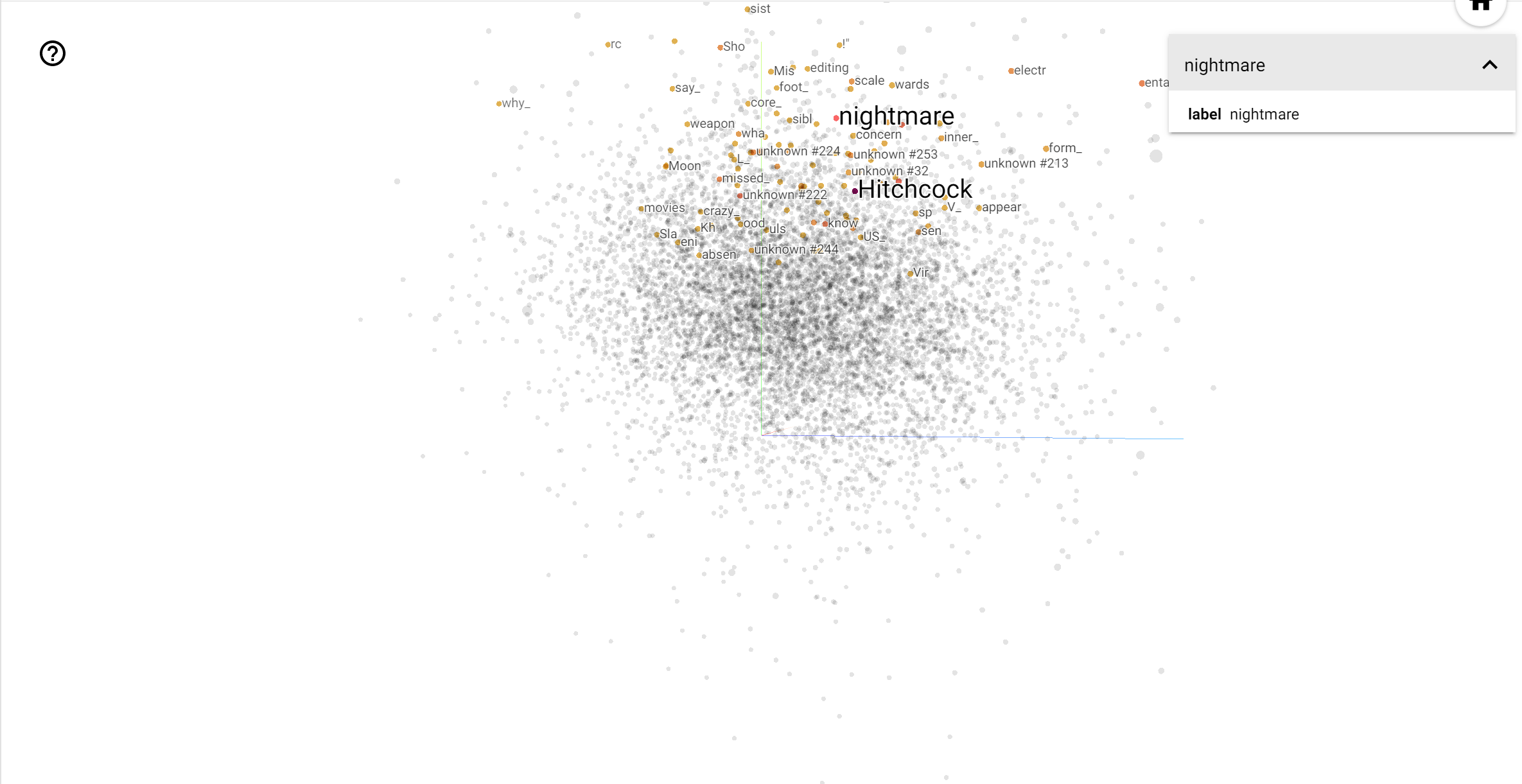
ในพื้นที่นี้ฮิตช์ค็อกเป็นผู้ใกล้ชิดกับคำเหมือน nightmare ที่น่าจะเกิดจากความจริงที่ว่าเขาเป็นที่รู้จักในฐานะ "โทใจจดใจจ่อ" ขณะที่เดอร์สันเป็นผู้ใกล้ชิดกับคำว่า heart ซึ่งมีความสอดคล้องกับรายละเอียดอย่างไม่ลดละและสไตล์ที่อบอุ่นใจของเขา .
