
pengantar
TFX adalah platform machine learning (ML) skala produksi Google berdasarkan TensorFlow. Ini menyediakan kerangka kerja konfigurasi dan pustaka bersama untuk mengintegrasikan komponen umum yang diperlukan untuk menentukan, meluncurkan, dan memantau sistem pembelajaran mesin Anda.
TFX 1.0
Kami dengan senang hati mengumumkan ketersediaan TFX 1.0.0 . Ini adalah rilis pasca-beta awal TFX, yang menyediakan API dan artefak publik yang stabil. Anda dapat yakin bahwa saluran pipa TFX Anda di masa mendatang akan tetap berfungsi setelah peningkatan dalam cakupan kompatibilitas yang ditentukan dalam RFC ini.
Instalasi

![]()
pip install tfx
Paket Malam
TFX juga menyelenggarakan paket malam di https://pypi-nightly.tensorflow.org di Google Cloud. Untuk menginstal paket nightly terbaru, silakan gunakan perintah berikut:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Ini akan menginstal paket malam untuk dependensi utama TFX seperti TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD).
Tentang TFX
TFX adalah platform untuk membangun dan mengelola alur kerja ML di lingkungan produksi. TFX menyediakan yang berikut:
Toolkit untuk membuat pipeline ML. Pipeline TFX memungkinkan Anda mengatur alur kerja ML di beberapa platform, seperti: Apache Airflow, Apache Beam, dan Kubeflow Pipelines.
Kumpulan komponen standar yang dapat Anda gunakan sebagai bagian dari pipeline, atau sebagai bagian dari skrip pelatihan ML Anda. Komponen standar TFX menyediakan fungsionalitas yang telah terbukti untuk membantu Anda mulai membangun proses ML dengan mudah.
Perpustakaan yang menyediakan fungsionalitas dasar untuk banyak komponen standar. Anda dapat menggunakan pustaka TFX untuk menambahkan fungsionalitas ini ke komponen kustom Anda sendiri, atau menggunakannya secara terpisah.
TFX adalah toolkit machine learning skala produksi Google berdasarkan TensorFlow. Ini menyediakan kerangka kerja konfigurasi dan pustaka bersama untuk mengintegrasikan komponen umum yang diperlukan untuk menentukan, meluncurkan, dan memantau sistem pembelajaran mesin Anda.
Komponen Standar TFX
Pipeline TFX adalah urutan komponen yang mengimplementasikan pipeline ML yang dirancang khusus untuk tugas machine learning yang skalabel dan berkinerja tinggi. Itu termasuk pemodelan, pelatihan, penyajian inferensi, dan pengelolaan penerapan ke target online, seluler asli, dan JavaScript.
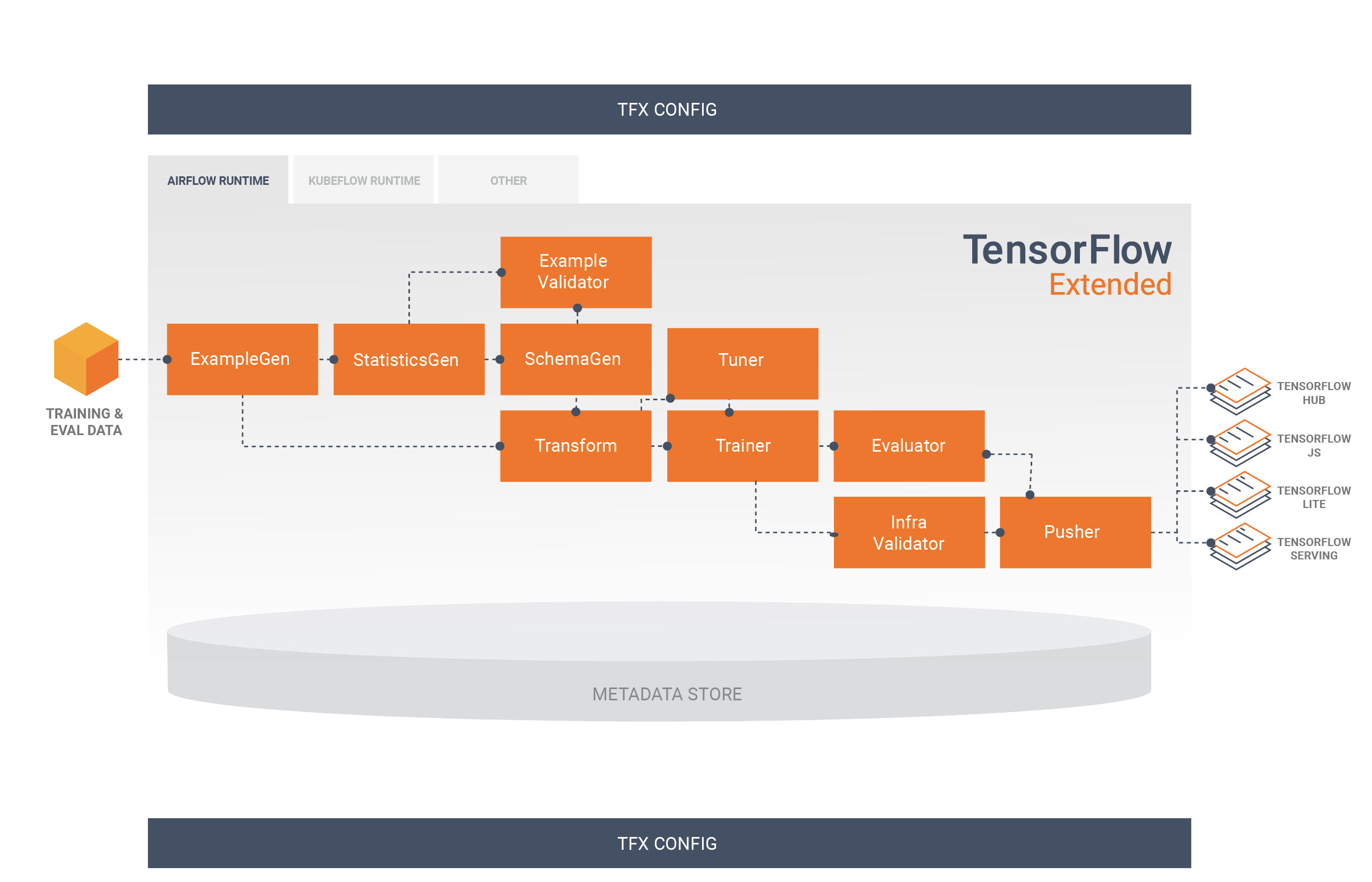
Pipa TFX biasanya mencakup komponen berikut:
ExampleGen adalah komponen input awal dari pipeline yang menyerap dan secara opsional membagi set data input.
StatisticsGen menghitung statistik untuk kumpulan data.
SchemaGen memeriksa statistik dan membuat skema data.
ExampleValidator mencari anomali dan nilai yang hilang dalam kumpulan data.
Transform melakukan rekayasa fitur pada dataset.
Pelatih melatih model.
Tuner menyetel hyperparameters model.
Evaluator melakukan analisis mendalam terhadap hasil pelatihan dan membantu Anda memvalidasi model yang diekspor, memastikan bahwa model tersebut "cukup baik" untuk didorong ke produksi.
InfraValidator memeriksa model benar-benar dapat dilayani dari infrastruktur, dan mencegah model yang buruk didorong.
Pusher menyebarkan model pada infrastruktur penyajian.
BulkInferrer melakukan pemrosesan batch pada model dengan permintaan inferensi yang tidak berlabel.
Diagram ini menggambarkan aliran data antara komponen-komponen ini:
Perpustakaan TFX
TFX mencakup perpustakaan dan komponen pipa. Diagram ini mengilustrasikan hubungan antara library TFX dan komponen pipeline:
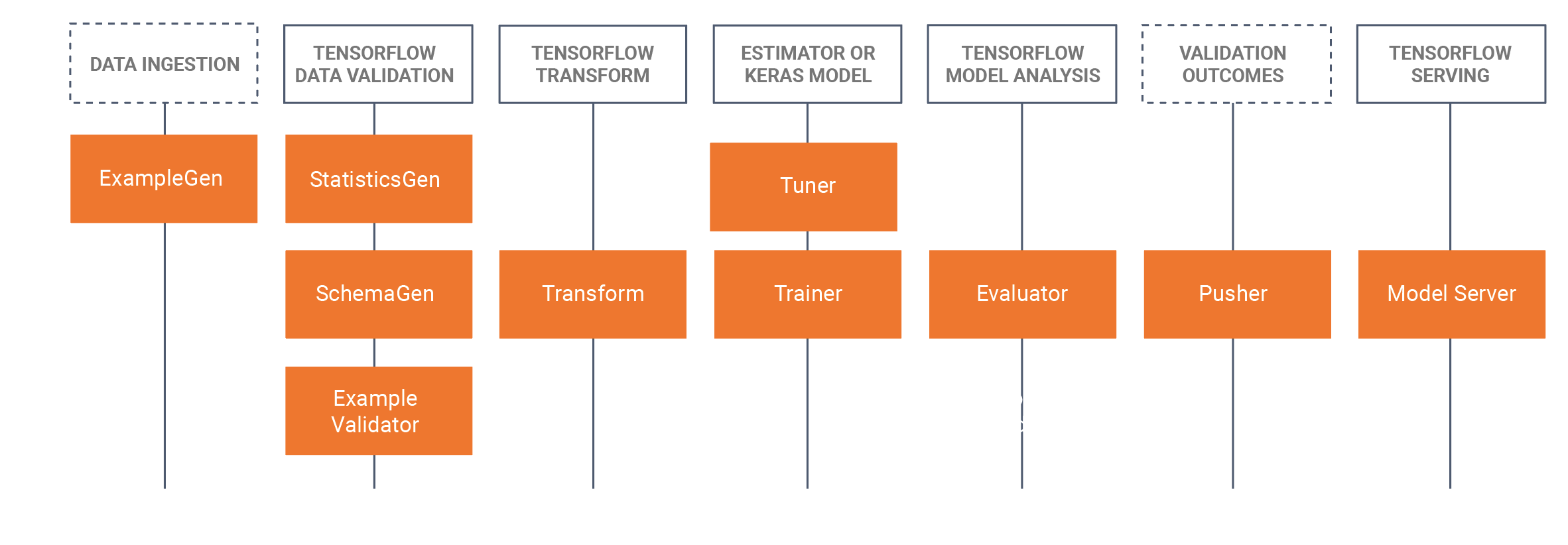
TFX menyediakan beberapa paket Python yang merupakan library yang digunakan untuk membuat komponen pipeline. Anda akan menggunakan pustaka ini untuk membuat komponen saluran Anda sehingga kode Anda bisa fokus pada aspek unik dari saluran Anda.
Pustaka TFX meliputi:
TensorFlow Data Validation (TFDV) adalah library untuk menganalisis dan memvalidasi data machine learning. Ini dirancang agar sangat skalabel dan bekerja dengan baik dengan TensorFlow dan TFX. TFDV termasuk:
- Perhitungan scalable statistik ringkasan pelatihan dan data uji.
- Integrasi dengan penampil untuk distribusi data dan statistik, serta perbandingan segi pasangan set data (Fase).
- Pembuatan skema data otomatis untuk menggambarkan ekspektasi tentang data seperti nilai, rentang, dan kosakata yang diperlukan.
- Penampil skema untuk membantu Anda memeriksa skema.
- Deteksi anomali untuk mengidentifikasi anomali, seperti fitur yang hilang, nilai di luar rentang, atau jenis fitur yang salah, untuk beberapa nama.
- Penampil anomali sehingga Anda dapat melihat fitur apa saja yang memiliki anomali dan mempelajari lebih lanjut untuk memperbaikinya.
TensorFlow Transform (TFT) adalah library untuk prapemrosesan data dengan TensorFlow. TensorFlow Transform berguna untuk data yang memerlukan full-pass, seperti:
- Menormalkan nilai input dengan mean dan standar deviasi.
- Konversi string ke bilangan bulat dengan menghasilkan kosakata di semua nilai input.
- Konversikan float ke integer dengan menetapkannya ke bucket berdasarkan distribusi data yang diamati.
TensorFlow digunakan untuk model pelatihan dengan TFX. Ini menyerap data pelatihan dan kode pemodelan dan membuat hasil SavedModel. Ini juga mengintegrasikan pipeline rekayasa fitur yang dibuat oleh TensorFlow Transform untuk prapemrosesan data input.
KerasTuner digunakan untuk menyetel hyperparameters untuk model.
TensorFlow Model Analysis (TFMA) adalah library untuk mengevaluasi model TensorFlow. Ini digunakan bersama dengan TensorFlow untuk membuat EvalSavedModel, yang menjadi dasar analisisnya. Ini memungkinkan pengguna untuk mengevaluasi model mereka pada sejumlah besar data secara terdistribusi, menggunakan metrik yang sama yang ditentukan dalam pelatih mereka. Metrik ini dapat dihitung melalui potongan data yang berbeda dan divisualisasikan di notebook Jupyter.
TensorFlow Metadata (TFMD) menyediakan representasi standar untuk metadata yang berguna saat melatih model machine learning dengan TensorFlow. Metadata dapat diproduksi dengan tangan atau secara otomatis selama analisis data input, dan dapat digunakan untuk validasi data, eksplorasi, dan transformasi. Format serialisasi metadata meliputi:
- Skema yang menjelaskan data tabular (misalnya, tf.Examples).
- Kumpulan statistik ringkasan atas kumpulan data tersebut.
ML Metadata (MLMD) adalah pustaka untuk merekam dan mengambil metadata yang terkait dengan alur kerja pengembang ML dan ilmuwan data. Paling sering metadata menggunakan representasi TFMD. MLMD mengelola persistensi menggunakan SQL-Lite , MySQL , dan penyimpanan data serupa lainnya.
Teknologi Pendukung
Yg dibutuhkan
- Apache Beam adalah open source, model terpadu untuk mendefinisikan jalur pemrosesan paralel data batch dan streaming. TFX menggunakan Apache Beam untuk mengimplementasikan pipa paralel data. Pipeline kemudian dijalankan oleh salah satu back-end pemrosesan terdistribusi yang didukung Beam, yang meliputi Apache Flink, Apache Spark, Google Cloud Dataflow , dan lainnya.
Opsional
Orchestrator seperti Apache Airflow dan Kubeflow membuat konfigurasi, pengoperasian, pemantauan, dan pemeliharaan pipeline ML menjadi lebih mudah.
Apache Airflow adalah platform untuk menulis, menjadwalkan, dan memantau alur kerja secara terprogram. TFX menggunakan Airflow untuk membuat alur kerja sebagai grafik asiklik terarah (DAG) tugas. Penjadwal Airflow menjalankan tugas pada larik pekerja sambil mengikuti dependensi yang ditentukan. Utilitas baris perintah yang kaya membuat operasi kompleks pada DAG menjadi mudah. Antarmuka pengguna yang kaya memudahkan untuk memvisualisasikan pipeline yang berjalan dalam produksi, memantau kemajuan, dan memecahkan masalah saat diperlukan. Saat alur kerja didefinisikan sebagai kode, alur kerja menjadi lebih dapat dipelihara, dapat dibuat versi, dapat diuji, dan kolaboratif.
Kubeflow didedikasikan untuk membuat penerapan alur kerja pembelajaran mesin (ML) di Kubernetes menjadi sederhana, portabel, dan skalabel. Tujuan Kubeflow bukan untuk membuat ulang layanan lain, tetapi menyediakan cara langsung untuk menerapkan sistem sumber terbuka terbaik untuk ML ke berbagai infrastruktur. Kubeflow Pipelines memungkinkan komposisi dan eksekusi alur kerja yang dapat direproduksi di Kubeflow, terintegrasi dengan eksperimen dan pengalaman berbasis notebook. Layanan Kubeflow Pipelines di Kubernetes mencakup penyimpanan Metadata yang dihosting, mesin orkestrasi berbasis container, server notebook, dan UI untuk membantu pengguna mengembangkan, menjalankan, dan mengelola pipeline ML kompleks dalam skala besar. Kubeflow Pipelines SDK memungkinkan pembuatan dan berbagi komponen dan komposisi pipeline secara terprogram.
Portabilitas dan Interoperabilitas
TFX dirancang agar portabel untuk berbagai lingkungan dan kerangka kerja orkestrasi, termasuk Apache Airflow , Apache Beam dan Kubeflow . Ini juga portabel untuk berbagai platform komputasi, termasuk di tempat, dan platform cloud seperti Google Cloud Platform (GCP) . Secara khusus, TFX bekerja sama dengan layanan GCP terkelola server, seperti Cloud AI Platform for Training and Prediction , dan Cloud Dataflow untuk pemrosesan data terdistribusi untuk beberapa aspek lain dari siklus hidup ML.
Model vs. Model Tersimpan
Model
Sebuah model adalah output dari proses pelatihan. Ini adalah catatan serial dari bobot yang telah dipelajari selama proses pelatihan. Bobot ini selanjutnya dapat digunakan untuk menghitung prediksi untuk contoh input baru. Untuk TFX dan TensorFlow, 'model' mengacu pada pos pemeriksaan yang berisi bobot yang dipelajari hingga saat itu.
Perhatikan bahwa 'model' mungkin juga merujuk pada definisi grafik komputasi TensorFlow (yaitu file Python) yang menyatakan bagaimana prediksi akan dihitung. Kedua pengertian tersebut dapat digunakan secara bergantian berdasarkan konteks.
Model Tersimpan
- Apa itu SavedModel : serialisasi universal, netral bahasa, hermetis, dan dapat dipulihkan dari model TensorFlow.
- Mengapa penting : Ini memungkinkan sistem tingkat yang lebih tinggi untuk memproduksi, mengubah, dan menggunakan model TensorFlow menggunakan satu abstraksi.
SavedModel adalah format serialisasi yang direkomendasikan untuk menyajikan model TensorFlow dalam produksi, atau mengekspor model terlatih untuk aplikasi seluler atau JavaScript asli. Misalnya, untuk mengubah model menjadi layanan REST untuk membuat prediksi, Anda dapat membuat serial model sebagai SavedModel dan menyajikannya menggunakan TensorFlow Serving. Lihat Melayani Model TensorFlow untuk informasi selengkapnya.
Skema
Beberapa komponen TFX menggunakan deskripsi data input Anda yang disebut skema . Skema adalah turunan dari schema.proto . Skema adalah jenis buffer protokol , lebih dikenal sebagai "protobuf". Skema dapat menentukan tipe data untuk nilai fitur, apakah fitur harus ada di semua contoh, rentang nilai yang diizinkan, dan properti lainnya. Salah satu manfaat menggunakan TensorFlow Data Validation (TFDV) adalah akan secara otomatis menghasilkan skema dengan menyimpulkan jenis, kategori, dan rentang dari data pelatihan.
Berikut kutipan dari protobuf skema:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Komponen berikut menggunakan skema:
- Validasi Data TensorFlow
- Transformasi TensorFlow
Dalam pipeline TFX, Validasi Data TensorFlow menghasilkan skema, yang digunakan oleh komponen lain.
Berkembang bersama TFX
TFX menyediakan platform yang kuat untuk setiap fase proyek pembelajaran mesin, mulai dari penelitian, eksperimen, dan pengembangan di mesin lokal Anda, hingga penerapan. Untuk menghindari duplikasi kode dan menghilangkan potensi kemiringan pelatihan/penyajian , sangat disarankan untuk menerapkan saluran TFX Anda untuk pelatihan model dan penerapan model terlatih, dan menggunakan komponen Transform yang memanfaatkan perpustakaan Transform TensorFlow untuk pelatihan dan inferensi. Dengan melakukannya, Anda akan menggunakan kode prapemrosesan dan analisis yang sama secara konsisten, dan menghindari perbedaan antara data yang digunakan untuk pelatihan dan data yang diumpankan ke model terlatih Anda dalam produksi, serta mendapat manfaat dari menulis kode itu sekali.
Eksplorasi, Visualisasi, dan Pembersihan Data
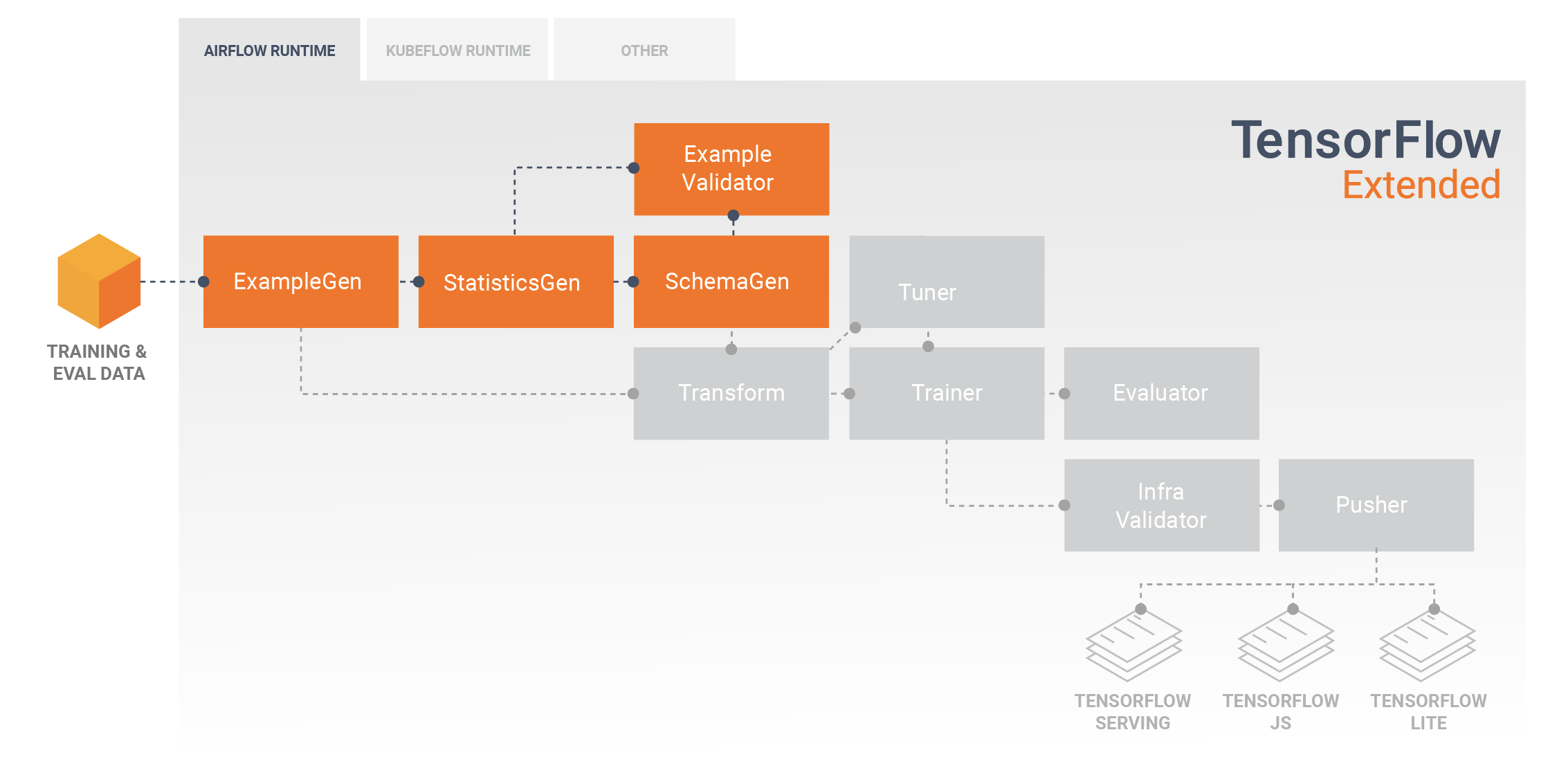
Pipeline TFX biasanya dimulai dengan komponen ExampleGen , yang menerima data input dan memformatnya sebagai tf.Examples. Seringkali ini dilakukan setelah data dipecah menjadi set data pelatihan dan evaluasi sehingga sebenarnya ada dua salinan komponen ExampleGen, masing-masing untuk pelatihan dan evaluasi. Ini biasanya diikuti oleh komponen StatisticsGen dan komponen SchemaGen , yang akan memeriksa data Anda dan menyimpulkan skema data dan statistik. Skema dan statistik akan digunakan oleh komponen ExampleValidator , yang akan mencari anomali, nilai yang hilang, dan tipe data yang salah dalam data Anda. Semua komponen ini memanfaatkan kemampuan library Validasi Data TensorFlow .
TensorFlow Data Validation (TFDV) adalah alat yang berharga saat melakukan eksplorasi awal, visualisasi, dan pembersihan set data Anda. TFDV memeriksa data Anda dan menyimpulkan tipe data, kategori, dan rentang, lalu secara otomatis membantu mengidentifikasi anomali dan nilai yang hilang. Ini juga menyediakan alat visualisasi yang dapat membantu Anda memeriksa dan memahami kumpulan data Anda. Setelah pipeline Anda selesai, Anda dapat membaca metadata dari MLMD dan menggunakan alat visualisasi TFDV di notebook Jupyter untuk menganalisis data Anda.
Setelah pelatihan dan penerapan model awal Anda, TFDV dapat digunakan untuk memantau data baru dari permintaan inferensi ke model yang Anda terapkan, dan mencari anomali dan/atau penyimpangan. Ini sangat berguna untuk data deret waktu yang berubah dari waktu ke waktu sebagai akibat dari tren atau musim, dan dapat membantu menginformasikan ketika ada masalah data atau ketika model perlu dilatih ulang pada data baru.
Visualisasi data
Setelah Anda menyelesaikan menjalankan pertama data Anda melalui bagian pipa Anda yang menggunakan TFDV (biasanya StatisticsGen, SchemaGen, dan ExampleValidator), Anda dapat memvisualisasikan hasilnya dalam notebook gaya Jupyter. Untuk proses tambahan, Anda dapat membandingkan hasil ini saat melakukan penyesuaian, hingga data Anda optimal untuk model dan aplikasi Anda.
Anda akan terlebih dahulu meminta ML Metadata (MLMD) untuk menemukan hasil eksekusi komponen ini, lalu menggunakan API dukungan visualisasi di TFDV untuk membuat visualisasi di buku catatan Anda. Ini termasuk tfdv.load_statistics() dan tfdv.visualize_statistics() Dengan menggunakan visualisasi ini, Anda dapat lebih memahami karakteristik kumpulan data Anda, dan jika perlu, modifikasi sesuai kebutuhan.
Mengembangkan dan Melatih Model
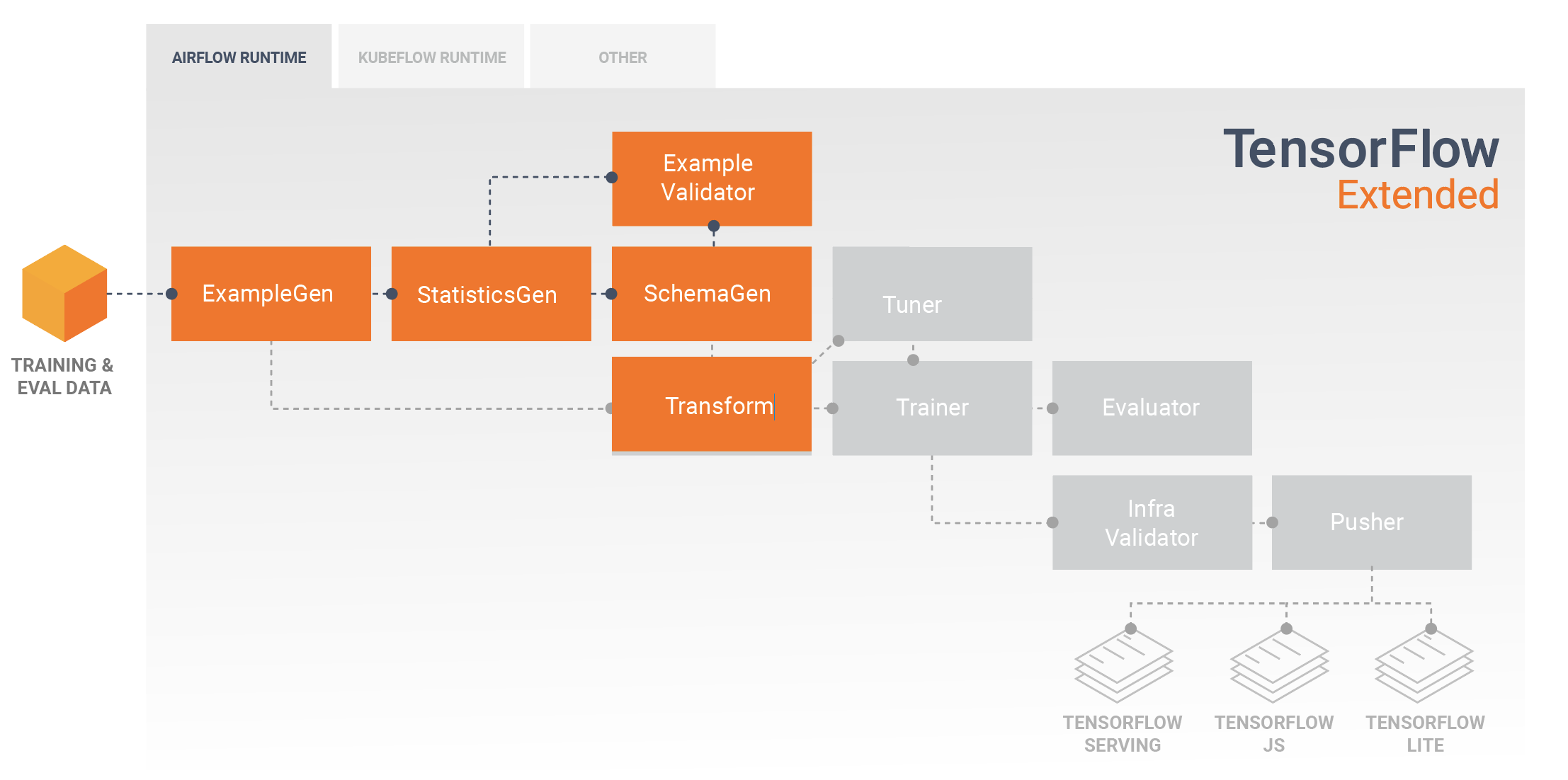
Pipeline TFX tipikal akan menyertakan komponen Transform , yang akan melakukan rekayasa fitur dengan memanfaatkan kemampuan library TensorFlow Transform (TFT) . Komponen Transform menggunakan skema yang dibuat oleh komponen SchemaGen, dan menerapkan transformasi data untuk membuat, menggabungkan, dan mengubah fitur yang akan digunakan untuk melatih model Anda. Pembersihan nilai yang hilang dan konversi tipe juga harus dilakukan di komponen Transform jika ada kemungkinan bahwa ini juga akan ada dalam data yang dikirim untuk permintaan inferensi. Ada beberapa pertimbangan penting saat merancang kode TensorFlow untuk pelatihan di TFX.
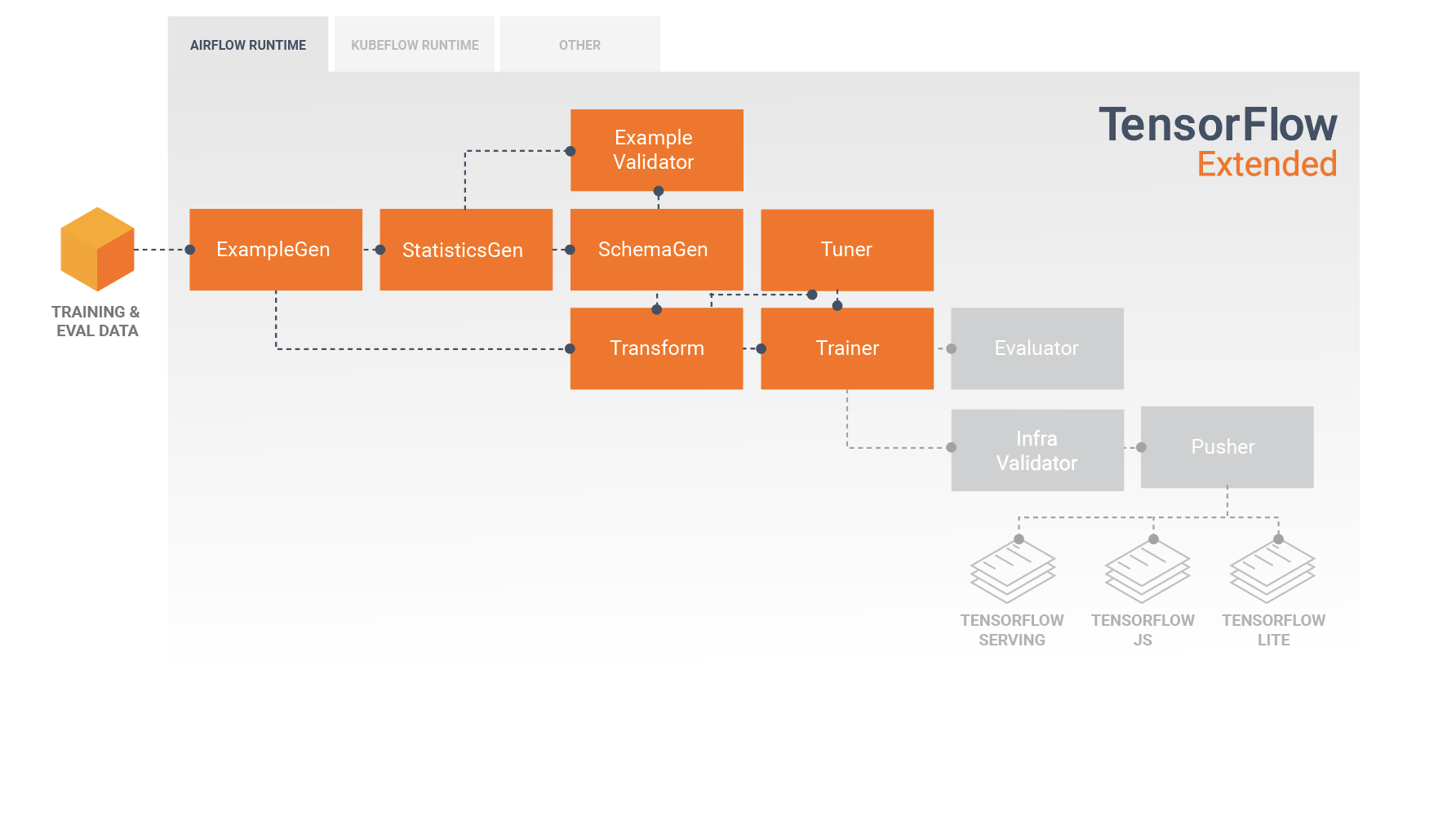
Hasil dari komponen Transform adalah SavedModel yang akan diimpor dan digunakan dalam kode pemodelan Anda di TensorFlow, selama komponen Trainer . SavedModel ini mencakup semua transformasi rekayasa data yang dibuat dalam komponen Transform, sehingga transformasi identik dilakukan menggunakan kode yang sama persis selama pelatihan dan inferensi. Dengan menggunakan kode pemodelan, termasuk SavedModel dari komponen Transform, Anda dapat menggunakan data pelatihan dan evaluasi serta melatih model Anda.
Saat bekerja dengan model berbasis Estimator, bagian terakhir dari kode pemodelan Anda harus menyimpan model Anda sebagai SavedModel dan EvalSavedModel. Menyimpan sebagai EvalSavedModel memastikan metrik yang digunakan pada waktu pelatihan juga tersedia selama evaluasi (perhatikan bahwa ini tidak diperlukan untuk model berbasis keras). Menyimpan EvalSavedModel mengharuskan Anda mengimpor library TensorFlow Model Analysis (TFMA) di komponen Trainer Anda.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Komponen Tuner opsional dapat ditambahkan sebelum Pelatih untuk menyetel hyperparameter (misalnya, jumlah lapisan) untuk model. Dengan model dan ruang pencarian hyperparameter yang diberikan, algoritma tuning akan menemukan hyperparameter terbaik berdasarkan tujuannya.
Menganalisis dan Memahami Kinerja Model
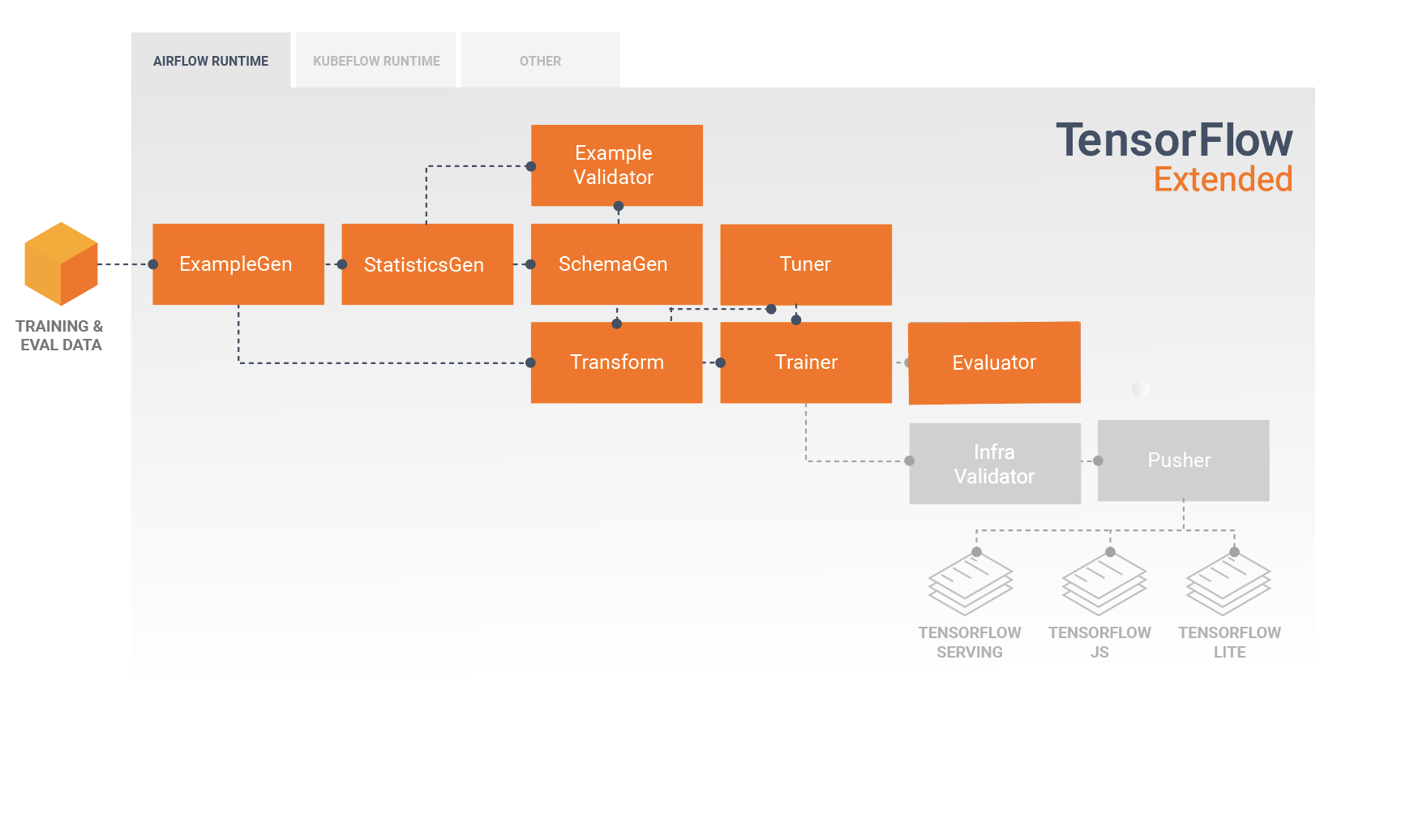
Setelah pengembangan dan pelatihan model awal, penting untuk menganalisis dan benar-benar memahami kinerja model Anda. Pipeline TFX tipikal akan menyertakan komponen Evaluator , yang memanfaatkan kemampuan library TensorFlow Model Analysis (TFMA) , yang menyediakan perangkat daya untuk fase pengembangan ini. Komponen Evaluator menggunakan model yang Anda ekspor di atas, dan memungkinkan Anda menentukan daftar tfma.SlicingSpec yang dapat Anda gunakan saat memvisualisasikan dan menganalisis kinerja model Anda. Setiap SlicingSpec mendefinisikan sepotong data pelatihan Anda yang ingin Anda periksa, seperti kategori tertentu untuk fitur kategoris, atau rentang tertentu untuk fitur numerik.
Misalnya, ini penting untuk mencoba memahami kinerja model Anda untuk berbagai segmen pelanggan Anda, yang dapat disegmentasikan menurut pembelian tahunan, data geografis, kelompok usia, atau jenis kelamin. Ini bisa menjadi sangat penting untuk kumpulan data dengan ekor panjang, di mana kinerja kelompok dominan dapat menutupi kinerja yang tidak dapat diterima untuk kelompok penting namun lebih kecil. Misalnya, model Anda mungkin berkinerja baik untuk karyawan rata-rata tetapi gagal total untuk staf eksekutif, dan mungkin penting bagi Anda untuk mengetahuinya.
Analisis dan Visualisasi Model
Setelah Anda menyelesaikan proses pertama data Anda melalui pelatihan model Anda dan menjalankan komponen Evaluator (yang memanfaatkan TFMA ) pada hasil pelatihan, Anda dapat memvisualisasikan hasilnya dalam notebook gaya Jupyter. Untuk proses tambahan, Anda dapat membandingkan hasil ini saat melakukan penyesuaian, hingga hasilnya optimal untuk model dan aplikasi Anda.
Anda akan terlebih dahulu meminta ML Metadata (MLMD) untuk menemukan hasil eksekusi komponen ini, lalu menggunakan API dukungan visualisasi di TFMA untuk membuat visualisasi di buku catatan Anda. Ini termasuk tfma.load_eval_results dan tfma.view.render_slicing_metrics Dengan menggunakan visualisasi ini, Anda dapat lebih memahami karakteristik model Anda, dan jika perlu, modifikasi sesuai kebutuhan.
Memvalidasi Kinerja Model
Sebagai bagian dari menganalisis kinerja model, Anda mungkin ingin memvalidasi kinerja terhadap garis dasar (seperti model yang sedang ditayangkan). Validasi model dilakukan dengan melewatkan model kandidat dan baseline ke komponen Evaluator . Evaluator menghitung metrik (misalnya AUC, kerugian) untuk kandidat dan baseline bersama dengan serangkaian metrik berbeda yang sesuai. Ambang batas kemudian dapat diterapkan dan digunakan untuk mendorong model Anda ke produksi.
Memvalidasi Bahwa Model Dapat Dilayani
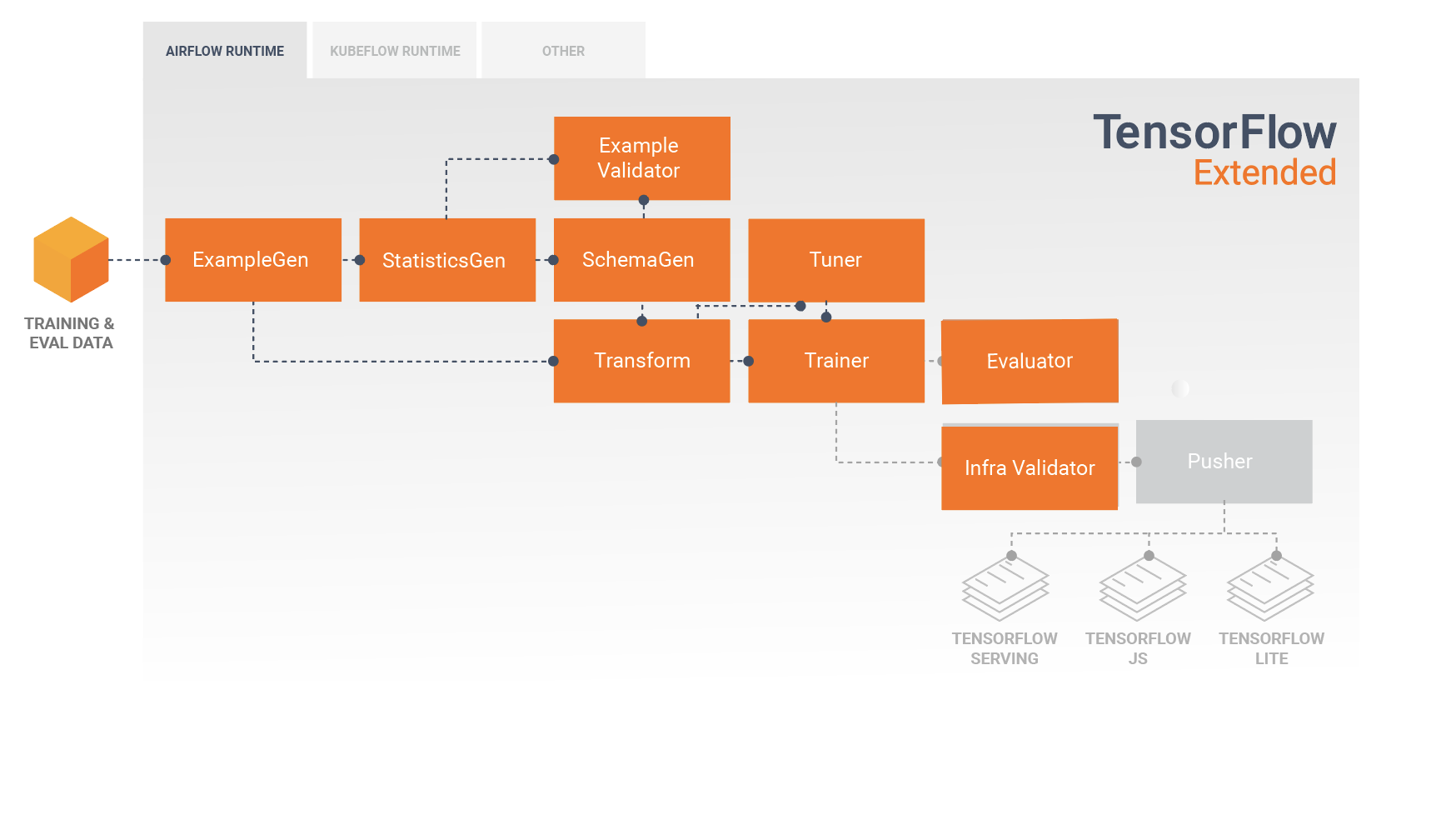
Sebelum menerapkan model terlatih, Anda mungkin ingin memvalidasi apakah model tersebut benar-benar dapat ditayangkan dalam infrastruktur penyajian. Ini sangat penting dalam lingkungan produksi untuk memastikan bahwa model yang baru diterbitkan tidak mencegah sistem menyajikan prediksi. Komponen InfraValidator akan membuat penerapan canary model Anda di lingkungan kotak pasir, dan secara opsional mengirim permintaan nyata untuk memeriksa apakah model Anda berfungsi dengan benar.
Target Penerapan
Setelah Anda mengembangkan dan melatih model yang Anda sukai, sekarang saatnya untuk menerapkannya ke satu atau beberapa target penerapan di mana ia akan menerima permintaan inferensi. TFX mendukung penerapan ke tiga kelas target penerapan. Model terlatih yang telah diekspor sebagai SavedModels dapat diterapkan ke salah satu atau semua target penerapan ini.
Inferensi: Penayangan TensorFlow
TensorFlow Serving (TFS) adalah sistem penyajian yang fleksibel dan berkinerja tinggi untuk model pembelajaran mesin, yang dirancang untuk lingkungan produksi. Ini menggunakan SavedModel dan akan menerima permintaan inferensi melalui antarmuka REST atau gRPC. Ini berjalan sebagai satu set proses pada satu atau lebih server jaringan, menggunakan salah satu dari beberapa arsitektur canggih untuk menangani sinkronisasi dan komputasi terdistribusi. Lihat dokumentasi TFS untuk informasi lebih lanjut tentang pengembangan dan penerapan solusi TFS.
Dalam pipeline tipikal, SavedModel yang telah dilatih dalam komponen Trainer pertama-tama akan divalidasi infra dalam komponen InfraValidator . InfraValidator meluncurkan server model TFS canary untuk benar-benar melayani SavedModel. Jika validasi telah berlalu, komponen Pusher akhirnya akan menyebarkan SavedModel ke infrastruktur TFS Anda. Ini termasuk menangani beberapa versi dan pembaruan model.
Inferensi dalam Aplikasi Seluler dan IoT Asli: TensorFlow Lite
TensorFlow Lite adalah seperangkat alat yang didedikasikan untuk membantu pengembang menggunakan Model TensorFlow terlatih mereka dalam aplikasi seluler dan IoT asli. Ini menggunakan SavedModels yang sama dengan TensorFlow Serving, dan menerapkan pengoptimalan seperti kuantisasi dan pemangkasan untuk mengoptimalkan ukuran dan kinerja model yang dihasilkan untuk tantangan berjalan di perangkat seluler dan IoT. Lihat dokumentasi TensorFlow Lite untuk informasi selengkapnya tentang penggunaan TensorFlow Lite.
Inferensi dalam JavaScript: TensorFlow JS
TensorFlow JS adalah library JavaScript untuk melatih dan menerapkan model ML di browser dan di Node.js. Ini menggunakan SavedModels yang sama dengan TensorFlow Serving dan TensorFlow Lite, dan mengonversinya ke format Web TensorFlow.js. Lihat dokumentasi TensorFlow JS untuk detail selengkapnya tentang penggunaan TensorFlow JS.
Membuat Pipa TFX Dengan Aliran Udara
Periksa bengkel aliran udara untuk detailnya
Membuat Pipeline TFX Dengan Kubeflow
Mempersiapkan
Kubeflow memerlukan cluster Kubernetes untuk menjalankan pipeline dalam skala besar. Lihat panduan penerapan Kubeflow yang memandu opsi untuk menerapkan cluster Kubeflow.
Konfigurasikan dan jalankan pipa TFX
Ikuti tutorial TFX di Cloud AI Platform Pipeline untuk menjalankan contoh pipeline TFX di Kubeflow. Komponen TFX telah ditampung untuk menyusun pipeline Kubeflow dan sampel menggambarkan kemampuan untuk mengonfigurasi pipeline untuk membaca kumpulan data publik yang besar dan menjalankan pelatihan dan langkah-langkah pemrosesan data dalam skala besar di cloud.
Antarmuka baris perintah untuk tindakan pipa
TFX menyediakan CLI terpadu yang membantu melakukan berbagai tindakan pipeline seperti membuat, memperbarui, menjalankan, membuat daftar, dan menghapus pipeline di berbagai orkestra termasuk Apache Airflow, Apache Beam, dan Kubeflow. Untuk detailnya, ikuti petunjuk ini .