
پس از استقرار TensorFlow Serving و صدور درخواستها از مشتری خود، ممکن است متوجه شوید که درخواستها بیشتر از آنچه انتظار داشتید طول میکشد یا به توان عملیاتی که میخواهید دست نمییابید.
در این راهنما، ما از TensorBoard's Profiler استفاده میکنیم، که میتوانید از قبل برای آموزش مدل نمایه استفاده کنید، تا درخواستهای استنتاج را ردیابی کنیم تا به ما در رفع اشکال و بهبود عملکرد استنتاج کمک کند.
شما باید از این راهنما همراه با بهترین روشهای ذکر شده در راهنمای عملکرد برای بهینهسازی مدل، درخواستها و نمونه سرویس TensorFlow استفاده کنید.
نمای کلی
در سطح بالایی، ابزار Profiling TensorBoard را به سرور gRPC TensorFlow Serving اشاره خواهیم کرد. هنگامی که یک درخواست استنتاج به Tensorflow Serving ارسال می کنیم، به طور همزمان از TensorBoard UI نیز استفاده می کنیم تا از آن بخواهیم ردپای این درخواست را بگیرد. در پشت صحنه، TensorBoard با TensorFlow Serving از طریق gRPC صحبت میکند و از آن میخواهد ردیابی دقیقی از طول عمر درخواست استنتاج ارائه دهد. سپس TensorBoard فعالیت هر رشته را در هر دستگاه محاسباتی (کد در حال اجرا یکپارچه شده با profiler::TraceMe ) در طول طول عمر درخواست در رابط کاربری TensorBoard برای مصرف ما تجسم می کند.
پیش نیازها
-
Tensorflow>=2.0.0 - TensorBoard (اگر TF از طریق
pipنصب شده باشد باید نصب شود) - داکر (که از آن برای دانلود و اجرای سرویس TF>=2.1.0 تصویر استفاده خواهیم کرد)
استقرار مدل با سرویس TensorFlow
برای این مثال، ما از Docker، روش پیشنهادی برای استقرار Tensorflow Serving، برای میزبانی از یک مدل اسباببازی استفاده میکنیم که f(x) = x / 2 + 2 موجود در مخزن Tensorflow Serving Github را محاسبه میکند.
منبع سرویس TensorFlow را دانلود کنید.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
سرویس TensorFlow را از طریق Docker راه اندازی کنید و مدل half_plus_two را اجرا کنید.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
در ترمینال دیگر، مدل را پرس و جو کنید تا مطمئن شوید که مدل به درستی مستقر شده است
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
پروفایل TensorBoard را تنظیم کنید
در یک ترمینال دیگر، ابزار TensorBoard را بر روی دستگاه خود راه اندازی کنید و فهرستی را برای ذخیره رویدادهای ردیابی استنتاج در دستگاه خود ارائه دهید:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
برای مشاهده رابط کاربری TensorBoard به http://localhost:6006/ بروید. از منوی کشویی در بالا برای رفتن به تب Profile استفاده کنید. روی Capture Profile کلیک کنید و آدرس سرور gRPC Tensorflow Serving را ارائه دهید.
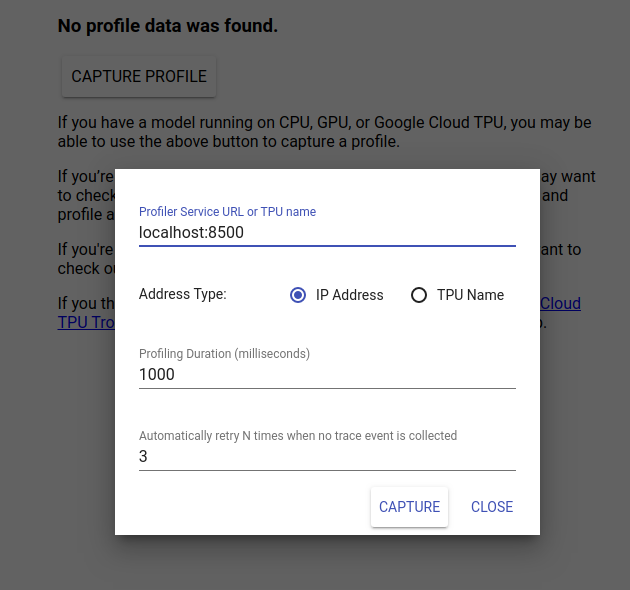
به محض اینکه "Capture" را فشار دهید، TensorBoard شروع به ارسال درخواست های پروفایل به سرور مدل می کند. در گفتگوی بالا، میتوانید هم مهلت هر درخواست و هم تعداد کل دفعاتی را که Tensorboard دوباره امتحان میکند، در صورتی که هیچ رویداد ردیابی جمعآوری نشود، تعیین کنید. اگر در حال ایجاد پروفایل یک مدل گران قیمت هستید، ممکن است بخواهید مهلت را افزایش دهید تا مطمئن شوید که درخواست نمایه قبل از تکمیل درخواست استنتاج به پایان نمی رسد.
ارسال و نمایه یک درخواست استنباط
Capture را در رابط کاربری TensorBoard فشار دهید و پس از آن سریعاً یک درخواست استنتاج به سرویس TF ارسال کنید.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
شما باید یک "عکس نمایه با موفقیت را ببینید. لطفاً بازخوانی کنید." نان تست در پایین صفحه نمایش داده می شود. این بدان معناست که TensorBoard توانست ردیابی رویدادها را از سرویس TensorFlow بازیابی کند و آنها را در logdir شما ذخیره کند. صفحه را بازخوانی کنید تا درخواست استنتاج را با نمایشگر ردیابی The Profiler تجسم کنید، همانطور که در بخش بعدی مشاهده می شود.
ردیابی درخواست استنتاج را تجزیه و تحلیل کنید

اکنون می توانید به راحتی ببینید که در نتیجه درخواست استنتاج شما چه محاسباتی در حال انجام است. برای دریافت اطلاعات بیشتر مانند زمان دقیق شروع و مدت زمان دیوار، می توانید روی هر یک از مستطیل ها (رویدادهای ردیابی) زوم کرده و کلیک کنید.
در سطح بالا، ما دو رشته را می بینیم که به زمان اجرا TensorFlow و سومی متعلق به سرور REST است که دریافت درخواست HTTP را مدیریت می کند و یک جلسه TensorFlow ایجاد می کند.
ما می توانیم بزرگنمایی کنیم تا ببینیم در SessionRun چه اتفاقی می افتد.

در رشته دوم، یک ExecutorState::Process اولیه را مشاهده می کنیم که در آن هیچ عملیات تنسور فلو اجرا نمی شود، اما مراحل اولیه سازی اجرا می شود.
در رشته اول، فراخوانی برای خواندن متغیر اول را می بینیم و زمانی که متغیر دوم نیز در دسترس باشد، ضرب و جمع هسته ها را به ترتیب اجرا می کند. در نهایت، Executor سیگنال می دهد که محاسبه آن با فراخوانی DoneCallback انجام می شود و Session می تواند بسته شود.
مراحل بعدی
در حالی که این یک مثال ساده است، میتوانید از همان فرآیند برای نمایه کردن مدلهای بسیار پیچیدهتر استفاده کنید، و به شما این امکان را میدهد تا عملیات کند یا تنگناها را در معماری مدل خود شناسایی کنید تا عملکرد آن را بهبود بخشید.
لطفاً برای آموزش کامل تر در مورد ویژگی های TensorBoard's Profiler و TensorFlow Serving Performance Guide به راهنمای TensorBoard Profiler مراجعه کنید تا درباره بهینه سازی عملکرد استنتاج بیشتر بدانید.