
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي كيفية المعالجة المسبقة لملفات الصوت بتنسيق WAV وإنشاء نموذج أساسي للتعرف التلقائي على الكلام (ASR) وتدريبه للتعرف على عشر كلمات مختلفة. ستستخدم جزءًا من مجموعة بيانات أوامر الكلام ( Warden ، 2018 ) ، والتي تحتوي على مقاطع صوتية قصيرة (ثانية واحدة أو أقل) للأوامر ، مثل "down" ، "go" ، "left" ، "no" ، " صحيح "،" توقف "،" أعلى "و" نعم ".
تعد أنظمة التعرف على الكلام والصوت في العالم الحقيقي معقدة. ولكن ، مثل تصنيف الصور باستخدام مجموعة بيانات MNIST ، يجب أن يمنحك هذا البرنامج التعليمي فهمًا أساسيًا للتقنيات المستخدمة.
يثبت
استيراد الوحدات والتبعيات الضرورية. لاحظ أنك ستستخدم seaborn للتخيل في هذا البرنامج التعليمي.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
قم باستيراد مجموعة بيانات أوامر الكلام المصغرة
لتوفير الوقت مع تحميل البيانات ، ستعمل باستخدام إصدار أصغر من مجموعة بيانات أوامر الكلام. تتكون مجموعة البيانات الأصلية من أكثر من 105000 ملف صوتي بتنسيق ملف الصوت WAV (Waveform) للأشخاص الذين يقولون 35 كلمة مختلفة. تم جمع هذه البيانات بواسطة Google وتم إصدارها بموجب ترخيص CC BY.
قم بتنزيل واستخراج ملف mini_speech_commands.zip الذي يحتوي على مجموعات بيانات أوامر الكلام الأصغر باستخدام tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
يتم تخزين المقاطع الصوتية لمجموعة البيانات في ثمانية مجلدات تتوافق مع كل أمر حديث: no ، yes ، down ، go ، left ، up ، right ، stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
استخرج المقاطع الصوتية في قائمة تسمى filenames ، وقم بترتيبها عشوائيًا:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
قسّم filenames إلى مجموعات تدريب وتحقق واختبار باستخدام نسبة 80:10:10 ، على التوالي:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
اقرأ الملفات الصوتية وتسمياتها
في هذا القسم ، ستقوم بمعالجة مجموعة البيانات مسبقًا ، مما يؤدي إلى إنشاء موترات مفكوكة لأشكال الموجة والتسميات المقابلة. لاحظ أن:
- يحتوي كل ملف WAV على بيانات سلاسل زمنية مع عدد محدد من العينات في الثانية.
- تمثل كل عينة سعة الإشارة الصوتية في ذلك الوقت المحدد.
- في نظام 16 بت ، مثل ملفات WAV في مجموعة بيانات أوامر الكلام المصغرة ، تتراوح قيم السعة من -32768 إلى 32767.
- معدل العينة لمجموعة البيانات هذه هو 16 كيلو هرتز.
شكل الموتر الناتج عن tf.audio.decode_wav هو [samples, channels] ، حيث تكون channels 1 للأحادية أو 2 للستيريو. تحتوي مجموعة بيانات أوامر الكلام المصغرة على تسجيلات أحادية فقط.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
الآن ، دعنا نحدد وظيفة تعالج ملفات الصوت WAV الأولية لمجموعة البيانات في موترات صوتية:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
حدد وظيفة تنشئ تسميات باستخدام الدلائل الأصلية لكل ملف:
- قسّم مسارات الملف إلى
tf.RaggedTensors (موترات ذات أبعاد خشنة - مع شرائح قد يكون لها أطوال مختلفة).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
حدد وظيفة مساعدة أخرى - get_waveform_and_label - تجمع كل ذلك معًا:
- الإدخال هو اسم ملف صوت WAV.
- الإخراج عبارة عن مجموعة تحتوي على موترات الصوت والتسمية الجاهزة للتعلم تحت الإشراف.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
قم ببناء مجموعة التدريب لاستخراج أزواج التسمية الصوتية:
- قم بإنشاء
tf.data.DatasetباستخدامDataset.from_tensor_slicesوDataset.map، باستخدامget_waveform_and_labelالمعرفة مسبقًا.
ستنشئ مجموعات التحقق والاختبار باستخدام إجراء مماثل لاحقًا.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
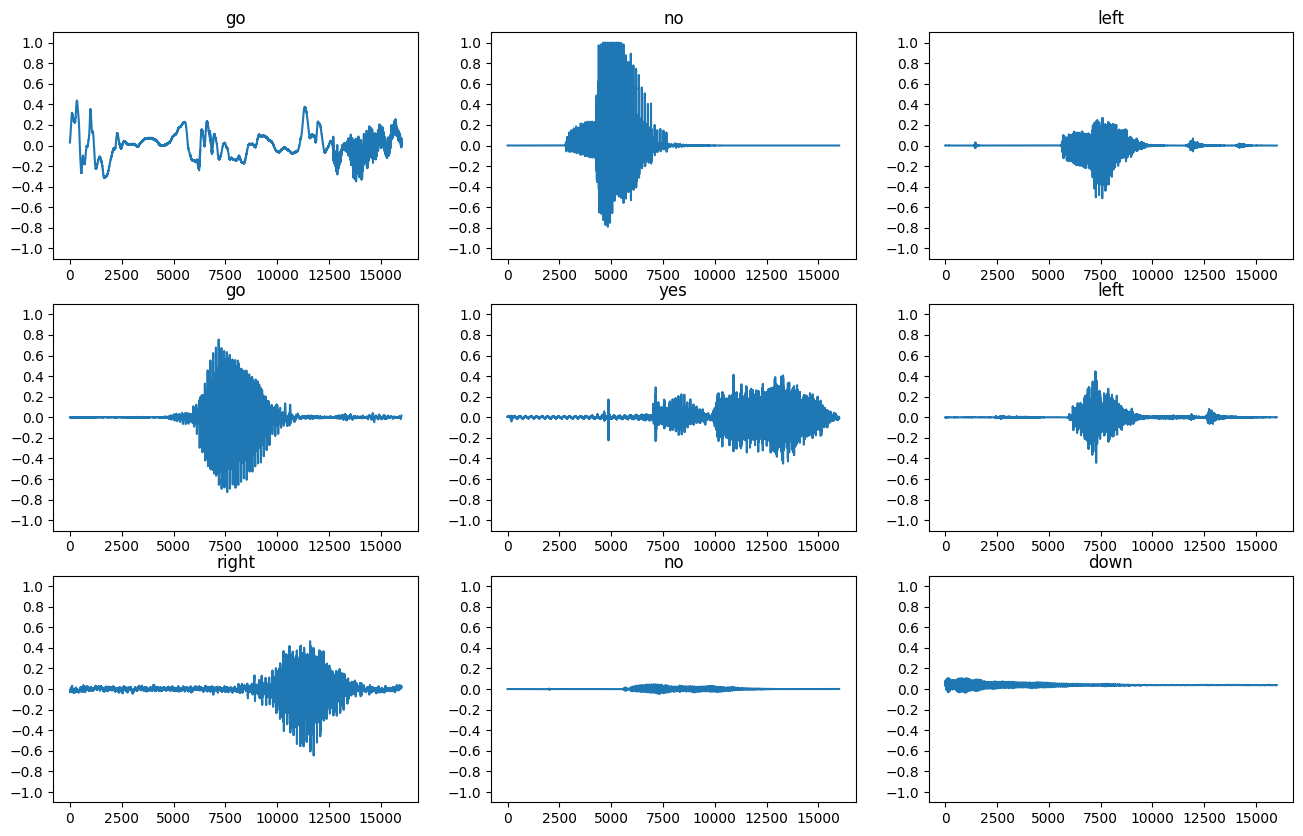
دعنا نرسم بعض أشكال الموجات الصوتية:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
تحويل أشكال الموجة إلى مخططات طيفية
يتم تمثيل أشكال الموجة في مجموعة البيانات في المجال الزمني. بعد ذلك ، ستقوم بتحويل أشكال الموجة من إشارات المجال الزمني إلى إشارات مجال التردد الزمني عن طريق حساب تحويل فورييه قصير المدى (STFT) لتحويل أشكال الموجة إلى مخططات طيفية ، والتي تُظهر تغيرات التردد بمرور الوقت ويمكن أن تكون كذلك ممثلة كصور ثنائية الأبعاد. ستقوم بتغذية صور المخطط الطيفي في شبكتك العصبية لتدريب النموذج.
يحول تحويل فورييه ( tf.signal.fft ) الإشارة إلى الترددات المكونة لها ، لكنه يفقد كل معلومات الوقت. بالمقارنة ، يقسم STFT ( tf.signal.stft ) الإشارة إلى نوافذ زمنية ويقوم بتشغيل تحويل فورييه على كل نافذة ، مع الاحتفاظ ببعض معلومات الوقت ، وإرجاع موتر ثنائي الأبعاد يمكنك تشغيل التلافيف القياسية عليه.
قم بإنشاء وظيفة مفيدة لتحويل أشكال الموجة إلى مخططات طيفية:
- يجب أن تكون أشكال الموجة من نفس الطول ، بحيث عندما تقوم بتحويلها إلى مخططات طيفية ، يكون للنتائج أبعاد متشابهة. يمكن القيام بذلك ببساطة عن طريق الحشو الصفري لمقاطع الصوت التي تكون أقصر من ثانية واحدة (باستخدام
tf.zeros). - عند استدعاء
tf.signal.stft، اختر معلماتframe_lengthوframe_stepبحيث تكون "صورة" الطيف المتولد مربعة تقريبًا. لمزيد من المعلومات حول اختيار معلمات STFT ، ارجع إلى فيديو Coursera هذا حول معالجة الإشارات الصوتية و STFT. - ينتج STFT مجموعة من الأعداد المركبة التي تمثل الحجم والمرحلة. ومع ذلك ، في هذا البرنامج التعليمي ، لن تستخدم سوى المقدار الذي يمكنك اشتقاقه من خلال تطبيق
tf.absعلى إخراجtf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
بعد ذلك ، ابدأ في استكشاف البيانات. اطبع أشكال الموجة المتوترة لأحد الأمثلة والمخطط الطيفي المقابل ، وقم بتشغيل الصوت الأصلي:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
الآن ، حدد وظيفة لعرض مخطط طيفي:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
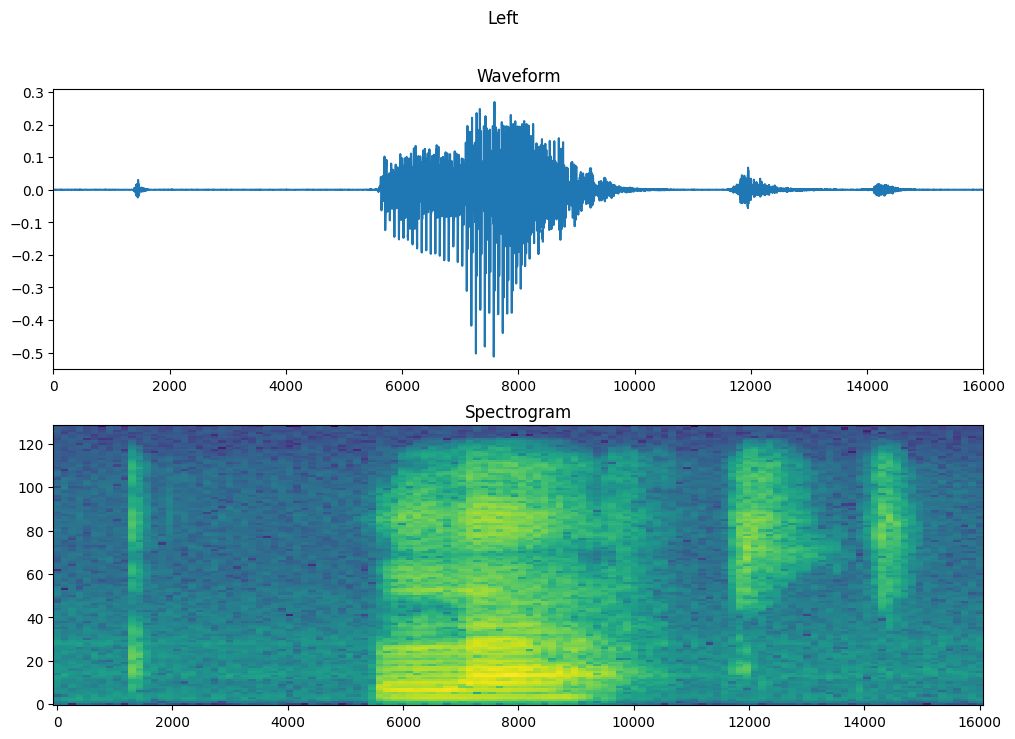
ارسم الشكل الموجي للمثال بمرور الوقت والمخطط الطيفي المقابل (الترددات بمرور الوقت):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
الآن ، حدد دالة تقوم بتحويل مجموعة بيانات شكل الموجة إلى مخططات طيفية والتسميات المقابلة لها كمعرفات عدد صحيح:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
get_spectrogram_and_label_id عبر عناصر مجموعة البيانات باستخدام خريطة مجموعة Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
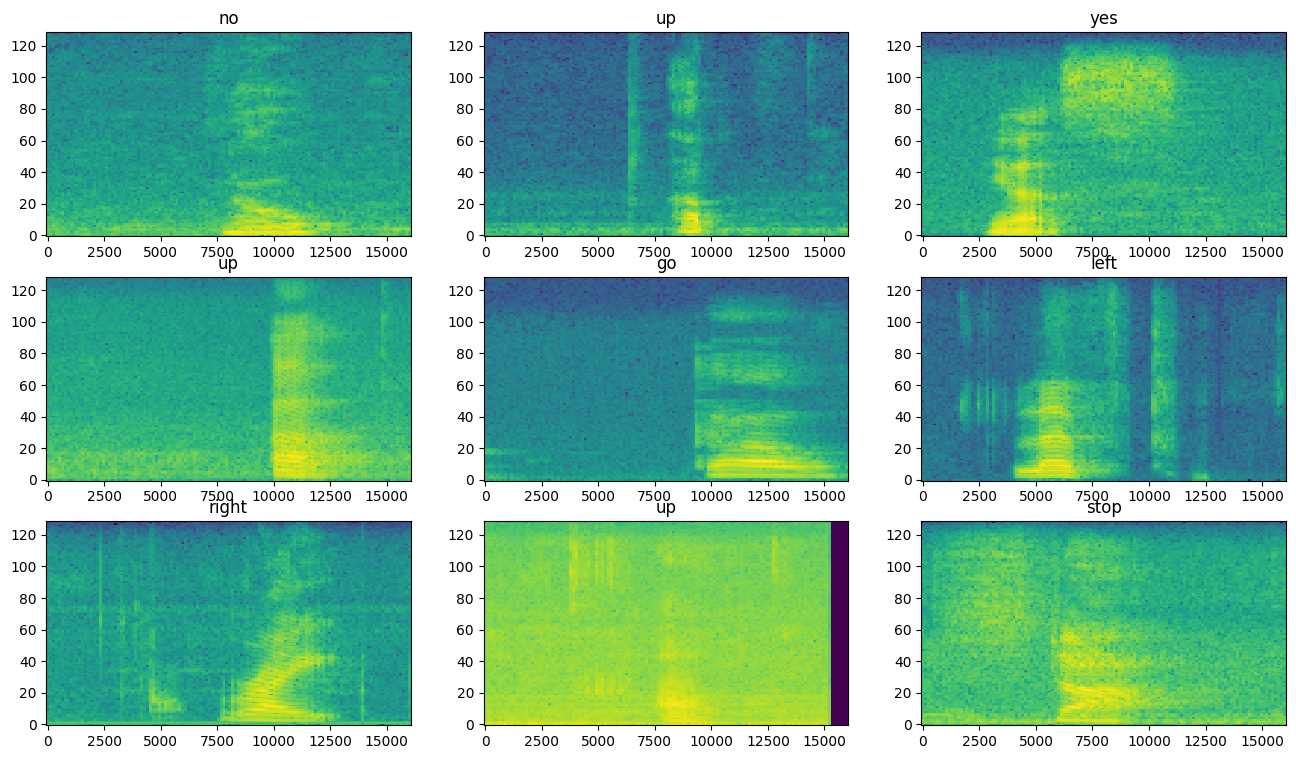
افحص مخططات الطيف للحصول على أمثلة مختلفة لمجموعة البيانات:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
بناء وتدريب النموذج
كرر مجموعة التدريب قبل المعالجة على مجموعات التحقق والاختبار:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
مجموعة مجموعات التدريب والتحقق من الصحة للتدريب النموذجي:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
أضف عمليات Dataset.cache و Dataset.prefetch لتقليل زمن انتقال القراءة أثناء تدريب النموذج:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
بالنسبة للنموذج ، ستستخدم شبكة عصبية تلافيفية بسيطة (CNN) ، نظرًا لأنك قمت بتحويل ملفات الصوت إلى صور طيفية.
سيستخدم نموذج tf.keras.Sequential المتسلسل طبقات Keras التالية للمعالجة المسبقة:
-
tf.keras.layers.Resizing: لاختزال المدخلات لتمكين النموذج من التدريب بشكل أسرع. -
tf.keras.layers.Normalization: لتطبيع كل بكسل في الصورة بناءً على متوسطها وانحرافها المعياري.
بالنسبة لطبقة Normalization ، يجب أولاً استدعاء طريقة adapt الخاصة بها في بيانات التدريب من أجل حساب الإحصائيات الإجمالية (أي المتوسط والانحراف المعياري).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
قم بتكوين نموذج Keras باستخدام مُحسِّن آدم وخسارة الانتروبيا المتقاطعة:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
قم بتدريب النموذج على مدى 10 فترات لأغراض العرض التوضيحي:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
دعنا نرسم منحنيات فقدان التدريب والتحقق من الصحة للتحقق من تحسن نموذجك أثناء التدريب:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

تقييم أداء النموذج
قم بتشغيل النموذج على مجموعة الاختبار وتحقق من أداء النموذج:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
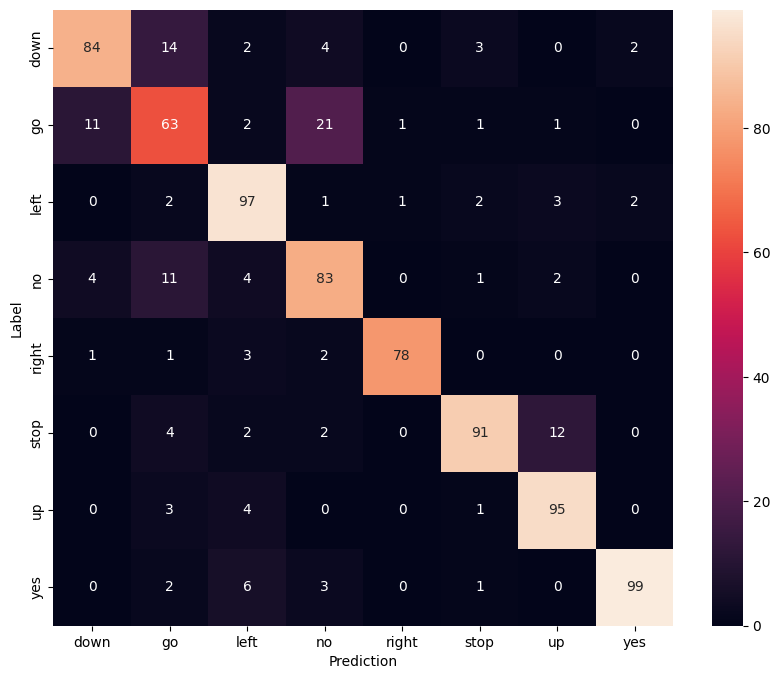
اعرض مصفوفة الارتباك
استخدم مصفوفة الارتباك للتحقق من مدى نجاح النموذج في تصنيف كل أمر من الأوامر في مجموعة الاختبار:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
تشغيل الاستدلال على ملف صوتي
أخيرًا ، تحقق من إخراج توقع النموذج باستخدام ملف صوتي إدخال لشخص يقول "لا". ما مدى جودة أداء نموذجك؟
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
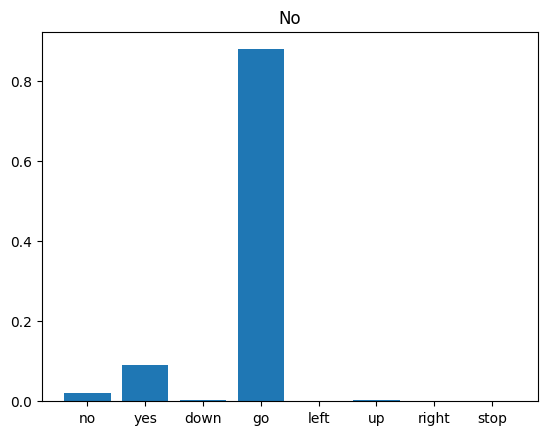
كما يوحي الإخراج ، يجب أن يتعرف نموذجك على الأمر الصوتي على أنه "لا".
الخطوات التالية
يوضح هذا البرنامج التعليمي كيفية إجراء تصنيف صوتي بسيط / التعرف التلقائي على الكلام باستخدام شبكة عصبية تلافيفية مع TensorFlow و Python. لمعرفة المزيد ، ضع في اعتبارك الموارد التالية:
- يوضح تصنيف الصوت مع برنامج YAMNet التعليمي كيفية استخدام التعلم عن طريق التحويل لتصنيف الصوت.
- دفاتر الملاحظات من اختبار TensorFlow للتعرف على الكلام من Kaggle .
- يعلم TensorFlow.js - التعرف على الصوت باستخدام مختبر ترميز تعلم النقل كيفية إنشاء تطبيق ويب تفاعلي خاص بك لتصنيف الصوت.
- برنامج تعليمي حول التعلم العميق لاسترجاع المعلومات الموسيقية (Choi et al. ، 2017) على arXiv.
- يحتوي TensorFlow أيضًا على دعم إضافي لإعداد البيانات الصوتية وتعزيزها للمساعدة في مشروعاتك القائمة على الصوت.
- ضع في اعتبارك استخدام مكتبة librosa - حزمة Python للموسيقى وتحليل الصوت.